基于分层信息过滤的生成式文本摘要模型*
2021-05-19符升旗李金龙
符升旗,李金龙
(中国科学技术大学 计算机科学与技术学院,安徽 合肥230026)
0 引言
自动文本摘要模型旨在提取出原文中的关键信息并生成摘要。对自动文本摘要的研究可以分为两大类:抽取式文本摘要和生成式文本摘要。抽取式文本摘要直接从原文中抽取出一些句子组成摘要,而生成式文本摘要首先构建一个模型对原文中的信息进行理解,然后根据对原文的理解以模拟人类的方式输出摘要。本文主要关注生成式文本摘要模型。
目前,生成式文本摘要模型主要基于序列到序列(sequence-to-sequence,seq2seq)模型构建[1-2]。seq2seq模型包含一个编码器和一个解码器。编码器对输入的原文进行编码得到文本表示,解码器对编码器的输出进行解码生成摘要。在实际中,输入文本通常包含冗余信息,即噪声[3],而seq2seq 模型会将输入文本的所有信息进行编码,包括噪声,这会导致最终生成的摘要不能很好地体现原文中的关键信息[4]。最近的一些研究[4-5]表明,对输入文本中的噪声进行过滤能提高摘要模型的表现。
对输入文本中的噪声进行过滤通常包含两个步骤[4-5]:(1)根据编码器的输出(局部向量)计算得到全局向量,全局向量代表了输出文本的整体表示;(2)根据全局向量和局部向量计算门向量,然后将局部向量和门向量按元素对应位置相乘,来实现对输入文本中语义噪声的过滤。例如,ZHOU Q[5]等人使用长短时记忆网络(Long Short Time Memory,LSTM)作为模型的编码器,然后将编码器最后一个时间步的输出作为全局向量进行噪声过滤。LIN J[4]等人使用基于卷积神经网络(Convolutional Neural Network,CNN)的方法对编码器的输出进行卷积得到全局向量,之后使用全局向量进行噪声过滤。
这种噪声过滤方法存在两个问题:(1)在计算全局向量的过程中存在信息损失。例如,ZHOU Q[5]将LSTM 最后一个时间步的输出作为全局向量,没有考虑其他时间步的输出,这会造成信息损失。LIN J[4]使用基于CNN 的方法来计算全局向量,而CNN 中的卷积操作会导致输入文本中位置信息的丢失[6],也会带来信息损失问题。由于信息损失,全局向量不能很好地表达输入文本整体的含义,从而影响到噪声过滤的过程。(2)噪声过滤算法存在信息被过度过滤的问题。在噪声过滤的过程中,首先通过全局向量和编码器的输出计算出门向量,由于门向量中的元素值都在0 到1 之间,将门向量和编码器的输出按元素对应位置相乘实现噪声过滤的过程中,不止噪声会被过滤,关键信息也会被削弱,从而造成信息被过度过滤的问题。
为了解决上述的两个问题,本文提出了基于动态路由的分层噪声过滤层,首先使用动态路由算法计算全局向量来避免信息损失,动态路由算法的思想来自于胶囊网络[7]。胶囊(Capsule)是一组神经元的集合,它能比普通的神经元包含更多的信息(例如位置信息)。在动态路由的过程中,编码器每个时间步的输出都被看做是一个胶囊,并参与运算,避免了使用LSTM 计算全局向量中信息损失的问题。此外,因为胶囊中包含了位置信息,避免了使用CNN 计算全局向量中的位置信息丢失问题。然后使用分层噪声过滤算法对噪声过滤过程进行清晰地建模并且避免了信息被过度过滤的问题。具体来说,分层噪声过滤算法在词层面和语义层面对噪声进行过滤,首先通过全局向量和编码器的输出选择输入文本中的关键字,然后使用双门语义噪声过滤算法在语义层面对输入文本进行噪声过滤。在文本摘要数据集Gigaword和CNN/Daily Mail 上的实验结果验证了方法的有效性。
1 方法
图1 描述了模型的结构,其由三部分组成:编码器、基于动态路由的分层噪声过滤(Dynamic Routing Based Hierarchical Information Filtering,DRBHIF)层以及解码器。输入文本首先通过编码器进行编码得到文本表示,即局部向量。DRBHIF 层则首先根据局部向量,通过动态路由算法计算得到全局向量,然后根据全局向量进行分层噪声过滤。具体来说,首先根据全局向量和局部向量进行词层面的关键字选取,然后通过双门语义噪声过滤算法进行语义层面的噪声过滤。
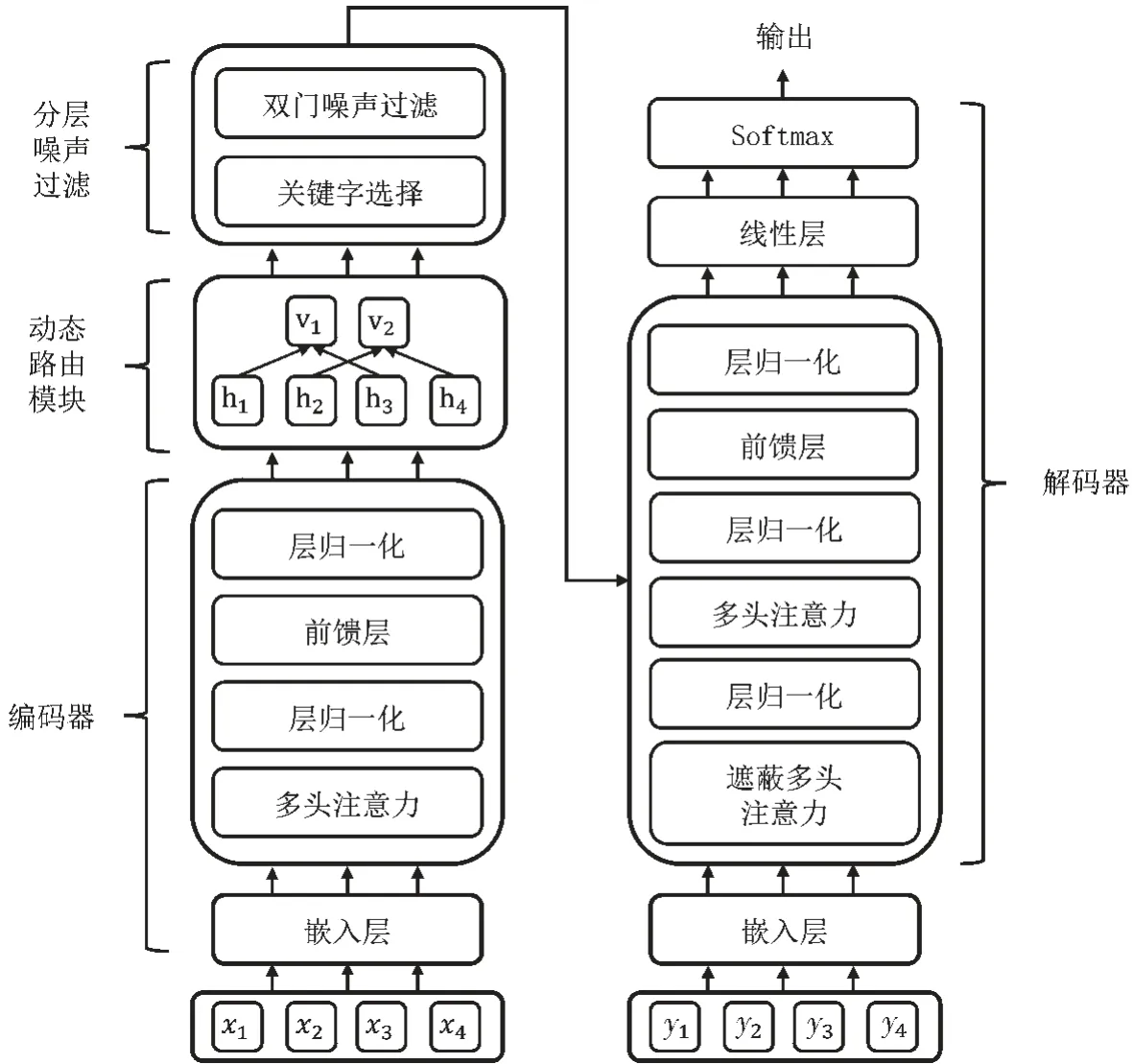
图1 模型结构图
1.1 编码器
给定长度为n的输入文本S=(x1,x2,…,xn),其中,xi表示S中的第i个单词。编码器对S中的单词编码得到S的文本表示H=(h1,h2,…,hn),其中,hi为单词xi的文本表示。编码器基于Transformer[8]构建,它由N个堆叠的层组成。编码器的每一层包含两个模块:自注意力模块和前馈神经网络(Feed-Forward Network,FFN)模块。每两个模块之间使用残差连接,并且对FFN 的输出应用层标准化。编码的过程如下列公式所示:

自注意力模块的输入为三个矩阵:查询矩阵Ql∈Rn×dn、键 矩阵Kl∈Rn×dn和值矩阵Vl∈Rn×dn,其中,dn是矩阵的维度。这三个矩阵是由前一层的输出Hl-1经线性变换得到。最终,自注意力模块的输出Zl通过式(4)计算得到:
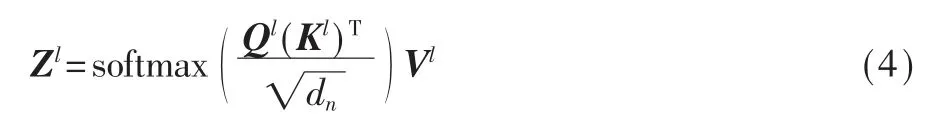
1.2 动态路由模块
动态路由模块根据编码器的输出H动态地计算出全局向量V,全局向量会指导接下来的分层信息过滤过程。
将编码器的输出H=(h1,h2,…,hn)作为输入胶囊,将全局向量V=(v1,v2,…,vm)作为输出胶囊,其中,vi是第i个输出胶囊,m是输出胶囊的个数。在动态路由的过程中,第i个输入胶囊传送到第j个输出胶囊的信息比例是由因子cij确定的,cij的计算方法如式(5)所示:

其中,bij是初始化为0 的对数几率。根据信息传送的比例cij,则从第i个输入胶囊hi传送到第j个输出胶囊vj的信息mij可由式(6)得到:

其中,Wch为权重矩阵。第j个输出胶囊vj从所有输入胶囊接收到的信息mj可以通过式(7)计算:

对mj应用一个非线性的挤压函数(Sqush Function)得到第j个输出胶囊vj,然后根据vj和第i个输入胶囊的相似度更新对数几率bij,如式(8)和式(9)所示:
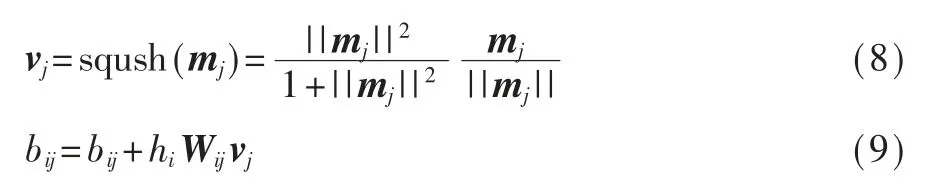
其中,Wij为参数矩阵。
1.3 分层信息过滤
分层信息过滤在两个层面对输入文本中的噪声进行过滤,分别是词层面的关键字选择和语义层面的双门噪声过滤。
1.3.1 关键字选择
该模块旨在根据全局向V和编码器的输出H对输入文本中的关键字进行选择。首先根据V和H计算权重向量α,如式(10)所示:
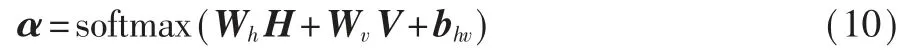
其中,Wh和Wv为权重矩阵,bhv为偏置向量,α=(α1,α2,…,αn),αi对应第i个单词wi的重要程度,αi越大,wi越重要,从而被当做关键字。将α和H相乘得到输入文本中的关键字表示,如式(11)所示:

1.3.2 双门语义噪声过滤
双门语义噪声过滤算法包含两个门:过滤门和补充门。过滤门对输入文本中的语义噪声进行过滤,补充门根据过滤门过滤的结果,将原文中的信息补充回一部分形成最终的文本摘要,这样可以避免信息被过度过滤的问题。过滤门的计算方法如式(12)和式(13)所示:

其中,Whf、Wvf和bf为可训练的参数,σ 表示Sigmoid激活函数,⊗表示按矩阵元素对应位置相乘。
补充门d由过滤后的文本表示和关键字的初始表示通过式(14)计算得到:

其中,Whd、Wvd和bd为可训练的参数。最后,根据补充门d,补充一部分原文中的信息组成最终的文本表 示:

1.4 解码器
解码器对过滤后的文本表示进行解码生成摘要。解码器的结构类似于编码器,也是由N个相同的层叠加组成。解码器最后一层的输出被记为D,在生成摘要中的第t个单词时,将D输入到一个线性层生成单词分布Pvocab,如式(16)所示:

其中,Wo和bo是可训练的参数。最终,通过单词的分布Pvocab得到第t个输出单词。
2 实验结果及分析
2.1 实验数据集
为了验证模型的有效性,在两个公开的文本摘要基准数据集Gigaword[9]和CNN/Daily Mail[10]上进行了实验。两个数据集均由原文—摘要数据对组成。其中,Gigaword 包含380 万条训练样本,8 000 条验证样本和2 000 条测试样本。CNN/Daily Mail 数据集包含28 万条训练样本,1 万条验证样本和1 万条测试样本。两个数据集的具体统计数据如表1 所示。
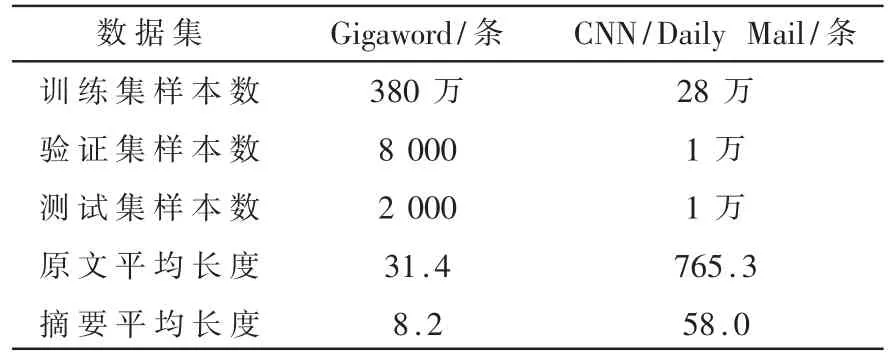
表1 实验数据集描述
2.2 实验设置
基于Transformer[8]构建模型,模型的编码器共有12 层,解码器也有12 层。词向量的维度为1 024,隐状态的维度为768。在多头注意力中,注意力头的个数被设置为12。使用预训练的模型权重MASS[11]来初始化模型参数。使用Adam[12]随机梯度下降优化器对模型进行训练,在Adam 优化器中,β1被设置为0.9,β2被设置为0.999,∈被设置为1×10-8。模型的初始学习率被设为0.000 1,使用sqrt 学习率调度器在训练过程中动态地减小学习率。为了防止过拟合,在模型中引入了Dropout[13]机制,并设置dropout率为0.1。在模型训练的过程中,设置模型训练的批量大小为64。在两块NVIDIA RTX 2080 SUPER GPU 上进行实验。为了加快训练速度并减小显存占用,使用了混合精度训练[14]。
2.3 评价指标
参照之前的工作,使用ROUGE[15]作为模型的评价指标。ROUGE 通过计算模型生成的摘要和参考摘要之间的n元组(n-grams)的召回率来衡量模型生成摘要的质量。在本实验中,使用ROUGE-1(1 元组)、ROUGE-2(2 元组)和ROUGE-L(最长公共序列)作为具体的评价指标。
2.4 模型比较
2.4.1 Gigaword 数据集
将模型在Gigaword 数据集上和SEASS[5]、CGU[4]、BiSET[16]、UNILM[17]、MASS[11]和PEGASUS[18]进行了比较。其中,SEASS、GCU、BiSET 也采用了噪声过滤的思想,UNILM、MASS、PEGASUS 则是目前最先进的模型。在Gigaword 数据集上各模型的实验结果如表2 所示。
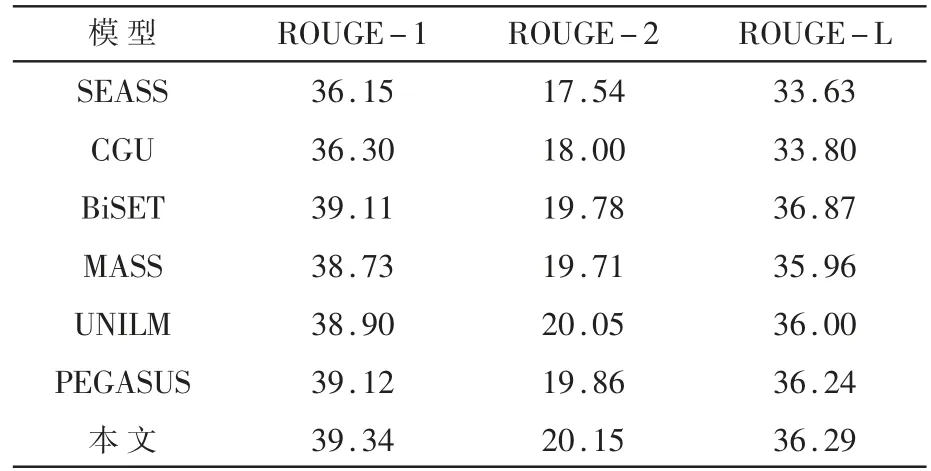
表2 各模型在Gigaword 数据集上的实验结果
对比模型的所有结果均来自其原始文献。结果表明,模型在Gigaword 数据集上的ROUGE-1 和ROUGE-2 两个指标上均超过了对比模型。相比于之前噪声过滤模型BiSET,模型在ROUGE-1 上提升了0.23,在ROUGE-2 上提升了0.37。相比于基模型MASS,模型在ROUGE-1 上提升了0.61,在ROUGE-2 上提升了0.44,在ROUGE-L 上提升了0.33。
2.4.2 CNN/Daily Mail 数据集
将模型在CNN/Daily Mail 数据集上和BottomUp[19]、EditNet[20]、DCA[21]、BERTSum[22]、MASS[11]进 行 了 比较。各模型在CNN/Daily Mail 数据集上的实验结果如表3 所示。
对比模型的所有结果均来自其原始文献。结果表明,模型在ROUGE-1 和ROUGE-L 上超过了所有的对比模型。相比较于基模型MASS,模型在ROUGE-1 上提升了0.19,在ROUGE-2 上提升了0.02,在ROUGE-L 上提升了0.35。
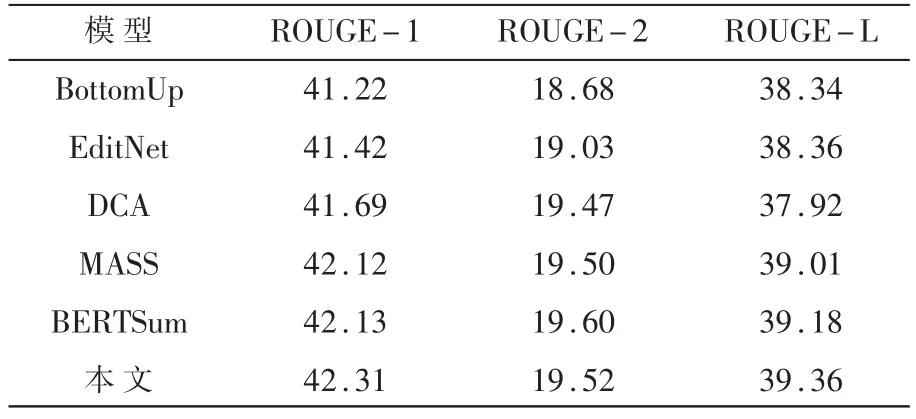
表3 各模型在CNN/Daily Mail数据集上的实验结果
2.5 参数分析
输出胶囊的个数m在计算全局向量时是一个关键参数,因为全局向量是由m个输出胶囊组成的。当输出胶囊个数过少时,由输出胶囊传送到输出胶囊的信息会发生一定程度的损失,而当输出胶囊过多时,输出胶囊和输出胶囊会比较相似,这会导致由输出胶囊组成的全局向量不能很好地表达输入文本的全局含义。将输出胶囊的个数m在{1,2,4,8}范围内进行实验,实验结果见图2。从图2 中可以看出,随着输出胶囊个数的增加,模型的ROUGE-1得分先上升后下降,这与之前的预期相符合。
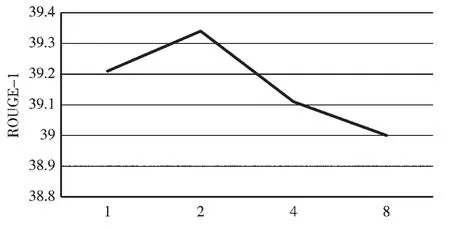
图2 输出胶囊的个数对ROUGE-1 的影响
2.6 模块对比
对比了计算全局向量的3 种方法:(1)将编码器最后一个时间步的隐状态作为全局量(LSTMbased);(2)使用基于CNN 的方法计算全局向量(CNNbased);(3)使用动态路由算法计算全局向量(DRbased)。三种方法在Gigaword 数据集上的实验结果如表4 所示。
可以看到,使用胶囊网络计算全局向量的结果相比于基于LSTM 的方法和基于CNN 的方法均有提升,这说明了使用动态路由方法计算全局向量比基于LSTM 的方法和基于CNN 的方法更有效。使用基于LSTM 的方法计算全局向量比使用基于CNN的方法计算全局向量的结果要好,这说明了位置信息对全局向量计算的重要性。
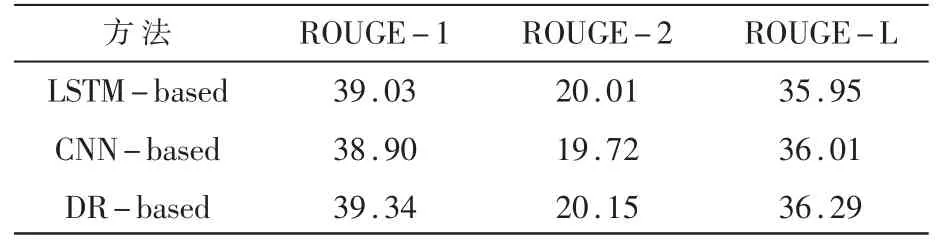
表4 不同全局向量计算方法对最终结果的影响方法
2.7 删减实验
通过删减实验来验证DRBHIF 层中各模块的有效性。依次将补充门、过滤门和关键字选择模块从模型中删除并进行实验,实验结果如表5 所示。
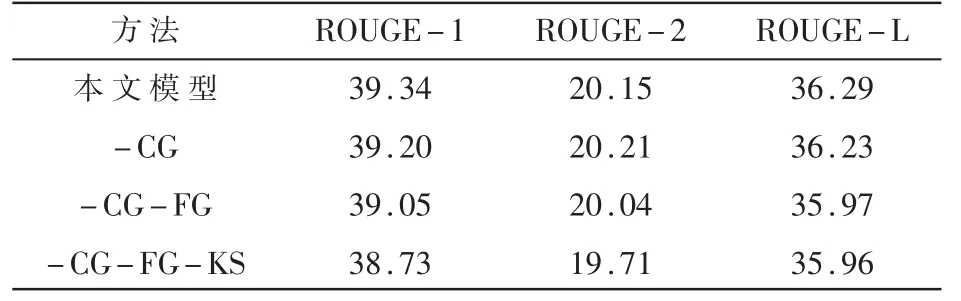
表5 删除不同的模块对最终结果的影响
其中,-CG 表示从模型中删除补充门,-CG-FG表示从模型中删除补充门和过滤门,-CG-FG-KS表示从模型中删除补充门、过滤门以及关键字选择模块。从表5 可以看出,每删除一个模块,模型的性能都会随之下降,这验证了模型中各个模块的有效性。
3 结论
在本文中,为了对输入文本中的噪声过滤进行清晰地建模,解决噪声过滤过程中全局向量的计算问题以及噪声被过度过滤的问题,提出了基于动态路由的分层信息过滤层DRBHIF。DRBHIF 使用动态路由算法代替基于LSTM 的方法和基于CNN 的方法来计算全局向量,这防止了信息损失的问题,并且从词层面和语义层面对噪声进行过滤。为了防止语义噪声过滤过程中出现的信息被过度过滤的问题,还提出了双门语义噪声过滤算法。在Gigaword 数据集和CNN/Daily Mail 数据集上的实验结果验证了本文模型的有效性。在未来的工作中,将尝试进一步提高DRBHIF 在长文本噪声过滤上的性能。
