基于DCPAN的低剂量能谱CT图像去噪方法
2023-02-15史再峰欧阳顺馨孔凡宁齐俊宇
史再峰,程 明,欧阳顺馨,孔凡宁,齐俊宇,田 颖
基于DCPAN的低剂量能谱CT图像去噪方法
史再峰1, 2,程 明1,欧阳顺馨1,孔凡宁1,齐俊宇1,田 颖3
(1. 天津大学微电子学院,天津 300072;2. 天津市成像与感知微电子技术重点实验室,天津 300072;3. 天津仁爱学院,天津 301636)
能谱式计算机断层扫描(CT)成像技术具备良好的能量分辨率,能够精确地鉴别人体组织成分,从而为后续诊断提供更准确的检测信息.随着辐射剂量的降低,能谱CT图像中噪声水平显著提高,对成像质量产生严重影响,进而降低了组织成分的解析精度.基于卷积神经网络(CNN)的去噪模型虽然可以显著降低图像中的噪声含量,但随着卷积层数的增加,深层神经网络通常会丢失高频信息.为了解决这一问题,并实现在低剂量条件下重建出高质量能谱CT图像,本文提出了一种结合通道注意力机制(CA)和持续自注意力机制(PSA)的密集连接持续注意力网络(DCPAN).两种注意力机制分别建立特征图像在通道和全局维度的联系以提高网络对图像高频分量的敏感程度,进而抑制高频细节信息的丢失.该模型所采用的密集连接结构通过特征复用的方式可以在前馈传播中保留高频信息,使用复合损失函数来监督网络的训练可以使该模型对边缘特征和组织细节信息更加敏感.实验结果表明,经该模型处理的腹部切片CT图像峰值信噪比、结构相似性指数和特征相似性指数分别达到了38.25dB、0.9937和0.9732以上.相比于目前先进的CT噪声去除方法,该方法具有更好的噪声抑制能力,处理得到的重建图像组织结构清晰、噪声含量更低,为后续诊断和其他处理工作提供更精确的检测信息.
能谱式计算机断层扫描;低剂量;卷积神经网络;注意力机制
能谱式计算机断层扫描(computed tomography,CT)成像技术可以提供多个X射线能量区间的衰减信息,进而更加精准地量化评估所测组织成分信息.随着辐射剂量的降低,光子饥饿、串扰等不良效应增强、噪声水平明显上升,这严重地影响了能谱CT的图像质量,进一步降低了组织成分解析的精度,因此改善低剂量能谱CT图像质量的关键在于抑制噪声.目前已提出的CT图像去噪方法基于数据来源可以分为两类:投影域数据处理方法[1-2]和图像域数据处理方法[3-5].通过引入字典学习[6]、非局部均值等[7]图像处理算法虽然可以在一定程度上去除噪声和伪影,但由此处理得到的CT图像中存在图像分辨率下降和边缘模糊等问题,因此改善CT图像质量的效果十分有限.
相比于这些方法,深度学习在对图像的特征提取和学习方面具有更强的优势,特别是在CT图像去噪领域,涌现出了大量基于深度学习的方法.Kang等[8]提出了一种结合了小波变换的卷积神经网络模型对低剂量CT图像进行处理,有效地提高了CT图像的分辨率.Chen等[9]提出了一种残差编解码器CNN模型(RED-CNN)用于改善低剂量CT图像质量,在抑制噪声和保留细节结构等方面取得了不错的效果.虽然基于卷积运算模型在抑制CT图像噪声方面有较强的优势,但是随着网络层数的加深,深层网络会丢失图像特征的高频分量,导致其输出图像过于平滑,影响对CT图像组织细节的观察.Liang等[10]提出了一种结合边缘检测层来保留图像边缘处高频信息的去噪模型(EDCNN),在一定程度上提高了图像质量,但其边缘敏感程度受限于所引入的Sobel算子计算方向,对医学影像中复杂的边缘纹理结构处理效果仍不理想.最近,随着注意力机制在计算机视觉领域的快速发展,它可以通过提升网络对输入数据的选择能力来使得网络对特定信息具有更强的敏感性.这种特点为解决高频信息丢失的问题提供了新的思路.例如,Zhang等[11]通过将通道注意力机制(channel attention mechanism,CA)引入神经网络中在图像超分辨率重建领域实现了更好的效果.Wang等[12]通过优化网络结构来改善CA对空间位置间关系的敏感性,进而提高了网络的去噪能力,但其对空间信息的调整仅通过聚合通道特征来实现,导致其对高频信息的敏感程度不佳.
为了抑制高频信息在网络处理过程中的丢失,使去噪图像保留更多的细节信息,在本文中笔者提出了一种结合了CA和持续自注意力机制(persistent self-attention mechanism,PSA)的密集连接网络模型:密集连接持续注意力网络(densely connected persistent attention network,DCPAN).一方面,CA可以利用特征图的通道依赖性自适应地调整需要强调的通道权重;另一方面,PSA既可以通过建立全局各位置间相关性来调整特征权重,又可以聚合先前自注意力特征信息以减少前馈过程中的信息丢失.DCPAN结合两种注意力机制来改善网络对通道和全局特征敏感性,并使用密集连接结构聚合不同位置特征信息,有效地减少图像高频特征在处理过程中的丢失,进而重建出高质量的低剂量能谱CT图像.
1 能谱CT图像去噪方法
1.1 图像域去噪模型


深度学习模型具有强大的特征提取能力,并可通过训练来逼近算子,进而建立这种未知映射关系以解决该图像反问题.因此,本文通过构建并训练深度学习模型DCPAN以建立低剂量和常规剂量条件下能谱CT图像之间的映射关系从而改善输入图像质量是可行的.
1.2 基于DCPAN的去噪方法
1.2.1 模型整体结构
相比机器视觉领域的常规图像,能谱CT各能量区间重建图像的噪声分布具有一定的相关性.因此使用注意力机制来调整各通道信息有利于改善模型的去噪性能.笔者将探测数据重建的能谱CT各能量图像堆叠为一个高维张量作为网络的输入,网络的输出为与输入数据相对应的低噪声图像所构成的高维张量.如图1所示,所提出的DCPAN的整体结构由个级联注意力模块(cascaded attention block,CAB)组成,各模块之间采用密集连接方式,即除第1个模块外,第个模块均需要聚合前-1个模块的输出数据.在网络的末端,将网络输入数据与第个模块的输出相加,这种残差结构有助于解决深层网络所引起的梯度消失问题.
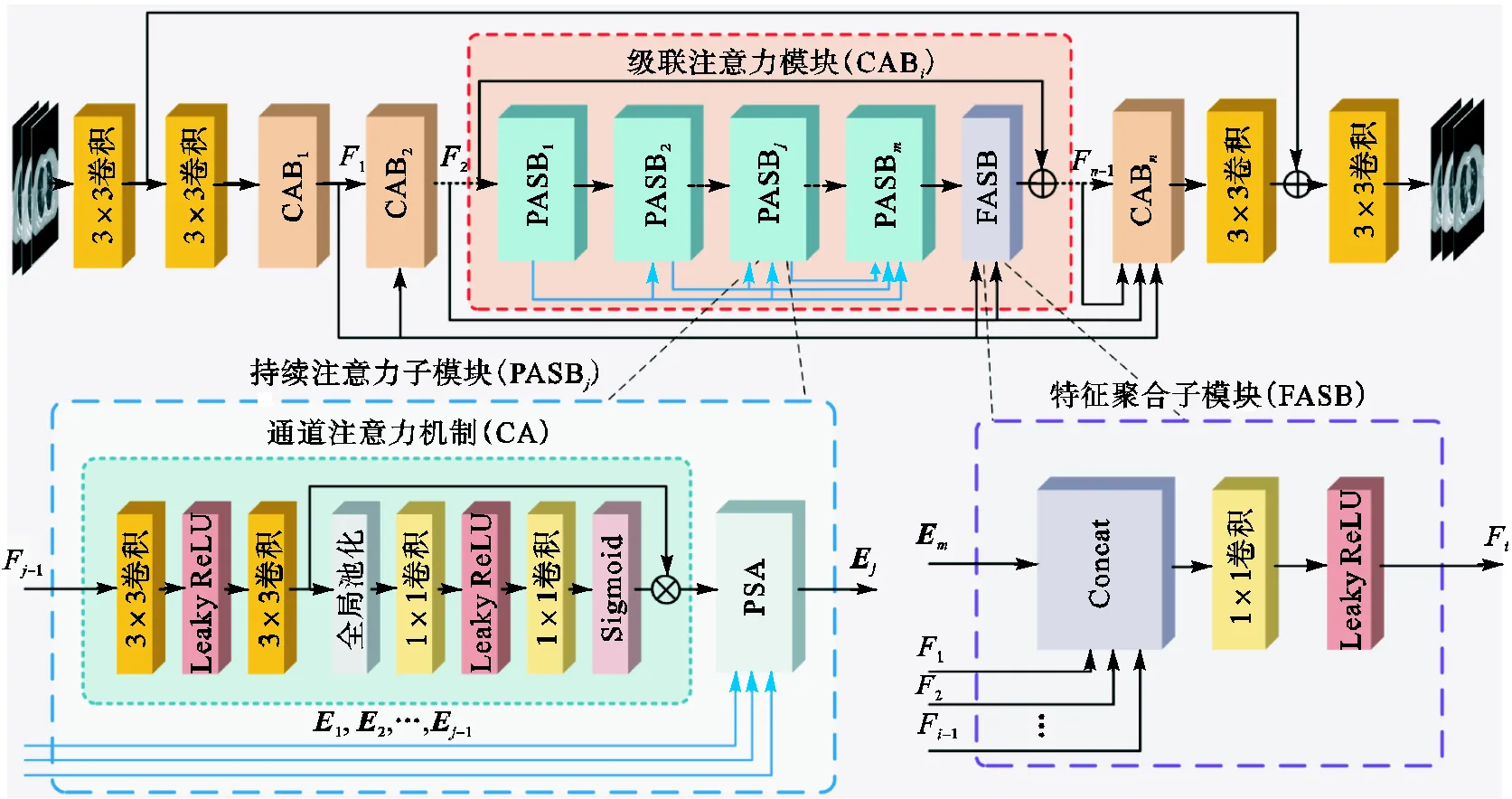
图1 基于DCPAN的低剂量能谱CT去噪方法结构
每个CAB均由个级联的持续注意力子模块(persistent attention sub-block,PASB)和1个特征聚合子模块(feature aggregation sub-block,FASB)组成,各个PASB间也采用了密集连接的方式.每个PASB主要由CA单元和PSA单元组成,输入数据经过两个3×3卷积层进行特征提取后输入至CA单元.CA单元可以在通道维度上重新校准特征数据,先通过全局平均池化层对输入数据的空间维度进行特征压缩,然后分别通过两个1×1卷积层和两个激活层生成特征权重来建立各通道间的相关性,并最终将其与输入数据相乘,从而增强或抑制不同通道的特征信息.由于能谱CT图像具有一定的能量相关性且模型输入数据为各能量区间图像堆叠而成的高维张量,CA单元可以通过调整各通道的权重更好地利用各能量区间图像噪声信息的能谱相关性,有益于提升模型的噪声抑制能力.CA单元的输出数据被输入到PSA单元中.PSA单元在直接捕捉特征图各位置间关系的过程中,通过对前级PASB的密集连接将各级特征权重与本级特征图中的空间位置关系充分融合,从而减少了高频信息的丢失.最终,第级PASB的输出数据被输入至FASB中.FASB密集连接先前各级CAB以汇集各级特征,并通过1×1卷积层和带泄露线性整流(leaky rectified linear unit,Leaky ReLU)激活层来融合这些特征,其输出与本级CAB的输入数据相加构成残差结构并输出至下级CAB中.
1.2.2 持续自注意力机制
自注意力机制通过计算特征图像各位置的加权平均值作为其中某个位置的输出响应.Non-Local神经网络[13]作为一种自注意力机制结构,将非局部运算引入网络中来建立特征信息间的远程依赖关系,从而有效地保留了图像的高频信息,这对于保留能谱CT图像复杂的细节结构和边缘特征具有很大的优势.但是在深层网络中,随着卷积层数的增多,中间卷积层的特征信息会呈现分层结构,因此在不同位置的自注意力机制嵌入空间中也存在不同的全局特征信息.应用这些信息可以使本级注意力机制在调整特征权重的同时兼顾前级子模块对特征信息的调整情况,这有益于改善网络的去噪性能并减少能谱CT图像中细节信息的丢失.因此,PSA为融合各自注意力特征的嵌入空间信息,在Non-Local神经网络结构基础上加入密集连接结构.


式中为输入的特征信息.第级PASB的PSA单元还需要融合前-1级的自注意力机制响应信息,该过程通过聚合前-1级信息并将其与本级嵌入空间特征图加和来实现,定义为
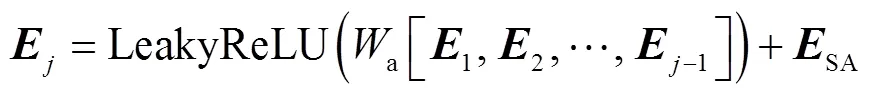
式中:1~分别为第1~级PSA输出的特征权重信息;a为1×1卷积层的权重,用于压缩这些特征信息.此外,PSA还通过另一个1×1卷积层来构建全局位置信息作为自注意力机制的值向量.第级PASB中PSA单元最终响应为

式中Wb为一个1×1卷积层用于调整数据维度以实现与输入信息xj的残差连接.
1.2.3 复合损失函数
复合损失函数可以有效地均衡各损失函数的优势,在去噪过程中,使用复合损失函数约束网络训练过程可以有效地阻止图像过于平滑,提高网络对于细节信息的敏感性,从而克服图像的细节纹理丢失问题.监督DCPAN训练的损失函数共分为1损失、特征感知损失和边缘损失3个部分.其中,1损失可以描述输出图像与标签之间的各对应像素间的差异的均值.相比于2损失,1损失具有更加稳定的梯度,可以有效防止梯度爆炸等问题,可以用公式表示为

在网络的优化过程中,仅最小化1损失会引起输出图像过于平滑,从而丢失很多用于疾病诊断的重要特征信息.特征感知损失则可以通过描述输出图像与标签在特征维度上的差异以促使输出图像与标签的特征信息更加接近,从而抑制原有细节信息的丢失.根据文献[14]中的经验,笔者使用已训练好的VGG-19网络得到输出图像与标签的特征维度数据,并使用2范数描述差异,定义为

边缘损失通过最大化输出图像与标签在梯度上的相关性系数来提高网络对边缘信息的敏感程度.将该系数加上一个非常小的参数并取倒数来保证损失函数的整体最小化,参数可以避免分母为零所造成的损失函数失效问题,其可以被表示为
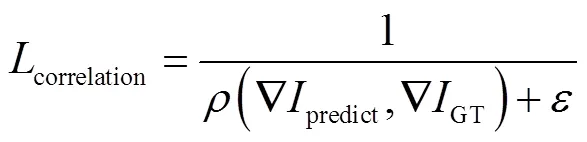
综上所述,用于训练DCPAN的复合损失函数可以表示为

式中1和2为用来平衡两部分损失的权重参数.
2 实验设置与结果分析
2.1 数据集与模型配置
2.1.1 数据集的准备
在实验中,笔者使用大量数据集来训练、验证和测试所提出网络结构.其中,杜克大学的XCAT[15]生成的体模被分为训练集、验证集和测试集3个部分.所使用体模数据来自12名不同年龄、性别、身高和体重患者.采用边缘入射型X射线探测器模型[16]模拟X射线探测过程,并由140kVp驱动的GE_Maxiray_125型球管产生X射线光子.该探测器仿真模型可以充分考虑探测过程中的散射效应,并可以模拟投影过程中的随机噪声,采用FBP算法将投影数据重建为CT图像,探测器配置参数如表1所示.
表1 边缘入射型探测器配置参数

Tab.1 Parameters setting for edge-on detector
边缘入射型探测器的能量阈值分别设置为70keV和95keV,并忽略20keV以下的光子数量,由此得到的3个能量范围分别为20~70keV、70~95keV和95~140keV.使用仿真探测器模型扫描体模分别得到了常规剂量和低剂量条件下3个能量范围的CT图像.数据集的尺寸为256×256,实验中选择其中10个体模的共1400组数据和标签进行网络的训练和验证,并随机标记其中280组作为验证集,其余1120组用于训练以抑制模型的过拟合现象.采用补丁训练策略,将输入图像和标签划分为重叠的64×64图像块,滑动间隔为32个像素,共计54880组补丁用于网络训练.使用其余2个体模的280组数据和标签测试模型性能,分别使用胸部和腹部CT切片结果对所提出方法的去噪性能和效果进行定性和定量分析,选取具有代表性的RED-CNN[9]、EDCNN[10]、InceptionNet[17]和混合高斯模型的正弦图噪声去除网络(sinogram denoising network with Gaus-sian mixture model,SDN-GMM)[18]作为对比方法.
2.1.2 网络训练及参数设置
在训练网络的过程中,每个迭代周期使用的最小批次为32,采用Adam算法优化网络的梯度更新,其中学习率设为1×10-5,指数衰减参数分别为0.5和0.99.网络中Leaky ReLU激活层的alpha系数设为0.1.网络模型基于Tensorflow框架实现,并在Intel i5-9400f CPU搭载的NVIDIA公司GeForce RTX 2080GPU上训练1000个周期,TensorFlow-GPU的版本为1.9.0,Python的版本为3.6.8.
2.2 对比实验结果分析
2.2.1 主观效果对比
在实验中,从测试数据集中分别选取了胸部和腹部切片输入至各模型,测试结果如图3和图4所示.两图中第1列分别展示了低剂量条件下3个能量区间腹部和胸部切片CT图像,第2列为常规剂量条件下3个能量区间对应切片图像,第3~7列分别展示了RED-CNN、EDCNN、InceptionNet、SDN-GMM和DCPAN的相应测试结果.为了更加直观地评估各方法的测试结果,笔者在图像中分别选取了具有更多的细节特征的感兴趣区域(region of interest,ROI),并标注为红色方框以便观察各方法测试结果的噪声与细节特征的保留程度.
从图3中可以看出,每种方法对于各能量区间下的低剂量CT图像的噪声均有一定的抑制作用.输入的低剂量CT图像具有很严重的噪声和伪影,尤其是在低能图像中严重影响了诊断过程中对病灶周边组织和结构的识别精确程度.图3(c)和图4(c)显示了RED-CNN对低剂量CT图像的处理结果,可以看出仍然带有部分残留的噪声影响视觉效果.EDCNN的测试结果如图3(d)和图4(d)所示,可以看出边缘特征提取层有益于改善边缘部分图像质量,但图像中仍有部分残留噪声,尤其是在射束硬化较为严重的胸部切片图像.使用多尺度采样的InceptionNet可以很好地保留图像的细节信息,但其边缘部位较为平滑,这说明该网络对边缘高频信息并不够敏感.图3(f)和图4(f)为SDN-GMM的测试结果,该方法因充分考虑到投影数据噪声统计分布而取得较好的效果,可以看出图中噪声含量显著降低,细节特征得到了很好的保留.图3(g)和图4(g)为DCPAN的处理结果,各重建图像边缘信息较为清晰且保留了组织细节,这有利于后续诊断过程中对病灶组织的精确观察.投影域数据难以获取使SDN-GMM通用性依然受限,DCPAN利用了更易于获取的图像数据,取得了与SDN-GMM相近的效果,具有更强的通用性和实用潜力.

图3 腹部切片不同算法去噪效果对比

图4 胸部切片不同算法去噪效果对比
笔者针对ROI标注区域来进一步对比各方法对边缘和细节信息的保留情况.在低剂量能谱CT图像中,标注区域的组织结构受到噪声信息的影响,无法准确地判断组织的清晰结构.RED-CNN的测试结果虽然抑制了图像中的噪声,但对边缘结构的显示并不清晰,尤其是图3中紫色方框和图4中蓝色方框标注区域.EDCNN和InceptionNet测试结果的边缘清晰度虽然有所提高,但对在部分细节信息的处理中出现了过于平滑的现象,不利于对体积较小的结构进行观察.SDN-GMM和DCPAN的处理结果中组织细节结构和边缘特征均得到很好的保留,具有较好的组织清晰度.
2.2.2 客观量化分析
为了进一步分析各方法的性能,采用客观评价指标峰值信噪比(peak signal to noise ratio,PSNR)、结构相似性(structural similarity,SSIM)指数和特征相似性(feature similarity,FSIM)指数来对测试结果进行量化分析,其中PSNR表示图像与背景噪声的比率,PSNR越高则说明图像中噪声含量越低;SSIM则可以描述两组图像之间的结构性差异,更高的SSIM值代表二者间更小的细节差异;FSIM通过计算图像间的特征差异来衡量不同算法在去噪过程中对特征信息的保留能力.以各测试切片所对应的标签作为客观评价指标的对比图像,各方法测试图像客观评价指标的平均结果如表2所示.
从表2中可见,相比于其他对比方法,DCPAN在PSNR、SSIM和FSIM 3种评价指标上均具备一定优势,更高的PSNR值证明了该模型相比于其他方法可以显著抑制图像的噪声,更高的SSIM值可以说明该方法在对于图像细节纹理结构的保留上具有一定优势,更高的FSIM值则可以说明该方法具有更好的图像特征保留能力.与EDCNN的测试结果相比,经DCPAN处理的图像PSNR值提高了1.67~3.28dB,SSIM值则提高了0.0010~0.0048,FSIM值提高了0.0099~0.0109.这说明相比于通过边缘特征提取层保留细节特征,DCPAN结合两种注意力机制而建立的信道和全局特征联系使其对高频特征信息更具敏感性.相较InceptionNet的测试结果,DCPAN测试结果的PSNR值提高了0.47~0.75dB,SSIM值提高了0.0012~0.0044,FSIM值则提高了0.0040~0.0091,这说明虽然多尺度采样可以改善网络性能并提高网络对于细节信息的敏感程度,但DCPAN通过在密集连接运算过程中调整各注意力特征权重对细节特征具有更佳的保留效果.DCPAN测试结果的评价指标与SDN-GMM非常接近,这说明DCPAN通过充分利用能谱CT图像特征在通道和全局维度的相关性,达到了与结合投影数据噪声模型的SDN-GMM相近的去噪水平.对于胸部切片,该部位测试结果的指标则普遍低于腹部切片,这可能是由于胸部组织结构更为复杂,且该部位胸骨、椎骨等具有较高衰减系数的组织所带来的射束硬化更为严重. DCPAN对胸部切片的处理具有最佳效果,其测试结果的PSNR值达到了36.1600dB以上,SSIM值达到了0.9921以上,FSIM值达到了0.9678以上,这 说明DCPAN具有较强的去噪性能和细节特征保留能力.
表2 不同算法腹部和胸部切片测试结果客观指标
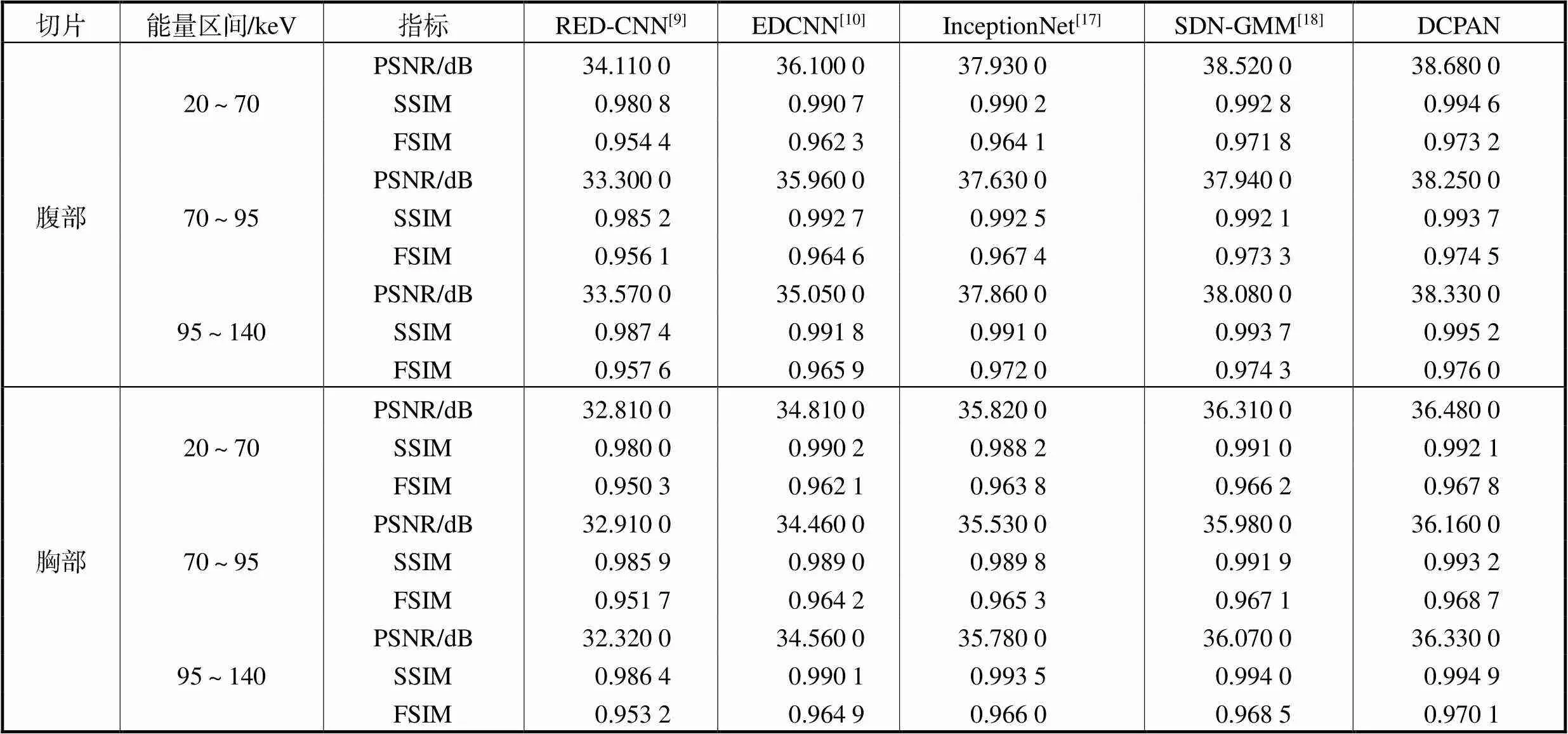
Tab.2 Evaluation index of abdominal and chest slice test results from different methods
此外,为更好评估几种方法的噪声水平,从腹部和胸部切片中选取了较为平滑的部分如图3和图4中绿色方框所示,分别标注为ROI A和ROI B,并计算了这些部分的均值和标准差(standard deviation,SD)以定量分析,计算结果如表3所示.相比于其他对比模型,DCPAN各输出图像的SD均有不同程度的降低,这种变化尤其体现在ROI B中.相比于InceptionNet,对于胸部切片的DCPAN 3个输出图像SD分别下降了15.2%、14.3%和11.1%,胸部切片的SD分别下降了1.0%、1.5%和1.4%,说明DCPAN的输出结果具有更低的噪声水平.
表3 不同算法测试结果中的均值与标准差对比

Tab.3 Comparison of the mean and standard deviation of test results from different methods
2.3 消融实验结果分析
2.3.1 不同模块的消融研究
为验证DCPAN中各模块的性能,笔者针对各模块对模型性能的影响进行了消融研究,其分析结果如表4所示.根据该表中的数据可以看出CA和PSA均有益于提升模型抑制噪声的能力,且PSA对全局特征的建模可以使得模型对高频信息更加敏感.相比于CA对信道特征的建模,PSA对去噪效果的改善程度更高,两种注意力机制相结合则可以进一步提高模型的性能.相比于只具有单种注意力机制,PSNR值提高了0.92dB以上,SSIM值提高了0.0018以上,FSIM提高了0.0061以上.此外,FASB所构建的密集连接结构通过聚合运算过程中各CAB的输出信息有效抑制了信息的丢失,网络整体与CAB中所使用的残差结构可以优化训练过程中的梯度,使模型获得更好的训练效果,两种结构的使用使得模型性能进一步改善,相比于未使用两种结构的情况,PSNR值提高了约3.58%~6.56%,SSIM值提高了约0.29%~0.69%,而FSIM提高了约0.64%~0.73%.由此可以看出,两种注意力机制结合密集连接和残差结构是所提模型的最佳方案,进一步证明其在低剂量能谱CT去噪领域的潜力.
表4 不同模块与结构下DCPAN的腹部和胸部切片测试结果客观指标
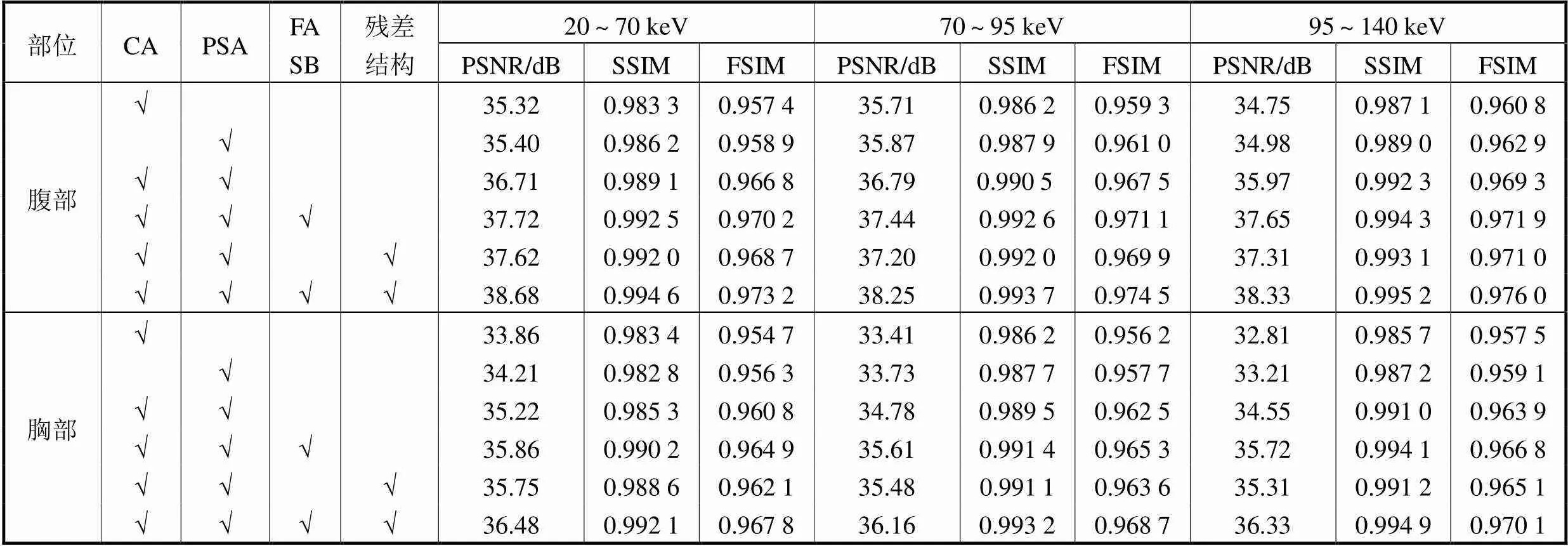
Tab.4 Evaluation index of abdomen and chest slice from DCPAN with different combination of blocks and structures
2.3.2 不同损失函数的影响
为了探究复合损失函数各部分对模型性能的改善程度,分别采用各项损失的不同组合来训练DCPAN模型,并选取腹部切片20~70keV能量区间下的测试图像中具有组织细节和边缘特征的部分作为ROI,如图5(a)红色线段标注所示,包含64个像素,将测试结果中在该部分64个像素的值,即线性衰减系数(linear attenuation coefficient,LAC),绘制为折线图进行对比,以对各损失函数组合的训练效果加以评估,对比结果如图5(b)所示.可以看到通过1损失训练的测试结果在相对平滑部位的抖动程度较少,但由于其过于平滑,边缘部位的值与标签相比产生了较大的偏差.当损失函数中加入特征感知损失后,可以看到在测试结果中,较为平滑的组织部位具有相对较小范围数值变化,这说明感知损失的加入有益于模型对细节特征信息敏感性的提升.而对于1损失与边缘损失组合所训练的模型,测试图像中边缘部位准确程度显著提升,这说明该损失组合提高了模型的边缘特征学习能力,解决了重建图像过度平滑所导致的边缘不清晰等问题.相比上述几种方案的测试结果,使用由1损失、感知损失和边缘损失构成复合损失函数来训练模型可以获得最接近标签图像的处理效果,说明损失函数中各部分优势和性能达到了均衡,证明了这种组合为最佳损失函数方案.

图5 不同损失函数下DCPAN的腹部切片衰减曲线
3 结 语
随着辐射剂量的降低,能谱CT图像内噪声含量的升高严重影响后续诊断工作中医生对病灶组织的准确观察.因此,本文提出了一种具有密集连接结构的网络模型DCPAN以改善低剂量能谱CT图像质量.该模型使用了CA和PSA两种注意力机制,通过结合空间和全局特征相关性来增强有效特征,从而使网络能够更多地关注与图像高频分量相关的特征信息.网络的密集连接结构通过特征复用有效地减少了图像特征压缩产生的信息丢失.监督网络训练的复合损失函数均衡了各损失函数的优势,其中1损失保证了输出图像与标签之间的逐像素对应关系,感知损失抑制了图像过于平滑导致的细节信息丢失,边缘损失则进一步改善了网络对边缘信息的敏感性.实验结果表明:DCPAN输出的低噪声图像具有较为清晰的边缘特征和更低的噪声水平,主观效果和客观指标均优于其他对比方法,证明该方法能够实现低剂量能谱CT图像的高质量重建,具有一定的实际应用潜力.在未来的工作中,使用来自更多的CT系统成像数据来训练所提出的网络模型可以进一步增强其实用性和泛化能力.
[1] Wang J,Li T F,Lu H B,et al. Penalized weighted least-squares approach to sinogram noise reduction and image reconstruction for low-dose X-ray computed tomography[J]. IEEE Transactions on Medical Imaging,2006,25(10):1272-1283.
[2] Xie Q,Zeng D,Zhao Q,et al. Robust low-dose CT sinogram preprocessing via exploiting noise-generating mechanism[J]. IEEE Transactions on Medical Imaging,2017,36(12):2487-2498.
[3] Liu Y,Ma J H,Fan Y,et al. Adaptive-weighted total variation minimization for sparse data toward low-dose X-ray computed tomography image reconstruction[J]. Physics in Medicine & Biology,2012,57(23):7923-7956.
[4] Yang C,Yin X D,Shi L Y,et al. Improving abdomen tumor low-dose CT images using a fast dictionary learning based processing[J]. Physics in Medicine & Biology,2013,58(16):5803-5820.
[5] Fumene F P,Vinegoni C,Gros J,et al. Block matching 3D random noise filtering for absorption optical projection tomography[J]. Physics in Medicine & Biology,2010,55(18):5401-5415.
[6] Wu W,Yu H,Chen P,et al. Dictionary learning based image-domain material decomposition for spectral CT[J]. Physics in Medicine and Biology,2020,65(24):245006.
[7] Liu Y,Wang J,Chen X,et al. A robust and fast non-local means algorithm for image denoising[J]. Journal of Computer Science and Technology,2008,23(2):270-279.
[8] Kang E,Min J,Ye J C. A deep convolutional neural network using directional wavelets for low-dose X-ray CT reconstruction[J]. Medical Physics,2017,44(10):e360-e375.
[9] Chen H,Zhang Y,Kalra M K,et al. Low-dose CT with a residual encoder-decoder convolutional neural network(RED-CNN)[J]. IEEE Transactions on Medical Imaging,2017,36(12):2524-2535.
[10] Liang T F,Jin Y,Li Y D,et al. EDCNN:Edge en-hancement-based densely connected network with com-pound loss for low-dose CT denoising[C]//International Conference on Signal Processing. Beijing,China,2020:193-198.
[11] Zhang Y L,Li K P,Li K,et al. Image super-resolution using very deep residual channel attention networks[C]// Lecture Notes in Computer Science. Munich,Germany,2018:286-301.
[12] Wang Y,Song X,Chen K. Channel and space attention neural network for image denoising[J]. IEEE Signal Progressing Letters,2021,28:424-428.
[13] Wang X L,Girshick R,Gupta A,et al. Non-local neural networks[C]//IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City,USA,2018:7794-7803.
[14] Yang Q,Yan P,Zhang Y,et al. Low-dose CT image denoising using a generative adversarial network with Wasserstein distance and perceptual loss[J]. IEEE Trans-actions on Medical Imaging,2018,37(6):1348-1357.
[15] Segars W P,Sturgeon G,Mendonca S,et al. 4D XCAT phantom for multimodality imaging research[J]. Medical Physics,2010,37(9):4902-4915.
[16] Shi Z,Yang H,Cong W,et al. An edge-on charge-transfer design for energy-resolved X-ray detection[J]. Physics in Medicine and Biology,2016,61(11):4183-4200.
[17] Zhang J,Zhou H L,Niu Y,et al. CNN and multi-feature extraction based denoising of CT images[J]. Quantitative Imaging in Medicine and Surgery,2021,67:102545.
[18] 史再峰,李慧龙,程 明,等. 基于SDN-GMM网络的低剂量双能CT投影数据去噪方法[J]. 天津大学学报(自然科学与工程技术版),2021,54(9):899-906.
Shi Zaifeng,Li Huilong,Cheng Ming,et al. A projection data denoising method based on SDN-GMM network for low-dose dual-energy computed tomography[J]. Journal of Tianjin University(Science and Technology),2021,54(9):899-906(in Chinese).
Low Dose Spectral Computed Tomography Image-Based Denoising Method via DCPAN
Shi Zaifeng1, 2,Cheng Ming1,Ouyang Shunxin1,Kong Fanning1,Qi Junyu1,Tian Ying3
(1. School of Microelectronics,Tianjin University,Tianjin 300072,China;2. Tianjin Key Laboratory of Imaging and Sensing Microelectronic Technology,Tianjin 300072,China;3. Tianjin Renai College,Tianjin 301636,China)
Spectral computed tomography(CT)has good energy resolution,which makes it more accurate to identify tissue components and provides more precise detection information for subsequent diagnosis. As low dose require-ments increase,the noise in spectral CT images improves significantly,affecting imaging quality and reducing reso-lution accuracy. Although the denoising model based on a convolutional neural network(CNN)can reduce the noise level,with the increase of layers,the denoised images from deeper neural networks often have less high-frequency information. To solve this problem,the densely connected persistent attention network (DCPAN)is proposed in this paper,which adopts the channel attention mechanism(CA)and the persistent self-attention mechanism(PSA),establishing the correlation of feature maps in the channel and global dimensions to improve the sensitivity of the network to the high-frequency components and thus suppress the loss of high-frequency information. The adopted densely connected structure realizes the retention of high-frequency information in feedforward propagation through feature multiplexing. During the period of training,a hybrid loss function is deployed to make the model more sensitive to edge and detailed information. The experimental results show that the peak signal to noise ratio,structural similarity,and feature similarity of abdomen slices are over 38.25dB,0.9937,and 0.9732. Compared with the current advanced methods,the method has a better denoising effect,and the tissue structure in the denoised images is clearer,giving a more accurate reference for the following diagnosis.
spectral computed tomography;low dose;convolutional neural network(CNN);attention mechanism
10.11784/tdxbz202202012
TP391.4
A
0493-2137(2023)02-0184-09
2022-02-19;
2022-05-03.
史再峰(1977— ),男,博士,副教授.
史再峰,shizaifeng@tju.edu.cn.
国家自然科学基金资助项目(62071326)
Supported by the National Natural Science Foundation of China(No. 62071326).
(责任编辑:孙立华)
