面向自然场景文本检测的改进NMS算法
2022-01-22杨有为
杨有为,周 刚
新疆大学信息科学与工程学院,乌鲁木齐 830046
自然场景文本检测是许多计算机视觉应用的基础,如自动导航、场景文本翻译[1]等等,其检测效果将直接影响后续应用的效果。近十年来,神经网络的发展已经大幅度的提升了其检测效果,但场景文本检测领域仍然面临着文本框形状差异大、自然背景复杂混叠等问题。自然场景文本检测算法大多在经典的目标检测算法基础上进行改进。目前的目标检测算法根据其检测定位方式的不同主要可以分为one-stage 如SSD[2]、YOLO[3]、CornerNet[4]和two-stage 如Faster R-CNN[5]、R-FCN[6]、Deformable CNN[7]、Mask R-CNN[8]、Light-Head R-CNN[9]两大类。无论是one-stage 系列还是two-stage 系列算法,作为后处理的NMS 算法都是它们不可缺少的一部分。上述的two-stage 方法如Faster R-CNN[5]、Mask R-CNN[8]、one-stage方法如SSD[2]、YOLO[3]均采用了NMS算法,该算法对检测框的选择具有重要作用。
如图1(b)所示,在实验中,观察到前端检测算法会产生大量候选框,其中大部分候选框并不紧靠目标文本区域,并且该类候选框的存在将直接导致最终检测效果较差。检测效果较差主要由两种情况造成:(1)如图1(c)中紫色检测框所示,对长文本区域,受卷积核感受野等影响,选择单一检测框定位往往不够准确。(2)如图1(c)中红色检测框所示,对多个邻近文本区域,相邻检测框易产生混叠现象,对文本区域定位较差。在本文中,针对自然场景文本检测在后处理阶段产生的检测结果不紧靠文本区域的问题,提出了一种改进的NMS算法。

图1 NMS算法检测结果Fig.1 NMS algorithm test results
本文方法主要做了以下改变:针对部分候选框检测结果偏差较大的情况,设计了排序滤波与融合计算算法,既将所有候选框各坐标集合进行排序,滤除偏差较大的坐标值,再将剩余候选框进行融合计算,获得更加紧靠文本区域的检测结果。
1 相关工作
随着深度学习的快速发展,使用卷积神经网络的场景文本检测算法逐渐成为主流。Liao等人[10]提出了一种新型的全卷积网络结构,基于SSD[2]网络结构进行改进,在输出端通过text-box 层预测目标文本区域的候选框,再通过NMS 算法得到检测框。Jiang 等人[11]在Faster R-CNN[5]框架上进行改进,在其池化层进行多尺度池化去适应多尺度训练,再通过NMS 算法得到检测框。Zhou等人[12]提出对全卷积网络方法进行改进,将不同卷积层的特征级联再进行像素级别的预测,最后再通过Locality-Aware NMS[12]算法得到检测框。
上述方法均使用了NMS 算法,NMS 算法在选择最优候选框时将与最大置信度候选框交并比值(既目标预测框和真实框的交集与并集的比例,简称IoU 值)小于预设阈值的候选框全部删除,在实际情况中往往描述不够精确。因此,NMS类算法在近些年来也得到了快速的发展,许多改进的NMS算法被提出。如Incline NMS[11],在IoU的计算上提出了创新,根据文本的倾斜情况与检测目的,更改IoU定义重新训练数据,减少了普通IoU误差带来的影响,实验证明其有效地提高了检测效果。如Soft NMS[13],对滤除候选框的策略进行改进,认为NMS算法会将原本是目标物体的候选框滤除,应将小于阈值的候选框进行降低得分而不是完全抑制。又如Softer NMS[14],认为不能以置信度作为选择标准,提出候选框置信度得分与其位置准确性并非强相关,实际过程中存在大量置信度得分较低但定位良好的候选框在NMS算法中由于抑制被舍弃。所以,研究一种新参数去衡量候选框的定位准确性是有必要的。Softer NMS[14]针对网络模型进行改进,在输出全连接层的同时训练一个位置参数用于后续改进NMS 算法,精确定位候选框的位置。但这些方法如Incline NMS[11]、Softer NMS[14]都需重新训练,不同模型训练后参数设置并非一致,这样会使得算法的嵌入性降低,复杂度提升。
2 方法
传统的NMS 算法对于多文本混叠和长文本区域,由于卷积核感受野的限制与周边区域的影响,选择单一框去作为检测结果时效果往往较差。针对上述情况,提出了一种新的NMS 算法,使用排序滤波与融合计算的方法去获取检测框。图2(a)所示为未经过NMS处理前的候选框集合;如图2(b)所示,在融合前进行排序滤波处理,将同一文本区域预测产生的所有候选框相同位置的坐标按照从小到大排序,取中间一部分保留进行接下来的融合计算,经过排序滤波与融合计算后得到的检测框如图2(c)所示。

图2 算法原理Fig.2 Algorithm principle
2.1 方法理论
Softer NMS[14]中将候选框各坐标建模成不同的高斯模型,使用候选框各坐标所服从高斯分布的方差去衡量其定位的精度,认为方差越小时,该坐标的预测效果越好。具体模型如公式(1)所示,xp为预测候选框的某一坐标,方差σ2由其网络训练输出的全连接层预测所得,其中标注框(简称GT 框)各坐标视为σ→0 时的高斯模型。

考虑到重新训练参数带来的影响,本文中采用了排序滤波算法,其原理既将候选框相同位置的坐标中偏差较大的坐标进行滤除,使剩余坐标更接近他们的中值,该算法无需重新训练,其嵌入性较高,复杂度较低。

根据Softer NMS[14]中推论与排序滤波后剩余坐标的特性,假设经过排序滤波后,同一文本区域保留的候选框相同位置的坐标服从同一方差的高斯分布,模型同公式(1)。设经过排序滤波后,相同位置剩余m个坐标,由高斯分布的性质,将这m个服从高斯分布的坐标平均融合后得到的检测框坐标也将服从高斯分布,且融合后检测框坐标所服从高斯分布的方差将变为原来的m分之一,融合后方差计算方式见公式(2)。
如图2(b)高斯曲线所示(红色为GT框),融合后检测框的高斯分布曲线将会更窄,其预测将会更加接近GT框。
2.2 排序滤波与融合计算
本文算法简称Order NMS,算法原理如算法1所示。其中S是所有候选框的集合,每个候选框由8个坐标组成,i为候选框8个坐标的编号,pmax[i]、q[i]、F[i]对应候选框某个坐标的索引,i∈[0,7],N值为执行排序滤波与融合计算前要求的最低候选框数量,N≥3。在每一次循环中,找到候选框集合S中预测某一文本区域最大置信度的候选框,以该最大置信度候选框为基准,将集合S中所有候选框逐一与最大置信度候选框进行IoU 值比较,若大于预设融合IoU 阈值(具体融合阈值分析见实验部分),则将其4 个顶点的8 个坐标按照顺时针方向从左上角开始依次存入8 个集合Gi中,i∈[0,7],直到遍历所有候选框,遍历完后保留了n个候选框既每个Gi中保留了n个坐标,再将每个集合Gi内元素进行从小到大排序。若n大于N,则滤除每个Gi集合内首尾Δ 个偏差较大的坐标值,滤除完后每个Gi中保留了m个坐标,将每个Gi中保留的m个坐标根据i值对应,依次存放在8 个新集合Hi中,i∈[0,7],再将每个Hi进行融合计算得到最终检测框各坐标。若n小于等于N,则不执行排序滤波与融合计算,直接选取最大置信度候选框为最终检测框(具体N值分析见实验部分)。F[i]为最终检测框8个坐标,i∈[0,7]。
算法1 OrderNMS

在实验中,直接采用排序滤波与融合计算时效果并不理想(具体分析见实验3.1部分)。由于场景文本十分密集,存在较多条文本并排情况,当以最大置信度候选框为基准进行融合阈值筛选时,保留的候选框并不全是该目标文本区域预测产生的候选框,其中夹杂着一类周边文本区域预测产生的候选框。如算法1 中方框标注代码所示,为了解决该问题,结合了Soft NMS[13]的方法,将其用于此类候选框的滤除。在每轮算法执行时降低剩余候选框的置信度得分,通过设置滤除阈值抑制小于指定置信度得分的候选框,减少此类候选框在后轮算法中被重复保留的情况。
Soft NMS[13]降低得分机制见公式(3),其中Si为当前候选框得分,Nt为预设IoU值。

图3 直观地展示了排序滤波与融合计算的实际效果。图3(a)为未经过NMS处理的候选框集合。图3(b)为排序滤波后的候选框集合,观察发现,偏差较大的候选框数量有效减少,这对后续的融合计算十分有利。图3(c)为直接进行融合计算得到的检测框,由于融合了偏差较大的候选框,效果并不理想。图3(d)为排序滤波后进行融合计算的检测框结果,可观测到其对长文本和混叠文本等情况有较大改善。

图3 排序滤波与融合计算前后对比Fig.3 Comparison before and after sortingfiltering and fusion computing
3 实验
为保证实验数据的公平,本文统一在Zhou等人[12]提出的网络模型上进行NMS模块对比。将Locality-Aware NMS[12]、NMS、Soft NMS[13],与是否结合Soft NMS[13]的Order NMS 在相同条件下,在ICDAR2015[15]数据集和MSRATD500 数据集上进行实验比较。测试实验均使用resnet50[16]模型,使用批量梯度下降(BGT),指数衰减学习率,学习率初始值设置为0.000 1。ICDAR2015数据集迭代6万次,MSRATD数据集迭代10万次。
3.1 实验结果
实验结果如表1与表2,展示5种算法在ICDAR2015[15]数据集与MSRATD500数据集上recall、precision、F-score值的大小。
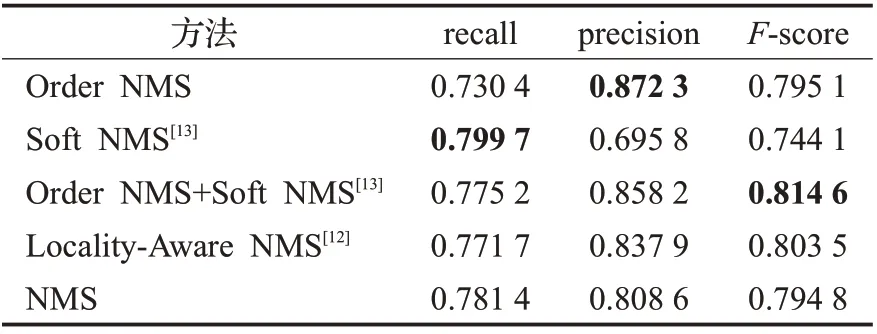
表1 5种方法ICDAR2015实验结果对比Table 1 Comparison of ICDAR2015 experimental results of five methods

表2 5种方法MSRA500实验结果对比Table 2 Comparison of MSRA500 experimental results of five methods
根据表1与表2的实验结果发现,结合Soft NMS[13]与Order NMS的F-score值对比其他算法得到了明显提升,这也证明了本文算法方法理论部分提出的假设是正确的。仅使用Order NMS 时,受邻近区域预测候选框的干扰,排序滤波算法无法有效发挥其实际作用。Soft NMS[13]算法原本是用来检测重叠物体区域的,本文主要应用其降低得分机制去优化排序滤波算法,因此,结合Soft NMS[13]的Order NMS取得了明显效果。
3.2 重要参数对比
以ICDAR2015[15]数据集为实验基础,在同等实验条件下通过控制变量法对不同阈值进行实验比较。
如表3展示了滤除阈值对实验结果的影响,滤除阈值既允许候选框存在的最小置信度得分,实验时Nt设置为0.1。观察发现,滤除阈值取大取小对实验结果均有提升,滤除阈值取0.6时效果最佳。
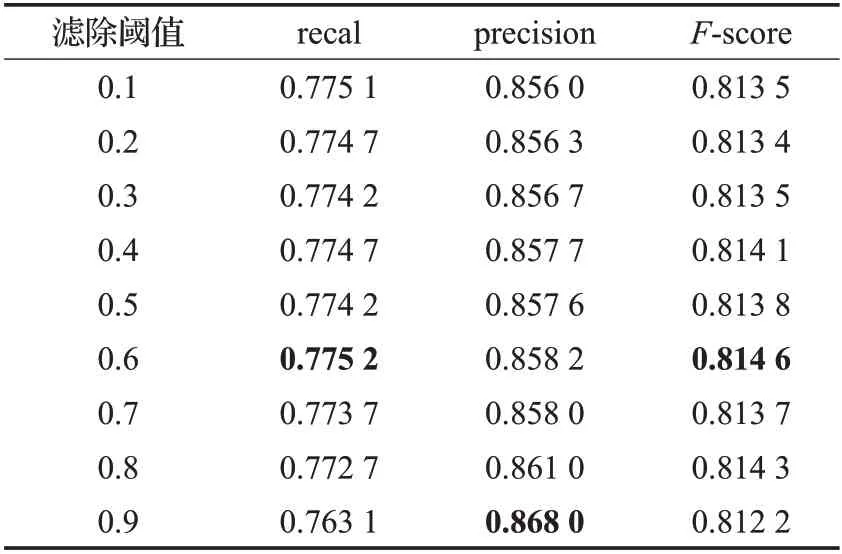
表3 不同滤除阈值下ICDAR2015实验结果对比Table 3 Comparison of ICDAR2015 experimental results under different filtering thresholds
如表4展示了融合阈值对实验结果的影响,观察发现,融合阈值设置过高会减少预融合候选框数量,过低则会加大极端候选框数量,融合阈值取0.3时效果最佳。

表4 不同融合阈值下ICDAR2015实验结果对比Table 4 Comparison of ICDAR2015 experimental results under different fusion thresholds
如表5 展示了N值对实验结果的影响,观察发现,N值越小对实验结果的提升越大,N值取3时效果最佳。

表5 不同N 值下ICDAR2015实验结果对比Table 5 Comparison of ICDAR2015 experimental results under different N values
4 结束语
NMS算法一直都是场景文本检测中的一个重要环节。在本文中,提出了一种基于排序滤波与融合计算的NMS算法。通过在ICDAR2015[15]数据集与MSRATD500数据集上的实验,证明了本文算法能够提高最终的检测结果,并且对长文本和混叠文本的情况更加有效。
