少样本条件下基于K-最近邻及多分类器协同的样本扩增分类
2022-07-28陈伟杰郑成勇蔡圣杰罗智玉
陈伟杰,郑成勇,蔡圣杰,罗智玉
(五邑大学 数学与计算科学学院,广东 江门 529000)
0 引 言
在传统的模式识别中,若训练一个高效且准确的分类器,大量的已标记样本是必不可少的。但在许多情况下,标记样本十分耗时耗力,导致每个类别的训练样本很可能只有一个或者少量几个,无法使分类器的分类精度得到有效提高。同时,很多的数据集也会存在样本类别数量不平衡的问题。样本数量不足以及样本类别数量不平衡而导致分类器性能下降的问题统称为少样本问题。少样本问题的本质是训练样本数量过少,大量的无标记样本信息无法得到应用。
面对少样本问题,文献[2]提出通过数据增强的方法对原有的少量样本数据集进行样本扩充,待扩充的样本可以是未标记样本或者合成的已标记虚拟样本。
在少样本条件下进行样本扩充,第一步在于筛选可靠的无标记样本,即候选样本选择问题。筛选的原则是根据无标记样本与标记样本的相似性进行筛选。如通过邻域像素与中心标记像素具有相似性,挑选相邻像素加入标记样本集中。在同质区的样本均符合同质准则,则同质区的样本大概率属于同一类,将同质区的样本添加进标记样本集中。传统的SMOTE(Synthetic Minority Oversampling Technique,合成少数过采样技术)算法通过线性插值生成虚拟样本,在线性空间中,通过投影扩增虚拟样本进行样本扩充。
同时,聚类分析也应用于样本筛选中。如半监督Kmeans 聚类算法是以K-means 聚类为基础,将数据对象标签的分布作为初始的聚类分布进行聚类,或者以标签信息作为辅助信息的半监督聚类算法。考虑到无标记样本隐含的空间结构信息,与半监督分类结合,文献[8]使用模糊C 均值聚类选取信息含量高的无标记样本赋予标签来辅助训练分类器,该方法有效考虑到样本间的相似性以及隐含的空间数据信息。文献[9]通过计算无标记样本与标记样本的距离,选取距离类中心最近的点进行朴素贝叶斯分类,这也应用了标记样本与无标记样本间的空间相似性。
筛选无标记样本后,更重要的是如何从候选样本中选择出各类扩展训练样本集、样本扩充方法问题。由于单个分类器局限性较大,通过经验与先验知识可知,使用单个分类器对候选样本进行样本选择,往往会使分类决策存在一定的错误。在训练样本扩充的过程中,若将赋予了错误类标记的样本大量地添加至训练样本集中,则会降低分类器的分类能力,造成分类错误率的提高。
针对单一分类器的局限性较大的问题,文献[10]提出了一种Co-training的算法,利用标记样本初始训练两个分类器,通过两个分类器赋予无标记样本伪标签,然后将每个分类器标注后的样本添加进另一个分类器的训练样本集中,并对另一个分类器进行再次训练,使分类器的分类效果提高。随后,文献[11]提出了Tri-training算法,较Co-training 上增加了第三个分类器,前两个分类器共同从候选样本集中选择扩展训练样本添加至第三个分类器的训练样本集中,并再次训练第三个分类器。但在少样本条件下,传统的Tri-training 算法会因为标记样本数量较少,导致分类器的差异性不足,无法有效提高分类器的分类性能。因此,文献[12]通过主动学习选取具有大量信息量的无标记样本,并通过差分算法得到最优训练样本集,并用此训练样本集训练多个分类器,使多个分类器的差异性加大,提高了分类器的分类性能。这些算法的目的是获取不同的训练样本集,以此训练样本集训练同一分类器,从而获得多个差异性较大的分类器。这些方法的弱点在于尽管通过不同的扩增样本方法,使多个分类器的差异性增强,但单一分类器的局限性仍然存在。
针对上文所述候选样本选择问题以及样本扩充方法问题,本文提出一种K-最近邻及多分类器协同的训练样本扩增分类框架。该分类框架在少量样本的条件下,通过选择多个分类器协同判别每类训练样本的K-最近邻样本,扩增训练样本集,有效提高分类器的分类精度。
1 基于K-最近邻及多分类协同判决的训练样本扩增分类方法
1.1 算法思想
在少样本条件下,如何扩增训练样本是模式识别、半监督分类中的重要问题。要进行样本扩增,首要的问题是选择哪些未标记样本去进行扩增,即候选样本选择问题;其次是如何从候选样本中选择出各类的扩展训练样本集,即样本扩充方法问题。针对候选样本选择问题,本文提出一种标记样本K-最近邻候选样本选择法,通过搜索出各类的各个标记样本的个最近邻的方法,来获得各类的候选扩增样本集。针对样本扩充方法问题,本文提出一种多分类器协同判决样本扩增法:若多个分类器多数或一致将某候选样本判决为某类,则将该候选样本添加至该类的扩展训练样本集中。
本文所指某样本的K-最近邻,可以是样本在特征空间中的距离(如人脸图像所提特征之间的欧氏距离)度量意义下的最近邻,也可以是几何空间中的距离意义下的最近邻(如图像中的邻域像素)。
提出K-最近邻候选样本选择法的出发点如下:
1)可以快速缩小扩增样本的搜索范围,加速样本扩增过程。
2)无论是空间距离下的最近邻,还是特征距离意义下的最近邻,某标记样本的K-最近邻较大概率具有与该训练样本一样的类别,从该候选集中选择扩增样本可以较好地保证标记样本与其扩增样本在类别上的一致性。
尽管各个标记样本的K-最近邻候选扩增样本集具有较大概率属于同一类,为进一步避免其他类的未标记样本错误加入某类的扩增样本集,提出使用多分类器协同判决样本扩增法。在少样本条件下,通过少样本训练好的单一分类器分类精度一般仍然较低,不足以将候选扩增训练样本正确识别为其所属类别,但若多个分类器多数或一致将某候选扩增样本判决为某类,则将该候选样本添加至该类的扩增训练样本集,出错的概率较低。
获得扩增训练样本集后,利用训练样本集及扩增训练样本集共同对多个分类器进行训练,并对剩余的未标记样本进行基于投票的分类判决。这样做的好处是:
1)通过再次训练分类器,提高分类器的分类精度,正确识别剩余的未标记样本。
2)单一分类器识别过程中具有局限性,对某些较难识别的样本难以识别为正确类别。通过多个分类器共同判别,在少样本条件下,保障了剩余未标记样本的分类准确率。
3)单一分类器可能在某一数据集上具有很高的分类精度,但在另外的数据集上,分类精度会劣于其他分类器。通过多分类器共同判别,可有效解决单一分类器的局限性,提高分类器的泛化能力。在对未知的数据集进行分类时,可达到良好的分类结果。
1.2 K-最近邻及多分类协同训练样本扩增分类方法
基于K-最近邻及多分类协同判决的训练样本扩增分类方法具体描述如下:
输入:标记样本集,未标记样本集,分类器集={,,…,f},近邻数,分类器分类一致率∈( 0,1 ]。
步骤1:使用标记样本集训练分类器集中的分类器。
步骤2:对任意∈,不妨设的类标签为,在中搜索出的个最近邻,并将他们加入到标签为的候选训练样本扩增子集E中。
步骤3:对x∈E,若分类器集中的分类器有不少于100%的分类器将x判别为类别,则将x添加到,并标记其分类标签为。
步骤4:若中还有未搜索过其K-最近邻的标记样本,则返回步骤2,否则,执行下一步。
步骤5:使用标记样本集及扩增训练样本集再次训练分类器集中的分类器。
步骤6:使用分类器集中的分类器,对剩余的未标记样本进行分类,并基于投票法确定未标记样本的类别。
输出:未标记样本集中各样本的分类标签,扩增训练样本集中样本的类别为其扩增时确定的类别标签。
在上面的算法框架中,分类器集可采用各种常见的分类器。限于篇幅,本文考虑采用最近邻分类算法(KNearest Neighbor,KNN)、支 持 向 量 机 分 类 算 法(Support Vector Machine,SVM)、集成随机子空间KNN算法(Ensemble KNN,EKNN)以及集成随机子空间鉴别算法(Ensemble Discriminate,ED)。
1)KNN:KNN 的分类策略是针对样本空间里的某个未知类别样本点,观测它周围的样本是属于哪一类的,如果与待测样本距离最小的个样本中属于某类的样本最多,即判定待测样本为该类。
2)SVM:该分类器针对二分类问题,是定义在特征空间上间隔最大的线性分类器;由于包括核技巧,这在实质上使SVM 成为非线性分类器。SVM 的学习算法就是求解凸二次规划的最优化算法。
3)EKNN:随机子空间是在训练样本的全部特征中,通过随机选取部分特征来训练每个分类器,从而降低每个分类器的相关性,为集成学习的一种。集成学习需要多个弱学习器共同构造成一个强分类器完成分类任务。该算法在集成学习中选择的弱分类器为最近邻分类器算法。
4)ED:随机子空间是在训练样本的全部特征中,通过随机选取部分特征来训练每个分类器,从而降低每个分类器的相关性,为集成学习的一种。集成学习需要多个弱学习器共同构造成一个强分类器完成分类任务。该算法在集成学习中选择的弱分类器为高斯判别分析分类器算法。
步骤6 中的投票法,具体执行时会遇到多个类别出现票数一样多的情况,无法按少数服从多数原则确定未标记样本的类别。针对此问题,提出如下修正方法:
记分类器集中的分类器f(=1,2,…,)对中的扩增样本的分类与该样本按步骤3 确定的标签一致的样本个数为v,找出v所对应的最大分类器f。在步骤6中,若存在或超过-1 个子分类器将未标记样本判别为某一类,则以该类作为该未标记样本的类别,否则用分类器f的分类结果作为其最终分类结果。
2 实验结果及分析
为了证明所提算法框架的有效性,需要同时与该算法所集成的分类器集的各个分类器进行比较。本文算法与构成本文算法的4种分类器算法,共5种算法。5个分类器在所有数据集上各重复10 次实验。在每一次实验中,通过将每一个数据集随机划分为两部分,分别为标记样本集和测试样本集。实验前,经过反复验证选择参数。
2.1 实验数据集
实验数据集共6 个,数据集描述如表1 所示。

表1 数据集描述
1)Lung_Cancer数据集:肺部癌症数据集。具有5 个类别,每个样本12 600 个特征,共203 个样本。
2)divorce 数据集:离婚预测数据集。具有2 个类别,每个样本54 个特征,共177 个样本。
3)ORL_32×32 数据集:人脸图像数据集,包含40 个人,每人10 张图片,共400 张图像。具有40 个类别,每个样本1 024个特征,共400个样本。
4)semeion 数据集:通过扫描80 人手写的阿拉伯数字图像集,每个裁剪图像的分辨率为16×16,其中每个像素有256 个灰度级。具有10 个类别,每个样本256 个特征,共1 593 个样本。
5)Letter-recognition 数据集:字母信息识别数据集。具有26 个类别,每个样本14 个特征,共20 000 个样本。
6)Crowdsourced-Mapping 数据集:地球空间信息数据集。具有6 个类别,每个样本28 个特征,共10 845 个样本。
2.2 实验设置
针对每个类别样本总数的不同,实验分以下两种情况:
情况一:针对样本总数较少的数据集。每类的标记样本个数设置为2,3,4,5。经反复测试,设置为3。由于每类样本总数较少,故值不可设置过高。所选的数据集为divorce、Lung_Cancer 及ORL_32×32。
情况二:针对每类样本总数较多的数据集,每类的标记样本个数设置为10,20,30,40。由于每类的样本数较多,所以每个样本与其同一类别的近邻样本的数目也较多,故将近邻数值适当增大。经反复测试,设置为10。所选数据集为Crowdsourced-Mapping、semeion 以及Letter-recognition。
2.3 样本扩增对分类器分类精度的提升效果
为验证样本扩增对分类器性能的提升效果,针对情况一和情况二进行了实验,实验结果如图1 所示。图1的每个子图的横坐标代表标记样本的个数,纵坐标代表10 次实验每个分类器算法的平均分类精度;图中的实线代表扩增后分类器的分类精度,虚线代表扩增前分类器的分类精度,每个子分类器扩增前后的分类精度均由不同的符号进行标记。
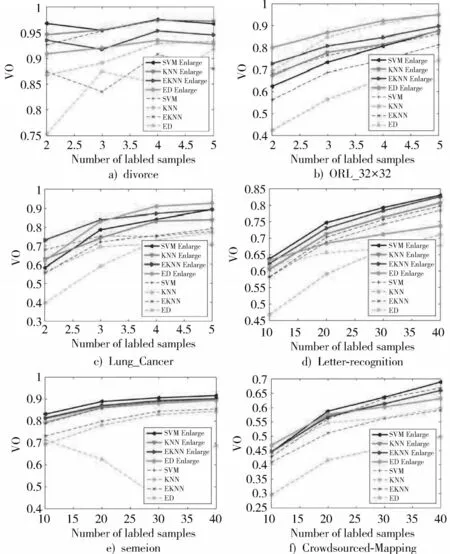
图1 在6 个数据集上四种算法使用数据扩增和不使用数据扩增的分类精度对比
从图1 可以看出,基于多分类器协同判别的样本扩增能显著提升各子分类器的分类精度。对于每类的样本总数较少的情况一,随着标记样本数的增加,扩增后的分类效果更好。对于每类的样本数目较多的情况二,随着标记样本数的增加,多分类器协同判别扩增后的分类精度的扩增幅度在减小。
2.4 多分类器协同下的实验结果
在多个分类器协同判别每类个最近邻样本得到扩增训练样本集后,通过扩增训练样本集再次训练多个分类器,然后再次使用训练后的多个分类器对剩余未标记样本进行协同分类,与使用扩增训练样本集的多个分类器的分类结果进行对比,以检验所提算法的有效性。实验结果如图2 所示。其中,每个子图的横坐标代表标记样本数,纵坐标表示10 次实验每个分类算法的平均分类精度,vote 代表所提算法的实验结果。
从图2a)~图2c)可以看出,在不同的数据集上,组成多分类器协同判别框架的多个分类器各有优劣,无任何分类器一致优于其他分类器。在少样本的条件下,所提算法的分类效果较组成多分类器协同判别算法的多个分类器算法的分类效果有所提高,并且稳定性优于组成多分类器协同判别算法的多个分类器算法。
从图2d)~图2f)可以看出,在数据集样本总数较多的情况下,绝大多数情况下多分类器协同判别投票法接近或优于组成协同判别分类框架的子分类器的最优分类效果。个别不是最优的情况下,也与组成多分类器协同判别算法框架的多个子分类器算法的最优分类结果相差较少,且随着扩增训练样本数量的增多,所提算法的分类结果更好。

图2 在6 个数据集上的对比实验结果
3 结 语
针对少样本条件下的分类问题,本文提出一种基于K-最近邻及多分类器协同的训练样本扩增分类框架。要进行样本扩增,首要的问题是候选样本选择问题,其次是样本扩充方法问题。针对候选样本选择问题,本文通过搜索出各类各个标记样本的个最近邻,获得各类候选扩增样本集。针对样本扩充方法问题,通过使用多个分类器对候选扩增样本集进行判别,若多数或一致将某候选样本判决为某类,则将该候选样本添加至该类的扩展训练样本集。获得扩增训练样本集后,利用训练样本集及扩增训练样本集共同对多个分类器进行训练,并对剩余的未标记样本进行基于修正的投票的分类判决。最后在多个数据集上验证了算法框架的有效性。在后续的工作中,将对算法框架中最优参数的选取,扩增样本的正确标签率的提高以及本文算法的时间成本的减少等多个方面进行探讨,从而更好地提升本文算法框架的分类正确率。
