基于DBSCAN的基站定位算法∗
2020-05-15彭艳兵张若愚
夏 天 彭艳兵 张若愚
(1.武汉邮电科学研究院 武汉 430070)(2.南京烽火天地通信科技有限公司 南京 210019)
1 引言
随着移动智能终端设备的加速普及,移动电子商务、休闲娱乐、社交、手机游戏等领域的使用率都在快速增长,移动用户对手机和互联网的依赖性和使用率越来越高,互联网服务商积累了大量的移动用户的实时位置数据。挖掘这些轨迹信息,可以发现人们活动的时空规律,使人们能够更深层地认知智能化城市中社群的生活轨迹、社交行为、环境变动等,不仅能够满足用户越来越强烈的个性化、社会化需求,为社交网络的发展提供支持,而且能够为舆情检测、商务智能提供支撑和保障。
对于互联网服务商而言,位置信息的准确性至关重要,其中基站位置信息在人员定位、轨迹分析等方面具有重要的作用。而在实际应用过程中,往往会出现基站数据陈旧、基站信息缺失,经纬度位置偏差极大等情况,给定位服务带来了困难。
DBSCAN(Density-Based Spaital Clus-tering of Applications with Noise)算法是一种基于密度的聚类算法,它可以通过计算点的密度把集合中的点分为核心点、边界点、噪声点,在此基础上对所有的点进行空间聚类,从而有效地处理噪音点,过滤低密度区域。
目前国内外关于DBSCAN的应用研究已有很多。刘畅[1]等使用基于DBSCAN的密度聚类方法发现城市交通阻塞区域,郭保青[2]等使用基于快速DBSCAN的方法用于检测铁路异物侵限,杨帆[3]等基于DBSCAN空间聚类对广州市区餐饮集群进行了识别,丁兆颖[4]等提出了基于DBSCAN的码头挖掘算法。
本文针对基站位置数据分析的特点,提出了一种基于DBSCAN的基站定位算法。考虑到DB⁃SCAN聚类算法在噪声处理上的良好表现,尝试使用DBSCAN对基站下用户上报的经纬度坐标进行密度聚类,去除噪音点后根据聚类情况选择不同的策略计算基站位置。本文基于某App中用户上报的经纬度数据进行实验,验证了所提算法的有效性。
2 基站定位算法
2.1 基站定位算法思路
用户通过基站传输数据时一般处于基站的覆盖范围内,因此对于基站而言,用户位置坐标点会密集的环绕在基站坐标周围,使得基站所处位置密度较大,可以通过密度聚类的方式得到基站的位置。本文将基站数据分为训练集和测试集两部分,使用训练集数据计算DBSCAN算法的关键参数组合[ϵ,MinPts],使用测试集数据评估算法准确性。本算法主要分为四步。第一步对数据进行预处理后构成算法的数据集。预处理主要是筛除出数据量满足聚类条件的基站。第二步对于训练集数据,遍历若干种密度聚类的参数组合,找到合适的聚类参数。在运用DBSCAN算法对基站位置定位的过程中,需要确定其邻域参数ϵ和最小点数 MinPts[5~8],对于不同的规模的数据集需要采用不同的聚类参数以获得良好的聚类效果。第三步使用最优参数组合对测试集数据进行密度聚类。第四步根据聚类结果得到基站位置。DBSCAN按照密度将数据集划分为任意个高密度区域,而我们期望得到一个坐标点来表示基站的位置,因此当聚类个数为1时,即高密度区域个数为1时,计算该高密度区域的重心点即可得到基站可能位置。而当存在多个聚类结果,即多个高密度区域时,不能简单地通过计算多个区域的重心来得到基站的位置,而是需要根据具体的聚类结果来判别基站所在位置。
2.2 聚类参数的选择
DBSCAN算法有两个重要参数,即邻域半径ϵ和邻域最小点数MintPts,对于不同数据量,应该设置不同的参数组合以适应数据情况[9~14]。
本文将数据按照基站下坐标点的数量划分为N 个数据集:(0,x1],(x1,x2],…,(xN-1,∞)。针对这 N个数量级的数据,从系统中抽取部分有完整位置信息的基站,通过第三方接口获取了其相对精确的经纬度信息。以这些基站的经纬度数作为训练集,计算各种参数组合下算法定位的精度,根据精度选取最优参数组合。使用本文定位算法对N个测试集数据遍历多种[ϵ,MinPts]的参数组合,与第三方接口的数据相比计算定位精度,得出每种参数组合下的平均定位偏差(m)、定位偏差的四分位数(q1,q2)、定位成功的基站比例(s)。其中定位成功指的是误差在200m以内。
对于每种参数组合定位的结果按照式(1)计算综合评价指标:

2.3 区域权重算法
对于DBSCAN聚类结果,如果基站下上报经纬度数据聚集性较高,则算法只会确定一个高密度区域,则此区域极可能为基站所在区域,只需计算该高密度区域的重心点即为基站可能位置。实际有部分基站因为附近地形等原因的限制,造成算法划分出多个高密度区域,因此不能直接对多个高密度区域计算重心来确定基站位置,需要对多个高密度区域进行分析。若几个高密度区域相隔较近,只是因为地形而被分割成多块,那么可以直接将几个高密度区域合并为同一个区域进行计算。若几个高密度区域相隔较远,则可能存在数据上报有误的情况,此时需要对几个高密度区域内数据情况进行统计分析。
针对上述问题,对于聚类类个数大于一的情况,本文选用数据量、总天数、时间跨度三个维度,对每个区域计算权重,权重越高说明该区域内上报的数据越接近真实基站区域。

2.4 基站位置计算
将待定位数据按照训练集的划分方式进行划分,得到N个数据集,对每个数据集选用2.2中确定的最优参数组合进行DBSCAN聚类。根据聚类个数、各类的区域权重计算基站位置。具体步骤如下:
1)对基站下的坐标点进行聚类。
2)如聚类个数小于1则定位失败;如聚类个数等于1则将聚类重心作为基站的位置。
3)如聚类个数大于1,则计算每个区域的区域权重,按照权重从大到下对区域进行排序,顺序比较每一个区域之间的距离,如区域距离小于100m则算为1类,大于100m则跳过,直至遍历所有基站。最后按照K-Means计所有区域聚为一类并计算中心点,以此作为基站位置。
3 实验验证
3.1 数据集和实验环境
本文实验数据来自于烽火App中2017-06-01至2018-06-01的位置上报数据。该数据包含用户的唯一ID、上报经纬度、上报时间、上报基站号等信息。通过第三方接口获得这些基站的相对精确位置构成本次实验的数据集。本文算法采用的语言是Python 3.6,在Windows系统下运行,计算机CPU为Intel Core i5-7500@3.40GHz,内存大小为8G。
3.2 实验过程
3.2.1 数据预处理
由于每个基站下应用上报经纬度数据质量存在较大差别,并不是所有基站都适合使用算法进行定位,有部分基站下数据质量较差,需要再积累数据,达到算法要求标准后再进行定位。首先,为了避免某用户短时间内重复上报错误经纬度坐标点数据,需要对每个基站下应用上报经纬度数据按照用户账号、时间(精确到小时忽略分秒)、经纬度进行去重,去重后剔除数据量小于3条的基站。然后统计每个基站下上报经纬度数据的认证账号及不同日期的数量,剔除用户数量小于2或不同日期数小于2的基站,避免极端情况对聚类造成影响。
从系统中提取数据,经过预处理后共190万条上报经纬度数据,共计4.8万个基站构成算法的数据集。选用其中2万个基站作为算法的训练集,剩余数据作为测试集。采用基于DBSCAN的基站定位算法对测试集中的基站位置数据进行定位,对比判断算法的可靠性。
3.2.2 确定最优参数
本文将基站下坐标点的数量划分为四个等级:[0,100)、(100,200]、(200,400]、(400,∞) 以上。针对这4个数量级的数据,使用训练集中的基站位置数据,对于DBSCAN的参数组合[ϵ,MinPts],建立了从[0.001,3]到[0.1,20]共1800种参数组合,采用遍历的方式对1800种参数组合下的定位精度进行计算,根据2.2中的方法得到每个参数组合的综合评价值z,最后选出每个数量等级的最优参数组合,如表1所示。

表1 最优参数组合

表2 组合数据统计
由表2可以看出在数据量小于100的最优组合里,平均偏差0.383公里大于上四分位数0.358公里,即至少75%的基站偏差都是小于均值的,这种情况的出现的原因就是在定位偏差计算时出现了极端值,影响了平均偏差。
3.3 实验结果分析
将测试集数据,按照同样的数量等级划分为四个数据子集,并所确定的参数组合对每个数据子集进行聚类。结果如表3所示。
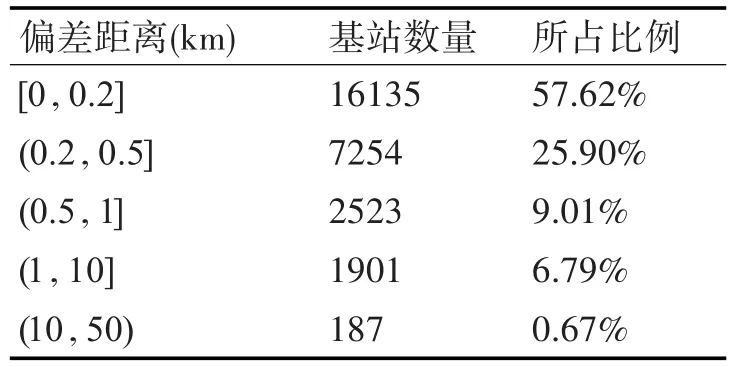
表3 最优参数组合定位偏差
表3中偏差距离指的是算法定位点与已知坐标点的距离,从表3可以看出,定位偏差在200m以内的基站有16135个,占基站总数的57.62%,定位偏差在200m~500m之内的基站共有7254个,占基站总数的25.90%。成功定位率为83.52%。
4 结语
本文提出了一种基于DBSCAN的基站定位算法。以基站下应用上报经纬度为数据来源,运用DBSCAN算法对基站位置进行定位。本文根据数据规模选择合适的聚类参数,并对聚类结果从数据量、总天数、时间跨度三个维度计算区域权重,最后得到定位结果。对比第三方接口提供的基站位置数据,本文算法成功率达到83.52%。实际上,在手机进行通话的过程中,由于信号、基站容量等客观问题,并不能总是选择距离最近的基站[15],且在信号不佳的情况下,还会出现上报应用中记忆经纬度(上一次定位经纬度)的情况,给本文算法的定位带来了困难。
