基于K近邻和随机森林的情感分类研究∗
2020-05-15张月梅刘媛华
张月梅 刘媛华
(上海理工大学管理学院 上海 200093)
1 引言
随着互联网飞速发展,互联网用户开始大规模增加。根据最新的《中国互联网络发展状况统计报告》,截至2018年6月,我国网民规模为8.02亿,相较2017年年末增加3.8%,互联网普及率达57.7%[1]。越来越多的用户通过网络发布动态和实时消息,但这些主观性的文本数据的飞速增长也造成了管理和检索上的困难,仅靠人工已经难以应对和处理这些海量数据。因此,如何利用信息技术对大量文本数据进行价值提取,成为近几年研究的热点。文本情感分析技术就是解决这一问题的有效工具。
传统的情感极性分类主要基于两种研究范畴:情感词汇语义特性和统计自然语言处理[2]。基于情感词汇语义特征方法是利用词汇的情感倾向来判断评论文本的情感极性,这类方法主要是以自处理为基础,目前自然语言领域还存在一些关键性技术需要突破,这限制了情感词汇语义特征方法的进一步发展。所以研究者开始更多地关注基于统计自然语言方法。现有的比较成熟的情感分类方法主要都是基于单个分类器模型,比如:随机森林[3]、K 近邻[4]、逻辑回归[5]、支持向量机[6]、朴素贝叶斯[7]、决策树[12]、最大熵等统计模型计算文本的情感倾向,但是不同的分类模型的分类任务的侧重点不同,使得单个模型在复杂的分类情况下,并不能保证分类性能的优良性,这就使得单一的分类方法有一定的局限性[6,11,13,15]。
K近邻是一种无需参数的便捷型懒惰分类算法,当文本数据过于庞大时,分类效果会变差,耗时会过长。随机森林则是由多个弱分类器通过多数投票方式构成的集成学习算法,相比与单一的决策树拥有不会过度拟合等的特点,但正是由于弱分类器较多,导致人们无法控制其内部的操作,只能通过对参数和随机种子来进行调优,而且如果有许多相似的决策树,则会遮盖住真实的分类结果。所以对随机森林的数据进行“本地化”显得尤为重要。根据文献,当两种算法结合使用可以提高情感分类的精度和效率。Y.Lin,Y.Jeon两位专家[8]对随机森林和它的一些变异进行了一些理论性的研究,并且建立了随机森林和自适应最近的相邻学习者之间的联系。H.Zhang等[9]专家提出了一种基于K近邻和支持向量机的混合模型(KNN-SVM),该算法虽然对情感分类有一定的效果,但是对参数的要求较高(如:成本函数和核函数等)。为了解决以上困难,文章提出了一种基于最近邻投影下的随机森林的混合算法。利用无监督、无参数、简单容易实现的KNN算法“本地化”数据集,再通过法随机森林进行分类,利用其多数投票机制综合各个弱分类器的计算结果得出情感的极性,进一步提高分类准确率。
2 相关理论
2.1 随机森林
随机森林是基于bagging的集成方法,它由一大组不稳定但各自独立的分类器组成,最终的分类结果通过多数投票产生。随机森林所用的基础预测结构就是决策树,因此得名。
2.1.1 Bagging和随机子空间的选择
Bagging是并行式集成学习方法中最著名的代表,是一种基于自主采样(bootstrap sampling)的机器学习方法。随机森林是通过一个bootstrapped训练集来保证预测器之间的独立性,即从原始数据集中有放回的抽取N个样本,其中原始数据集的样本数也是N。为了减少预测器之间的相关性,我们通过对P个属性随机挑选m个,找出这m个中最优的属性进行划分来增加随机性。随机选择一组属性也有利于减少随机森林对维度灾难的敏感性,即在考虑很少的属性时,随机森林处理在高纬度数据集中的噪音属性的鲁棒性更好。
2.1.2 袋外误差估计(OOB)
当我们用自主采样boostrapping数据作为每棵树的原始数据时,样本在B次抽样中始终没有被抽到的概率为,当B无穷大时,概率约等于0.3679,即自主采样数据集中会包含的原始数据,因为随机森林的这个性质,我们可以不用留出法来进行泛化估计,而是用(OOB)袋外误差来进行泛化估计。
专家指出[3],在使用随机特性时,使用袋外估计可以增加准确率;袋外估计用于估计组合数目的泛化性、强度和相关性,这些估计都是在袋外进行的。
2.2 K近邻算法
KNN是一种无需参数的便捷型懒惰分类算法。该方法通过计算特定样本与训练集里样本之间的距离,一般为欧几里得距离,找到离它最近的k个数据样本。若k个最近邻样本原本属于A类,那么新的测试数据的样本也划入到A类。
KNN分类过程的数学描述如下。
定义判别函数:
分类的决策规则为
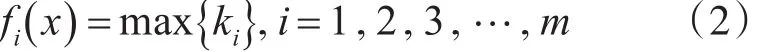
x∈LLi,其中x为分类文本,m为总的类别,k(k>1)为训练集样本数据中与x距离最近的文本数,Li为训练集中的某个类别,ki为Li类文本的数目。
3 本文算法KNN-RF
KNN-RF是一种基于K近邻和随机森林的混合算法。通过懒惰算法KNN将原始数据集中的数据进行投影过滤,即将距离测试点的最近的K个文本向量投影到新的数据子集中,进行第一步的数据过滤,过滤掉一些不相关的噪音数据,净化下一步随机森林分类器中的数据子集。具体见算法1与算法2。
算法1:RandomForesttrain(Dtrain)
输入:有N个样本的训练集Dtrain和测试样本x′
1)从Dtrain中有放回的随机抽取N个样本
2)抽取B组
3)for x inDB
通过递归地对树的每一个根节点重复以下步骤,直到达到最小的节点。
1)在P个属性中随机选出m个
2)在m个属性中选择最优的属性(分裂节点)
3)将节点分裂成两个子节点

输出x′的类别
算法1详细介绍了随机森林算法的工作原理,通过有放回的随机抽样生成bootsrrapped训练子集以及随机子空间的选择,能有效增加分类器的独立性,减小相关性对分类效果的影响。算法1将作为改进算法中的一个重要函数。
算法2:KNN-RF算法
输入:有n1个样本的训练集Dtrain和测试样本x′输出:测试集类别
1)function:获得K个近邻(Dtrain,x′,k)
(1)for x inDtrain
计算 distance(x,x′)
(2)将距离排序得出最优的前K个训练样本,
2)返回最优的前K个训练样本
3)DKNN=function:获得K个近邻(Dtrain,x′,k)
4)KNNRF=RandomForst.train(DKNN)
输出x′的类别
算法2作为混合算法中的主程序加入了KNN算法,将“本地化”后的数据子集分别带入了随机森林分类器进行分类任务,最终输出x′类别
4 实验及结果分析
为了验证模型的有效性,将在中文评论数据集上进行对比实验。本文选用了谭松波博士整理的酒店评论2000作为数据集。算法使用Python语言实现,中文分词选用的是Jieba分词工具库,分类器模型选择的是Scikit-Learn机器学习库中的函数,硬件环境为 DELL,处理器为 Intel(R)Core(TM)i5-7200U,CPU@2.5Hz 2.7GHz,内存为8GB。
4.1 数据准备
本文选用了包括1000条正面评论和1000条负面评论的谭松波博士酒店评论语料作为数据来源。针对数据中存在的酒店反馈,顾客的补充说明以及评论的长短等进行了数据的预处理,本文在处理过程中将评论的最小长度设置为50。最终选择了524条负面评论,462条正面评论最为数据集。
4.2 评价指标[11]
文本分类效果的评价主要从以下几个方面进行:
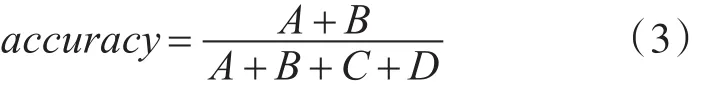

A,B,C,D的含义见表1。

表1 分类准确率变量说明
4.3 实验设置
本文利用Python中的Jieba工具包进行精确分词,IG进行特征降维,TF-IDF计算每个词的权重并形成词向量维度为300的向量空间模型。
完成向量空间模型的构造后,我们需要对随机的森林模型的参数进行定义,包括森林中树的数量、每棵树的停止标准、随机选择的特征数量和分割准则。这些参数通常是估计的。本文选择让树无限制的生,随机子集的大小固定为p,p是所有属性的总数[3]。需要估算的是树木的生长数量。根据经验,生长的树越多,得到的泛化性能就越好,但是过多的树木会浪费资源。
图1中显示了随着数目棵树增加,OOB估计的变化趋势,为了获得最合理的随机森林的数目棵树,本文需要找到使OOB估计平稳的最小一点,看见当树的棵数为24时,袋外估计趋于平稳。故参数n_estimate=24。
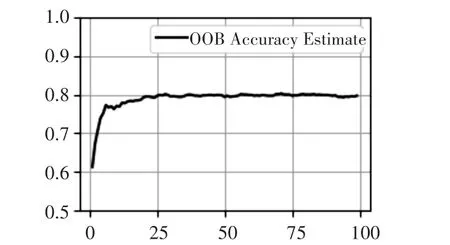
图1 森林中不同树木数量下的OOB估计
由上文可知[7],KNN-SVM是良好的文本分类器,这里作为我们对比的基线之一引入,分别将我们的数据集运用于两中算法之中。可见图2、图3,KNN-RF与KNN-SVM算法随着投影面积的增加,效果都表现显著。可以发现,当K为900时两者的精度都表现优异,最终,我们选用K为900进行下面的对比实验。
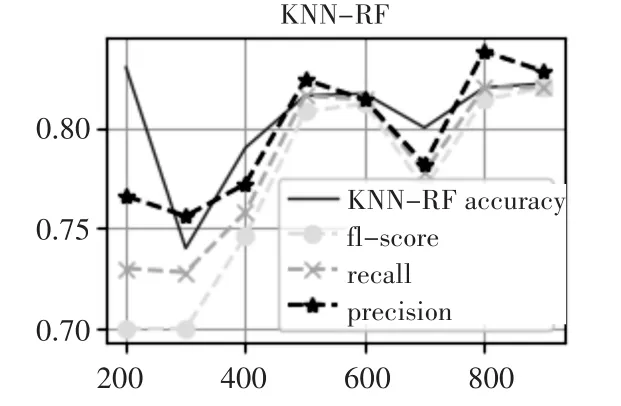
图2 八种K投影下的KNN-RF分类结果

图3 八种K投影下的KNN-SVM分类结果
4.4 实验结果分析
由表2可知,相比与单一的分类器,两个混合算法的分类精度较好,可以认为混合的分类器比单一的分类器效果更优。从宏观上来说,本文算法在四个指标中精度排名第一,另外三个的精度也以较小的精度次于第一名。从更微观的角度来看,本文提出的KNN-RF的算法在F-measure上占优,分别为79%与85%;在总体的分类精度上KNN-RF以82.2%的精度优势强于其他四个分类器,认为本文提出的分类算法在分类效果上具有一定的有效性和可行性。

表2 五种分类算法的分类结果
5 结语
本文通过“本地化”原始数据集,对文本进行差异性过滤后再进行分类做法使混合算法在与单一性分类器进行比较时具有明显优势,具有良好实用性和发展前景。
对于今后的研究方向:本文只考虑了将两种方法相结合,未来可以考虑将多种单一分类器融合的方法,进一步提高文本的情感分类精度;文中随机森林所使用的投票机制,只是简单的多数投票方法,未来可考虑改用加权投票机制,使每个子分类器的权重更具有自身特点;最后,文中给出的特征词指向性不足等问题日后都需要深入研究。
