基于实时数据流特征提取的设备能耗异常识别算法研究
2021-05-19黄家续曾献辉施陈俊
黄家续 ,曾献辉 ,2,施陈俊
(1.东华大学 信息科学与技术学院,上海201620;2.数字化纺织服装技术教育部工程研究中心,上海201620)
0 引言
节能降耗是企业面对的一个迫在眉睫的问题,设备节能是其中的一种有效手段。企业能源浪费很大一部分来自用电设备的管理维护不够精确、不够及时。人走忘记关灯、忘记关水、设备爆管、设备老化等异常不能够及时检测出来,给企业造成了一定程度上的损失。
目前企业中大多都使用了设备能耗数据采集系统[1],采集到的数据量大、实时产生。因此,设备运行过程中产生的各种异常也会在数据上有直接反映。所以为了能够及时、精确地检测出设备运行中产生的各种异常,对能耗数据异常的检测以及分类有着重要的研究意义。
目前国内外许多研究者对用电数据的异常检测进行了大量的研究。黄悦华等提出了一种基于用电特征分析的无监督方式异常检测方法[2],具有较高的准确性;张春辉等提出了基于小波检测电力负荷异常的方法,利用ARFIMA 统计方法结合小波,能够快速准确全面地发现电力负荷异常数据[3];赵嫚等利用模糊聚类和孤立森林算法相结合进行异常检测[4];徐瑶等采用卷积神经网络挖掘用户时间序列中的用电规律,并通过反向传播来实现网络参数的更新,利用支持向量机检测出异常用电行为[5];ANGELOS EWS 等人使用模糊分类矩阵来改进C均值聚类,归一化度量距离最大的即为异常用电行为[6];ARISOY I 等基于电力公司长期运营的专家知识,对用电数据的时间关联关系进行了数学建模,实现了用户异常用电量的检测[7]。
但是对于设备用电数据异常分类目前国内相关的研究比较少,异常分类可以及时地找到异常产生的原因,能及时通知工作人员进行快速精准的维护,减少不必要的能源浪费。本文提出了一种基于多特征提取的企业用电异常分类方法。因为本文采用的数据是企业设备每天24 h 的能耗量数据,属于一维时间序列数据,所以并不能直接对用电量数据进行分类。如何对用能设备所产生的时间序列数据的特征进行提取[8]是本研究中很重要的一环。孤立森林算法[9-10]能够快速准确地对异常点进行检测,它利用异常点数据少、异常数据特征值与正常数据差别大这两大特点来孤立异常点。该方法效率高,能有效地处理海量数据。本文利用孤立森林算法对异常数据进行检测,分离出正常数据和异常数据,同时标定正常数据类型。为了对异常数据进一步地划分标定,采用K-means 聚类算法[11],选取特征,设定聚类数目k为3,此方法经验证能够很好地分离出三种不同的异常,并对其进行标定。最后针对企业设备用电数据量大并且实时产生的特点,本文提出了一种注意力机制和LSTM 算法[12-13]相结合的设备用电异常分类方法。
1 特征提取
在进入分类器进行训练之前,首先要进行输入数据特征的提取工作,将输入数据转化成多种特征。特征提取对于分类器最后的效果有很大的影响。本文将设备的运行异常分为了三种类型:设备空置异常、高能耗用电异常、用电规律变化异常。
一种典型的设备空置异常曲线如图1 所示。从图中可以看出,处于空置状态的设备以一种低能耗的方式运行。这种异常在企业中是很常见的,比如人走后设备没有正常关闭。
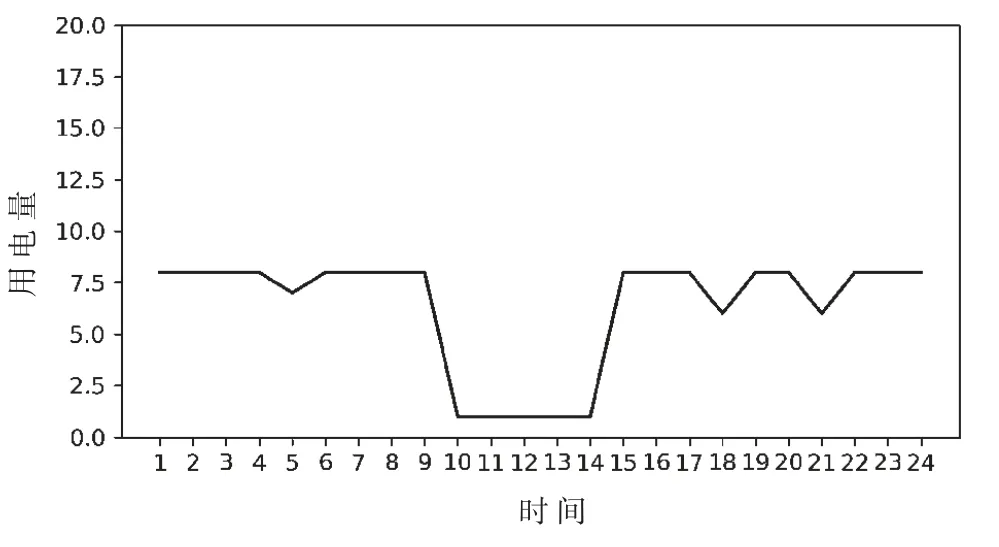
图1 设备空置异常曲线
图2 所示是一种典型的高能耗用电异常曲线,从图中可以看出,设备用电量在某一个时刻急剧升高,超过一个阈值,并且这种高能耗的状态持续很长时间。比如设备爆管就会引起这种异常。
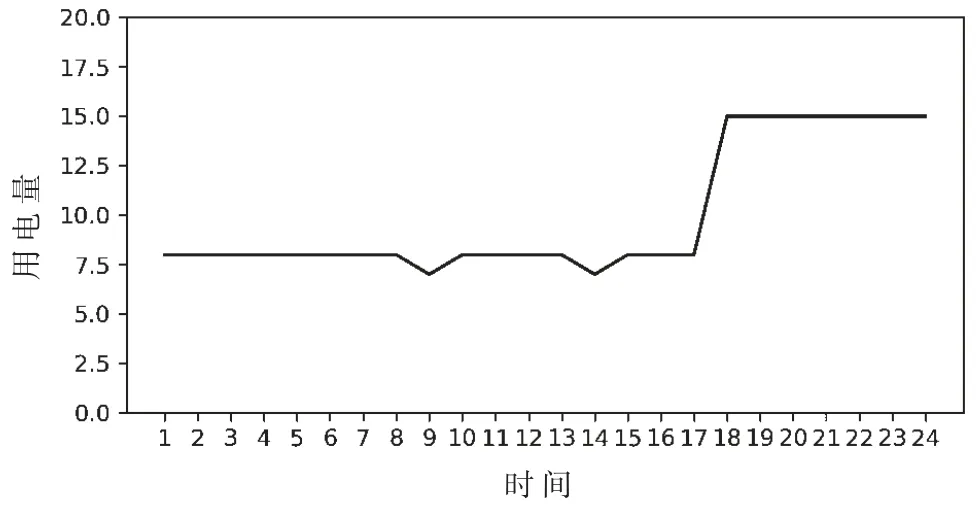
图2 高能耗用电异常曲线
一种典型的用电规律变化异常曲线如图3 所示,从图中可以看出,从第16 小时开始,设备的用电量数据相比于之前发生了明显的变化。

图3 用电规律变化异常
为了更好地对数据进行分类,本文在对设备能耗数据集的处理中构建了如下特征。
1.1 低能耗时间比
低能耗时间比在一定程度上反映了一段时间序列中设备处于低能耗状态的时间比值。为了描述低能耗时间比,为每个小时的用电量数据设定一个上限Emax和一个下限Emin,处于这个上下限范围之内的用电量数据在本文中定义为低能耗数据。每小时的用电量是否属于低能耗的判定为:

其中,E(i)(i=0,1,2,…,N-1)为一个长度为N的用电量时间序列,则低能耗时间比定义为:

1.2 高能耗时间量
高能耗时间量反映了样本时间序列数据中设备处于高能耗状态的用时总量。为了判定设备的用电量是否属于高能耗,为每小时的用电量设置一个阈值,当数据超过设定的阈值,则判定该时刻的用电量属于高能耗。则高能耗时间量T定义为:

1.3 DTW 距离特征
为了描述设备用电规律是否发生了变化,引入了动态时间弯曲距离即DTW 距离[14]。DTW 是时间序列相似性度量的一种方法。下面介绍如何求得新输入的设备用电时间序列与历史时间序列的DTW距离。
若设备历史用电时间序列为:X={x1,x2,…,xm},新输入的 用电时间序列为:Y={y1,y2,…,yn}。首先构造两者的累积距离:

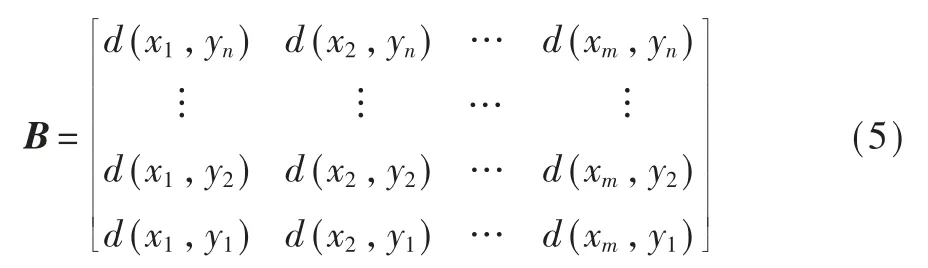
弯曲路径W=(w1,w2,…,wk)满足条件:max(m,n)≤k≤m+n-1,元素wr=(i,j)定义了序列X和序列Y的映射。并且必须满足以下两个约束条件:
(1)W从矩阵B的左下角出发,到右上角结束,即w1=(1,1),wk=(m,n);
(2)W上的元素不可能跨过某个点去匹配,只能和自己相邻的点对齐。即若有wk=(ak,bk),wk+1=(ak+1,bk+1)则满足0≤ak+1-ak≤1 以及0≤bk+1-bk≤1。
最终DTW 距离定义为:

其中K为弯曲路径W的长度,综上所述,该特征值即为D(X,Y)。
1.4 基于高斯模型的特征提取
高斯模型[15]就是用高斯概率密度函数将事务以量化的方式进行刻画,将一组数据分解为若干高斯概率密度函数的叠加。在本文使用的模型中,仅仅假设样本来自于一个正态分布,下面给出正态分布的定义。
定义1若随机变量X服从一个均值参数为μ、方差参数为σ 的概率分布,并且它的概率密度函数为以下形式:

则将该随机变量叫做正态随机变量,其服从的分布叫做正态分布,记为xN(μ,σ2)。本文高斯特征的提取中假设设备用电时间序列来自于一个正态分布,那么可以通过参数估计的方法得出模型的参数:

对于设备用电时间序列X={x1,x2,…,xn},对其做一阶差分得到Y={y1,y2,…,yn-1},使得yk=xk-1-xk,该序列反映了设备用电量的变化特征。对其做k阶差分直到其成为一个平稳序列,然后对于每一阶的差分序列,都可以得出其高斯特征,本文采用设备用电原始序列值X={x1,x2,…,xn}以及一阶差分序列值Y={y1,y2,…,yn-1}分别建立高斯模型,得到高斯模型参数该高斯模型参数反映了时间序列本身的均值和抖动情况,以及时间序列变化的平均大小和抖动情况。本文以高斯模型的参数作为分类的特征值。
1.5 差值平均量
差值平均量是用新输入的时间序列数据与正常时间序列做差并求均值,描述了与正常时序数据的差异大小。若设备用电时间序列为X=(x1,x2,…,xn),新输入的时间序列为Y=(y1,y2,…,yn),两者作差得到(δ1,δ2,…,δn),其中δk=xk-yk。则差值平均量的定义如下:

2 设备用电异常分类模型
2.1 基于多特征提取的企业用电异常分类流程架构
图4 为基于多特征提取的企业用电异常分类流程架构,首先对用电量时序数据样本集中的每一条样本进行特征提取,本文对每条样本都提取了8个特征,分别是低能耗时间比、高能耗用时量、DTW距离、反映时序数据本身均值和抖动情况以及反映时序数据变化的平均大小和抖动情况的4 个高斯模型系数,以及差值平均量特征。特征提取过后的样本并不能直接进入分类器进行训练,因为本文中采用的样本数据属于无标签数据,还需为样本数据打上标签,对类型进行标定,随后才会进行分类器模型训练。对输入的每条样本数据进行特征提取,进入训练好的模型,得到分类结果。
2.2 样本类型的标定
本文所采用的数据集为企业设备的用电量数据,每一条时间序列数据中包括每天24 h 设备的用电量,同时也属于无标签数据,所以在进入分类器模型训练之前,要利用算法为每条样本数据打上标签。本文为样本数据标定类型同时使用了孤立森林模型以及K-means 模型。利用孤立森林模型能够很精确地检测出异常数据,从而分离正常数据和异常数据,然后对异常数据利用K-means 模型进行聚类,聚类数目K为3,经过考虑和试验选用低能耗时间比、高能耗时间量、DTW 距离、原始序列高斯系数μ1以及差值平均量5 个特征构成样本数据作为K-means 算法的输入,经检验此方法能够很好地对设备空置异常、高能耗用电异常以及用电规律变化异常进行类型标定。样本数据类型标定的流程图如图5 所示。
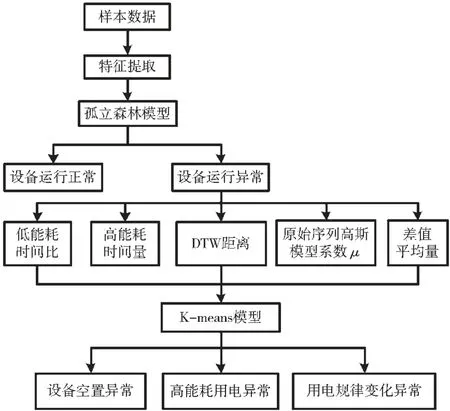
图5 样本数据类型标定流程图
2.3 基于注意力LSTM 的设备用电异常分类模型
针对企业设备用电数据量大并且实时产生的特点,本文提出了一种基于注意力机制和LSTM 的神经网络设备用电异常分类方法。图6 为注意力LSTM 神经网络的整体框图,其中包含两个LSTM 层、注意力层和输出层。
传统的RNN(循环神经网络)能够链接以前的信息和现在的任务,但是它有一个缺点,即容易产生梯度消失和梯度爆炸问题。LSTM 就是为了解决梯度的问题,其内部增加了长期存储有效信息的单元。LSTM 每个神经元内部都包含输入门、输出门和遗忘门,它们被用作网络内信息传播的接口。

图6 注意力LSTM 神经网络框图
LSTM 的计算公式如下:
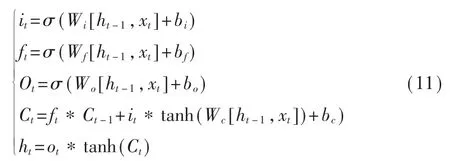
其中,Wf、Wi、Wc、Wo是权重参数,bf、bi、bc、bo是偏置,xt作为输入序列,结合上一个隐含层ht-1的状态,通过激活函数构成遗忘门ft。输入门it和输出门Ot也由xt和ht-1计算。遗忘门ft与前单元状态Ct-1联合以确定是否丢弃信息。本节采用双层LSTM 模型,并将其输出与注意力机制相结合,突出序列中所提取的特征。
近年来注意力机制被广泛地应用于深度学习中。注意力机制没有严格的数学定义,而是根据具体的任务目标,对关注的方向和加权模型进行调整。
对于输入x的序列中的每个向量xi,可以根据式(12)计算注意力权重αi,其中f(xi)是评分函数。

注意力层的输出attentive_x是输入序列的权重之和,如式(13)所示:

本文在LSTM 之后引入注意力机制,可以实现设备用电异常分类结果与特征输出每一项的对应关系。上文从原始序列中提取了8 个特征作为模型的输入,输出为该设备用电异常类型,采用Softmax函数把输入映射到[0,1]空间中,并且进行归一化操作,保证其和为1,将最大的概率值作为判别出的异常类型。
3 实验结果分析
本文采用的数据集为上海某公司某设备每天24 h 的用电量数据,共有715 条样本数据。通过Python 编程得到每条样本数据的8 个特征值,并利用孤立森林算法和K-means 聚类算法为样本数据打上标签。本文使用TensorFlow 框架进行注意力LSTM 模型结构的搭建,对设备能耗异常进行识别。为了方便训练,将类型标签转换为one-hot 标签。然后将数据集按70%和30%划分为训练集和测试集。经处理后,输入的特征序列,x的shape 为(715,8),y的shape 为(715,4),每条设备能耗数据的特征值个数为8,数据集的样本总量为715,数据类型的数量为4。
经过实验测试后,基于注意力LSTM 异常用电分类模型的准确率达到了97.76%。图7 是注意力LSTM 异常用电分类模型在训练集和测试集上的10 次epoch 迭代过程中的准确率,图8 为其对应的损失。

图7 模型训练过程中的准确率

图8 模型训练中的损失
为了验证所述方法的优越性,本文在使用相同数据集并且训练10 轮的情况下,用不加注意力机制的LSTM 神经网络分类模型进行训练和测试,准确率为95.45%。而注意力LSTM 模型的准确率为97.76%,经过对比可得出基于注意力LSTM 异常分类模型具有更高的分类精确度。
4 结论
针对能耗设备的节能,本文利用企业中实时采集到的数据流,提出了一种基于多特征提取的设备能耗异常识别方法。首先对原始序列数据进行特征提取,利用孤立森林算法和K-means 聚类算法为每条样本数据打上标签。最后针对企业中设备用电数据量大并且实时产生的特点,提出了一种基于注意力LSTM 的设备用电异常分类算法。提取的8 个特征作为LSTM 的输入,将LSTM 的输出作为注意力层的输入,通过调整权重然后输入到全连接层及Softmax 层进行分类。通过数据验证,注意力LSTM设备用电异常分类模型相比于没有添加注意力机制的LSTM 分类模型效果要更好,分类准确率也更高,更为可靠,可以高效地识别出不同类型的设备能耗异常,从而可以为企业及时作出处理,减少能耗损失提供决策依据。
