基于优化集成学习的CKD透析时机预测
2019-05-17熊长柱李健
熊长柱,李健
(四川大学电子信息学院,成都610065)
0 引言
慢性肾病在全世界内广泛存在,它是一种进展性疾病,同时早期发生率是晚期的100倍。过早的透析不利于残余肾功能的保存和复原,因此,借助数据挖掘技术挖掘出能指导患者接受透析治疗的关键指标很有必要,辅助医生合理选择透析时机。目前没有一种针对终期末肾病(End Stage Renal Disease,ESRD)透析时机选择的算法。在这种情况下,本文提出了一种基于优化集成学习的模型融合方案提高透析预测精度,通过确定这些特征,医生能决定患者是否需要透析,合理地为患者选择透析时机,改善患者生存率。
目前研究已经证实血液透析前和透析后患者死亡率有明显区别[1-3],而且透析时机对患者其他并发症有影响[4],另外血液透析对甲状旁腺素、钙变化与心脏病死率也有重要的影响[5],因此血液透析的研究有重要的现实需求和意义[6]。目前在透析时机的研究上也已经有许多工作,例如:老年肾病和透析的诊断与治疗[7];血液透析在降低血液透析患者的全因死亡率和心血管死亡率的研究[8-10]。
1 特征选择
本文采用的特征选择过程包括产生过程、评价函数、停止准则、验证过程这四个部分。PCA(Principal Component Analysis)可看作是依次选取方差最大方向,它是通过沿着数据最大方差方向旋转坐标轴来实现的。本文采用的PCA算法描述如下:
输入:样本集D={x1,x2,...,xm};
低维空间维数d'
过程:
2:计算样本的协方差矩阵XXT;
3:对协方差矩阵XXT做特征分解;
4:取最大的d'个特征值所对应的特征向量 ω1ω2,...,ωd';
输出:投影矩阵 W=(ω1ω2,...,ωd')
PCA仅保留样本均值向量即可通过简单的向量减法和矩阵向量乘法将高维样本投影到低维空间。PAC一方面舍弃部分信息可以增大样本的采集密度;另一方面当数据中有噪声时,舍弃最小特征可以在一定程度上起到去噪效果。
2 集成学习
2. 1 算法描述
本文综合利用 RF(Random Forest)、AdaBoost、GB-DT(Gradient Boosting Decision Tree)等集成学习器和SVM(Support Vector Machines)、KNN(k-Nearest Neighbor)、NB(Naive Bayes)、DT(Decision Tree)、MLP(Multilayer Perceptron)、ET(Extremely Randomized Trees)、LR(Logistic Regression)七种分类器,用大量不同数据集来训练和测试十种模型,进行多项实验,最后确定此十个模型的最佳权重值。在建立预测模型的过程中每个弱学习者都为分类器,并且通过投票加权方式执行集成学习。模型根据每个弱分类器的不同预测性能,分配不同的投票权重。预测性能越高,投票权越大。最终预测结果是每个弱分类器预测结果的加权平均值。这样可以提高模型的预测性能,并且可以防止单个学习器过拟合。
2. 2 支持向量机(SVM)
本文采用支持向量机(Support Vector Machines)作为集成模型的核心分类器。SVM的目的是寻找一个超平面来对样本根据正例和反例进行分割,其学习策略便是间隔较大化,最终可转化为一个凸二次规划问题的求解。输入一个训练数据集 T={(x1,y1),(x2,y2),…(,xn,yn)},其中xi∈ χ=Rn,yi∈ γ={-1,+1},i=1,2….,N;输出为分类决策函数。选取适当核函数K(x,z)和适当的参数C,构造并求解最优问题。
参数C为惩罚参数,(α1*,α2*,...,αN*)T为拉格朗日乘子向量。当K(x,z)是正定核函数时,上式为凸二次规划问题。
2. 3 AdaBoost提升方法
AdaBoost是一种可将弱学习器提升为强学习器的算法。AdaBoost采取加权多数表决的方法,加大分类误差率小的弱分类器权值,使其在表决中起作用较大,减小分类误差率大的弱分类器,使其在表决中起作用较小,AdaBoost算法流程如下:

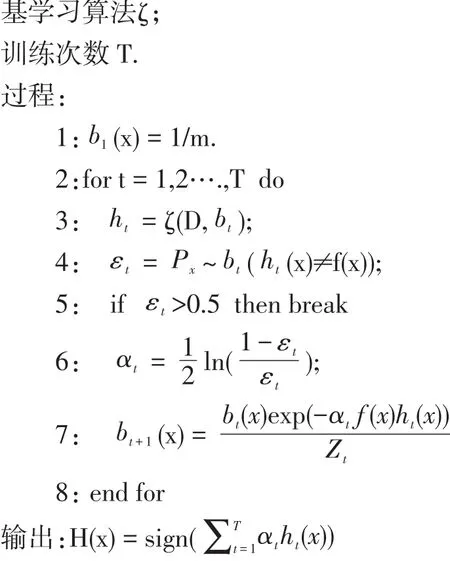
如上所示,在第1-4行中,初始化样本权值分布,基于分布bt从数据集D中训练分类器ht,并估算出ht的误差。在第6-7行中,确定ht的权重,更新样本分布,其中Zt是规范化因子,用来确保bt+1是一个分布。
3 实验结果
3. 1 ESRD数据准备及预处理过程
实验数据来自成都军区总医院HIS系统肾内科2011年1月至2015年12月采集到的肾病患者临床检验结果,包含医院在此阶段所有的肾内科287059条不完整临床数据。经过数据预处理,本章确定的研究对象为慢性肾病样本1338例,包括25个特征,其中包含透析样本507例,不透析样本831例。25个特征经过PCA降维后得到特征集相关重要性如图1所示。

图1 特征集相关权重图
如图1所示,以SCR为百分比参考的权重系数可知,SCR权重占主导地位,SYSC、CCR和BUN等特征子集占重要作用。
3. 2 集成学习实验结果分析
根据LVW 方法选择前 5个特征:SCR、SYSC、CCR、BUN和P,实验利用十种分类器进行模型融合。本实验数据样本随机分为训练集80%(1070个样本)测试集20%(268个样本),经过10次随机实验取模型预测性能平均值。其中SVM模型性能指标表如表1所示。

表1
本文利用RF、AdaBoost、GBDT等集成学习器和SVM、KNN、NB、DT、MLP、ET、LR 等分类器进行模型融合,其中集成模型的ROC曲线如图2所示,输出混淆矩阵图如图3所示。
由图2模型ROC曲线计算得到AUC值为0.97,可知集成模型效果比单一学习器要好。由图3集成模型混淆矩阵可得,在测试集268个样本中仅有5个样本分类错误。本文用大量不同数据集训练和测试十种模型,进行多次实验,以此确定模型的最佳结合策略,实验采用十倍交叉验证法。如表2为集成模型和其他学习器的性能比对表。

图2 集成模型ROC曲线

图3 集成模型混淆矩阵

表2
如表2所示,在与其他学习器模型比对中可知,本文提出的集成模型有最好的平均精度和较低的标准偏差。实验结果表明本文提出集成学习的模型是一种有效的透析预测方法。
4 结语
本文对ESRD透析时机进行了分析和预测,研究了不同模型对预测性能的提升效果,提出了基于集成学习的预测模型。我们通过其他十种学习器的大量对比实验可知,本文提出的基于集成学习的模型具有降低亢余特征和消除噪声的明显效果,具有更加优良的泛化能力以及更低的标准误差。研究结果已经证实本文提出的模型在透析时机预测中具有有效性。
