用于指法估计的音高差数据增强方法
2023-02-15赵昊月
关 欣,赵昊月,李 锵
用于指法估计的音高差数据增强方法
关 欣,赵昊月,李 锵
(天津大学微电子学院,天津 300072)
指法估计模型的性能除了与自身的结构有关,数据本身的数量和质量也是其重要影响因素.然而,乐谱指法的标注需要标注者有一定演奏经验,且标注过程费时费力,导致现有乐谱-指法数据集稀少,且增速缓慢.为解决数据集样本数量有限带来的模型表现不佳、参数过拟合等问题,提出了两种针对键盘类乐器乐谱音高差指法数据的数据增强方法.通过分析乐谱-指法数据的统计特征,一方面结合键盘类乐器和指法的映射关系,提出了基于隐马尔可夫模型的数据增强方法,另一方面结合双手手部生理学特性,提出了左右手镜像变换的数据增强方法.将本文提出的两种增强方法生成的数据加入训练集,经过与人工确定指法思路相近的双向长短期记忆网络学习后,一般匹配率提高了2.24%,最高匹配率提升了3.73%.结果表明数据增强有助于模型更好地学习音指特征.将基于隐马尔可夫模型的数据增强方法生成的“再采样数据集”和基于手部生理学特性生成的“左右手镜像变换数据集”分别加入训练,对指法估计结果中单音和复音占比75%以上的乐谱匹配率分别进行统计,结果表明再采样数据可以增强数据集本身的统计特征,左右手镜像变换数据可以弥补一些数据集原先没有的音指规律,说明了两种数据增强方法在键盘乐器指法估计任务中的有效性.
指法;数据增强;统计学习;左右手变换
自动指法估计已成为音乐符号信息处理的新兴主题之一,对于指法估计的研究也在蓬勃发展.但其数据集的搜集还处于初级阶段,很多研究者还在使用小规模的私人非公用数据集[1].建立指法数据时需要大量专业演奏者手工逐一标注,并且对于同一乐谱的指法数据并不唯一,搜集阶段耗时较长且工作量大.目前基于数据驱动模型的数据增强方法已经成为解决小数据集过拟合问题、提高模型识别准确率的有效手段之一[2].现阶段还没有针对键盘乐器指法数据的数据增强方法.
数据增强(data augmentation)是指通过引入未观测到的数据或隐变量构建迭代优化或采样算法的方法[3].数据增强的目的是通过应用转换来人为地创建新的训练数据,将转换(例如音频片段的拉伸或压缩)应用到输入数据,同时保留类标签.这种转换有许多潜在的好处:数据增强可以编码以前有关数据或任务特定不变的知识,作为规范模板使生成的模型更加稳健,并为以数据为基础的深度学习模型提供资源[4].
指法来源于演奏者对乐谱的认知,受约束于其手部条件与键盘排布.乐谱-指法数据中的指法灵活多变,不同于自然语言处理(natural language process-ing,NLP)中词性标注任务中一个词有且只有一个正确标签,即便受制于指法规则,指法也往往可以有多种排列组合形式.研究人员通常通过改善模型结 构[1,5]或设置一些模型约束条件[6-7]来获得更优的指法估计结果,但数据本身的不足是模型参数学习受限的根本原因.数据增强能在不增加人工成本的情况下扩展数据集,节约大量时间和精力.
本文主要提出了两种关于键盘类乐器指法数据的数据增强方法,其中基于隐马尔可夫的方法适用于所有键盘类乐器,基于左右手变换的方法适用于双手演奏的键盘类乐器,例如钢琴、电子琴等.基于隐马尔可夫的方法和左右手变换方法分别对一般匹配率提升了1.75%和1.39%,最高匹配率提升了2.43%和2.16%,两种增强方法同时使用也对结果有2.24%与3.73%的提升.
1 数据增强方法研究现状
数据增强是在不实质性的增加数据的情况下,从原始数据加工出更多的表示,提高原数据的数量及质量,以接近于更多数据量产生的价值[8].数据增强有助于加强数据内在特征,减少模型过拟合,提升泛化能力.
数据增强主要分为基于样本变换的数据增强和基于样本特征的数据增强.前者是利用数据变换规则对已有数据扩增,例如图像的几何操作[9]、文本的同义词替换[10]、时间序列的添加噪声[11]等.基于样本特征的数据增强是通过神经网络或某种模型将样本数据的特征提取为具体参数,利用参数对数据进行扩增,例如基于神经风格迁移的数据增强、构造生成网络生成数据等.
基于样本变换数据增强是基础的数据增强方法,目前在机器视觉以及自然语言处理中已有广泛的应用[8,12].基于样本变换的数据增强方法立足于数据本身特性.例如在图像数据中,图像的位置信息、颜色信息、局部信息对标签影响不大,通过几何操作、颜色变换、随机擦除等方法[9,13-14]增加的数据能使系统更好地区分背景与物体,着眼于颜色间的梯度变化和整体轮廓;在序列数据中,有添加噪声、窗口裁剪、频率域变换等方法[11].基于样本变换的数据增强方法会根据数据类型的不同有不同的表现形式,可以让系统降低或消除数据中冗余信息的权重,从而提高模型泛化能力.
基于样本特征的数据增强依托系统或网络对数据的提取.例如moment exchange(MoEx)方法[15]利用神经网络特征空间中可以捕获图像底层结构的特征矩(标准差和方差),通过样本间随机交换特征矩实现特征空间的数据增强;生成模型如变分自编码网络(variational auto-encoding network,VAEN)[16]和生成对抗网络(generative adversarial network,GAN)[17]通过训练样本固定其内部参数用于数据增强[18];神经风格迁移(neural style transfer)[19]通过随机初始化的生成图像和其定义的代价函数()生成新样本.基于样本特征的数据增强方法是通过强化有效信息来提高模型精确度基于样本变换和特征的数据增强方法正交,可以联合使用.以上研究启示笔者可以从乐谱-指法数据特点和适合该数据的模型的特征空间探索钢琴指法数据的数据增强方法.
2 键盘乐器指法数据
数据增强需要从已知数据本身出发,通过增强方法突出样本与标签间的显性联系.针对指法估计任务,笔者从数据本身带来的信息结合人类确定指法的逻辑思路来设计增强方法.
2.1 键盘乐器指法数据的特征分析
结合基本键盘乐器演奏常识,分析音高及指法数据特征的优化点.
(1) 音符指法数据集是一种一维音符序列到一维指法序列的数据集.键盘乐器的音符指法数据集,例如钢琴、手风琴、管风琴、电子琴等键盘乐器,其指法与乐谱上的音符往往是一一对应的关系,也就是可以将键盘乐器的指法估计问题看成是序列到序列的映射.
(2) 音程隐含着琴键相对位置的信息.键盘上琴键是由低音到高音依次排布的,那么键盘乐器的乐谱上的音符可以对应到每个琴键,音高信息确定了哪个位置的琴键被弹奏.音程是两个音高之间的跨 度[20],进一步说,演奏时后一琴键对于前一琴键的相对位置与当前乐谱的音程信息有关.
(3) 对于双手演奏的键盘乐器,例如钢琴或电子琴,若左右手弹奏升降调类型相同的同一琴键间物理距离,指法是相反的;若左右手分别弹奏升降调相反的同一物理距离,则指法相同.人的左右手的生理结构是对称的,如果分别用左右手弹奏同一首曲子,指法肯定不相同,如果在左手弹奏时将琴键的高低音顺序交换,则因为左右手对应的琴键分布也对称,所以指法相同.研究表明,对于键盘乐器来说,弹奏乐曲时琴键的绝对位置并不重要,琴键的相对位置才是影响指法的确定的关键[21].综上两点,即使不弹同一首曲子,只要琴键的相对位置一直相同,在左右手琴键也对称的情况下,左右手指法相同.而在实际演奏中琴键是固定的,在跨度也就是相对物理距离一致的情况下(琴键绝对位置可能不同),如图1所示,在左手弹奏大跨度升调乐谱时使用2指到1指的指法,如果换为右手弹奏,变为了1指到2指,指法因手的类型不同而互换了.
(4) 对于弹奏和弦,左右手指法具有相似性,如图2所示,弹奏琴键位置均间隔一个白键的和弦,左右手均使用1指、3指和5指弹奏.
2.2 确定指法的一般思路
演奏者确定指法时主要以舒适度和流畅性为目标,受手部人体工程学和琴键位置的自然约束.琴键所在位置是指法确定的基础,同时,乐谱对应的前后琴键的位置关系、前后指法的指法状态也限制了当前的指法选择.

图1 左右手演奏同一音程的升调示意

图2 左右手演奏三和弦示意
指法是灵活的,针对某个乐谱的指法并不唯一,针对同一片段的指法可能会根据乐曲的速度和节奏不同而有所变化.在哈农指法练习中为了训练某种专门设立针对性的指法,甚至可以用单指弹奏整首练习[22].演奏者会根据自身手部条件,结合乐曲的音乐表现性对指法统筹规划,设计出具有连贯流畅的指法.
3 钢琴乐谱-指法数据的优化方法
3.1 音符数据预处理
数据处理思路主要有两种,一种是将音高信息转换为其对应的MIDI号作为输入来估计指法[1,5],一种是将表征琴键间的相对位置信息作为输入[6-7].经第2.1节分析,相对位置信息比原始音高信息更有利于指法估计任务,本文音高信息的表示方式参照文 献[10].该文将处理过的数据称为音高差(pitch-difference,PD)数据,这种表示方法包含相邻音高的物理位置间隔信息与时间信息,更利于模型对音指关系的探索.在该处理方式中,左右手数据是分开处理,独立训练的.具体表示方式为
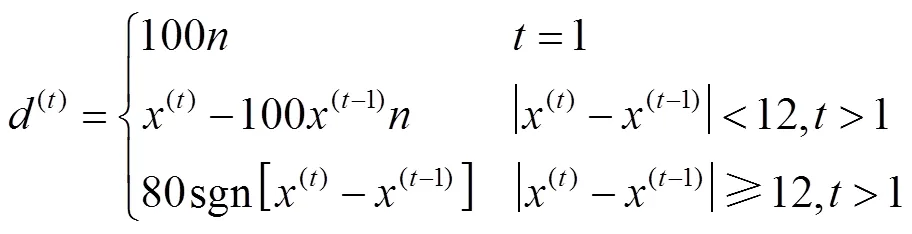
式中:表示音符音高对应的Midi号;表示音符的顺序索引;表示当前时刻音符的数量,即复音包含的音符个数.当前音符为单音时,规定为0.
3.2 基于隐马尔可夫生成模型的数据增强方法
虽然乐谱-指法数据增强,不能直接应用自然语言处理领域的数据增强方法,但其中蕴含的一些思路仍具有启发意义.例如:在文本序列词性标注或机器翻译等任务中,同义替换的数据增强方法十分常见.同义替换以保持两个词之间语义等价性的方式实现数据增强.受此启发,对于乐谱-指法数据来说,可以通过保持乐谱数据和指法间映射关系的等价性实现数据增强.
在指法标注任务中,除非音符前面或后面有其他音符,否则任何指法都是可行的,即指法本质是寻找一个平滑状态转换的最佳序列问题.因此,钢琴演奏可以解释为从手指位置的状态序列中生成演奏音符序列的过程[5].基于此,笔者提出了一种基于隐马尔可夫模型(hidden Markov model,HMM)[23]的数据增强方法,HMM之前也直接用于指法估计任务[5-6]并取得良好效果.


接下来的指法为
对应的音高差为

以此便能生成指定长度的增强序列.
3.3 左右手数据变换的数据增强方法
根据第2.1节可得,左右手的指法有一定相似性,且在弹奏中对于左右手的转指规则是相同的[6,21],这启示笔者在一定条件下,左(右)手的指法数据可以在升降调类型转换后用于右(左)手数据的训练.但由于数据处理中区分了单音与复音,笔者在处理中也保留这种数据处理带来的优势,具体转换公式如下.
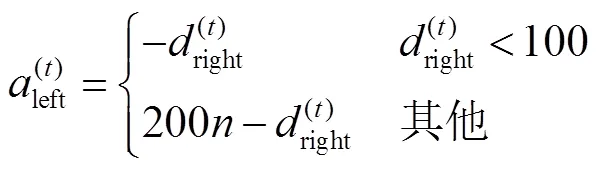
4 实验与验证
4.1 数据选择
本文以钢琴的指法数据集PIG[1]为实验数据集来验证本文提出的两种数据增强方法的有效性.PIG数据集包含150首乐曲,其中有30首包含了4种以上的不同指法标注,共有309例音符-指法数据样本,是目前关于键盘类乐器的唯一公开乐谱-指法数据集,对于乐曲成分中的单音、各类和弦成分的统计结果如表1所示.
其中连续和弦为除单音和前后都是单音的复音外的音,连续单音是指除复音和前后都是复音的单音外的其他音.通过表1可以看出左右手演奏的乐谱成分在单音、和声、三和弦、以及连续和弦、连续单音上差别较大.这个规律和演奏钢琴的实际认知是相符合的,右手通常主导旋律,一些快节奏的演奏也通常由右手完成,故单音占比较大,左手的演奏作为铺垫,增添色彩的和弦通常由左手完成.
表1 乐谱数据集音高成分分布

Tab.1 Pitch composition distribution of the music database
使用PIG数据中30首乐曲对应的150例音高差-指法数据作为测试集,其余120首乐曲拓展为的159例样本作为训练集.考虑到整体数据量,实验使用一阶HMM,生成50例长度在150~300之间的数据,称为“再采样数据集”.将基于左右手变换后的增强数据称为“左右手镜像变换数据集”.
4.2 评价指标
本文以与数据真值的一致程度为评价标准,即模型标注结果与指法标签一致的数量在整个乐谱中的占比,本文称为匹配率,匹配率的计算公式为
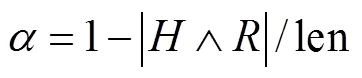
式中:为人工标注结果;为算法标注结果;len为乐谱总长度.
由于涉及到一个乐谱对应多个指法的问题,个乐谱加入不同的指法真值序列后变为gen个测试样本的情况下,本文参考文献[1]中的评价方法使用两种指标.计算估计结果与每个指法真值序列匹配率平均值记为一般匹配率gen,计算每首曲子中和估计结果最相似的指法真值序列的匹配率,将其平均值记为最高匹配率high,表示方式为
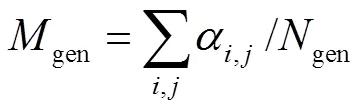
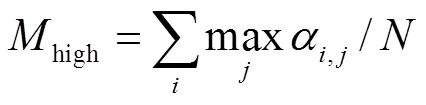
4.3 模型选择
音高差数据是一维序列,加入时序考量的循环神经网络[24](recurrent neural networks,RNN),比更普遍用于分类的前馈神经网络、卷积神经网络更适合指法标注任务,但原始的RNN在训练中容易出现梯度爆炸和梯度消失的问题导致其无法捕捉长距离依赖.故选用在原始RNN基础上发展起来的长短期记忆(long short-term memory,LSTM)[25]网络作为验证实验的基础.
LSTM主要功能由其内部3个门实现,如图3所示.针对指法估计问题,其内部功能可做如下具体化:遗忘门可以控制之前的音高差和估计出的指法对目前指法估计的影响,输入门控制当前音高差对指法的影响,输出门控制包括当前的音高差在内的长期音高差记忆与之前的长期指法记忆是否对当前估计指法产生影响.LSTM单元前向过程贴近人工确定指法的思路,根据第2.2节所述,后文的音高信息与指法信息对当前指法也有所约束,故采用双向长短期记忆(bidirectional LSTM,Bi-LSTM)网络作为实验模型.
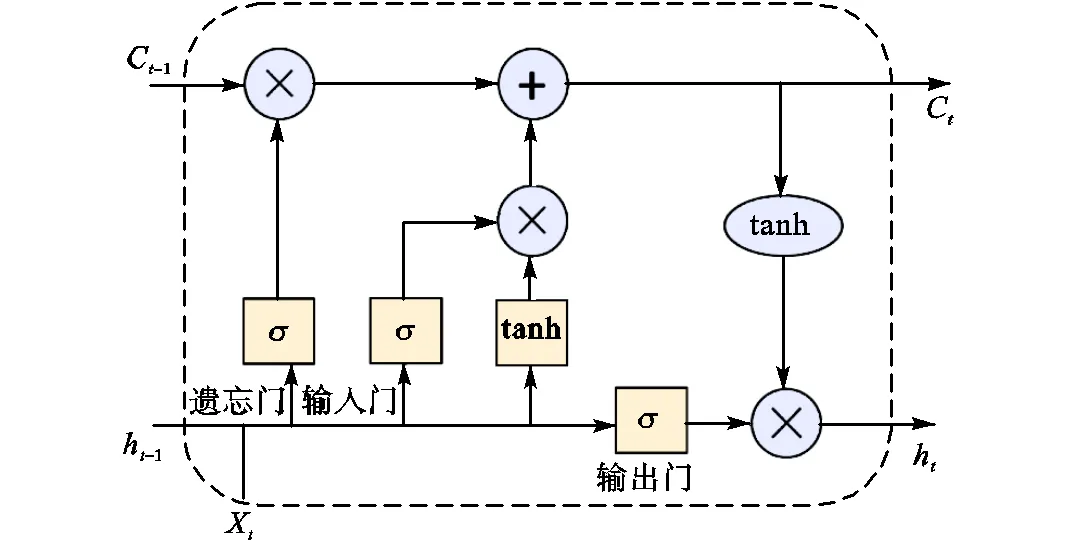
图3 LSTM单元示意
4.4 参数设置
在模型训练中使用Adam自适应学习率优化器进行自动优化,使用3层LSTM网络.模型初始学习率为0.005且每经过10轮(Epoch)训练使其乘以0.8,通过不断降低学习率,找到损失的最小值.
由于左右手转换数据会生成309个样本,约为真实训练集样本的2倍,因此在有左右手变换数据集训练过程中,将真实训练样本复制扩容为原来的3倍,以防增强集在训练集中占比过大导致系统模型学习音指关系偏差.
4.5 结果与分析
为了体现两种数据增强方法的作用,笔者设计了4组对比实验,均使用BI-LSTM模型,结果如表2 所示.
表2 增强方法对比结果

Tab.2 Comparison results of augmentation methods
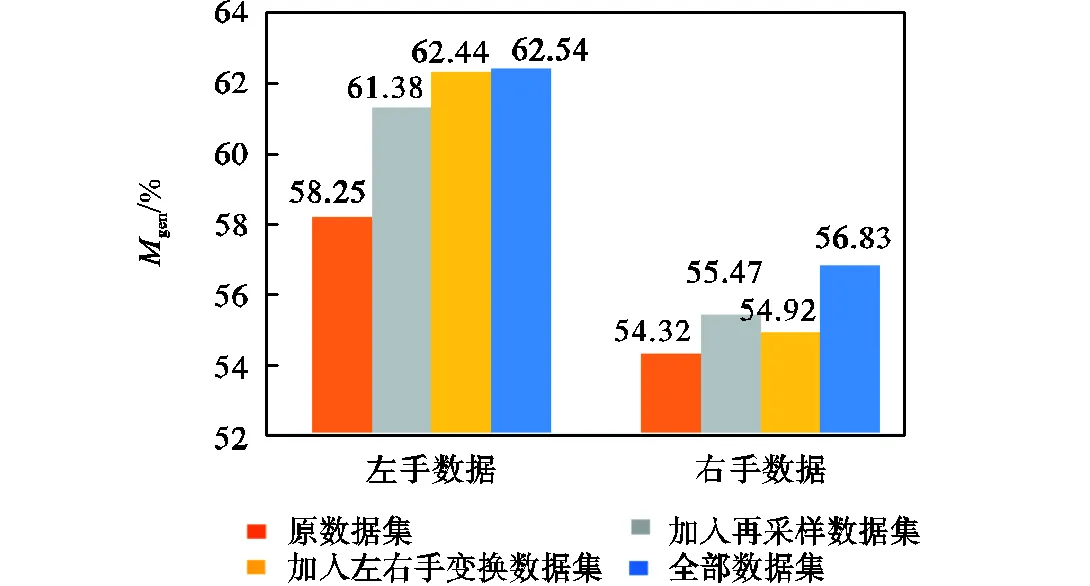
图4 单音占比75%以上的数据结果统计

图5 复音占比75%以上的数据结果统计
在单音占比75%以上的曲谱中,对于右手来说,再采样数据集加入的效果优于左右手变换数据集的加入,对于左手数据则正好相反;在复音占比75%以上的乐谱中,对于右手来说,加入左右手变换数据后效果由于再采样数据,甚至超过全部数据集训练的结果,对于左手数据则是加入再采样数据的效果优于左右手变换数据.
结果进一步说明了两种增强方法的优势,结合数据样本的分布,再采样数据集增强了原数据集的特色,从而使优势得到更好的发挥,例如其在单音较多右手数据与复音较多的左手数据中取得了良好表现;左右手变换数据集弥补了原数据集中指法多样性的缺陷,例如其在复音占比75%以上的右手数据与单音占比75%以上的左手数据中取得了更好的表现.在右手多复音数据统计中,两种增强方法的数据集全部加入后,再采样数据对参数的影响匹配率使得有所减少,这一结果也验证了左右手数据的差异性较大.
5 结 语
本文提出了两种针对键盘乐器指法估计的数据增强方法,其中一种是基于数据集样本与标签的统计分布特性的增强方法,另一种是基于左右手指法的镜像对称性的增强方法,并通过钢琴指法数据集PIG验证了这两种数据增强方法的有效性.鉴于键盘乐器的相似性,这两种数据增强方法也适用于各类双手弹奏键盘的乐器的指法估计.再采样数据可以增强数据集本身统计特征,左右手镜像变换数据可以弥补一些数据集原先没有的音指规律.同时实验结果也表明,数据增强有助于模型自然地整合域知识间的关系,使音高差更容易地转换为指法数据.
基于HMM的数据增强方法通过将数据的统计分布特征转换为具有马尔可夫和独立输出特性的模型参数实现数据增强,该思路也可迁移用于其他非键盘类乐器指法标注的数据增强中.其统计指法转移频率的矩阵是灵活的,在数据量充足的情况下,可以联系更长的指法关系,在该情况下,增强后的数据更符合手部人体工程学,甚至其片段有出现在真实乐谱里的可能性.
[1] Nakamura E,Saito Y,Yoshii K. Statistical learning and estimation of piano fingering[J]. Information Sciences,2020,517:68-85.
[2] 陈文兵,管正雄,陈允杰. 基于条件生成式对抗网络的数据增强方法[J]. 计算机应用,2018,38(11):3305-3311.
Chen Wenbing,Guan Zhengxiong,Chen Yunjie. Data enhancement method based on conditional generative confrontation network[J]. Computer Applications,2018,38(11):3305-3311(in Chinese).
[3] Van Dyk D A,Meng X L. The art of data augmentation[J]. Journal of Computational & Graphical Statistics,2001,10(1):1-50.
[4] Da O T,Gu A,Ratner A J,et al. A kernel theory of modern data augmentation[J]. Proc Mach Learn Res,2019,97:1528-1537.
[5] Yonebayashi Y,Kameoka H,Sagayama S. Automatic piano fingering decision based on hidden Markov models with latent variables in consideration of natural hand motions[J]. Ipsj Sig Notes,2007,2007(81):179-184.
[6] 李 锵,李晨曦,关 欣. 基于判决HMM和改进Viterbi的钢琴指法自动标注方法[J]. 天津大学学报(自然科学与工程技术版),2020,53(8):814-824.
Li Qiang,Li Chenxi,Guan Xin. Automatic fingering annotation for piano score via judgement-HMM and improved Viterbi [J]. Journal of Tianjin University (Science and Technology),2020,53(8):814-824(in Chinese).
[7] Guan Xin,Zhao Haoyue,Li Qiang. Estimation of playable piano fingering by pitch-difference fingering match model[EB/OL]. https://asmp-eurasipjournals.springero-pen.com/articles/10.1186/s13636-022-00237-8,2022-04-11.
[8] 葛轶洲,许 翔,杨锁荣,等. 序列数据的数据增强方法综述[J]. 计算机科学与探索,2021,15(7):1207-1219.
Ge Yizhou,Xu Xiang,Yang Suorong,et al. A review of data enhancement methods for sequence data[J]. Computer Science and Exploration,2021,15(7):1207-1219(in Chinese).
[9] Chatfield K,Simonyan K,Vedaldi A,et al. Return of the devil in the details:Delving deep into convolutional nets[EB/OL].https://arxiv.org/abs/1405.3531v4,2014-10-05.
[10] Wei Jason,Zou Kai. EDA:Easy data augmentation techniques for boosting performance on text classification tasks[EB/OL]. https://arxiv.org/abs/1901.11196,2019-08-05.
[11] Wen Q,Sun L,Song X,et al. Time series data augmentation for deep learning:A survey[EB/OL]. https://arxiv.org/abs/2002.12478,2021-09-18.
[12] Simard P,Steinkraus D,Platt J C. Best practices for convolutional neural networks applied to visual document analysis[C]// Proceedings Seventh International Conference on Document Analysis and Recognition. Edinburgh,UK,2003:958-963.
[13] Lecun Y,Bottou L. Gradient-based learning applied to document recognition[J]. Proceedings of the IEEE,1998,86(11):2278-2324.
[14] Alex K,Ilya S,Geoffrey E,et al. Image net classification with deep convolutional neural networks[J]. Commun of the ACM,2017,60:84-90.
[15] Li B,Wu F,Lim S N,et al. On feature normalization and data augmentation[C]//2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition(CVPR). Nashville,USA,2021:12378-12387.
[16]翟正利,梁振明,周 炜,等. 变分自编码器模型综述[J]. 计算机工程与应用,2019,55(3):1-9.
Zhai Zhengli,Liang Zhenming,Zhou Wei,et al. Overview of variational autoencoder model[J]. Computer Engineering and Applications,2019,55(3):1-9(in Chinese).
[17] Goodfellow I,Pouget-Abadie J,Mirza M,et al. Generative adversarial networks[J]. Advances in Neural Information Processing Systems,2014,3:2672-2680.
[18] Luis P,Jason W. The effectiveness of data augmentation in image classification using deep learning[EB/OL]. https://arxiv.org/abs/1712.04621,2019-10-13.
[19] Gatys L A,Ecker A S,Bethge M. Image style transfer using convolutional neural networks[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas,USA,2016:2414-2423.
[20] Hasegawa R. Tone representation and just intervals in contemporary music[J]. Contemporary Music Review,2006,25(3):263-281.
[21] Parncutt R,Sloboda J A,Clarke E F,et al. An ergonomic model of keyboard fingering for melodic fragments[J]. Music Perception,1997,14(4):341-382.
[22]朱 斌. 追寻钢琴声音美的必由之路——以钢琴指法练习《哈农》为例[J]. 音乐探索,2009,25(4):90-92.
Zhu Bin. On the finger-excising issue by taking Hanon as an example[J]. Music Exploration,2009,25(4):90-92(in Chinese).
[23] Rabiner L R. A tutorial on hidden Markov models and selected applications in speech recognition[J]. Proceedings of the IEEE,1989,77(2):257-286.
[24] Graves A,Mohamed A,Hinton G. Speech recognition with deep recurrent neural networks[C]//2013 IEEE International Conference on Acoustics,Speech andSignal Processing. Vancouver,Canada,2013:6645-6649.
[25] Hochreiter S,Schmidhuber J. Long short-term memory[J]. Neural Computation,1997,9(8):1735-1780.
Pitch-Difference Data Augmentation for Fingering Estimation
Guan Xin,Zhao Haoyue,Li Qiang
(School of Microelectronics,Tianjin University,Tianjin 300072,China)
Fingering estimation performance for keyboard instruments is mostly affected by the quantity and quality of data, in addition to the structure of the model. However, fingering labeling requires annotators to have playing experience, and the labeling process is time-consuming and labor-intensive, which leads to scarcity and slow development of fingering-score datasets. Two data augmentation methods are proposed to extend the fingering-score dataset for keyboard instruments to address the problem of poor model performance and parameter overfitting caused by limited datasets. By analyzing statistical features of fingering-score data, a data augmentation method based on hidden Markov models is proposed by combining the mapping relationship between keyboard instruments and fingerings. Another method using hands mirror transformation is proposed that combines the physiological characteristics of hands. The bidirectional long short-term memory network is used, which is similar to the manual process of fingering labeling for experimental verification. After adding the generated data to the training set using the proposed methods, the general and highest matching rates were reported to have increased by 2.24% and 3.73%, respectively. The results show that the data augmentation strategy assists the model in learning finger-score features well. The “resampling data” generated by the data augmentation method based on the hidden Markov model and the “hand mirror transformation data” based on the physiological characteristics of the hand were added to the training. The matching rates of scores with more than 75% monophonic ratio and more than 75% polyphonic ratio in the estimation results were calculated. The results show that resampling data can enhance the statistical characteristics of the original data set, and the hand mirror transformation data can provide certain fingering knowledge that were not in the original data set. The results demonstrate the effectiveness of the two data augmentation methods presented in this study for the task of fingering estimation for keyboard instruments.
fingering;data augmentation;statistical learning;physical transformation of hands
10.11784/tdxbz202112047
TP391
A
0493-2137(2023)02-0200-07
2021-12-29;
2022-03-21.
关 欣(1977— ),女,博士,副教授,guanxin@tju.edu.cn.
李 锵,liqiang@tju.edu.cn.
国家自然科学基金资助项目(61471263);天津市自然科学基金资助项目(16JCZDJC31100).
Supported by the National Natural Science Foundation of China(No.61471263),the Natural Science Foundation of Tianjin,China (No.16JCZDJC31100).
(责任编辑:孙立华)
