学贯中西(6):阐述ML分类器的工作流程
2022-04-21高焕堂
高焕堂



1天字第一号MlL模型:分类器
在上一期里,曾经在Excel 画面的幕后,设计了一个分类器(Classifier)模型,将各<诗句>归类到各自所属的<作品>。此时,把一个作品名称(如静夜思),当作一个类(Class )。于是,这种ML模型,就通称为:分类器。在ML(机器学习)领域中,分类器就是天字第1号模型。
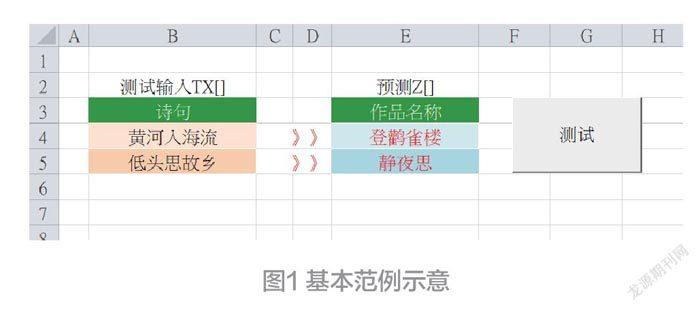
在本专栏的前面几期里,曾经介绍过分类器的幕后实践技术。在本期里,就来把去年介绍过的技术,与华夏的艺术、文化创作,连结起来,让您能够贯通ML的知识体系及其实现技术,请您回忆上一期的范例(见图1)。
这是ML模型的基本技能,它透过机器学习而记住了<诗句>与<作品名称>之间的关系,也就是分类关系。于是我们就可以把某个<诗句>输入给这模型,由它来预测(推论)出其所属的<作品名称>(参见图2)。
这是典型的ML分类器模型。我们可以建立更多这样的模型,来表达各式各样的事物之间的复杂关系。
分类器的学习流程
刚才已经说明了,分类器是一种AI模型。顾名思义,它经过机器学习,就能在人们的指引下,认识不同种类的图像,或其他事物。换句话说,它就具有分辨出不同种类事物的智慧能力。现在来举例说明其学习流程。2.1收集数据
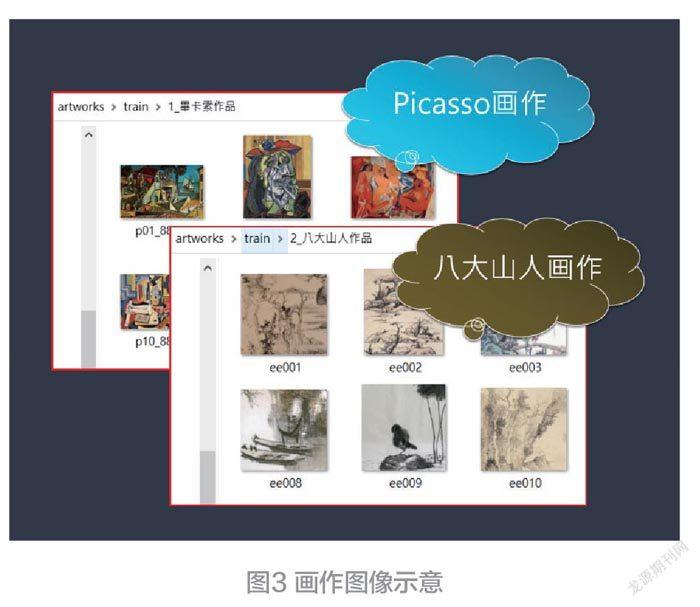
于此,叙述分类器的工作(学习)流程。例如,它就具有分辨出八大山人与毕加索,两种不同画作的风格。首先,收集两个类的画作图像,如图3。
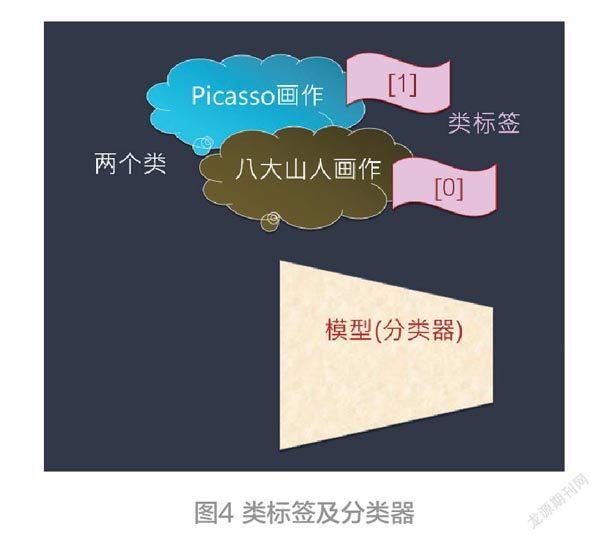
这些图像是用来训练一个分类器模型。训练完毕之后,它就具有分辨出八大山人与毕加索,两种不同画作的风格。由于分类器是属于监督式学习( Supervisedlearning ),我们先进行分类,并且对各类来贴上标签( Label)。贴上类的标签:[1]代表<Picasso>类,而以[0]代表<八大山人>类(见图4)。
分类器是属于监督式学习( Supervised learning ) ,我们先进行分类,并且对各类来贴上标签( Label )。贴上类的标签:[1]代表<Picasso>类,而以[0]代表〈八大山人〉类。接下来,就来定义这个分类器的架构,包括它的各项参数来配合这些画作图像的大小(即多少像素)。
现在,训练数据(Training data)准备好了,模型也定义好了,就可以展开〈机器学习〉了;也就是,开始训练这个分类器模型。
2.2展开机器学习
·步骤1:拿第1笔数据来训练
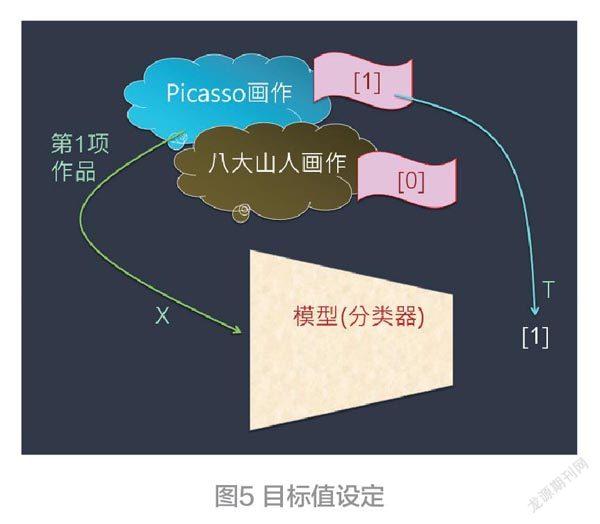
首先从Picasso类取出一笔数据(即一张画作),以X表示之,输入给分类器。同时,把Picasso类的标签,提供给分类器,做为目标值(Target),简称:T值(见图5)。
此时,分类器模型就进行推论(Inference ):从X 计算出Z。并且计算出Z与T的误差。也就是:T-Z = Error (見图6)。
然后,依据这项误差值(即Error)来更新这分类器的参数,如图7所示。于是,更新了分类器的参数,让分类器的智慧提升了。此时已经输入第1笔数据,并对分类器进行1次迭代(Iteration)的训练了。
·步骤2:拿第2笔数据来训练
现在从八大山人类取出一笔数据(即一张画作),以X表示之,输入给分类器。同时,把八大山人类的标签, 提供给分类器,做为目标值(T)。此时,分类器模型就进行推论:从X计算出Z,如图8所示。
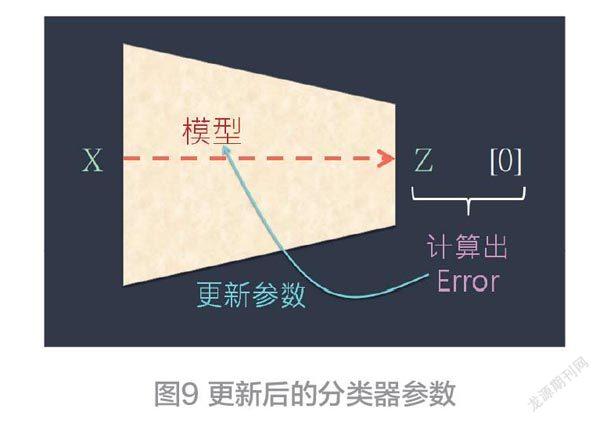
接下来,就计算出Z与T的误差。也就是:T-Z =Error。然后,依据这项误差值(即Error )来更新这分类器的参数(见图9)。
更新了分类器的参数,让分类器的智慧提升了。此时已经输入2笔数据,并对分类器进行2次迭代的训练了。
·步骤3:继续拿下一笔数据来训练
这是重复〈步骤1〉的学习流程,从Picasso类取出另一笔数据(即另一张画作),以X表示之,输入给分类器。同时,把Picasso类的标签,提供给分类器,做为目标值。此时,分类器模型就进行推论,计算出Z 和误差值(Error)。最后,依据这项误差值来更新这分类器的参数。更新了分类器的参数,让分类器的智慧提升了。此时已经输入3笔数据,并对分类器进行3次迭代的训练了。
·步骤4:继续拿下一笔数据来训练
这是重复<步骤2>的工作流程,但是从八大山人类别取出另一笔数据(即另一张画作),来输入给分类器。同时,把八大山人类的标签,提供给分类器,做为目标值(T)。此时,分类器模型就进行推论,计算出Z和误差值。最后,依据这项误差值来更新这分类器的参数, 让分类器的智慧提升了。此时已经输入4笔数据,并对分类器进行4次迭代的训练了。
·步骤5:继续重复循环下去
然后,重复循环下去,直到Error趋近于0为止。以上是典型的机器学习流程,其中每1次迭代都各输入1笔数据给分类器去进行学习(也是训练),也更新1次模型参数。这样地重复循环下去,就会逐一地把各笔数据(画作)都输入给分类器去学习了。当我们把全部数据都输入给模型去学习了,就称为:学习一回合(Epoch )。
如果学习了一回合之后,发现其误差值(Error)还蛮大的(不接近于0),表示学习得还不够好。于是继续重复下去,也就是进行另一回合的学习,重复循环下去,直到Error趋近于0为止。一般而言,机器学习都需要进行数千或数万,或更多回合的学习(训练)过程, Error才会趋近于0。
3学习的效果
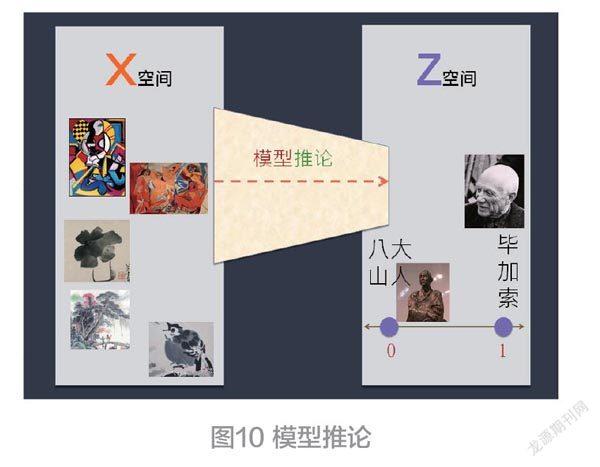
于此,使用空间对应(Space-mapping )的观念来解释之。输入空间(即X空间)包含全部数据(画作),经由推论(计算)之后,会对应到输出空间(即Z空间)。这种对应过程,就通称为:模型推论,如图10所示。
经过数百或数千,或更多回合的学习之后,这分类器就能把这些画作,对应(Mapping )到它们各自所属的类了。
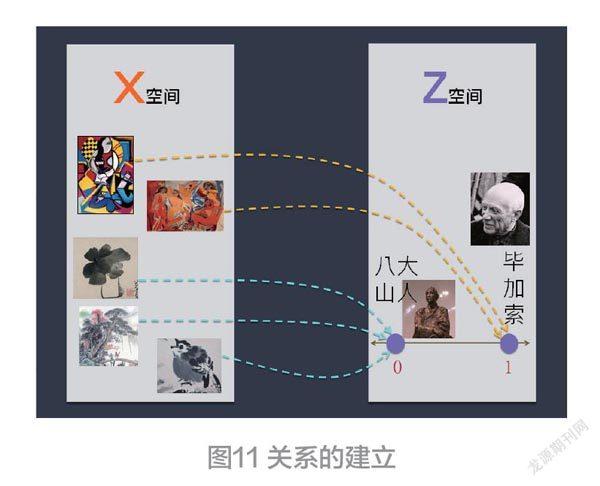
一旦机器学习完成,图11里的关系建立起来了。计算机(ML模型)就观察画作的风格,而推论出该幅画作是来自毕加索或是来自八大山人了。
4结语
前面提到了,分类器是ML领域的天字第一号模型。为什么它具有这样重要的角色呢?请您仔细领会一下图11里的X(空间)与Z(空间)的关系。基于这项关系,MIL模型就观察画作的风格(结果),而推论出该幅画作是来自毕加索(原因)或是来自八大山人了。
于是,X空间里的事物或其特征,是我们所观察到的结<果>。而Z空间里所表达的却是这些结果幕后隐藏的原<因>。一旦能找到眼前(现实)结果幕后藏的真正的因,我们就能针对此<因>而对症下药,就可以改变眼前的<果>了。这称为:溯因( Abductivereasoning)推理。君不见,许多人类的科学性创新,大多来自于这项溯因(又称果因)推理能力。请您期待本专栏的继续解说ML的更多魅力。
