面向科技文献的国内外知识挖掘研究热点与展望
2024-01-02孙盟盟奚洋洋
孙盟盟 奚洋洋

★基金项目:本文系河北省社会科学发展研究课题“数字人文视域下高校图书馆特藏资源建设与服务策略研究”(20230303047)的研究成果。
摘要:以WOS核心合集与CNKI数据库作为数据来源,运用文献计量和内容分析方法,借助Citespace、VOSviewer对国内外关于科技文献的知识挖掘研究情况进行系统梳理。通过对发文趋势、作者共现、机构共现和关键词共现进行分析,揭示该领域的热点主题与发展趋势。研究发现关于科技文献知识挖掘的热点主题集中于面向科技创新的知识挖掘、知识产权与主题演化分析、细粒度知识抽取及知识关联挖掘等方面。提出未来需要探索多样化的知识挖掘方法,以更好地开发科技文献价值的相关建议。
关键词:科技文献;知识挖掘;主题演化;文献计量
中图分类号:G353.1 文献标识码:A
DOI:10.13897/j.cnki.hbkjty.2023.0078
随着科学技术的迅猛发展,知识更新迭代的周期不断缩短。科技文献作为科学技术研究活动的成果记录,每年的总体产出持续增长。据中国科学技术信息研究所发布的《2022年中国科技论文统计报告》显示,我国在国际顶尖期刊中的论文数量继续保持在世界第二位[1]。与此同时,根据WIPO公布的数据,我国专利申请量已连续多年位居世界第一。科技文献作为表达科学机理、阐述研究思路以及展示科技成果的重要载体,其中蕴含了丰富的知识,是科技创新活动中最重要的资源。因此,近年来诸多研究开始探索如何采用大数据技术深入挖掘、集成和利用海量的科技文献资源,促进知识发现、知识增值。而知识挖掘主要采用知识抽取、知识识别、知识发现、分类、聚类等技术方法,从庞大数据资源中自动发现隐藏的知识和信息,曾广泛应用于智能搜索、深度问答、社交网络以及一些垂直行业。在此背景下,本文拟对国内外关于科技文献资源的知识挖掘理论、方法、技术等相关研究进行进一步梳理和总结,以期为后续研究提供参考和借鉴。
1 数据来源与研究方法
本研究选择Web of Science核心合集数据库作为外文文献数据来源,从中国知网平台获取中文文献。直接以“科技文献知识挖掘”为主题进行检索,返回的结果较少,需要调整检索策略进行扩检。考虑到科技文献的类型主要为科技论文、专利、科技报告,因此构造中文检索式为:((主题=科技文献) OR (主题=科技论文) OR (主题=专利) OR (主题=科技报告) ) AND ((主题=挖掘) OR (主题=识别) OR (主题=抽取) OR (主题=发现) OR (主题=分类) OR (主题=聚类)) AND (主题=知识),限定文献类型为期刊论文。外文检索式为(TS=(scientific paper) OR TS=(patent) OR TS=(scientific Report)) AND (TS=(mining)OR TS=(identify)OR TS=(extract)OR TS=(classify) OR TS=(cluster)) AND (TS=(knowledge)),限定文献类型为Article,时间范围不做设定,检索时间为2023年5月31日。根据上述检索策略,清除会议报道、资讯简介、书评等,共获得中文文献1 121篇,外文文献9 160篇。
在研究方法上,本文采用文献计量和图谱可视化的方式对国内外关于科技文献知识挖掘的相关论文进行分析。其中,针对发文趋势、作者共现、机构共现的分析通过Citespace进行梳理;在分析热点研究主题及应用时,借助VOSviewer可视化工具进行,对数据进行布局,调整标签、节点,最后根据图谱总结归纳相关主题。
2 国内外发文趋势分析
2.1 年度发文量分析
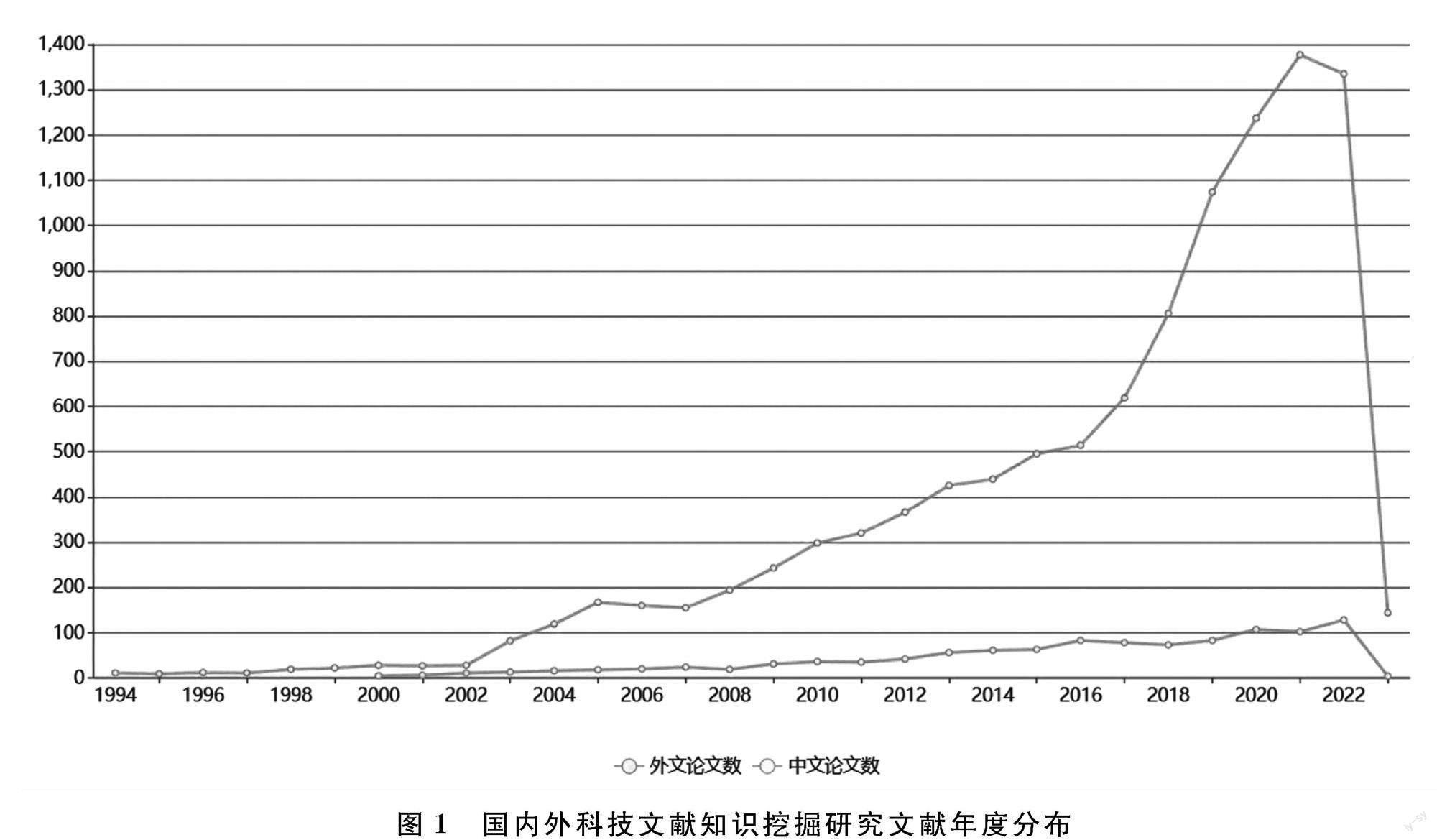
发文量的年度变化趋势是衡量某一研究领域发展态势的关键指标[2]。关于科技文献知识挖掘研究的国内外论文发文时间如图1所示,从图1可看出国际上的相关研究最早可追溯到1994年前后,国内大概始于2000年。早期研究主要以科技文献资源的发现为主,国内外年度产出整体呈稳定增长态势。2006年,我国召开全国科学技术大会,相关研究逐渐增多。从国际整体发文趋势来看,2016年成为文献激增的拐点,大数据、人工智能技术的飞速发展,为科技文献的知识挖掘提供了方法和技术支撑。2023年文献量因未完整统计不作参考。可以预见,知识挖掘在未来很长一段时间内都会是知识组织、知识服务等领域的研究重点。
2.2 研究作者及主要发文机构分析
2.2.1 研究作者及共现分析
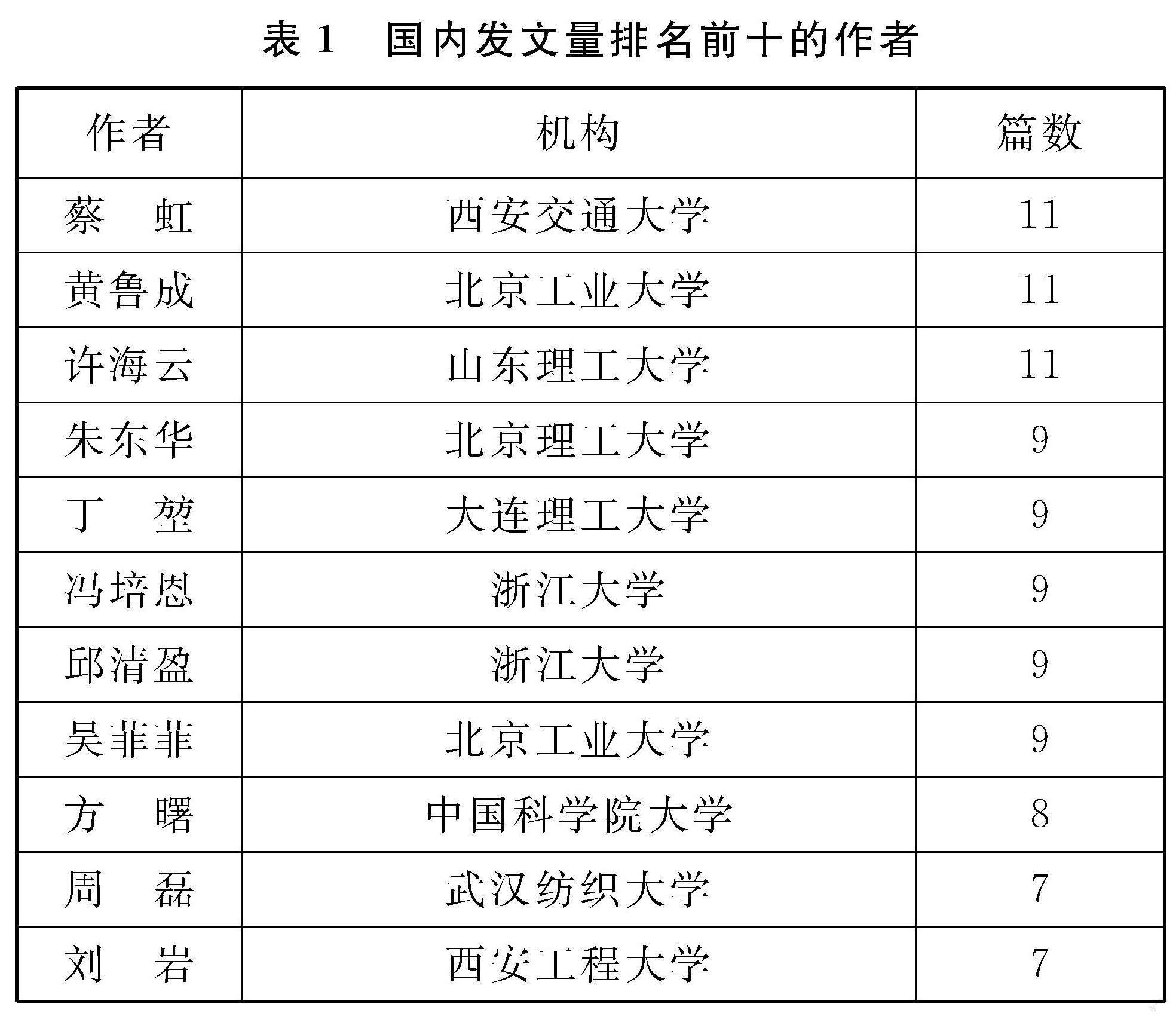
普赖斯定律[2]可预测研究主题的核心作者群体,公式为:m≈0.749(Nmax )1/2,发文数超过m的作者即为核心作者,Nmax是最高产作者的发文数。根据检索数据,国内发表文献量排名前十的作者见表1,其中,黄鲁成、蔡虹、许海云均发文11篇,计算可知满足发文量超过 3 篇的核心作者共59位,累計发文194篇,约占全部发文的17.3%;国外发表文献量排名前十的作者见表2,其中,Yoon Janghyeok发文18篇,计算可知满足发文量超过4篇的核心作者共482位,累计发文1 958篇,约占全部发文的21.4%。总体来看,国内外均未形成核心作者群体。
基于中国知网文献数据,使用Citespace设定时间节点为“2000年1月至2023年5月”,时间切片为“1年”,节点类型选择“author”,生成国内20多年科技文献知识挖掘研究领域的作者合作网络图谱(图2):节点数量N=198,连线数E=77,网络密度D=0.0039,可见该研究领域的作者合作较少且分散;外文文献数据分析保持其他参数及默认值不变,设定时间节点为“1994年1月至2023年5月”,生成国外近30年相关研究领域的作者合作网络图谱(图3):节点数量N=272,连线数E=387,网络密度D=0.0105,该研究领域的国际学者已形成一定合作团队,但仍有一部分研究者是独立发表。
2.2.2 发文机构及共现分析
从发文机构的文献数量来看,国内发文量排在前五位的机构分别是中国科学院大学(43篇)、中国科学技术信息研究所(38篇)、大连理工大学(36篇)、北京工业大学(29篇)和中国科学院文献情报中心(25篇),基本集中于北京地区;国外发文量排在前五位的机构分别为加州大学(197篇)、法国研究型大学联盟(173篇)、伦敦大学(159篇)、法国国家科学研究中心(131篇)、哈佛大学(109篇),基本为欧美大学。
对科技文献知识挖掘研究进行机构共现网络分析,保持其他参数不变,节点类型选择“Institution”,国内作者合作网络图谱如图4所示(阈值设定为5),国外作者合作网络图谱如图5所示(阈值设定为50)。从图4可知,国内发文机构仍以独立发文居多,机构合作以中国科学技术信息研究所、中国科学院文献情报中心为中心的合作网络较为凸显,区域内合作仅凸显出武汉地区的小范围合作网络;从图5中可看出,国外发文机构间的合作较为普遍,以加州大学、伦敦大学、哈佛大学等形成的合作集群较为突出,形成了一定的研究合力。加州大学是多个研究机构的连接纽带。
3 科技文献知识挖掘研究主题分析
研究借助VOSviewer工具对论文关键词进行分析,构建文献共词网络,洞悉该领域的热点主题以及各主题之间的关系。具体实现过程为:中文分析所有文献;外文因数量较多,仅选取SSCI和SCI来源期刊的论文作为样本数据。关键词频次设定为5,生成中文论文关键词共现图谱(图6)和外文论文关键词共现图谱(图7)。其中,元素的颜色代表所属聚类,可看出国内关于科技文献知识挖掘研究的共同关注点集中于知识产权、专利、知识图谱、科技文献、数据挖掘、专利信息等;国外关注点集中于创新、专利、文献计量学、系统评价、文本分析、气候变化、药用植物等。国内外共同点在于:研究对象集中于知识产权、专利和科技论文,研究主题主要涉及科技文献的技术创新、知识抽取、知识关联、知识发现、分类与聚类、主题分析与演化等,采用方法主要包括文献计量分析、机器学习、深度学习、内容分析、社会网络分析等。同时,可以看出国际上对科技文献的知识挖掘已逐渐深入到细分学科领域,如医学、生态学、药理学等。
根据图谱揭示的研究概况,并对样本文献进行内容分析,可发现国内外相关研究主题主要集中于科技创新的知识挖掘、知识产权与主题演化分析、基于机器学习的细粒度知识抽取、知识关联挖掘与知识网络构建、科技文献的分类与聚类五个方面。
3.1 面向科技创新的知识挖掘
从图6、7可看出,相关研究中“创新”这一关键词出现频率较高。从根本上而言,科学研究及对科研成果的知识挖掘都是为了促进科技创新。因此,国内外学者开展了较多支持科技创新的知识挖掘研究,具体包括对科技文献中创新点的挖掘、技术创新识别、基于内容的创新性测度等。针对创新点的挖掘,张楠等
[3]以石墨烯领域的论文和专利为研究样本,采用LDA2Vec主题模型和Kmeans聚类算法进行了硬科技创新候选技术主题挖掘。R.K.Amplayo等[4]以arXiv中一定时间范围内的科技论文作为数据集,构建了基于作者、关键词、主题词等实体的引用图谱,当新的论文被添加时,图谱的变化会体现出该论文的创新点,将其输入自动编码器神经网络中能实现创新检测。针对创新技术的识别,周潇等[5]以语音识别领域的专利文本数据为例,通过Word2Vec构建领域技术主题的词向量语义网络,并利用CFDP算法识别出潜在创新要素及组合方式。王金凤等[6]构建基于文本挖掘、机器学习算法及多维空间专利地图的技术创新路径识别模型。针对基于内容的创新性测度,S.Shibayama等
[7-8]依据论文所引参考文献的篇名之间的语义距离、S.Uddin等综合关键词数量、长度以及新词比例等指标测度科技文献的创新性。
3.2 知识产权与主题演化分析
专利是科技文献中应用性极强的一部分,如何有效开展专利挖掘、执行专利布局是知识产权战略的重要一环。在专利挖掘领域,关键技术与主题演化分析作为科技文献知识挖掘的一个重要研究方向,能够帮助企业更好地开展专利布局,抓住市场机会[9]。因此,国内外学者在该方面做出了诸多探索。如,A.Momeni[10]提出了一种基于专利发展路径、k-core分析的主题建模方法,以识别光伏产业中有潜力产生决定性影响的技术。许学国等[11]基于机器学习和经验模态分解方法,识别出了新能源汽车领域的20项核心技术。近年来,深度学习技术为科技文献知识挖掘提供了更加智能的手段,杨辰等[12]利用Doc2vec模型结合基于密度的离群值检测算法、黄鲁成等[13]利用TF-IDF及ABOD异常点检测方法识别出了具有潜在技术机会的异常专利。除了专利以外,同样也有基于科技论文数据进行关键技术识别的研究[14-15]。同时,也有学者将多种方法结合起来用于技术主题的演化分析,如综合使用主题建模与社会网络分析法识别基因编辑的核心主题、突出主题和新兴主题,并預测基因编辑技术的未来发展趋势[16];或通过Leiden算法识别技术主题,采用专利引文网络分析发现决定性技术的主题演化趋势[17]。
3.3 基于机器学习的细粒度知识抽取
随着自然语言处理技术的发展,对科技文献的知识挖掘逐渐深入到细粒度的知识元,从章节、段落、句子到短语,实现了对科技文献中的术语、技术要素、关系的抽取以及结构功能的识别。采用方法主要有基于统计的、基于规则的及基于机器学习的方法,抽取对象既有科技论文也有专利文献。如,S.Kaewphan等
[18]利用深度学习模型CNN-BiLSTM-CRF,从生物医学领域的科技论文中抽取分子、细胞和组织等实体。赵丹宁等[19-20]利用基于规则的方法从药物代谢动力学文献摘要中抽取了实验、药物、给药方式、药物代谢力学参数等实验数据,并采用LSTM、Attention机制等深度学习模型,自动抽取了非结构式摘要中的“目的”“方法”“结果”三种结构要素。Pang N等
[21]提出了一种基于BERT-CRF模型的化学实体和关系抽取方法,从科技文献中抽取了化合物、溶液、方法、反应、化学键、PKA、PKA-VALUE 7类实体以及化学键能数据链。D.Zhao等[22]结合表征学习和多头注意力机制,以生物医学领域科技文献为分析对象,实现了跨句子多元关系抽取。同时,也有较多研究探索了科技文献结构功能识别的方法,以满足科研人员对科技文献中部分特定知识的检索,帮助他们快速获取精细的知识点。比如,A.Varga A等[23]提出了一种用于篇章结构识别的zoneLDA 模型。马晓慧等[24]利用CNN、LSTM、BERT等深度学习模型,分别从句子、段落、章节内容等层次对科技论文进行了结构功能识别。
3.4 知识关联挖掘与知识网络构建
知识关联挖掘与知识网络构建常被用于发现科技文献资源或内部知识之间的潜在关联,在此基础上进行预测与知识推理,挖掘隐性知识。比如,范馨月等
[25]以PubMed论文集为研究对象,采用文本挖掘方法,构建了“药物—副作用”的共现矩阵,进而发现两者之间的潜在关系。贾丽燕等[26]利用关联规则分析方法,通过对医疗文献的数据挖掘,发现了糖尿病视网膜病变的用药规律。同时,也有研究从科技文献资源纵向挖掘角度建立知识网络,根据知识网络节点间错综复杂的关系进一步发现核心的或隐含的知识点。如,王凯等[27]将文献正文表示成一个以句子为节点,句子间关联为边的文本关系网络,采用社会网络分析方法挖掘出重要章节中的核心句。近年来,知识图谱被广泛用于科技文献的知识组织与知识关联中,以实现语义搜索、智能问答等知识服务。李星原等[28]以癫痫领域的相关论文作为数据集,构建了多模态的知识图谱,直观地呈现了该领域医疗实体之间的关联。A.Rossanez等[29]提出了一种基于规则的半自动方法,从一组生物医学论文的摘要中识别生物医学命名实体和关系,生成知识图谱,并将其链接到生物医学领域的本体中。钟将等[30]以人工智能、大数据等领域的最新科技论文为语料集,从中提取知识三元组(涵盖处理任务、处理方法、处理对象以及性能指标4类实体以及包含、应用、对比和同指4种关系),构建了计算机领域知识图谱。
3.5 科技文献的分类与聚类
科技文献的分类和聚类是建立在对文本主题、内容或属性进行特征表示、特征选择的基础上实现,进而发现同类文献之间潜在的相似模式。科技文献的分类对资源的检索、筛选和推荐都有重要意义,而对科技文献资源的聚类分析则被广泛用于技术热点的挖掘、价值评估等各个方面。分类和聚类一般基于文本内容或主题,采用机器学习方法实现。肖悦珺等[31]以新能源汽车领域的专利文本作为实验数据,利用BERT模型提取句子和重要专有名词的特征表示向量,并根據文本特征结合专有名词及其上下文语句信息对专利文本进行分类。宫小翠等[32]提出了基于 Labeled LDA 主题模型的医学文献自动分类法。白思萌等[33]采用文本级超图和交叉注意力机制捕捉科技文献的组织结构及语义语法信息,对生物医学领域的文本进行分类。J.Yun[34]根据科技文献的共引网络与共被引网络的结构信息进行了文献聚类。马建红等[35]采用信息实体语义增强表示(ERNIE)和卷积神经网络(CNN)相结合的深度学习模型,提出了一种基于功效特征的跨领域专利聚类的方法。李玉等[36]通过DBSCAN聚类改进了随机森林算法,并将其用于专利的价值评估中。李俊州等[37]利用K-medoids聚类算法提出了一种针对科技文献文本特征选择的方法,实现文本内容的特征降维。
4 结论与展望
本研究借助Citespace、VOSviewer对科技文献知识挖掘领域的发展现状、热点研究主题等进行系统梳理和总结,根据分析结果,主要提出以下建议:
(1)整体来看,现阶段正是科技文献知识挖掘研究的白热化时期,国内外都应加强多学科、多领域、跨区域间的合作交流,逐渐形成一批用于知识发现、知识检索、知识推荐等领域的成熟技术与产品。
(2)语义网、关联数据、知识图谱的发展,从语义层面为科技文献的知识挖掘、组织、关联提供了极大的技术支撑,但文献内容知识元间的联系揭示仍然受自然语言处理、信息抽取、知识图谱等技术和算法的限制,如自然语言处理技术中的文本匹配算法、情感分析算法等仍存在一定的误差[38],复杂的非结构化数据的信息抽取技术还需要依赖于大量的数据训练[39]等,需加强对新技术的关注及在人力、物力、财力方面的投入,推动数据处理、模型优化和训练等研究的开展、普及与应用。
(3)机器学习与深度学习技术使得科技文献的知识挖掘更加智能化,为科技文献深度聚类研究提供了更多思路。科技文献的分类与聚类分析主要是建立在处理文本数据的基础上,而对复杂的图像、时序类数据的探索不足,可考虑利用深度神经网络等人工智能技术来提高聚类效果,发展到更多领域,更好地改变人们的生产生活。
研究发现当前的科技文献知识挖掘方法及其应用仍处于初级探索阶段,还存在较多亟待解决的问题,例如,如何开展跨领域的知识挖掘,如何提高知识挖掘方法的可移植性与准确性等,未来还需要进行更深入的研究。
参考文献
[1]中国科学技术信息研究所.2022年中国科技论文统计报告发布
[EB/OL].[2023-03-08].https://www.istic.ac.cn/html/1/284/338/1292211314138981529.html.
[2]顾海,奉子岚,吴迪,等.我国远程医疗研究现状及趋势——基于CiteSpace的文献量化分析[J].信息资源管理学报,2020,10(4):119-129.
[3]张楠,赵辉.基于论文—专利的石墨烯领域硬科技创新技术主题识别研究[J].高技术通讯,2021,31(8):892-900.
[4]Amplayo R K , Hong S L , Song M . Network-based Approach to detect novelty of scholarly literature[J]. Information sciences, 2017(422):542-557.
[5]周潇,许银彪,史益.基于深度学习与语义挖掘的技术创新组合识别与追踪[J].图书情报工作,2022,66(10):33-44.
[6]王金凤,徐正强,冯立杰,等.基于多维空间专利地图及可拓学的技术创新路径识别与评价[J].科技管理研究,2022,42(8):8-17.
[7]Shibayama S, Yin D, Matsumoto K.Measuring novelty in science with word Embedding[J].PLoS ONE, 2021,16(7):e0254034.
[8]Uddin S, Khan A. The impact of author-selected keywords on citation counts[J].Journal of Informetrics, 2016, 10(4):1166-1177.
[9]賈军,魏洁云.新兴产业核心技术早期识别方法与应用研究[J].科学学研究,2018,36(7): 1206-1214.
[10]MOMENI A, ROST K. Identification and monitoring of possible disruptive technologies by patent-development paths and topic modeling[J].Technological Forecasting and Social Change, 2016, 104:16-29.
[11]许学国,桂美增.基于机器学习的新能源汽车核心技术识别及布局研究[J].科技管理研究,2021,41(9):96-106.
[12]杨辰,王楚涵,陶琬莹,等.基于专利的技术机会识别:深度学习领域的案例分析[J].科技管理研究,2021,41(12):172-176.
[13]黄鲁成,李晓宇,李晋.基于专利的ABOD-RFM技术机会识别方法研究[J].情报理论与实践,2020,43(9):144-149.
[14]Jia W, Xie Y, Zhao Y, et al. Research on Disruptive Technology Recognition of Chinas Electronic Information and Communication Industry Based on Patent Influence[J].Journal of Global
Information Management,
2021, 29(2):148-165.
[15]Dotsika F, Watkins A. Identifying Potentially Disruptive Trends by Means of Keyword Network Analysis[J].Technological Forecasting Social Change, 2017(119): 114-127.
[16]翟东升,金苑苑,徐硕,等.基于语义特征的潜在标准必要专利识别研究[J].科研管理,2022,43(3):183-191.
[17]吴洁,桂亮,刘鹏.基于图卷积网络的高质量专利自动识别方案研究[J].情报杂志,2022,41(1):88-95,124.
[18]Liu J, Wei J, Liu Y. Technology Forecasting based on Topic Analysis and Social Network Analysis: A Case Study Focusing on Gene Editing Patents[J].JOURNAL OF SCIENTIFIC & INDUSTRIAL RESEARCH, 2021, 80(5):428-437.
[19]李乾瑞,郭俊芳,黄颖,等.基于突变——融合视角的颠覆性技术主题演化研究[J].科学学研究,2021,39(12):
2129-2139.
[20]Kaewphan S, Hakala K, Miekka N, et al. Wide-scope Biomedical Named Entity Recognition and Normalization with CRFs,Fuzzy Matching and Character Level Modeling[J]. Database:The Journal of Biological Databases and Curation, 2018(2018):1-10.
[21]赵丹宁,牟冬梅,斯琴.研究型科技文献的实验数据自动抽取研究——以药物代谢动力学文献为例[J].图书馆建设,2017(12):33-38.
[22]赵丹宁,牟冬梅,白森.基于深度学习的科技文献摘要结构要素自动抽取方法研究[J].数据分析与知识发现,2021,5(7):70-80.
[23]Pang N , Qian L , Lyu W , et al. Transfer Learning for Scientific Data Chain Extraction in Small Chemical Corpus with BERT-CRF Model: arXiv, 10.48550/arXiv.1905.05615[P]. 2019.
[24]Zhao D , Wang J , Zhang Y , et al. Incorporating representation learning and multihead attention to improve biomedical cross-sentence n-ary relation extraction[J]. BMC Bioinformatics, 2020, 21(1):312.
[25]Varga A , Preotiuc-Pietro D , Ciravegna F. Unsupervised document zone identification using probabilistic graphical models[C]// Eight International Conference on Language Resources & Evaluation. 2012:1610-1617.
[26]馬晓慧,赵文娟,刘忠宝.基于深度学习的多学科多层次学术论文结构功能识别方法比较研究[J].情报科学,2021,39(8):94-102.
[27]范馨月,崔雷.基于文本挖掘的药物副作用知识发现研究[J].数据分析与知识发现,2018,2(3):79-86.
[28]贾丽燕,来保勇,赵楠琦,等.基于文献数据挖掘的糖尿病视网膜病变中药用药关联规则分析[J].中国中医眼科杂志,2019,29(1):25-30.
[29]王凯,孙济庆,李楠.面向学术文献的知识挖掘方法研究[J].现代情报,2017,37(5):47-51,110.
[30]李星原,汪鹏,申牧,等.癫痫病相关论文多模态知识图谱的构建初探[J].北京邮电大学学报,2022,45(4):19-24.
[31]RossanezA,Reis J D,Torres R,et al.KGen:a knowledge graph generator from biomedical scientific literature[J].BMC Medical Informatics and Decision Making, 2020, 20(S1):1-24.
[32]钟将,尹红,张剑.基于学术知识图谱的辅助创新技术研究[J].计算机科学,2022,49(5): 194-199.
[33]肖悦珺,李红莲,张乐,等.特征融合的中文专利文本分类方法研究[J].数据分析与知识发现,2022,6(4):49-59.
[34]宫小翠,安新颖,单连慧.基于Labeled LDA主题模型的医学文献自动分类法[J].中华医学图书情报杂志,2018,27(10):53-58.
[35]白思萌,牛振东,何慧,等.基于超图注意力网络的生物医学文本分类方法[J].数据分析与知识发现,2022,6(11):13-24.
[36]Yun J ,Ahn S , Lee J Y . Return to basics: Clustering of scientific literature using structural information[J]. Journal of Informetrics, 2020,14(4):101099.
[37]马建红,曹文斌,刘元刚,等.基于功效特征的专利聚类方法[J].计算机应用,2021,41(5): 1361-1366.
[38]李玉,王利,周志平,等.基于DBSCAN聚类改进随机森林算法的专利价值评估方法[J].科学技术与工程,2020,20(14):5673-5679.
[39]李俊州,武莹.基于改进K-medoids算法的科技文献特征选择方法[J].华中师范大学学报(自然科学版),2015,49(4):541-545.
[40]孙静含,任静.计算机文本分析算法发展综述[J].电子技术应用,2023,49(3):42-47.
[41]杨洋,关毅,李雪,等.中文医学细粒度知识表示体系与标注语料库构建[J].中文信息学报,2023,37(6):52-66.
作者简介:
孙盟盟(1990),女,硕士,河北大学图书馆馆员。研究方向:信息素养、文献分析。
奚洋洋(1990),女,硕士,河北大学图书馆馆员。研究方向:信息服务、数据可视化。
(收稿日期:2023-07-17 责任编辑:孙 炜)
Research Hot spots and Prospects of Knowledge Mining for Scientific and
Technological Literature at Home and Abroad
—Quantitative Analysis Based on WOS Core Collection and CNKI Database
Sun Meng-meng Xi Yang-yang
Abstract:Taking the WOS core collection and CNKI database as data sources, using bibliometric and content analysis methods,with the help of Citespace and VOSviewer, knowledge mining research on scientific and technological literature at home and abroad is systematically sorted out. By analyzing the publication trend and the co-occurrence of authors, institutions and keywords, this paper reveals the hot topics and development trends in this field. It is found that the hot topics about knowledge mining of scientific and technological literature are concentrated in the aspects of knowledge mining for scientific and technological innovation, intellectual property and topic evolution analysis, fine-grained knowledge extraction and knowledge association mining. Some suggestions are put forward that diversified knowledge mining methods should be explored in the future to better exploit the value of scientific and technological literature.
Keywords:Scientific Literature; Knowledge Mining; Theme Evolution; Bibliometrics
