基于单帧标注的弱监督动作定位
2019-04-26周金成
文/周金成
1 引言
随着互联网的发展和社交媒体的普及,网络上视频的数量越来越多,靠人工来处理这些视频不再现实,计算机视觉的发展可以解决海量的视频数据和有限的人员精力的矛盾。计算机视觉中的动作定位任务可以确定视频中动作的位置,也就是在视频的每一帧上用矩形框框住动作的执行者。动作定位有着广泛的应用前景,可以用来截取一段长视频中只包含特定内容的片段,也可以用来追踪监控视频频中逃犯的逃跑轨迹等等。
本文提出一种基于单帧标注的动作定位方法,这是弱监督方法,不必标注训练视频中每一帧图像,只需在每个视频中标注一帧图像即可定位动作。首先在训练视频每一帧上给出动作执行者的矩形候选框,然后连接候选框形成候选动作轨迹,利用人工标注的矩形框去除大量不满足条件的候选轨迹,同时对保留下来的候选轨迹打分,保留得分最高的提名作为训练视频中动作的位置,然后训练一个SVM分类器。测试阶段,先在测试视频的每一帧上给出矩形候选框,然后连接候选框形成候选动作轨迹,利用训练好的SVM分类器对候选轨迹打分,确定哪个候选轨迹是视频中动作的位置。
2 提取候选框
由于滑动窗口方法给出的矩形框数量过多,而且不适用于尺度变化较大的目标,这里利用目标检测方法来提供动作执行者的矩形候选框,这样减少了候选框的数量,同时候选框的质量也提高了,降低后面连接候选框的难度。EdgeBoxes具有很高的召回率而且给出的矩形候选框的数量相对较少,本文利用EdgeBoxes在每个视频中提取帧级别的矩形候选框,但是在每个视频帧上只保留得分靠前的100个矩形框。
3 候选动作轨迹
视频中帧级别的候选框获取后,需要连接候选框形成候选动作轨迹。将候选框连接过程转化成求解最大路径问题,利用文献[2]中MaxPath方法找到一个视频中若干个时序上的路径,每条路径对应一个候选动作轨迹。
4 模型训练和测试
为了确定训练视频中动作的位置,首先利用每个训练视频中标注的一个矩形框,筛除掉大量错误的轨迹,然后计算保留下来的候选轨迹的得分,将得分最高的轨迹作为训练视频中动作的位置。提取每个轨迹的特征,训练一个SVM分类器,利用训练好的分类器可以判定测试视频中哪条候选轨迹与动作的位置最符合。
为去除视频中大量的无效轨迹,计算轨迹上的矩形框与对应标注帧上的标注框的重叠度,只保留重叠度较大的候选轨迹。重叠度的计算公式按照公式(1):

其中,b1表示视频标注帧上的人工标注的一个矩形框,b2表示候选轨迹在标注帧上的对应的矩形框。舍弃的候选轨迹。
计算保留下来的候选轨迹中每个矩形框的光流幅值的平均值f,整个候选轨迹的平均光流幅值按照公式(2)计算:

其中,fi表示候选轨迹上第i个矩形框的光流幅值的平均值,n是候选轨迹上矩形框的数量,score是候选轨迹的得分。最终将众多候选轨迹中得分最高的轨迹作为视频中动作的位置。
将训练视频中得分最高的轨迹作为正样本,其它候选轨迹作为负样本,提取每条轨迹的HOG3D特征,训练SVM分类器:
测试阶段,先获得每一帧上的候选框,然后连接候选框形成多个候选动作轨迹,提取每个轨迹的HOG3D特征,代入训练好的模型中,得分最高的轨迹就是视频中动作的位置。
5 实验结果
实验中使用的数据集是J-HMDB,这是HMDB的一个子集,包含928个视频,有21类动作。划分训练视频和测试视频的比例是3:1.重叠度阈值ξ取值0.6。定位效果公式按照公式(3):
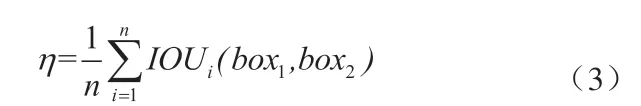
其中,η是模型的定位结果和视频中动作实际位置的重合度,n是视频中动作持续的帧数,IOU是两个框之间的重叠度,box1是标注框,box2是定位结果上对应帧上的矩形框。当η大于0.2即认为定位正确,实验取得了很好的结果,定位的正确率可以达到91.6%。
