基于自监督学习的文本行人检索
2023-02-15胡峻华丁学文李晟嘉
冀 中,胡峻华,丁学文,李晟嘉
基于自监督学习的文本行人检索
冀 中1,胡峻华1,丁学文2,李晟嘉3
(1. 天津大学电气自动化与信息工程学院,天津 300072;2. 天津职业技术师范大学电子工程学院,天津 300222;3. 中国运载火箭技术研究院研究发展部,北京 100076)
基于文本的行人检索任务旨在以文本为查询在大规模数据库中检索出目标行人的图像,在处理社会公共安全问题中具有较高的实用价值.不同于常规的跨模态检索任务,该任务中所有的类别都是行人,不同行人之间的外观差异较小,难以辨别;此外由于拍摄条件的限制图像质量通常较差,因此如何有效地提取更鲁棒、更具有判别性的视觉特征是该任务的一项重要挑战.为了应对这一挑战,设计了一种基于自监督学习的文本行人检索算法,以多任务学习的形式将自监督学习与基于文本的行人检索任务相结合,对两种任务同时进行训练,共享模型参数.其中,自监督任务作为辅助任务,旨在为行人检索任务学习到更鲁棒、更具有判别性的视觉特征.具体来说,首先提取视觉和文本特征,并以图像修复作为自监督任务,旨在学习更丰富的语义信息,且对遮挡数据具有更好的鲁棒性;基于行人图像的特殊性,进一步设计了一种镜像翻转预测任务,通过训练网络预测图像是否经过了镜像翻转学习具有判别性的细节信息,以帮助行人检索任务更好地区分难分样本.在公开数据集上进行的大量实验证明了该算法的先进性和有效性,将行人检索的Top-1准确率提升了2.77%,并且实验结果显示两种自监督任务存在一定的互补性,同时使用可以实现更好的检索性能.
行人检索;跨模态分析;自监督学习;多任务学习
随着经济社会的迅速发展,人们对于公共安全问题愈发重视,监控摄像头逐渐遍布大街小巷,寻找走失的儿童、追踪犯罪嫌疑人等都离不开监控设备的辅助.但是与此同时,海量的监控设备也产生了海量的数据,想要从如此庞大的数据库中找到目标往往需要耗费巨大的人力资源.近年来,深度学习技术在处理大数据问题中发挥了重要的作用[1],在这种背景下,基于文本查询的行人检索(text-based person search,TBPS)技术应运而生,该技术运用深度学习技术,旨在以自然语言作为查询,快速、准确地从海量的监控数据中检索到目标人物[2].TBPS可以利用目击者的口头描述,口头描述相比目标人物的图像更加容易获得[3],其行人属性更加灵活、自由[4],具有更强的描述能力.因此TBPS更加符合现实应用场景,具有更高的实用价值.
由于文本和图像数据属于不同的模态,因此TBPS属于一种跨模态任务.与常规跨模态任务不同,该任务中所有的类别都是行人,他们具有大致相似的外观特征,更加难以辨别.此外,由于现实中很多图像是从相当远的距离拍摄的,并且可能存在遮挡、光线不足等问题,因此该任务中的图像质量较差.基于以上困难,为了更好地区分相似的目标,需要模型学习到足够多的细节信息,并具有较强的鲁棒性.在现有的研究中,大多数方法更关注如何对齐视觉和文本两个模态的数据[5-7],对于如何提取更鲁棒、更具有判别性的特征则关注较少.
自监督学习是一种不依赖人工标注而是从数据本身学习表征的方法.事实上,相比于标注信息,数据本身包含着更丰富的信息,通过设计不同的自监督任务可以从数据中挖掘到不同的内容表征.目前已有很多研究使用自监督学习方法来学习视觉表征[8-9],并取得了很好的效果.
为了在TBPS中学习到更加鲁棒、更具有判别性的视觉特征,本文以多任务学习的形式将TBPS与自监督任务相结合,以行人检索作为主任务,自监督学习作为辅助任务,通过完成自监督任务学习到对行人检索有帮助的特征信息.这主要有两个挑战.第一,需要根据目标任务选择与其相适配的自监督学习方法.因为一些在其他视觉任务上有良好表现的方法并不一定也适合行人检索任务.例如图像旋转角度预测任务[10],由于所有行人都是站立状态,且身体部位的相对位置固定,所以很难通过判断旋转角度这一任务学习到有用的信息.第二,需要合理地控制自监督任务的难度.尽管采用多任务学习的形式,但是本文主要关注行人检索任务的性能,并不关注自监督任务的性能.作为辅助任务,自监督任务的意义只在于在完成它的过程中学习对主任务有帮助的信息.当自监督任务难度过高时,一方面可能难以完成,自然也就无法学习到有价值的信息;另一方面,即便能够顺利完成,也可能使网络过多地关注了自监督任务,学习到更多与自监督任务相关但与行人检索任务无关的信息,从而对行人检索任务造成干扰.反之,网络不需要学习过多的信息就可以轻松完成任务,该任务的存在也就失去了意义.因此需要控制自监督任务的难度,以达到在不干扰行人检索任务的情况下学习到对行人检索任务有帮助的信息.
本文的贡献主要体现在如下两个方面.首先,以Transformer模型作为视觉和文本特征提取网络,提出一种基于自监督学习的多任务学习框架.其中,选取自监督学习中的图像修复作为辅助任务,与行人检索任务同时训练,共享模型参数,旨在学习更丰富的语义信息,且针对遮挡数据具有更好的鲁棒性.其次,进一步设计了一种与行人检索任务相契合的镜像翻转预测作为自监督辅助任务,通过训练网络判断图像是否经过了镜像翻转学习具有判别性的细节信息.通过在公开数据集上设计的大量实验验证了所提方法的有效性,并且实验结果进一步显示这两种自监督任务存在一定的互补性.
1 相关领域研究现状
1.1 基于文本的行人检索
基于文本的行人检索任务自提出以来已经吸引众多研究者的关注[5-7].对于这一细粒度跨模态检索任务,大多数方法[2,5-6,11-12]使用通用的卷积神经网络和循环神经网络分别提取视觉特征和文本特征.例如,Li等[2]以VGG-16和长短时记忆网络作为特征提取器设计了一个带有门控神经注意机制的模型;Gao等[13]基于ResNet-50和BERT设计了一种自适应全尺度对齐模型;在近期的一项工作中,Li等[14]提出了一种基于Transformer的多粒度对齐模型.总体而言,随着通用网络模型的不断改进,这一任务的整体性能也在不断提升,但是行人检索任务由于细粒度问题和图像质量问题对于视觉特征提取的要求较高,仍需要进一步地针对该任务设计更好的视觉特征提取网络.为此,本文针对行人数据的特点设计了一种基于自监督学习的视觉特征提取网络,旨在获得更鲁棒、更具有判别性的视觉特征.
1.2 自监督学习
自监督学习是一种不依赖于人工标注的学习方式,旨在通过设计特定的任务以从数据本身学习到相应的知识[8,10].目前已经有多种自监督学习方法在视觉表征方面取得了出色的效果.例如,Komodakis等[10]通过训练网络预测图像的旋转角度迫使网络理解图像内容;Noroozi等[15]设计了一种拼图游戏,将图像划分成若干个小块并标记序号,按照某些特定的顺序将其打乱后再训练网络预测当前输入的是哪一个序列,要完成好这一任务,需要网络学习到图像的结构信息.此外,常见的自监督任务还包括图像修复[16]、图像上色[17]、超分辨率[18]等.这些自监督任务通常作为辅助任务,旨在训练得到一个特征提取网络进而用于目标任务.对于不同的目标任务需要选择与之契合的自监督任务,因此本文基于行人数据的特殊性设计了一种镜像翻转预测任务,旨在从图像中学习区分性的细节信息.
2 基于自监督学习的文本行人检索算法
为了在基于文本的行人检索任务中获得更鲁棒、更具有判别性的视觉特征,本文设计了一种基于自监督学习的文本行人检索算法(self-supervised learning approach for text-based person search,SSL-TBPS).由于TBPS是一个细粒度检索任务,并且该任务中的图像质量通常较差,句子结构复杂,因此对于网络的特征提取能力要求较高.本文使用具有较强特征提取能力的Swin Transformer[19]和BERT[20]分别作为基本的视觉和文本特征提取网络,并设计了一种多任务学习模型,将自监督学习中的图像修复任务与行人检索任务相结合,进一步地设计了一种更适合行人检索任务的辅助任务,即镜像翻转预测任务.
2.1 特征提取
1) 视觉特征提取
2) 文本特征提取

2.2 基于图像修复任务的文本行人检索
在基于文本的行人检索任务的实际应用中,经常会存在行人被遮挡的情况,为了在学习语义信息的同时更好地应对遮挡情况,本文首先选择图像修复作为自监督任务,将其与TBPS相结合.具体来说,受MAE模型启发[16],本文首先选取一定比例的图像块进行随机掩蔽,然后将掩蔽后剩余的可见部分重新输入到网络中,提取视觉特征,最后再由解码器根据视觉特征和掩码标记恢复出被掩蔽的部分.
基于图像修复任务的文本行人检索算法(记为SSL-TBPS-I)的网络结构如图1所示,由基于文本的行人检索和自监督学习两部分组成.在基于文本的行人检索部分,使用Swin Transformer和BERT分别提取图像嵌入和文本嵌入,其中Swin Transformer包括4个阶段的网络[19].然后使用跨模态投影分类损失(记为CMPC)和跨模态投影匹配损失(记为CMPM)[5]对齐两种模态.在自监督学习部分,对基于文本的行人检索部分中Swin Transformer第1阶段网络输出的28×28个图像块进行随机掩蔽,并经过编码器和解码器恢复出被掩蔽的部分.如前文所述,该算法需要较好地控制自监督任务的难度,直接对Swin Transformer输入的56×56个图像块进行随机掩蔽会使任务难度较高,且计算复杂.由于Swin Transformer会随着网络的加深不断地合并相邻的图像块,即在每个阶段的网络之间将相邻的4个图像块合并为一个,因此笔者选择对第1阶段网络之后的28×28个图像块进行随机掩蔽.具体来说,随机掩蔽这些图像块的75%,这将使剩余的14×14个图像块在数目上刚好满足第3阶段的网络,因此将剩余的可见部分重新输入到第3阶段的网络中,以第3阶段和第4阶段的网络作为编码器.解码器使用了包含4个Transformer Block的轻量级网络,并在最后加入一层线性投影,其输出通道数等于每个掩蔽图像块的像素值数,通过预测每个掩蔽图像块的像素值来重建输入.均方差损失(mean squared error,MSE)用来度量重建结果与原始输入间的误差,即

式中:表示原始输入值;表示重建预测值;表示被掩蔽的图像块数目.
2.3 基于镜像翻转预测任务的文本行人检索
本文进一步设计了一种新的自监督任务,通过预测图像是否经过镜像翻转来学习图像中的细节信息.其动机是笔者注意到行人图像是近似左右对称的,这使得经过水平镜像翻转后的图像与原始图像的差异并不大,因此需要学习到一些细节的位置信息才能准确地判断图像是否经过了镜像翻转.例如,经过翻转之后手提包从图像的左侧到了图像的右侧,只有网络学习到了这种类似的细节信息才可以准确地分辨这种细微差异.而这种细节的位置信息,对于行人检索任务有较大的帮助.例如文本描述提到“左手拎着一个手提包”,如果网络中没有学习到这种细节位置信息,而数据集中恰好存在一个右手拎着手提包的人,就很可能发生错误地匹配,检索出一个很相似但是错误的结果.
如图2所示,基于镜像翻转预测任务的文本行人检索算法(记为SSL-TBPS-M)的网络结构分为两部分:第1部分是基于文本的行人检索任务,通过Swin Transformer和BERT提取视觉嵌入和文本嵌入,然后通过优化损失函数对两种模态的嵌入进行对齐;第2部分是本文设计的镜像翻转预测任务,通过对原始图像进行镜像翻转得到新的图像,然后将原始图像和翻转后的图像都输入特征提取网络,通过分类器预测输入的图像是否经过了镜像翻转.这两部分共享视觉特征提取网络的参数.
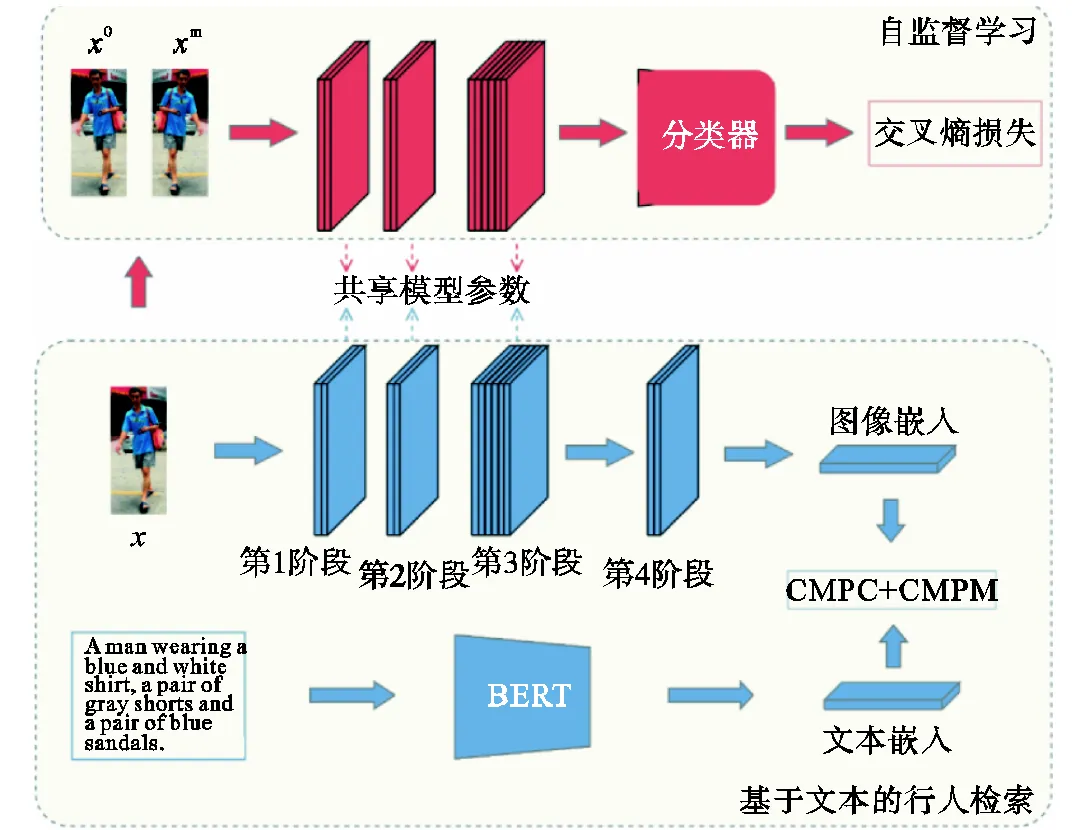
图2 基于镜像翻转预测任务的文本行人检索网络结构

2.4 目标函数
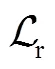
本文以多任务学习的形式同时优化行人检索与自监督任务的目标函数,但是由于本文的主要目的是实现更好的检索性能而并不关注自监督任务的完成情况,因此需要通过目标函数来调节不同任务的权重,其公式为

式中、、分别表示3种损失函数的权重系数.
3 实 验
3.1 数据集和评价指标
CUHK-PEDES是基于文本的行人检索领域目前唯一的大型公共数据集[2],本文在该数据集上对提出的算法进行评估.CUHK-PEDES数据集共包括13003个行人的40206张图像,每张图像对应两句文本描述,即共有80412个句子.相比一般的跨模态检索数据集,CUHK-PEDES中所有的类别都是行人,且图像质量更差,包含很多低分辨率和弱光线的图像,且平均每个句子含23.5个单词,也远多于一般跨模态检索数据集,这使得提取有区分性的视觉和文本特征更加具有挑战性.
为了保证实验的公平性,本文中对CUHK-PEDES数据集采用通用的划分方式[2].即将数据集划分成训练集、验证集和测试集,其中训练集包含11003个行人的34054张图像和68108个句子,验证集包含1000个行人的3078张图像和6156个句子,测试集包含1000个行人的3074张图像和6148个句子.
本文选择Top-准确率作为检索结果的评价指标.即在测试阶段中,给定一个查询文本,测试集中的所有图像根据与查询文本的相似度进行排序,如果排序后的前个结果中包含了目标图像则视为检索成功,检索成功次数与总检索次数的比值即为Top-准确率.
3.2 实验设置
Swin Transformer的4个阶段网络分别包括2、2、6和2个Transformer Block,将输入图像划分成尺寸为4×4的图像块,4个阶段网络中图像分别被划分为56×56、28×28、14×14、7×7个图像块.本文所使用的Swin Transformer预训练模型是由Liu等[19]在ImageNet-1K数据集(包含1000个类,128×104张图像)上训练300个epoch得到的.文本特征提取器选择在CUHK-PEDES数据集上训练过的BERT并冻结网络参数[13].视觉特征和文本特征的维度都设置为768.对于所有实验,都使用AdamW优化器[21]训练30个周期.初始学习率设置为8×10–5,最小学习率为8×10–7,并使用余弦退火学习率衰减策略和5个周期的热启动,根据经验设置为4.
3.3 性能评价与分析
笔者选取了11种较为先进且具有代表性的基于文本的行人检索方法与本文方法进行了性能对比,如表1所示.
表1 算法性能对比

Tab.1 Algorithm performance comparison %
按照所用视觉特征提取器的不同将这些方法分成3类,即基于VGG-16的方法、基于ResNet-50的方法和基于Transformer的方法.观察实验结果发现基于VGG-16的方法在性能上相对落后,这是由于VGG-16的特征提取能力有限,不能很好地从质量较差的行人图像中提取到判别性信息.基于ResNet-50的方法在性能上则要明显优于VGG-16,目前大部分方法仍是使用ResNet-50作为视觉特征提取器.由于Transformer在视觉领域的应用从近两年才刚刚兴起,因此基于Transformer的文本行人检索方法目前较少,但是已经展现了出色的性能.与上述方法相比,本文方法在各项指标上都实现了最佳的检索性能,将Top-1、Top-5、Top-10和总计指标分别提升了2.77%、0.88%、0.05%和3.99%.Top-1准确率的明显提升表明本文方法对于难分样本具有更好的区分效果,可以从多个相似的样本中检索出正确结果.
1)基于图像修复与镜像翻转预测任务的文本行人检索
本文进一步探究了使用不同的自监督任务对于行人检索性能的影响,如表2所示,当=0且=0时表示不使用自监督任务,即基线方法;仅=0时表示仅使用图像修复任务,记为SSL-TBPS-I;仅=0时表示仅使用镜像翻转预测任务,记为SSL-TBPS-M;二者均不为0时表示同时使用两种自监督任务,记为SSL-TBPS.
表2 自监督任务对性能的影响

Tab.2 Impacts of different self-supervised tasks on the performance %
观察表2实验结果,当同时使用两种自监督任务时,各项指标都达到了最佳,这表明图像修复任务与镜像翻转预测任务之间存在一定的互补性.即图像修复任务可以学习到更丰富的语义信息,镜像翻转预测任务可以学习到具有判别性的细节信息从而帮助区分难分样本.
进一步观察表2发现,在每组实验中和的具体取值都对实验性能有着明显的影响,即调节主任务与辅助任务之间的权重配比会影响主任务的性能.这是由于主任务与辅助任务既存在着相关信息也包含无关信息,所提方法在本质上就是要学习到更多对完成主任务有帮助的相关信息,尽可能少地学习到无关信息.当辅助任务权重过低时,辅助任务难以完成,自然无法学习到足够多的相关信息;而权重过高时模型就会倾注更多的“精力”去完成辅助任务,导致学习到更多的无关信息,对主任务造成干扰.
2)基于图像修复任务的文本行人检索
当使用图像修复任务时,相对于不使用任何自监督学习方法,总性能可以提升3.79%,这证明了自监督方法的有效性.
本文进一步探究了当面对遮挡数据时,基于图像修复任务的算法有何表现.通过对数据集的观察,笔者发现其中的遮挡数据相对较少,但是在实际的行人检索任务中遮挡情况却不可避免.因此为了更好地探究算法在面对遮挡数据时的表现,需要对测试集的数据进行一定的处理.具体来说,本文对测试集的图像进行随机擦除,擦除的概率为50%,擦除部分的面积为2%~30%的随机值,长宽比为0.3~3.3的随机值.笔者选取了两种具有代表性的开源算法[5]同本文基于图像修复任务的方法一起分别在原始测试集和处理后的测试集上进行测试,比较面对正常数据与遮挡数据时的性能差值.为了使对比更加直观,仅比较Top-1准确率,结果显示在表3中(此处对比算法的性能为笔者复现性能).
通过表3中的结果发现,对测试集进行一定程度的遮挡处理后,基于图像修复任务的方法性能下降4.34%,要明显低于NAFS的下降幅度.CMPM+CMPC方法尽管性能下降的绝对幅度不大,但是由于其初始性能较低,从比例来考虑其下降幅度也远大于基于图像修复任务的方法.由此可见,基于图像修复任务的方法对于处理行人检索任务中的遮挡情况具有一定的优势.
笔者还探究了选择不同阶段的图像块进行随机掩蔽对行人检索性能的影响,包括Swin Transformer原始输入的56×56个图像块,第1阶段网络输出的28×28个图像块以及第2阶段网络输出的14×14个图像块,如表4所示.当选择对56×56个图像块进行随机掩蔽时,实验耗时较长,模型体积较大,且性能不佳,这是由于此时图像修复任务过于复杂,使得网络过多地关注了图像修复任务,反而降低了行人检索的准确率;当选择对14×14个图像块进行随机掩蔽时,行人检索性能有较小提升,这是由于此时图像修复任务较为简单,在完成该任务的过程中学习到的知识也相对较少,因此对于行人检索任务的提升有限;当选择对28×28个图像块进行随机掩蔽时,相比另外两种设置取得了更好的效果,此时图像修复任务的难度较为合适,可以在完成该任务的过程中学习到更多与行人检索任务相关的信息.
表3 不同算法面对遮挡数据的鲁棒性对比

Tab.3 Robustness comparison of different algorithms against occlusion data %
表4 掩蔽不同图像对检索性能的影响

Tab.4 Impacts of masking different images on the re-trieval performance %
3)基于镜像翻转预测任务的文本行人检索
从表2中进一步观察可知,当使用镜像翻转预测任务时,相比于不使用任何自监督学习方法,Top-1准确率可以提升1.92%,证明这一简单的任务同样有很好的效果.进一步地对比基于镜像翻转预测的方法与基于图像修复的方法,可发现基于图像修复的方法在Top-5和Top-10两项指标上要优于基于镜像翻转预测的方法,而基于镜像翻转预测的方法在Top-1准确率上则更有优势.这一结果表明,图像修复任务可以学习到更丰富的语义信息,而镜像翻转预测任务可以更好地学习到具有判别性的细节信息,更有助于区分行人检索中的难分样本.
表5展示了基于镜像翻转预测任务的文本行人检索算法中在Swin Transformer网络的不同位置接入分类器对行人检索性能的影响.结果表明,在第3阶段的网络之后连接分类器会取得更好的检索性能.笔者分析这是由于深层的网络会学习到具体的语义信息,即针对不同的任务学习到的信息差异较大.因此若分类器连接在深层网络会使得整个网络对于辅助任务和主任务无法兼顾,导致辅助任务无法完成或是主任务被干扰.而稍浅层的网络学习到的特征会更为通用,包含着不同任务所共同需要的信息,具有更好的泛化性能.
表5 分类器位置对检索性能的影响

Tab.5 Impacts of the classifier position on the retrieval performance %
4)基于其他自监督任务的文本行人检索
除图像修复任务与镜像翻转预测任务外,本文探索了另外两种自监督任务与行人检索任务相结合的效果,即图像旋转角度预测任务[10]与拼图任务[15],实验结果展示在表6中.结果显示,这两种自监督任务并未带来行人检索性能的提升,这可能是由于它们与行人检索任务的相关性较弱,因此同时训练反而使得模型学习到了较多的无关知识,不能专注于行人检索任务.由此可见,设计自监督任务时需要结合行人检索任务的特点,充分考虑自监督任务与行人检索任务的相关性.
表6 不同自监督任务对检索性能的影响

Tab.6 Impacts of different self-supervised tasks on re-trieval performance %
4 结 语
为了在基于文本的行人检索任务中提取更鲁棒、更具有判别性的视觉表示,本文设计了一种基于自监督学习的算法,以自监督任务作为辅助任务从而学习对于行人检索任务有帮助的信息.本文首先以图像修复作为辅助任务,学习到了更丰富的语义信息,且面对遮挡数据展现了较好的鲁棒性.然后进一步设计了一种镜像翻转预测任务,为行人检索任务学习更具有判别性的细节信息.在公共数据集CUHK-PEDES上进行的大量实验证明了这两种任务的有效性,并且两种任务展示了一定的互补性,同时使用时实现了更好的检索效果.
[1] 庞彦伟,尚楚博,何宇清. 基于尺度不变特征和位置先验的行人检测算法[J]. 天津大学学报(自然科学与工程技术版),2017,50(9):946-952.
Pang Yanwei,Shang Chubo,He Yuqing. Pedestrian detection algorithm based on scale invariant features and prior position information[J]. Journal of Tianjin University(Science and Technology),2017,50(9):946-952(in Chinese).
[2] Li S,Xiao T,Li H S,et al. Person search with natural language description[C]// IEEE Conference on Computer Vision and Pattern Recognition. Honolulu,USA,2017:5187-5196.
[3] Wu L,Hong R C,Wang Y,et al. Cross-entropy adversarial view adaptation for person re-identification[J]. IEEE Transactions on Circuits and Systems for Video Technology,2019,30(7):2081-2092.
[4] Ji Z,He E L,Wang H R,et al. Image-attribute reciprocally guided attention network for pedestrian attribute recognition[J]. Pattern Recognition Letters,2019,120:89-95.
[5] Zhang Y,Lu H C. Deep cross-modal projection learning for image-text matching[C]// European Conference on Computer Vision. Munich,Germany,2018:707-723.
[6] Jing Y,Si C Y,Wang J B,et al. Pose-guided multi-granularity attention network for text-based person search [C]// AAAI Conference on Artificial Intelligence. New York,USA,2020:11189-11196.
[7] Niu K,Huang Y,Ouyang W L,et al. Improving description-based person re-identification by multi-granularity image-text alignments[J]. IEEE Transactions on Image Processing,2020,29:5542-5556.
[8] Chen T,Kornblith S,Norouzi M,et al. A simple framework for contrastive learning of visual representations[C]// International Conference on Machine Learning. Addis Ababa,Ethiopia,2020:1597-1607.
[9] Su J C,Maji S,Hariharan B. When does self-supervision improve few-shot learning?[C]// European Conference on Computer Vision. Glasgow,UK,2020:645-666.
[10] Komodakis N,Gidaris S. Unsupervised representation learning by predicting image rotations[C]// International Conference on Learning Representations. Vancouver,Canada,2018:1-16.
[11] Ji Z,Li S J,Pang Y W. Fusion-attention network for person search with free-form natural language[J]. Pattern Recognition Letters,2018,116:205-211.
[12] Ji Z,Li S J. Multimodal alignment and attention-based person search via natural language description[J]. IEEE Internet of Things Journal,2020,7(11):11147-11156.
[13] Gao C Y,Cai G Y,Jiang X Y,et al. Contextual non-local alignment over full-scale representation for text-based person search[EB/OL]. http://arxiv.org/abs/2101. 03036,2021-01-21.
[14] Li H,Xiao J M,Sun M J,et al. Transformer based language-person search with multiple region slicing[J]. IEEE Transactions on Circuits and Systems for Video Technology,2021,32(3):1624-1633.
[15] Noroozi M,Favaro P. Unsupervised learning of visual representations by solving jigsaw puzzles[C]// European Conference on Computer Vision. Amsterdam,The Netherlands,2016:69-84.
[16] He K M,Chen X L,Xie S N,et al. Masked autoencoders are scalable vision learners[EB/OL]. http://arxiv. org/abs/2111. 06377,2021-11-11.
[17] Zhang R,Isola P,Efros A A. Colorful image colorization[C]//European Conference on Computer Vision. Amsterdam,the Netherlands,2016:649-666.
[18] Ledig C,Theis L,Huszár F,et al. Photo-realistic single image super-resolution using a generative adversarial network[C]// IEEE Conference on Computer Vision and Pattern Recognition. Honolulu,USA,2017:4681-4690.
[19] Liu Z,Lin Y T,Cao Y,et al. Swin transformer:Hierarchical vision transformer using shifted windows[C]// IEEE International Conference on Computer Vision. Montreal,Canada,2021:9992-10002.
[20] Devlin J,Chang M W,Lee K,et al. Bert:Pre-training of deep bidirectional transformers for language understanding[C]// North American Chapter of the Association for Computational Linguistics:Human Language Technologies. Minneapolis,USA,2019:4171-4186.
[21] Kingma D P,Ba J. Adam:A method for stochastic optimization[C]// International Conference on Learning Representations. San Diego,USA,2015:1-15.
[22] Chen T L,Xu C L,Luo J B. Improving text-based person search by spatial matching and adaptive threshold[C]// IEEE Winter Conference on Applications of Computer Vision. Lake Tahoe,USA,2018:1879-1887.
[23] Chen Y C,Huang R,Chang H,et al. Cross-modal knowledge adaptation for language-based person search [J]. IEEE Transactions on Image Processing,2021,30:4057-4069.
[24] Zhu A C,Wang Z J,Li Y F,et al. DSSL:Deep surroundings-person separation learning for text-based person retrieval[C]// ACM International Conference on Multimedia. Chengdu,China,2021:209-217.
[25] Wang C J,Luo Z M,Lin Y J,et al. Text-based person search via multi-granularity embedding learning[C]// International Joint Conference on Artificial Intelligence. Montreal,Canada,2021:1068-1074.
A Self-Supervised Learning Approach for Text-Based Person Search
Ji Zhong1,Hu Junhua1,Ding Xuewen2,Li Shengjia3
(1. School of Electrical and Information Engineering,Tianjin University,Tianjin 300072,China;2. School of Electronic Engineering,Tianjin University of Technology and Education,Tianjin 300222,China;3. R&D Department,China Academy of Launch Vehicle Technology,Beijing 100076,China)
The text-based person search task aims at retrieving images of target pedestrians in a large-scale database with text as a query,which is highly practical in social and public safety. In contrast with the conventional crossmodal retrieval task,all categories in this task are pedestrians. However,the slight appearance difference among different pedestrians makes it difficult to discriminate,and poor shooting conditions cause the production of bad image quality. Therefore,the effective extraction of robust and discriminative visual features is an important challenge to this task. In response,a text-based person search algorithm based on self-supervised learning was designed,which formulated the self-supervised learning and text-based person search task in the form of multitask learning. Both tasks were trained at the same time and shared similar model parameters. As an auxiliary task,the self-supervised task aims to learn more robust and discriminative visual features for the person search task. Specifically,visual and textual features were first extracted,and the image inpainting was applied as a self-supervised task,aiming to learn richer semantic information and become more robust to occlusion data. Based on the particularity of the person image,a mirror flip prediction task was further designed to learn discriminative details by training the network to predict whether the image was mirror-flipped or not. This was applied to enable the person search task to distinguish difficult samples. Extensive experiments on the public dataset have demonstrated the superiority and effectiveness of the proposed approach,thereby improving the Top-1 accuracy of person search by 2.77%. Experimental results also show that the two self-supervised tasks are complementary,and better retrieval performance can be achieved using them at the same time.
person search;crossmodal analysis;self-supervised learning;multitask learning
10.11784/tdxbz202202003
TP37
A
0493-2137(2023)02-0169-08
2022-02-07;
2022-05-09.
冀 中(1979— ),男,博士,教授.
冀 中,jizhong@tju.edu.cn.
天津市自然科学基金资助项目(19JCYBJC16000);国家自然科学基金资助项目(62176178);天津市科委科技特派员资助项目(20YDTPJC01110);中国航天科技集团公司钱学森青年创新基金资助项目.
Supported by the Natural Science Foundation of Tianjin,China(No. 19JCYBJC16000),the National Natural Science Foundation of China (No. 62176178),Tianjin Science and Technology Commissioner Project(No. 20YDTPJC01110),China Aerospace Science and Technology Corporation Qian Xuesen Youth Innovation Fund.
(责任编辑:孙立华)
