基于NPU的实时深度学习跟踪算法实现
2022-09-13李良福王娇颖卢晓燕杨一洲刘培桢
何 曦,李良福,王娇颖,王 洁,卢晓燕,钱 钧,杨一洲,刘培桢
(西安应用光学研究所,陕西 西安 710065)
引言
目前目标跟踪算法大致可以分为传统算法、基于相关滤波的算法和基于深度网络的算法[1]。其中深度学习算法,一方面需要大数据的支持,另一方面需要强大的算力作保障。CPU、ARM、DSP无法完成此类大规模并行运算,需借助并行处理能力更高的GPU、FPGA 以及NPU。高性能GPU常年被国外公司所垄断,我国的GPU 水平明显落后于NVIDIA、AMD 等外国公司,短期之内无法赶超。FPGA 虽能完成大规模的并行计算,灵活性高,但其编译时间长,巨大的时间代价限制了其应用。我国的NPU 水平处于国际前列,如华为海思的昇腾芯片、阿里的Ali-NPU,都有着不错的性能,其主流平台性能对比见表1 所示。目前日益紧张的国际形势,也使得国产化替代迫在眉睫。
NVIDIA TX2 和Xavier 可使用TensorRT 高性能深度学习推理平台[2]实现低延迟和高吞吐量。从表1 中可以看出,Xavier 在TX2 的基础上增加了48 个张量核,其AI 算力大幅提升,但Atlas200的AI 总体算力强出TX2 很多,与最新的Xavier 相当,处于国际领先地位,性能功耗比更是明显优于TX2 和Xavier。

表 1 主流GPU、NPU 平台性能参数对比Table 1 Comparison of performance parameters of important GPU and NPU platforms
在应用领域,目标检测算法存在大量图片数据可供训练,发展速度很快。但目标跟踪算法由于跟踪对象的不确定性,不易采用大数据训练,工业上仍大多使用基于相关滤波的算法,例如KCF[3],DSST[4],文献[5]等。该类方法对边缘的预测不佳,会产生累计误差,长时跟踪目标容易丢失。2016年SiameseFC[6]的出现,让人们看到了深度学习跟踪算法在工业应用的希望,其模型简单,运行速度快,同时孪生网络很好地解决了跟踪的离线训练问题。之后的SiameseRPN[7]引入了Faster RCNN[8]中的区域生成网络模块,无需进行多尺度运算就可以对目标位置和形状进行回归,算法的性能大幅提升。但该类算法没有在线学习机制,对从未出现过的目标判别能力不佳,且未能有效利用背景信息,当目标受遮挡时容易受到干扰。2018年,IoUNet[9]使用交并比(IoU)代替分类得分作为评价指标,进一步提升了回归的准确性。DiMP[10]引入了目标模板预测网络,并且设计了有效的损失函数进行快速迭代优化,最大化预测模型的分辨能力,有效利用图像序列中目标与背景信息,提升目标跟踪性能。但此算法网络模型较大,加载和推理耗时高,迭代次数多,收敛速度慢,目前在高功耗显卡上虽然能够达到40 fps 以上的速度,但在嵌入式平台上依然无法实时跟踪。除此之外,IoU 损失策略还存在其他问题,如跟踪时候选框来回跳跃,跟踪位置不稳定,在候选位置与实际位置不重叠时IoUNet 存在收敛盲区,无梯度回传,无法正确收敛等。
针对以上问题,本文提出了一种改进的孪生网络跟踪算法。在特征特取网络中增加微调网络结构,可以在保证速度的前提下实现在线更新;回归网络中,在IoU 损失的基础上增加了中心距离惩罚项,解决了跟踪时候选框在相同IoU 位置来回跳跃和某些情况下无梯度回传的问题,同时还提升了IoUNet 的收敛速度;将训练好的网络再通过通道剪枝,压缩网络模型的尺寸,提升模型加载和推理速度,使之满足推理的实时性要求。最后在华为国产化嵌入式平台Atlas200 上实现了运行速度超过60 fps。
1 加入微调的剪枝孪生网络跟踪算法
1.1 加入微调网络的特征提取网络
传统的孪生网络系列跟踪算法存在一个问题,就是其模型权重只能离线训练,无法在线更新。在训练中学习到通用特征表达后,面对新场景有效性会降低,无法准确分辨目标此刻的状态,是否丢失或被遮挡。如果在目标丢失或遮挡情况下,盲目更新模板会造成误差累积,最终丢失目标。不选择更新模型权重最主要的原因是模型太大,无法适应实时应用需求。若要实现在线更新,则要从模型大小入手。
如果让整个网络模型全部参与更新,势必会增加更新时间,无法满足实时性要求,并且在线的数据量远小于离线训练的数据量,更新整个网络可能会适得其反。若减少训练的参数,在线更新就成为可能。在基础特征网络后面加入微调网络,在离线训练过程中,将基础特征网络和微调网络作为一个整体联合训练;在推理的过程中将基础特征网络和微调网络拆开,锁定基础特征网络的参数,只更新微调网络。这样既能实现模型在线更新,又能够保证更新速度,还不会影响离线训练效果。训练与推理时的参数更新流程如图1 所示。
图1 中基础特征网络为ResNet50 网络的特征输出层,微调网络为2 层卷积层。其效果类似于迁移学习,把基础特征网络ResNet50 的训练过程当作近似目标类别进行训练。微调网络的作用是在线推理过程中针对当前跟踪任务进行优化。
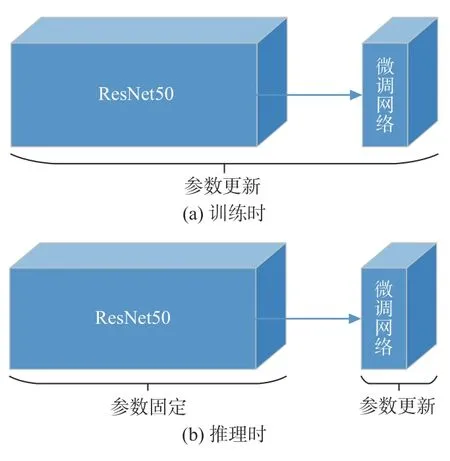
图 1 训练与推理时的参数更新Fig.1 Parameters update during training and inference
1.2 加入中心距离惩罚的IoU 回归
回归网络始终追求的是更准确的目标回归。但实际中,基于最大分类得分得到的候选框未必是最优的,有时最大分类得分框的中心位置与目标的实际中心位置存在一定偏差,这种误差会随着跟踪过程逐渐累积,引起漂移,从而造成目标丢失。
DiMP 中采用IoUNet 策略就是考虑到这个缺点,以IoU 重叠度得分评价策略代替分类得分的评价策略,在一定程度上改善了该问题。针对不同场景和目标的测试结果如图2 所示[9]。图2 中黄框代表目标真实位置,红框的分类得分均高于绿框,绿框的IoU 重叠度得分均高于红框,显然绿框的跟踪位置更加准确。但IoU 重叠度得分仍存在3 个问题:1)可能存在多个候选框IoU 相同情况,输出的跟踪框会在这几个框之间来回跳跃,增加了输出结果的不确定性;2)在目标框与候选框不相交时存在收敛盲区,无法计算回传梯度;3)IoUNet 收敛速度慢,需要多次迭代才能收敛。为解决以上问题,回归损失函数可在IoU 损失的基础上,增加目标中心位置和候选框中心位置距离的惩罚项。
以图3 为例,图中实线框为目标真实位置,虚线框为候选框位置,3 个候选框与真实目标的IoU相同,均为0.7,但所处真实框的位置不同,最终输出位置可能会在图3(a)、图3(b)和图3(c)这3 个虚线框位置来回跳跃,不利于保持跟踪稳定。IoU损失函数为

式中:B为 候选框;为实际目标框。

图 2 分类得分与IoU 重叠度得分效果比较Fig.2 Comparison between classification score and IoU overlap score

图 3 多个位置的IoU 损失相同示例Fig.3 Same examples of IoU loss with different locations
为应对上述问题,在IoU 损失的基础上增加候选框与真实目标中心距离的损失信息,即在保证高IoU 的同时,还要保证候选框中心位置与目标实际中心位置尽可能接近。这样即使在多个候选框IoU 损失相同的时候,也能够选择出最佳的跟踪位置输出,如图4 所示。加入距离惩罚的损失函数为

式中:c为 候选框中心;为实际目标框中心;为两者之间的距离;R为外接矩形的对角线长度。从图4 可看出,虽然3 个虚线框IoU 相同,均为0.7,但加入中心位置损失判断后,图4(c)虚线框的中心距离惩罚项为0,在3 个虚线框中中心惩罚项最优。

图 4 加入中心位置的损失判断Fig.4 Loss judgement added into centric position
在实际测试中,原始IoUNet 候选框位置需要迭代10 次才能够收敛,惩罚项同时还能够提升IoUNet 的收敛速度。加入中心距离惩罚项后训练得到的网络,只需要3 次迭代就可以收敛。综上所述,加入中心位置惩罚项,可以解决单纯依靠IoU 重叠度存在的3 个问题。
1.3 通道剪枝
使用DiMP 的离线训练方法,在TrackingNet[11]、LaSOT[12]、GOT10k[13]和COCO[14]数据集训练。主干网络使用ImageNet[15]权重进行初始化。每个循环通过20 000 个视频来训练,共训练50 个循环,每10 个循环的学习率衰减为原来的0.2。采用ResNet50 架构作为主干,将训练的损失函数设为Ltrain=kLIoU+(1-k)Lclf,其中k为0.01。
ResNet50 可带来良好的性能,但几百兆的模型也带来了存储和计算负担。在相同数据量条件下,一个剪枝后的深层网络性能优于一个浅层网络,所以我们选择将ResNet50 模型剪枝而不是选ResNet18。将训练好的模型进行剪枝,剪枝方法主要有权重剪枝和结构化剪枝。基于权重的剪枝方法会使网络结构不规则,需要硬件的特定优化才能实现推理加速,看似删剪率很高,实际加速效果一般。结构化剪枝是通过删剪冗余通道,即从一个宽网络中抽离出一个窄网络,实现有效缩减模型尺寸的同时提升推理速度。
ResNet 具有分支结构,采用剪枝方法可参考Network Slimming[16]。该方法实现简单,效果较好,在工业领域应用广泛。为了降低实现难度,只针对网络中没有分支的部分进行剪枝,分支部分结构保留,为每个无分支通道设置一个重要性因子γ,并与该通道的输出相乘,联合训练网络权重以及对应的重要性因子,并对后者进行稀疏正则化。重要性因子越小,说明当前通道越不重要,最后裁剪掉那些重要性因子小的通道,并对剪枝后的网络进行微调。
剪枝后的损失函数为

前项Ltrain为正常损失函数,后项为稀疏惩罚项,是 γ的L1 正则化范数。
通道中批规范处理层(BN 层)处在卷积层后面,其中缩放因子满足重要性因子 γ的要求,可以用其充当重要性因子 γ,并且不会增加网络的额外开销。论文[16]也证明了这种方法是设置通道剪枝重要性因子的最有效方式,剪枝前后网络分别如图5(a)和图5(b)所示。

图 5 剪枝前后网络Fig.5 Network before and after pruning
当剪枝率很高时,剪枝会导致一定的精度损失,但该损失可以通过网络微调进行补偿。限制每次的剪枝率,并通过多次剪枝迭代的方法可使精度损失下降幅度较小,经过微调的窄网络可以达到原始未剪枝网络相近的精度。剪枝流程图如图6 所示。所有的重要性因子都初始化为0.5,学习率为0.001,λ为10-5。设置动态阈值,每次修剪掉30%通道,对每次剪枝后的模型训练5 个循环再进行微调,同时迭代3 次。

图 6 通道剪枝流程图Fig.6 Flow chart of channel pruning
2 基于Atlas200 的推理实现
2.1 系统设计总述
Atlas200 嵌入式平台主要计算单元包括ARM(CPU 侧)和AI CORE(NPU 侧),其中网络模型推理适合放在NPU 侧运行,其他部分适合放在CPU侧运行。要将算法部署至Atlas200 嵌入式平台,首先要对算法整体架构进行分析,将适合在NPU 侧运行和适合在CPU 侧运行的部分解耦。算法整体架构如图7 所示,主要包括3 部分:初始化单元、跟踪单元和在线更新单元。

图 7 算法架构图Fig.7 Structure diagram of algorithm
将Pytorch 训练好的模型部署到Atlas200 嵌入式平台需要2 个步骤:首先将pytorch 的.pth 模型转换成ONNX 的.onnx 模型;然后通过华为提供的工具链MindStudio 将.onnx 模型转换成Atlas200 平台所需的.om 模型。
2.2 初始化单元设计
初始化单元如图8 所示。初始化步骤为:
1)对第一帧图像进行裁剪,然后对裁剪后的图像块进行增广、整合,得到对应的初始框;
2)利用ResNet50 和微调网络提取初始帧分类网络特征和IoU 网络特征;
3)利用分类网络特征初始化目标分类器,得到一个维度为(1,512,4,4)的目标分类器,用该分类器与后续帧中的分类网络特征卷积就可以得到目标最大响应位置,实现后续跟踪阶段准确区分目标和背景,以确定目标具体位置;
4)利用IoU 网络特征初始化IoUNet,得到2 个维度(1,256,1,1)的IoU 调制向量,用于后续跟踪阶段计算目标具体尺寸。
初始化单元主要有3 个功能:
(1)图像的裁剪增广可以作为预处理部分放在CPU 侧运行;

图 8 初始化单元Fig.8 Initialization unit
(2)提取基础网络和微调网络特征可以放在NPU 侧运行;
(3)步骤3)和步骤4)这2 个部分均可放在NPU 侧运行。
考虑到所有在NPU 侧运行的模块之间有较强的数据依赖性,故可以将网络特征提取、分类器初始化和IoUNet 初始化合并,转为一个初始化模型在NPU 侧进行推理。因此,初始化模块在嵌入式端实现需要两部分,即图像预处理部分和初始化模型推理部分。
2.3 跟踪单元设计
跟踪单元如图9 所示。这个单元的功能包括:
1)对当前帧图像裁剪采样;
2)利用ResNet50 和微调网络提取当前帧网络特征;
3)利用分类器和IoUNet 计算当前帧目标位置和大小;
4)逐帧记录基础网络特征和目标位置尺寸信息,用于后续在线更新分类器。
跟踪单元的核心是功能3),功能3)的实现包含3 个部分:
(1)利用分类器计算当前帧目标的位置。实现原理是用分类器对当前帧的特征图进行卷积得到热力图,热力图的最大值点的位置就是分类得分位置,是一个纯推理过程,可以放在NPU 侧运行。
(2)利用IoUNet 和分类得分位置计算当前帧目标尺寸,IoUNet 的作用是根据输入的特征图预测候选框的IoU 得分,优化跟踪位置。首先依据预测出的当前帧目标位置(x,y)和上一帧目标尺寸(w,h)生成1 个初始框(x,y,w,h),然后在这个初始bbox的基础上,通过随机调整中心点位置和宽高生成15 个候选框,最后将16 个候选框送入IoUNet 预测各自的IoU 得分,通过IoU 损失调整候选框的位置和大小,直到损失收敛。当未加入中心距离惩罚项时,需经过10 次迭代,IoU 损失才可收敛。加入中心惩罚项后只需经过3 次迭代,就可以收敛得到IoU 得分最佳的位置,该部分需要CPU 侧和NPU侧配合运行。
(3)结合分类得分和IoU 得分位置,得到最终的跟踪位置。根据候选框的IoU 得分和分类得分加权,输出最终的跟踪位置,该部分需要放在CPU侧运行。
取序列图像CarScale 第234 幅图像为例,如图10 所示。从图10(a)中可以看出,分类器输出结果能够得到目标的大致尺寸和位置,但不够精细,需要结合IoUNet 得到精细化结果。未加入中心惩罚项的IoUNet 迭代速度慢,迭代3 次仍未收敛到车辆边缘,如图10(b)所示,需要10 次迭代才能收敛到车辆边缘。加入中心惩罚项后,IoUNet迭代3 次就能收敛到比较满意的结果,如图10(c)所示,最终输出结果如图10(d)所示。

图 9 跟踪单元Fig.9 Tracking unit

图 10 跟踪单元中间结果Fig.10 Intermediate results of tracking unit
2.4 在线更新单元设计
在线更新单元如图11 所示。在线更新并不是每帧都执行,功能包括:
1)判断是否需要进行在线更新;
2)如果需要在线更新,利用共轭梯度法更新微调网络。
更新微调网络方法有2 种方式:
(1)定期更新。长时跟踪随着时间累积,目标会逐渐发生变化,定期更新微调网络可以保证分类器的时效性和稳定性;
(2)当目标周围出现相似目标时,疑似目标距离中心比目标远,但依然会对目标造成影响,此时分类器已不能很好地适应当前目标,很难得到准确的目标状态,需要更新微调网络以适应这种剧烈变化带来的影响。
判断微调网络何时需要更新的部分放在CPU侧运行,具体更新的微调网络部分放在NPU 侧运行。
在线更新单元作用如图12 所示。左下角出现干扰车辆,没有在线更新的响应图中会出现明显的干扰,如图12(b)所示;加入在线更新后,干扰车辆在响应图中影响不大,如图12(c)所示,提高了跟踪的准确性和稳定性。

图 11 在线更新单元Fig.11 Online update unit

图 12 在线更新单元作用Fig.12 Function of online update unit
3 实验与结果
选择Atlas 200 DK 开发者套件作为实验平台,操作系统版本为ubuntu18.04,CANN 版本5.0.3,sdk版本21.0.2。
Atlas 200 DK 开发者套件主要包含Atlas 200 AI 加速模块、图像/音频接口芯片(Hi3559C)和一些外部接口,其架构如图13 所示。
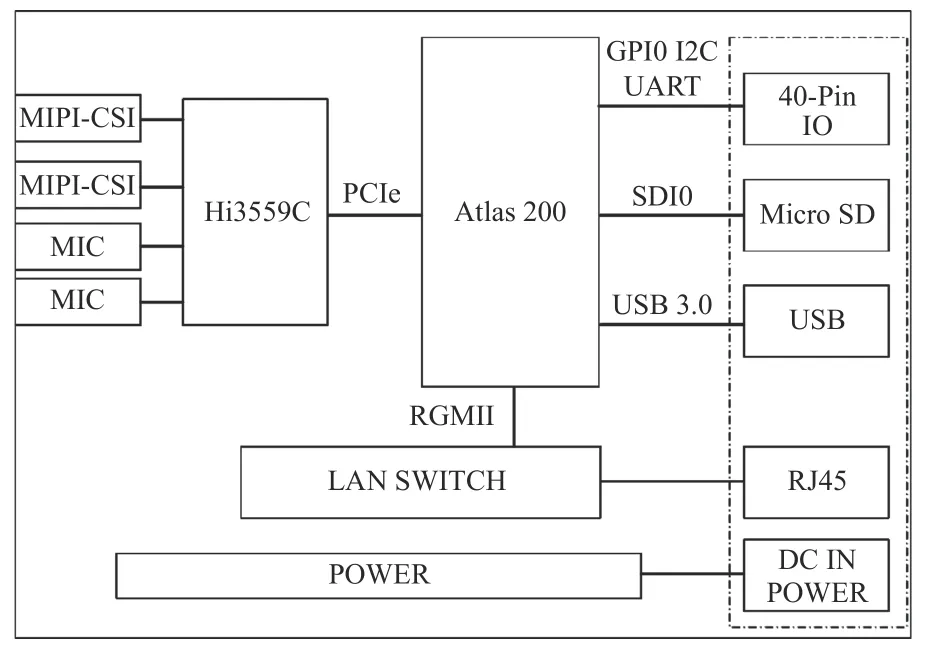
图 13 Atlas200 DK 系统框图Fig.13 System structure diagram of Atlas200 DK
3.1 多场景测试实验
选择多组图像序列对算法进行测试,算法可以在复杂背景、尺度变换、目标遮挡等条件下保持稳定跟踪。选取夜晚场景CarDark 序列进行测试,其测试结果如图14 所示。从图14(a)可视化结果可以看出,本文算法对于夜间复杂背景目标的跟踪具有较好的适应性;图14(b)是通过网络计算出特征图的响应图;图14(c)为在线更新微调网络后计算的损失。


图 14 CarDark 序列测试结果Fig.14 Test results of CarDark sequence
选取尺度变化场景CarScale 序列,其测试结果如图15 所示。从图15(c)可看出,损失随着目标车辆尺度逐渐变大,曲线不断上升,但可视化结果显示目标并未跟丢(见图15(a)),这说明本文算法对目标尺度的变化具有较好的适应性。

图 15 CarScale 序列测试结果Fig.15 Test results of CarScale sequence
选取遮挡场景SUV 序列,其测试结果如图16和图17 所示。在图像序列中目标车辆出现了被遮挡情况,但跟踪过程中跟踪效果依旧较好。在图16 中,目标车辆被树木完全遮挡,但并未出现跟踪丢失目标情况;在图17 中,目标车辆重新出现后跟踪器依旧能够很好地跟踪目标。对比图16 和图17 的损失曲线可以看出,在目标被遮挡阶段,损失出现了大幅度的上升,当目标重新出现时损失又回到了较低水平。由此可以看出,分类器在线更新机制能很好地适应目标被遮挡的情况。

图 16 SUV 序列遮挡时测试结果Fig.16 Test results of SUV sequence with occlusion

图 17 SUV 序列遮挡后测试结果Fig.17 Test results of SUV sequence after occlusion
3.2 本文算法与DiMP 算法对比结果
由于算法基于嵌入式NPU 平台运行,故未在大规模数据集上进行测试比较。选取具有代表性的共11 个视频序列进行测试,其中包含昼夜、缩放、旋转、遮挡等多个典型场景,目标对比度和尺寸如表2 所示。
设视频序列总帧数为M,正确检出目标且IoU满足要求的帧数为N,则准确率等于N/M。本文算法因为加入了微调网络和IoU 中心惩罚项,判别力和跟踪稳定性优于DiMP,故相比DiMP 有更高的准确率,如表3 所示。

表 2 数据集的目标对比度和尺寸Table 2 Target contrast and size of data set
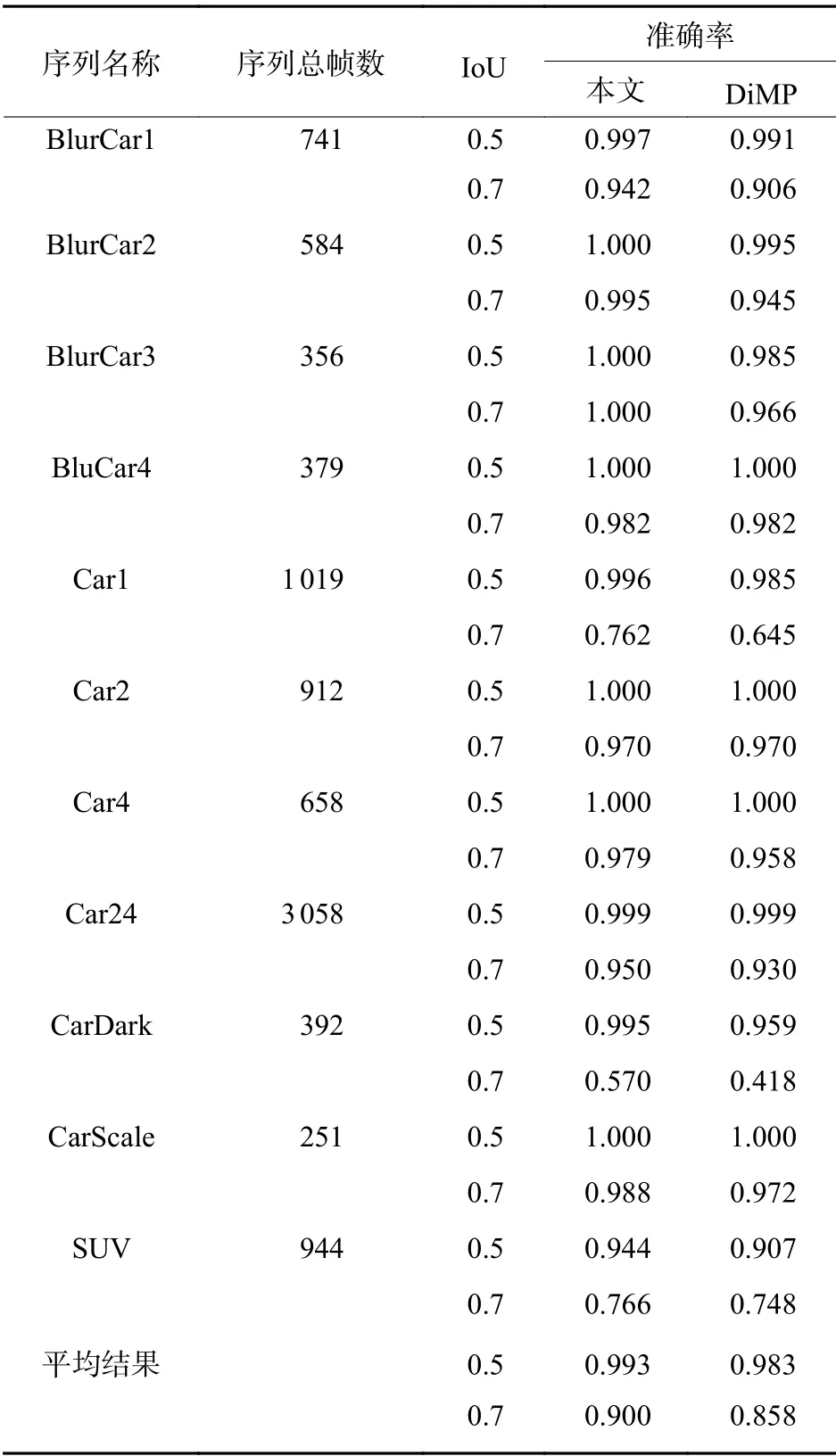
表 3 本文算法与DiMP 的准确率比较Table 3 Accuracy comparison of proposed algorithm and DiMP
3.3 NPU 与GPU 平台对比结果
DiMP 在TiTan X 上能够达到40 f/s。但TiTan X 非嵌入式平台,算力强,体积功耗大,其Int8 的算力约为44 TOPS,功耗更是高达250 W。本文算法采用Atlas200 平台,功耗仅为12 W,相比TiTan X 功耗相差巨大,尺寸更是小于一张信用卡,但却能达到更高的帧率。因为加入中心惩罚项后IoUNet 收敛速度加快,还通过通道剪枝压缩了模型的大小,所以速度快于DiMP,对比结果如表4所示。
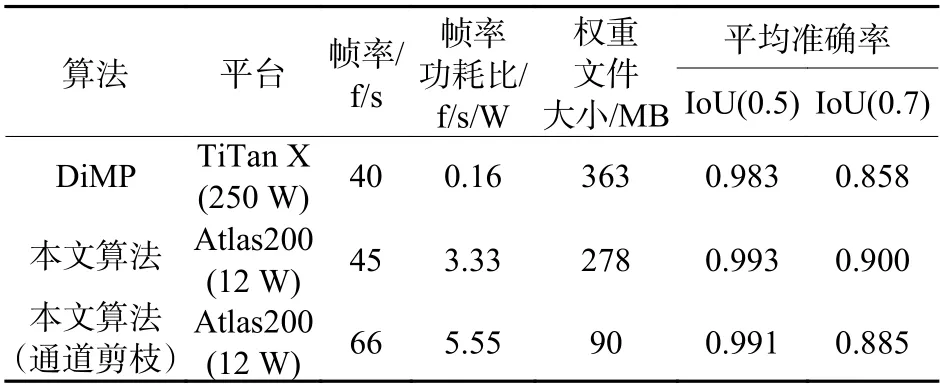
表 4 本文算法与DiMP 帧率对比Table 4 Frame rate comparison of proposed algorithm and DiMP
其他主流GPU 平台如NVIDIA TX2、NVIDIA Xaiver,算法功耗为15 W,与altas200 平台接近,帧率对比结果如表5 所示。,从表5 中可以看出,凭借NPU 对卷积网络的性能加速优势,Atlas200在功耗相近的前提下,计算速度优于NVIDIA 的TX2 和Xaiver。

表 5 不同平台下的帧率Table 5 Frame rates on different platforms
4 结论
本文在孪生网络跟踪算法的基础上,通过在特征提取网络中增加微调网络解决了孪生网络无法在线更新的问题。通过在IoUNet 中增加中心惩罚项,解决了单纯依靠IoUNet 输出不稳定,无重叠情况下存在收敛盲区和收敛速度慢等问题。通过通道剪枝技术压缩了模型大小,提升了推理速度,满足了实时要求,并最终在国产嵌入式平台Atlas200上实现。功耗仅有12 W,在测试中算法的平均准确率达到0.993(IoU>0.5)和0.900(IoU>0.7),高于DiMP 的0.983(IoU>0.5)和0.858(IoU>0.7),计算帧率达到66 Hz。
