基于AE-SVM 的嗅觉描述符分类*
2021-05-19朱红梅骆德汉莫卓峰
朱红梅,骆德汉,莫卓峰
(广东工业大学 信息工程学院,广东 广州510006)
0 引言
嗅觉是人类的一种化学感官,它通过感知空气中的化学物质来了解周围的环境。以往的研究表明,感知到的化学刺激与生物嗅觉系统复杂的组织结构有关[1-2]。嗅觉上皮内的嗅觉受体神经元与分子结合并向嗅觉神经提供电信号时被激活,信号被传送到嗅球并在嗅球上形成图案。然后,根据嗅球上的反应模式,在大脑进行与情绪和记忆相关的综合信息加工[3]。由于每种类型的嗅觉受体具有不同的分子选择性,因此出现在嗅球上的刺激模式因分子而异。也就是说,对气味的印象也因分子而异。
气味感官评价测试已被广泛采用,获得通过语言描述符量化的嗅觉描述符。嗅觉描述符的提取不仅在食品和化妆品行业,而且在其他行业的消费产品评价[4]中都是必不可少的。对大量化学品进行感官评估测试需要大量的时间和资源,本身是不切实际的。因此,本研究的目的是通过有限的样本分析,建立数学模型来预测嗅觉描述符。质谱是化学物质具有代表性的物理化学性质之一,早期的研究阐明了化学物质的气味与其化学结构之间的关系[5]。大量的质谱数据可以用来构建嗅觉描述符的预测模型。一些研究通过主成分分析(PCA)和非负矩阵分解(NMF)等线性建模方法报道了化学物质气味特征与其理化参数之间的关系[6-7]。这些研究表明,一些基本参数确实会影响人们对气味的感知。由于质谱数据本质上是高维稀疏的,虽然PCA 和NMF 是众所周知的预测建模方法,但它们不适合高维稀疏的数据结构。因此,很难得出这些线性建模技术与系统完全兼容的结论。深度学习建模是非线性建模中最权威的方法之一,具有广泛的应用前景。本文设计AE-SVM 来对质谱数据进行提取特征并完成对嗅觉描述符的分类。
1 方法
1.1 自动编码器
自动编码器(Autoencoder,AE),作为一种在半监督学习或无监督学习中常用的神经网络模型,可以很好地学习到数据的隐含特征。从直观上来看,由于AE 模型可以有效地提取出数据的特征,AE 模型可以直接用于特征降维[8]。一般而言,AE 模型由编码器(encoder)和解码器(decoder)两个部分组成。在训练过程中,编码器的输出通常作为解码器的输入,将解码器的输出值(即自动编码器的目标值)设置成与编码器的输入值 (即自动编码器的输入值)相等。通常采用反向传播算法训练AE 模型并得到最优参数。
1.2 支持向量机
支持向量机(Support Vector Networks,SVM)最初被CORTES C 等人应用到机器学习的分类任务中[9]。其原理如图1 所示,支持向量机使用最大化超平面来解决二分类问题。随着机器学习的发展,如今,支持向量机在多分类问题上也能获得很好的效果,广泛用于分类、回归和异常值检测的监督学习。
一般来说,支持向量机在多分类问题上有两种方法,分别是成对分类方法(one-against-one)[10]和一类对余类方法(one-against-all)[11]。假设训练集有M个类别,成对分类方法则在每两个类之间构造一个二分类支持向量机(binarySVM)。如图2 所示,在一个3 分类问题中,d12、d13、d23表示二分类支持向量在1 类和2 类、1 类和3 类以及2 类和3 类数据之间的决策边界。对于第i类和第j类数据,其求解一个二分类支持向量机为:
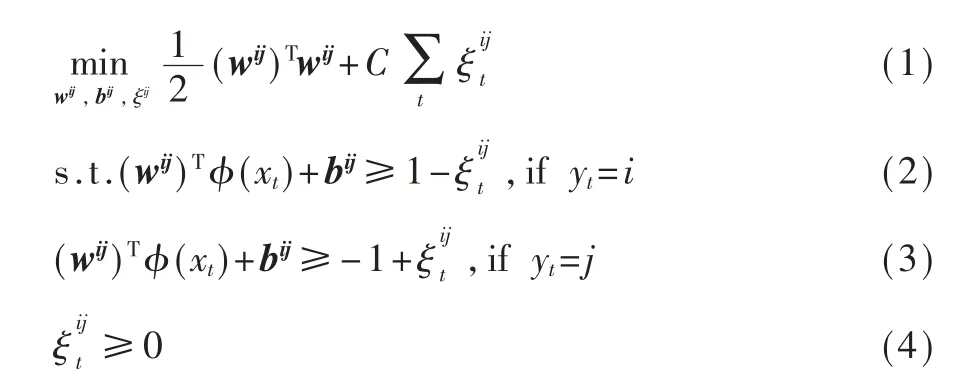
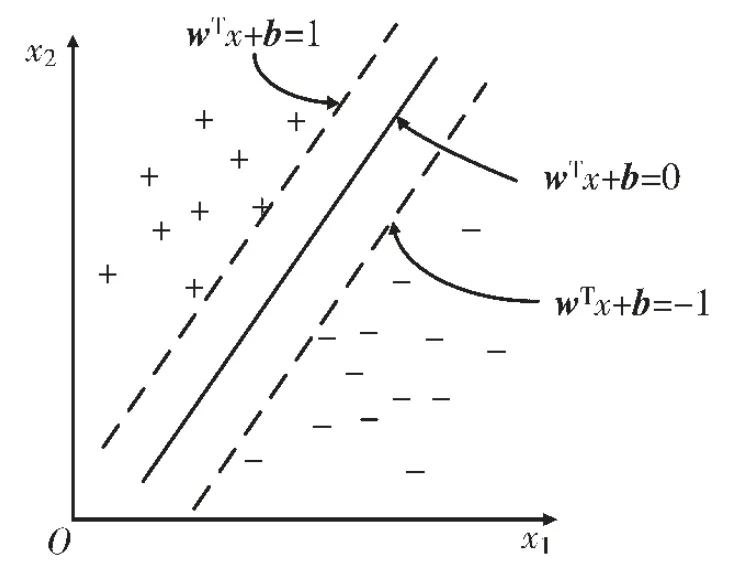
图1 SVM 原理
其中,上标表示是i类和j类之间的参数;t表示i类和j类的并集中样本的索引;表示输入空间到特征空间的非线性映射。第i类和第j类的决策函数为:
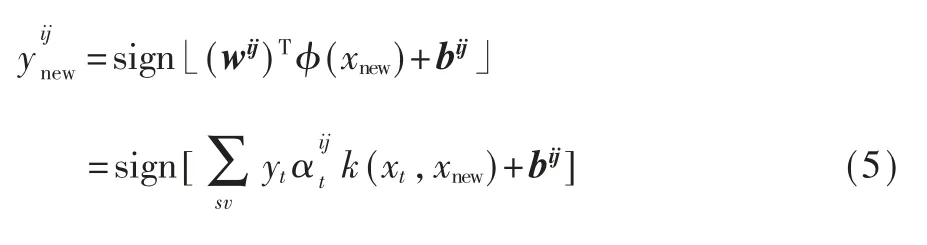
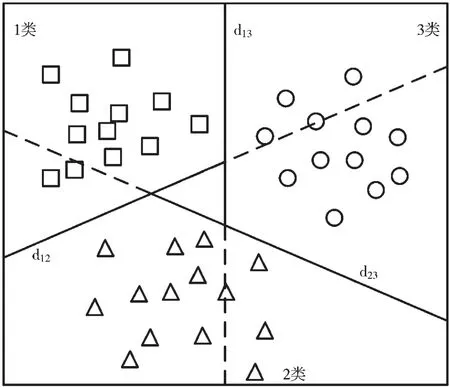
图2 SVM 成对分类方法
最后对新的数据投票进行分类。而一类对余类方法则是对每一个类作为类,其余所有类作为类构造二分类支持向量机,如图3 所示。两种方法各有优缺点,一类对余类方法因为训练集是一对多,容易存在偏差。经过HSU C W 等人的比较[11],成对分类方法适合实际使用,因此,本文使用这种方法对质谱数据进行分类。
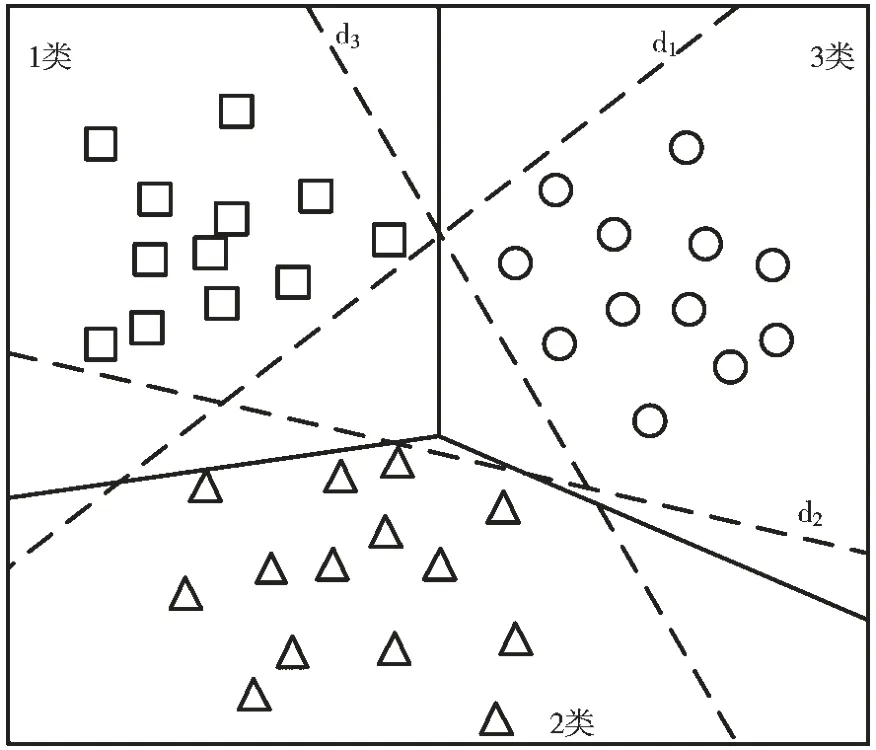
图3 SVM 一对余类方法
2 实验
本研究的AE-SVM 对嗅觉描述符分类流程如图4 所示。将数据集分为训练集和测试集,这个数据集将在2.1 节进行介绍。训练集经过数据预处理后放入设计好的AE 模型中进行训练,数据预处理的过程和AE 模型将分别在2.2 节和2.3 节进行介绍。在保存之后,评估AE 模型的性能并保存性能最好的参数,再使用AE 模型得到训练集降维后的特征,并训练SVM 模型。最后得出AE-SVM 模型并使用测试集评估该模型,得到的结果呈现在2.5 节中。
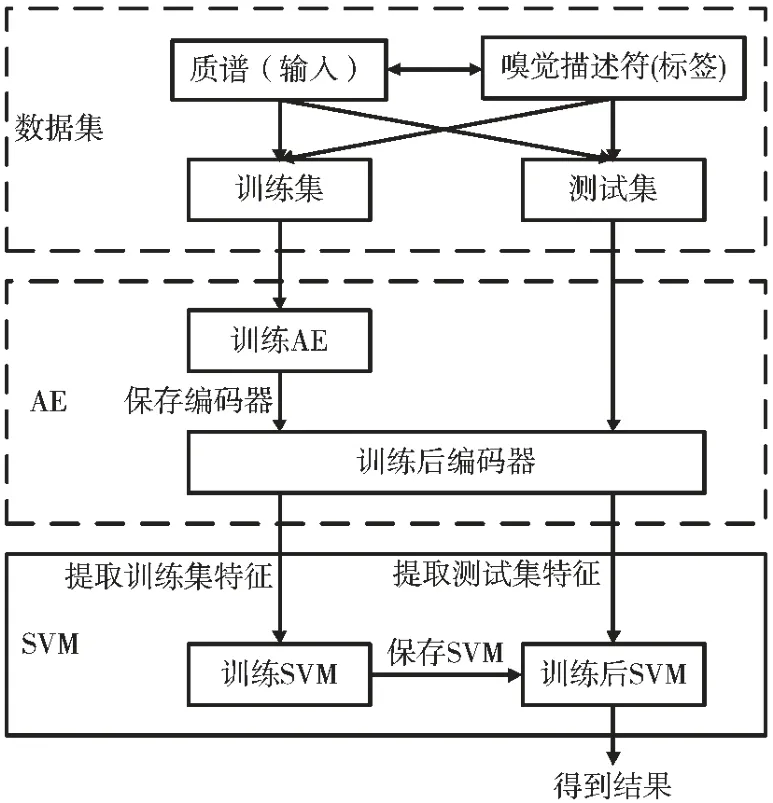
图4 AE-SVM 流程图
2.1 数据集
质谱是代表分子结构信息的物理化学性质,以强度与m/z(质荷比)的关系图形式给出。给定相同的测量条件,可以为每个分子确定质谱。因为可以在统一条件下执行许多质谱测量,可以使用大规模质谱数据集。这项研究中使用的质谱数据集来源于美国国家标准技术研究所(NIST)开源数据[12]。该数据库由100 000 多种通过70 [eV]电子电离获得的质谱化学物质组成。m/z 低于50 的强度通常源自无味的分子,例如氧气、氮气和二氧化碳,而高的强度源自挥发性低且对气味特性影响很小的分子。因此,本研究从原始数据集中提取了51 至262 m/z 的强度。
西格玛奥德里奇(Sigma-Aldrich)已发布了一份化学品目录,其中使用数百种描述符,对1 000 多种单分子气味物质进行了分析[13]。在目录中,每种物质的气味特征通过约150 种不同的描述符来描述,如balsam(香脂)、caramel(焦糖)、spicy(辛辣的)等。尽管目录中的信息有时可能不足以详细描述化学物质的气味,但由于它描述了化学物质的气味,因此它仍然是一种有价值的工具。
以Sigma-Aldrich 目录和NIST 数据集中列出的化学物质为例,共获得了999 个样品,去除没有收集到对应质谱的cas 号,最终得到了987 个样品,每个样品的提取了51 ~262 m/z 的强度,最终得到987×212 的质谱数据。从Sigma-Aldrich 目录的数据集中的150 个描述符中选择136 个(因为其他14 个描述符在目录中只出现了3 次或更少)。因此获得了987 个cas 号对应136 个嗅觉描述词,构建987*136 维的矩阵数据。随后找出每个嗅觉描述词对应cas 号数量大于50 的质谱数据和嗅觉描述符,最终本文实验以9 种嗅觉描述符作为分类目标。
2.2 数据预处理
在第2.1 节中获得的数据是不平衡数据,样本太小的类无法提取到太多特征,导致很难从中提取规律。过度依赖有限数量的样本来训练的模型很可能会导致过拟合的问题出现。本文使用SMOTE 过采样来解决嗅觉描述符标签数据不均衡的问题,通过增加采集数量较少类别的样本数量来实现平衡。SMOTE 过采样改进的随机过采样方法,克服了随机过采样在训练模型后使得模型泛化性能不足的问题。通过向少数类添加随机噪声、干扰数据或特定规则来生成新的合成样本。
由于质谱数据数量较大,区间范围较大,很多数据进行补0 处理,会影响到数据分析的结果。为了消除数据范围的影响,需要对数据进行归一化处理。原始数据经过数据归一化处理后,各数据处于同一数量级,利于后续实验的进行。本文使用离差标准化,如式(6)所示,对原始数据进行线性变换,以得到0 到1 之间的值:

2.3 构 建AE 模 型
质谱数据集的数据是高维数据,每个样本有数百个维度,噪声多,计算量大,会使实验结果的精确度降低。这个数据集有接近75%的数据标记为0,使得整体样本非常稀疏。当样本数量有限时,模型的预测能力会随着维数的增加而降低。
降维,即特征提取,是神经网络中常用的一种方法,它可以在实现有效投影函数的同时,避免因高维而产生的问题。自动编码器是一种常用的降维方法,它通过无监督学习输入数据的隐含特征,同时可以解构出原始输入数据。由于存在“维数灾难”的问题,当特征向量的大小没有得到优化时,编码器的性能会下降。本研究使用的自编码器有五层,其中三层为隐藏层,如图5 所示。使用PyTorch 进行建模,将编码器的输出设置为50,采用ReLU 函数作为每层网络的激活函数。优化器选用Adam 优化器,并将学习率设置为0.001。AE 模型在训练完之后,保存编码器,用于提取质谱数据特征。具体结果和分析请看2.5 节内容。
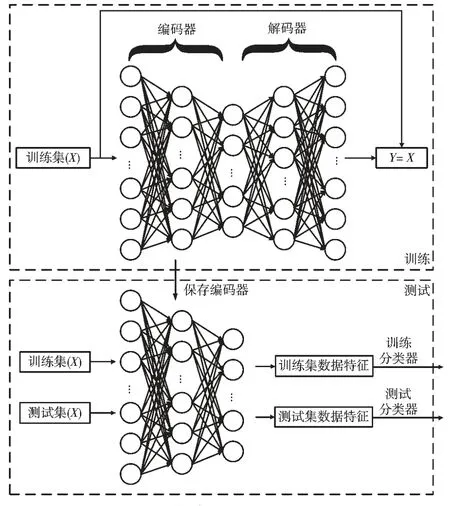
图5 构建AE 模型流程图
2.4 构 建SVM 模 型
将实验数据通过自动编码器进行特征提取以后,原本的212 维原始质谱数据将转化为50 维的特征向量,然后使用SVM 算法进行分类。本文使用Python 调用sklearn 机器学习库中的SVM 函数进行建模。选择高斯核函数作为SVM 的核函数,并将gamma 参数设置为auto。在5 折交叉验证后,保存交叉验证效果最佳的SVM 模型作为最终测试集使用的分类模型。
2.5 实验结果与分析
本文将AE-SVM 模型应用于嗅觉描述符的分类中,将数据集按照3:1 的比例划分为训练集和测试集。首先,通过AE 模型得到原始质谱数据的50 维特征。如图6 所示,使用均方误差(MSE)作为损失函数,利用训练集数据对模型进行训练。由图6 可以看出,本实验设置300 个epoch 进行迭代。随着迭代次数的增加,AE 模型的损失函数下降逐渐缓慢。epoch大约为200 的时候,误差下降到了0.014 6 且函数趋于收敛。可以看到,AE 模型的训练过程符合预期。
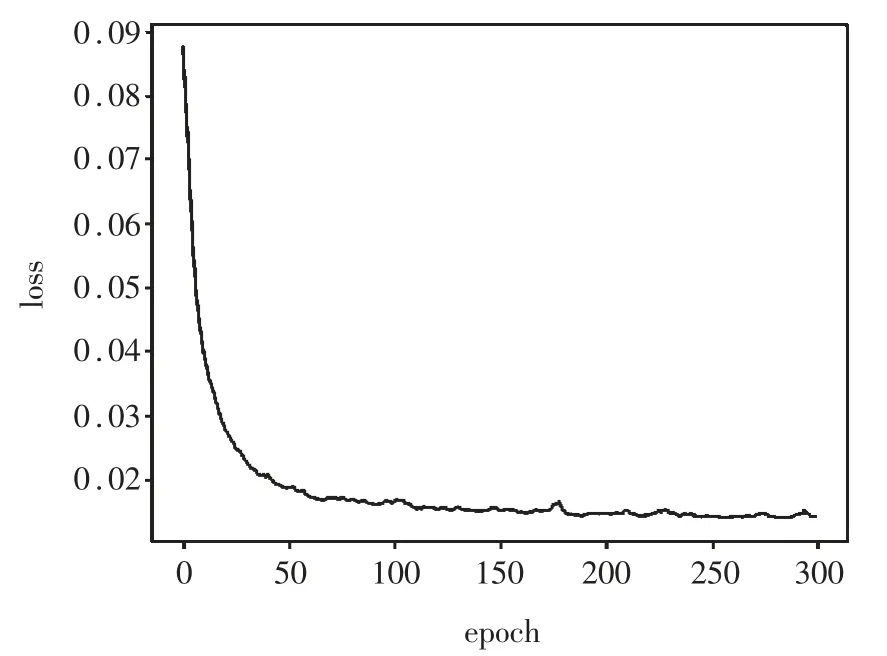
图6 AE 模型训练损失
为了验证AE 模型对质谱数据进行特征提取的性能,本文构建了PCA、LDA 和TSNE 3 种主流的机器学习特征提取方法与AE 模型做对比。表1 表示了测试集经过分别经过PCA、LDA、TSNE 和AE 特征提取之后,经由SVM 模型进行分类的结果。可以清晰地看到,经过AE 对质谱数据进行特征提取之后,SVM 对嗅觉描述符的分类准确度达到了85.71%,明显高于PCA+SVM、LDA+SVM 和TSNE+SVM 的71.43%、67.86%和75%。这表示本文设计的AE 模型能准确地从质谱数据中提取出主要的特征,并且效果优于其他方法。
为了更好地验证SVM 模型对质谱数据特征预测嗅觉描述符的效果,本文构建了KNN 和GaussianNB两个常用的机器学习分类器与SVM 做对比。如表2所示,质谱数据经过AE 模型进行特征提取之后,分别使用SVM、KNN 和GaussianNB 进行分类。从表2中看出,SVM 对AE 模型提取的质谱数据特征具有更好的预测效果,其准确度达到了85.71%。而KNN 和GaussianNB 对质谱数据特征预测嗅觉描述符的准确度仅有76.43%和78.57%。AE-SVM 模型明显更适合质谱数据预测嗅觉描述符。另一方面,由于质谱数据高维且稀疏的特点,在不使用特征提取的情况下,仅使用质谱原始数据,单独使用SVM、KNN 和GaussianNB进行嗅觉描述符预测的准确度分别仅有27.14%、30.71%和14.29%,远远无法达到预测效果。
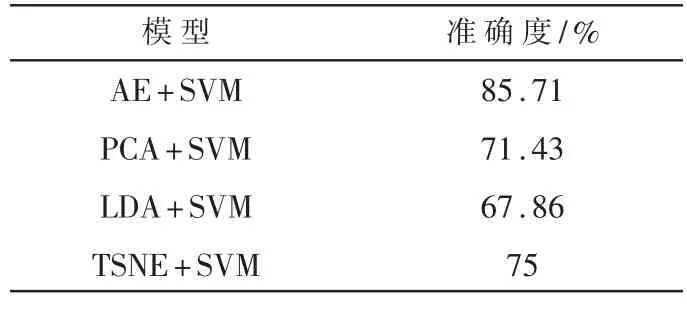
表1 特征提取模型准确度对比
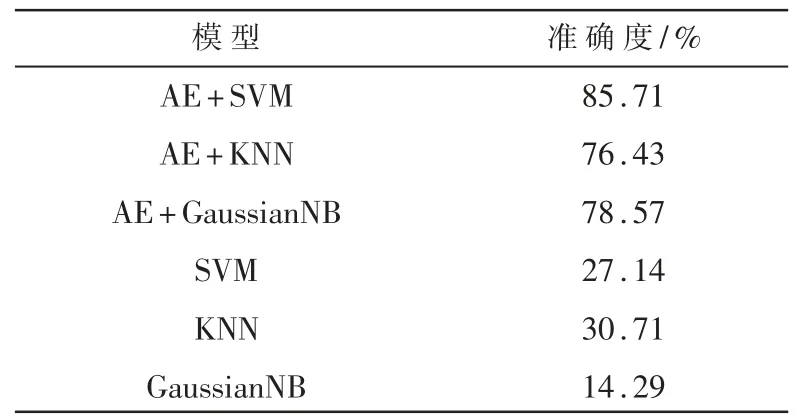
表2 模型分类准确度对比
3 结论
本文提出了一种AE-SVM 分类模型,该模型通过输入质谱数据预测其所属的嗅觉描述符类别。AE 算法将高维稀疏的质谱数据进行特征提取,与SVM 算法相结合,成功使用了质谱数据对嗅觉描述符进行分类并获得不错的分类效果,使其达到了85.71%,远优于其他算法。
