基于AdaBoost的人脸检测算法研究
2019-05-17白燕
白燕
(四川大学计算机学院,成都 610065)
0 引言
人工智能科学的产生要求计算机在观察和寻找信息时具有主观能动性,这就使得机器视觉的地位变得举足轻重,而人脸视觉分析处理作为机器视觉的重要任务,越来越受到人们的关注和重视。当图像处理的技术发展日趋成熟时,人脸检测的应用随之扩大化,在监狱管理、海关身份认证、公安系统、治安监控、视频会议以及智能身份证等方面均得到重要应用。当前人脸检测的主要研究难点是:如何在人脸多样性的前提下,创建准确分布模型;如何在复杂背景中准确保留人脸区域;如何在人脸多样性前提下提高系统识别率,使人脸检测更加集中快速以适应社会高实时性的要求。
人脸作为一种复杂结构,脸部的细节千变万化,因为肤色、形状等的不同,而且可能有胡须、口罩、眼镜、等人为所加的物品,同时人脸也可能会受光照的影响,所以人脸的模式经常变化。在这种情况下,如果可以解决上述难题,开发出一个非常优秀而实用的人脸检测系统,将具有非常巨大的价值和重要的意义。目前对静态图像的人脸检测有四种基本方法,分别是:基于知识的方法(Knowledge-based Methods)、基于特征不变的方法(Feature Invariant Approaches)、基于模板匹配的方法(Template Matching Methods)、基于外观的方法(Appearance-based Methods)。本文所述的基于Ada-Boost的人脸检测算法就属于所列的第二类——基于特征不变的方法,该算法在检测速度、准确性等方面具有一定的优势。
1 算法综述
AdaBoost算法作为Boosting算法的后续发展,是Boosting算法经过改进得到的[1],它具有自适应的特点。AdaBoost算法的自适应性表现在它不需要预先知道其中弱分类器的分类误差,它是由大量弱分类器组成的强分类器分类效果的好坏来决定组成强分类器的所有弱分类器的分类效果,这样就可以探究出利用弱分类器进行分类泛化和推广的能力。具体来说,就是从一个较大的特征中选择少量关键的特征(被选取的特征应该同时满足以下两个特性:强独立性及对特征具有较强的区分程度)使其变为一个能够高效进行分类的高强分类器,然后再通过一级一级联结的方式将各个单个的高强分类器聚合为级联分类器,从而致使图像的背景极快的被丢弃,然后便可在图像的可能存在区域进行相应较多的计算[2]。
这种方法的突出贡献在于:其一,它引入一种新的图像表示方法——积分图,利用积分图可快速判别出人脸检测时所用的特征;其二,AdaBoost算法的优点,就是能够从一个大的特征中进行选择,然后它会集中其中一小部分关键的特征来生成一个简单有效的分类器;其三,有很多时间来计算人脸区域,因为用级联方式来构建分类器最大的好处就是区分背景非常快。
近年来,AdaBoost算法已成为检测技术中最流行的Boosting算法,在所有的模式识别算法中,此算法也比较流行,这是首个具有实时性的检测方法,它的这一优点,激励了人们在实时性的人脸检测算法方面的研究。2001年Viola和Jones[3]初步构建了一个基于Ada-Boost算法的用于人脸检测的系统框架,这个框架在高速处理图像的同时还具有较高的检测率。2002年Stan Z.Li[4]提出一种FloatBoost多视角的方法,这种算法同基于AdaBoost的算法相比,能利用较少的弱分类器达到与AdaBoost算法一样或更高的分类正确率。2007年,Duy-Dinh.Le和 Shin’ichi.Satoh[5]提出了 Ent-Boost算法,该方法是通过一种度量——熵来学习弱分类器,信息熵用来确定最优分类区间的数目,利用Ent-Boost方法训练的强分类器具有较好的分类能力。经过多年的发展,基于AdaBoost的检测算法不断优化,检测率得到很大的提高。
2 实现细节
AdaBoost算法选择使用Haar-like特征,它是由脸部的灰度分布特征决定的,Haar-like特征是计算机视觉领域一种比较常用的特征描述算子,具有提取速度快、计算比较简单的特点,一般应用于灰度图像中,是基于积分图的特征。AdaBoost算法首先提取图像中的Haar-like特征,再通过训练从中选出最优的Haar-like特征,然后将训练得到的相应特征转换为弱分类器,最后再将上述弱分类器进行相应的优化组合,最终用于检测。
2. 1 Haar-like特征
在基于AdaBoost的人脸检测方法中最常用的是Haar-like特征[6],Haar-like特征是一种类似于Haar小波的简单矩形特征,共有三种类型:边缘特征、线性特征和中心特征,如图1所示,特征模板中包含黑色与白色两种矩形,特征值为白色矩形减去黑色矩形的值,体现了图像的灰度变化。
(1)边缘特征
(2)线性特征
(3)中心特征

图1 Haar-like特征
所有的矩形特征都可以用r=(x ,y,w,h,α )这个五元组来表示,其中x,y为坐标轴的基坐标,w表示该矩形特征的宽,h则为高,而α是旋转的角度。
2. 2 积分图
鉴于矩形特征太多,而求算相应特征值也很麻烦,因此我们利用积分图以达到快速计算的目的,此方法的优点是不用再次计算所测区域的像素和,积分图如图2所示。
(1)倾角为0度的矩形特征的SAT( )x,y计算公式以及像素和Rectsum(r)的计算公式为:

其中I(x',y')表示像素点(x',y')的像素值。
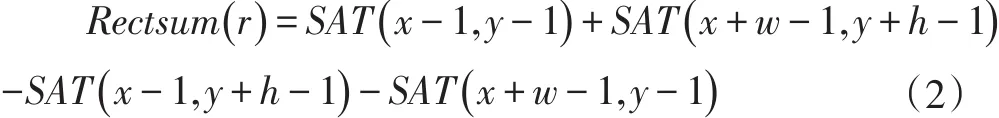
(2)旋转角度为45度的矩形特征的TSAT(x ,y)计算公式以及像素和Rectsum(r)的计算公式为:
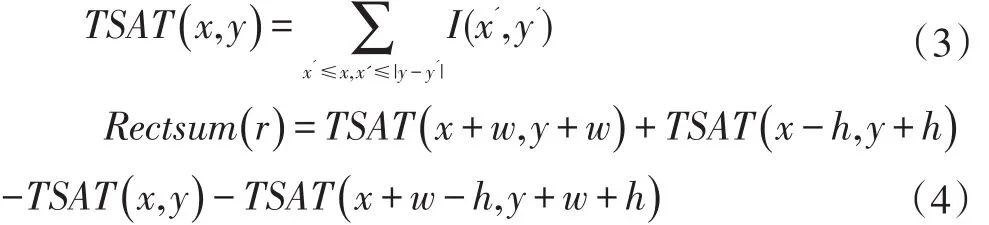

图2 积分图
2. 3 生成弱分类器
矩形特征数量和特征值被确定之后,我们需要对每一个特征 f训练出一个弱分类器,定义一个弱分类器h(x ,f,p,θ),找出 f的最优解,使得这个弱分类器对所有的训练样本的分类误差最低。

其中x是待检子窗口,f(x)是计算特征值的函数,θ是通过训练得到的特征值的阈值,p表示不等式的方向,取值为+1或-1。
2. 4 分类器训练过程
(1)h(x ,f,p,θ)是弱分类器的学习算法,T是循环迭代次数。
(2)用下面的公式对所有样本权值初始化

其中m为人脸样本,l为非人脸样本的数目。
(3)for t=1:T
①调用上面的弱分类器的学习算法,计算加权分类的误差,据此选取一个弱分类器并记录其相应的特征:f,p,θ。

②定义hi(x)=h(x,fi,pi,θi),其中 fi,pi,θi是 εi的最小化因子。
③令:
④更新权重:

2. 5 输出最终的强分类器

3 实验结果
AdaBoost算法因为采用了分类器的级联而有效提升了系统效率,它能够保证较快排除非人脸区域。AdaBoost算法具备速度快与精度高等优点,系统性能总体十分良好,稳定性也很高,但是也有较为明显的缺点,例如用弱学习算法进行训练分类器的时候,花费了大量的时间计算矩形特征值,时间复杂度比较高,若对训练过程进行优化会提高检测效率,同时对噪声极为敏感,在有背景复杂干扰时,检测能力比较差。表1为在不同实验环境下本算法检测人脸的实验结果,效果良好。表2为相同实验环境下本算法与其他几种经典算法实验结果对比,可以看出,基于AdaBoost的检测方法相比其他算法检测速度快,准确率高,综合性能良好。
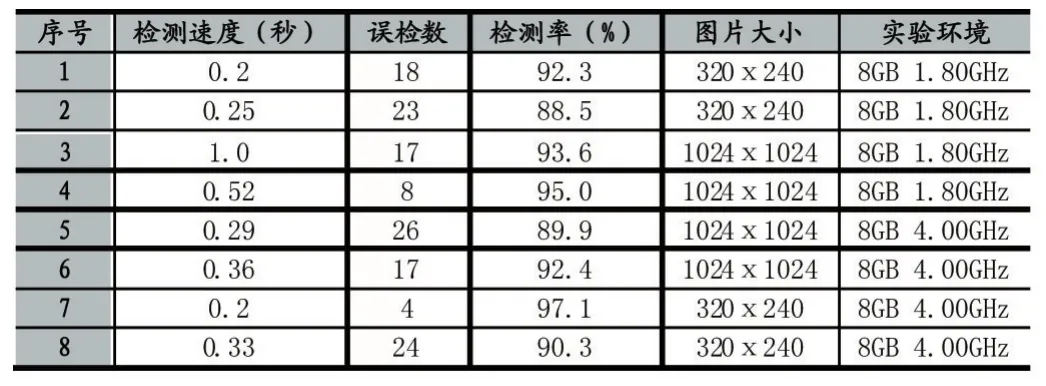
表1 部分实验结果
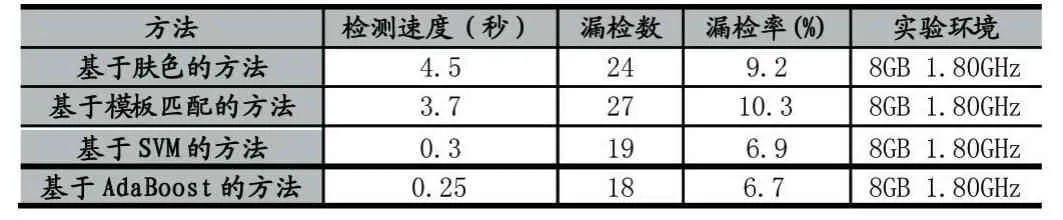
表2 几种方法实验结果比较
4 结语
在人脸检测技术的发展历程中,基于AdaBoost的算法一直是受人瞩目的,它的高效优越性能使得实时检测得以实现,因此在近年来被很多研究者青睐[7]。在速度和精度方面,精度的研究己经具有较成熟的理论和模型,亦可达到良好的效果,而速度的研究则在很长一段时间内成为人脸检测相关领域的研究热点。现在的研究方向一般集中在保证检测系统精度和稳定性的情况下,提高系统速度以达到实时检测的目标。系统速度通常包括训练和检测两个部分,而AdaBoost算法的检测速度非常快,已能够进行实时的检测[8]。
随着经济社会的发展,人们对人脸检测在安全、快速、高效等方面的要求越来越高,大量有关算法陆续被提出,人脸检测系统的研究也愈来愈深入。为了建立更完美更可行的人脸检测系统,达到通过人脸高效识别身份的目的,笔者认为以下几个方面值得继续深入研究:在单一的环境下检测人脸很简单,但是在各种复杂背景和不同光照的情况下精确检测人脸却很困难很复杂,如何找到这样的方法是一个值得研究的问题;可以建立由更多人脸样本组成的人脸数据库,帮助解决更复杂的问题;在人脸检测的过程中,可以把人脸与语音、指纹、虹膜等其他特征结合起来,成为一种新的身份鉴别方法,以此更精确地识别身份。
