基于距离正则化的单视图三维重建
2021-05-19胡茂林李金龙
胡茂林,李金龙,胡 涛
(中国科学技术大学 计算机科学与技术学院,安徽 合肥230027)
0 引言
三维重建是指给定一张或多张RGB 图像的情况下重建该RGB 图像中物体的三维形状。三维重建已经被探索了几十年,它是计算机视觉领域一个基础性任务之一,拥有大量应用场景,例如,机器人导航、虚拟现实、计算机辅助设计、无人驾驶、医学图像处理等领域。三维重建是一个非常复杂的过程,从二维图像恢复三维形状,恢复缺失的信息往往具有歧义性。为克服三维形状的歧义性,三维重建方法通常需要结合图像信息和先验形状知识。
随着大型数据集的出现,数据驱动的方法一定程度上克服歧义性问题,数据集提供三维形状先验知识。三维重建方法利用CNN 在大型数据集进行预测物体三维形状取得了巨大的成功,预测的三维形状可以被归结为三类:体素网格表示[1]、点云表示[2]、网格表示[3]。近年来,大量基于深度学习的方法被提出来进行三维重建,例如,3D-R2N2[4]、Pix2Vox、PSGN[2]和AttSets[5]。CHOY C B[4]率先提出使用长短期记忆网络(Long Short Term Memory,LSTM)[6]来融合不同视角图像的信息,一步一步重建三维物体的形状。PSGN 使用点云表示三维形状进行单视图三维重建。Pix2Vox++直接使用CNN 融合不同视角图像信息来进行三维重建。AttSets 使用一个注意力聚合模块去预测一个权重矩阵作为输入特征的注意力得分。
基于深度学习的方法围绕如何提升重建的三维物体质量问题,提出的解决方案可以概括为三类:(1)为了应对三维形状的变化,增加训练网络的参数数量,以提供更大的先验信息记忆空间,保留更多的先验信息;(2)提供更多的线索,增加不同视角的图像;(3)减少三维形状变化范围,每一个类别的三维形状,单独训练一个模型。Pix2Vox 的实验在多个类别下进行模型参数实验对比,得出增加参数数量可以提升三维物体重建质量。TULSIANI S[7]在每个类别上训练一个模型来提升三维物体重建质量。然而,在深度学习中已经证明,随着参数数量增加到一定程度,模型的性能并不能一直提高[6]。三维重建中增加不同视角图片数量在一些特定情况下并不可行。
本文研究给定一张RGB 图像情况下,重建三维物体的形状,即单视图三维重建。本文基于距离正则化提出了三维残三维重建网络(3D Residual Net work,ResVox)和设计特殊的残差块结构(3D ResBlock)。为了提高重建三维物体的质量,本文提出了软性距离规则化损失,利用真实的三维形状来监督生成的三维形状和三维形状周围空白部分。在三维残差块中设计了基于图像特征的批量归一化(Feature based Batch Normalization,F-BN)。总的来说,ResVox 有以下创新点:
(1)针对提升三维物体质量,提出了距离规则化损失,通过约束生成的三维形状,既考虑三维形状部分,也考虑了三维形状周围的空白部分;
(2)针对方法模型参数,设计了三维残差块和F-BN,F-BN 使用图像特征在深层网络中指导三维形状恢复;
(3)本文在ShapeNet 数据集进行实验,与其他方法进行对比,证明了该方法在三维重建上的有效性。
1 方法
1.1 问题定义
给定一张RGB 图片,单视图三维重建任务是恢复该RGB 图像中物体的三维形状。形式上,三维重建过程的表示成一个映射:

其中I是RGB 图像集合,S是三维形状集合,θ 表示一组参数。三维重建可以简化为学习一个预测函数:

可以预测RGB 图像中物体的三维形状S^与其真实的三维形状的接近程度。
1.2 基于图像特征的批量归一化
基于图像特征的批量归一化是条件归一化的一种,它使用图像特征作为条件,用来计算和产生参 数γ 和β,γ用哈达玛乘(Hadamard Multiplication)乘以上一层的输出和加上β,可以用式(1)表示:

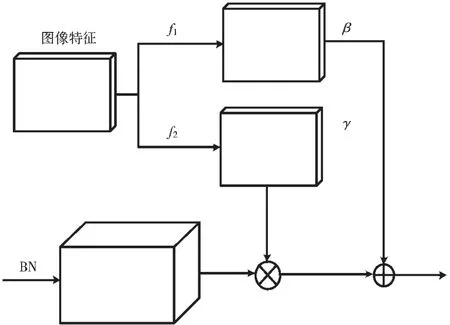
图1 基于图像特征的批量归一化
1.3 网络结构
该模型为三维残差网络,模型整体结构如图2所示,它包含两个模块:图像编码器和三维残差生成器。在ResVox 中给定一张图片,首先通过图像编码器提取RGB 图像的语义信息作为三维残差生成器的输入。三维残差生成器从该语义信息中一步一步恢复三维形状。每个三维残差块中包含二个基于图像特征的批量归一化层。

图2 单视图三维重建网络
1.4 图像编码器
图像编码器将为三维残差生成器计算一组图像语义特征,提供给三维残差生成恢复物体的三维形状。如图3 所示,图像编码器用来从大小为224×224×3 的RGB图像提取大小为512×28×28 的图像语义特征。图像编码器采用修改过后的预训练模型VGG16[8]来固定VGG16 的参数。图像编码器由11 层卷积神经网络层组成,每层卷积神经网络后面跟随一个批量归一化层和非线性激活层。图像编码器的前9 层卷积神经网络和VGG16 前9 层卷积神经网络一样,并且使用预训练好的VGG 的参数。图像编码器中使用的均为二维卷积神经网络,后面的3 层属于可训练二维卷积神经网络层,卷积核大小分别为33、33和33,输出通道大小分别为512、512 和256。第十层和第十一层二维卷积层之间直接使用最大池化(Max Pool)进行下采样操作。

图3 图像编码器结构
1.5 三维残差生成器
三维残差解码器负责将图像的语义特征的信息转换为三维形状。三维残差解码器由五个Res-Block块组成,ResBlock 结构如图4 所示。在三维残差生成器使用的是三维卷积神经网络,卷积核大小都是33。通过控制每层ResBlock 的通道大小,来控制模型参数的数量,ResVox 的第一层残差块的输入通道为2 048,输出通道为512;第二层残差块输入通道为512,输出通道为256;第三次残差块输入通道为256,输出通道为64;第四层残差块输入通道为64,输出通道为32;第五层残差块输入通道为32,输出通道为1,并使用sigmoid 函数对输出体素值约束到0 到1 之间。

图4 三维残差块结构
1.6 损失函数
ResVox 包含两个损失:二值交叉熵损失函数和软距离规则化损失损失函数。二值交叉熵用来度量预测的三维体素和真实的三维体素之间的距离。二值交叉熵损失如式(2)所示,二值交叉熵损失越小,表示重建三维形状与其对应的真实三维形状的距离越小。ResVox 重建的三维形状每个体素(x,y,z)服从伯努利分布[1-p^x,y,z,p^x,y,z],p^x,y,z是预测体素在该位置被三维形状占用的概率,该体素对应的真实体素px,y,z∈{0,1}。

为了提高重建三维物体的质量,提出了软距离正则化损失,如式(3)所示。m+是在三维体素空间中三维物体对应部分的软间隔,m-是三维体素空间中三维形状周围空白对应的软间隔,λ 是超参,代表对三维形状周围空白的体素关注度。
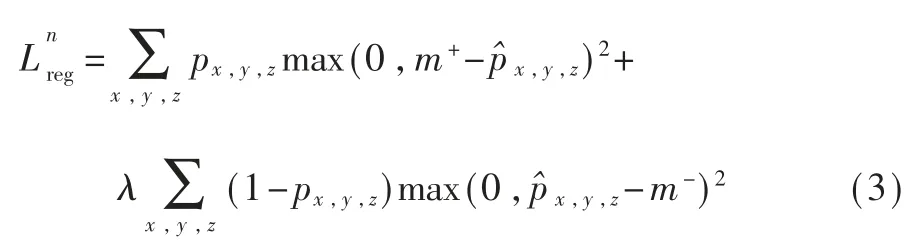
模型ResVox 的整体损失是二值交叉熵损失加上距离正则化损失,如式(4)所示:

其中η 表示正则化损失的作用,N是批量大小。
2 实验
2.1 三维形状表示
本文中三维形状使用三维体素表示,属于图像的像素在三维空间的一般化。三维形状在一个规则的体素网格R3,使用二进制表示,0 表示空白,即没有占用该体素网格;1 表示非空白,该体素被三维形状占用。
2.2 数据集
为了验证ResVox 的有效性,在大型数据集Shape-Net[9]的一个子集合上面进行实验。它包含13 个大类别的三维形状,总共43 783 个三维模型,表1 展示了各个类别数据的详细信息。把数据集分成训练集和测试集合,训练集占4/5,测试集占1/5。训练集中再划分训练集的2/5 作为验证集合,剩下的作为训练数据。在整个实验中把这两个数据集称为ShapeNet 测试集和ShapeNet 训练集。
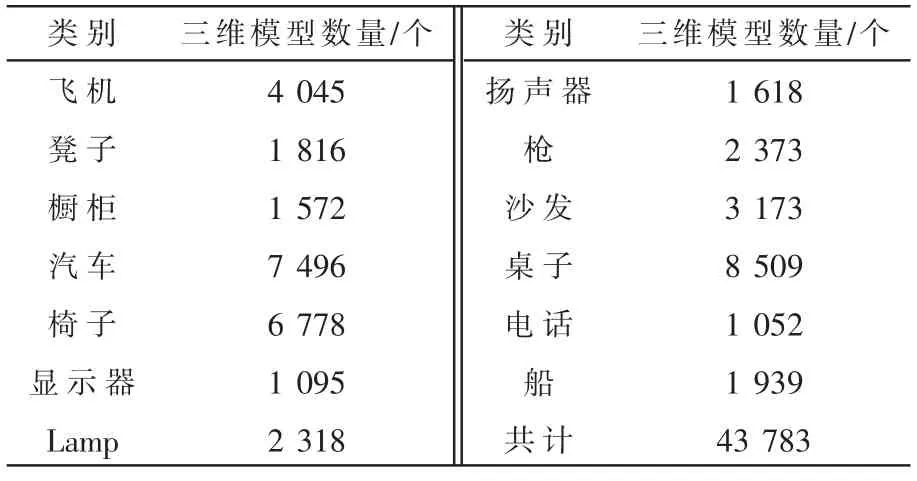
表1 ShapeNet 数据集
2.3 实验设置
所有三维形状用单通道三维体素表示,它的大小被设置为323。图像编码器和三维残差生成器网络同时训练。正则化损失中λ 被设置为0.4,整体损失中η 被设置为1。模型ResVox 的所有可训练参数初始化使用Xavier 方法[10],采用Adam[11]优化算法,其中β1等于0.9,β2等于0.999,所有的激活函数采用ReLU 函数[12]。训练批次大小为128,学习率初始设为0.001,在第150 次和第200 次,学习率衰减一半。采用PyTorch-1.7 实现该模型,并在一个Nvidia RTX 3 090 显卡上运行。训练模型总共600 次。
2.4 实验评价指标
为了评价模型生成的三维形状的质量,采用IoU 作为相似度评价。IoU 是测量预测到的三维形状与其对应真实的三维形状的交集比上它们的并集。IoU 值大于等于0,小于等于1。将模型概率化的三维形状输出二值化。IoU 的计算公式如式(5)所示。

式中,I(·)是一个指示函数(Indicator Function),t是二值化预测三维形状的阈值,,y,z是体素在(x,y,z)位置的预测值,Vx,y,z是体素在(x,y,z)位置的真实值。IoU 值越高,标志重建的三维物体质量越高。
2.5 模型参数分析
由于统计模型参数数量需要原作者的代码,选取3D-R2N2、OGN[13]、Pix2Vox 进行时参数数量对比。如表2 所示,该模型比之前最好的模型Pix2Vox 减少了约4 千万的参数。

表2 模型参数对比
2.6 重建效果对比
为了评价方法重建效果,在ShapeNet 数据集上与几个方法进行重建质量和视觉效果对比实验,重建质量使用IoU 评价指标进行评价。这些方法包括3D -R2N2、OGN、DRC[7]、PSGN、Matryoshka[14]、Atlas-Net[15]、Pixel2Mesh[16]、OccNet[17]、AttSets[5]和Pix2Vox。如表3 所示,ResVox 在13 个类别的10 个类别IoU中评价胜出,整个数据集取得最好的重建效果,重建效果图对比如图5 所示。
2.7 消融实验
对距离正则化损失和基于特征的批量归一化进行消融实验,如表4 所示。共进行四组对比实验,Y 表示使用该损失进行训练或者使用该模块,N 表示不使用该损失进行训练或者不适用该模块。ResVox-和ResVox 网络结构一样,ResVox-未使用距离正则化损失进行训练,实验结果显示IoU 仅仅平均提升0.08,使用正则化损失IoU 平均提升了0.15。ResVox+是ResVox 删除F-BN 模块的一个变体模型,即ResVox+的网络结构其模块和ResVox 相同。ResVox*代表去掉F-BN。实验结果如表3 所示,F-BN对三维重建质量提升有部分帮助,结合距离正则化损失效果更好。

表3 在ShapeNet 测试数据集上各个类别IoU 对比(最好的结果用加粗强调)

图5 单视图三维重在ShapeNet 测试集上部分示例模型对比

表4 消融实验配置
3 结论
本文提出基于距离正则化的单视图三维重建,针对使用图像特征在恢复三维形状,设计了残差生成器网络和提出了距离正则化损失来约束三维形状。此外,在残差生成器恢复三维形状过程中,使用基于图像特征的批量归一化,在每个残差块中融合图像信息。消融实验结果显示了正则化损失和F-BN 的有效性。同时,在网络参数的对比中,使用的参数比之前最好的方法要降低将近40%。综上,在ShapeNet 数据集上,该方法在IoU 评价指标上取得了良好的结果。
