基于改进Apriori算法的多源安全日志关联分析
2019-05-17瓮俊昊
瓮俊昊
(四川大学计算机学院,成都 610065)
0 引言
随着网络规模的逐渐扩大,互联网相关技术的日新月异,安全问题也日益突出,屡见不鲜的病毒、漏洞、攻击层出不穷。网络安全问题不仅严重影响了人民的生活,还对一个国家的安全和经济发展产生了严重威胁[1]。对于网络安全信息分析来说,日志数据作为信息挖掘的依据和基础在其中占据着重要的地位,日志描述了设备的相关行为,其中存在着大量未知信息,安全日志数据分析可以用来监测网络的入侵行为,在故障或安全事件发生时,日志就像是黑匣子,维护人员可以从这些数据记录中进行分析,查找故障源、获取攻击行为、重建攻击过程等,通过对安全隐患或事件的分析,执法机关还可以用来打击网络犯罪[2]。
现如今,随着日志数据的数量越来越多,类型越来越多样,数据处理的要求也越来越高[3],日志分析系统的功能就是通过对日志数据的分析发现系统的异常以便提出应对策略。网络管理人员可以通过对日志进行分析来寻找网络故障的原因,还可以根据分析结果找到攻击者遗留的痕迹。但是由于日志数量繁多,而且根据日志的特点,它在种类上具有多样性,不同设备产生的日志差异较大,所以有效地对日志进行处理分析才能得到分析人员的预期结果[4]。目前为止,针对日志分析已有许多方法,并且也衍生出了许多日志分析工具。目前针对安全日志的关联分析方法大致可分为4类,分别是基于统计、基于规则库、基于状态转移以及基于数据挖掘的分析方法。本文重心是在研究基于数据挖掘的日志分析的基础上,对基于Apriori算法的关联分析方法进行改进,从而在日志分析上能够提供更高的效率。本文主要提出一个基于矩阵Apriori算法增加权重向量的关联规则挖掘方法,并根据测试数据集进行效率测试,验证了该方法在关联规则的挖掘上能够大幅提高运行效率。
1 多源安全日志关联分析
多源日志的关联分析是指通过特定的规则对从多种设备上收集到的日志进行相关性描述,然后通过使用一些关联分析算法从这些结果数据中提取安全事件[5]。企业信息系统中包含路由器、防火墙、IDS/IPS、交换机、服务器和SQL数据库等多个种类的设备[6]。各种复杂的应用系统和网络设备每天都产生大量的日志信息,查找如此海量的数据并分析出其中的安全事件,对管理员来说意味着海量的工作和拖延的工作效率。在互联网中海量异构的日志大致分成以下三类:System log(UNIX/LINUX、Windows)、Network de-vice log(硬件设备、安全设备)、Application log(Web、软件等)。
在基于数据挖掘的网络安全日志分析方法中,Apriori算法的应用十分广泛,通过挖掘数据集中的不同规则,找出满足给定条件下的多个领域之间的依赖关系[7]。通过使用频繁项目集的挖掘算法挖掘出了网络中异常事件的IP、端口等属性间的关联特征,以帮助分析人员对网络安全事件进行识别[8]。对网络安全日志进行关联分析时,因为网络中的连接信息是多属性元组,所以在挖掘过程中使用的是多维关联规则。例如在对IDS日志进行挖掘分析时得出的其中一条规则:{SIP:220.228.136.38,DIP:11.11.79.83,EventType:Attempted information Leak,123}该规则表示目的IP 11.11.79.83在被监控时间内被源IP 220.228.136.38使用Attempted Information Leak攻击共计123次。通过Apriori算法可以挖掘出各安全事件IP、端口间的关联关系,从而建立起各安全事件的属性特征,提高事件的检测效率。本文提出了一种基于矩阵的Apriori增加权重向量的改进方法来进行挖掘,下一节将进行详细描述。
2 基于改进矩阵Apriori算法的关联规则挖掘研究
2. 1 传统Apriori算法的关联规则挖掘
传统基于Apriori算法的技术通常应用于查找项集之间的具有可信的和代表性的规则[9],类似A⇒B的表达式即一条关联规则,Apriori算法包含两个常用指标,分别是支持度(Support count)和置信度(Confidence),支持度(Support count)表示事务集T中事件A所发生的频率,支持度越高,说明这个事件发生的越频繁,用A.count表示计数:Sup_count(A⇒B)=,其中N表示事务集T中的事务总数。置信度(Confidence)表示A的前提下B同时发生的条件概率,它决定了关联规则是否足够准确,有以下公式计算:
在Apriori算法中,满足预先设定的最小支持度min_sup的项目集合,称为频繁项集,然后从中提取的所有规则中寻找到满足预先设定的最小置信度min_conf的规则,称为强关联规则。关联规则挖掘算法实际上就是一个不断生成频繁项集并寻找强关联规则的过程。传统的Apriori使用广度优先查找方式来找到频繁1项集,并由(k-1)-itemset自连接生成kitemset,其中 k=2,3,…,m;m 代表最大的项目集合,通过min_sup修剪来获得最终的频繁k-itemset。
2. 2 基于矩阵的Apriori算法研究
在传统的Apriori算法中,当我们使用频繁(k-1)-itemset自连接生成k-itemset时,如果频繁(k-1)-itemset的数量非常大,Apriori算法需要进行大量的I/O操作从而占用大量的CPU资源,而且会得到很多的候选项集,效率低下[10];同时,传统Apriori算法缺少对安全日志自身结构的考虑,所以在进行关联挖掘时会产生许多无效规则。针对Apriori算法存在的缺点,众多学者提出了多种改进方法,例如将矩阵融入到Apriori算法中产生的基于矩阵的Apriori算法[11],用0-1矩阵的方式存储和展示数据,只需通过矩阵的运算就能得到所需要的频繁项集,而且全程只搜索一次数据库,就能得到所有符合条件的项集,大幅度提高算法效率,同时减少大量候选项集的产生,节约了存储空间[12]。
事务中的每个属性及事务集按照序列排列。矩阵中的行表示事务中的属性,列表示事务。假设在m事务中存在编号n的属性,则对应生成的矩阵中第m行的第n列的值记为1,反之为0,矩阵中每列数字的和为属性计数,即为支持度的计算结果。例如对于二项集(Mm,Mn),仅需要查看矩阵的第m、n行上处于相同列中均为1的计数,便为它的支持度。以下是基于矩阵的Apriori算法步骤:
(1)首先根据事务集T构造0-1矩阵MT。其中若属性n在事务m中出现,则对应矩阵元素Mij=1,反之Mij=0。
(2)对MT每列1的值进行计数,删除计数结果低于min_sup的项(行向量),对满足min_sup的结果每两列做向量的交运算。
(3)利用上述结果构建新矩阵,重复此过程,直到不再产生新矩阵,最终矩阵就是我们要求的频繁项集。
使用基于矩阵Apriori算法的具体计算流程如图1。

图1 基于矩阵Apriori算法计算流图
2. 3 基于改进的加权矩阵 Apriori算法研究
2.2小节描述的算法在计算过程中会不断生成新的矩阵,而且根据事务量的不同,矩阵也同样需要发生变化,本文通过研究Apriori算法生成矩阵中的数据关系,发现很多行和列可以进行优化,通过增加一个权重向量的方式,对矩阵整体进行精简,提高计算效率。
假设事务集T中含有m条事务和n个属性,二进制布尔矩阵可据此构建如下:
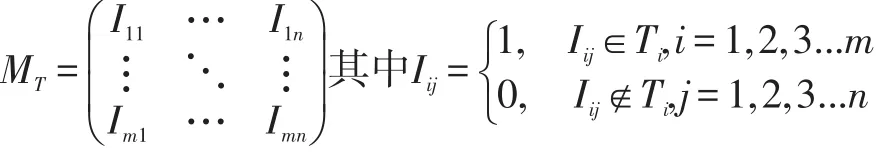
其中Ti代表事务集合T中第i条记录,存在一个权重向量WT,初始时WT={1 ,1,...,1},当连续扫描Ti时如果发现相同的事务,对应权重值加1,同时删除矩阵中相应行,支持度sup_coun(tI)可由WTI表示,I是矩阵中的列向量,具体算法流程图如图2。

图2 基于改进的加权矩阵Apriori算法流程图
根据Apriori算法的性质,我们有以下两个推论:
推论1:如果两个频繁项集(k-1)-itemset可以进行连接生成k-itemset,那么它们必然存在一个相同的(k-2)-itemset。
推论2:如果项目集是频繁的,那么它的所有子集必然也是频繁的,相应的,非频繁项集的超集肯定也是非频繁的。
同样使用图一中示例事务集T,构建初始矩阵并进行运算过程如下:

3 实验对比分析
为了验证基于矩阵加权的Apriori算法的性能,本节将该方法与传统基于矩阵的Apriori算法进行相同环境下的对比实验,实验环境在处理器为Intel Corei7-7700 CPU@3.6GHz、内存为16G的64位计算机上进行,程序在Weka平台下测试,数据集选用在UCIMLRepository中的Retail数据集,专门用于数据挖掘中的算法测试。
从该数据集中分别随机选择1000,5000,10000,30000,50000条记录作为测试用例,min_sup=20%,两种算法的运行时间比较如图3。
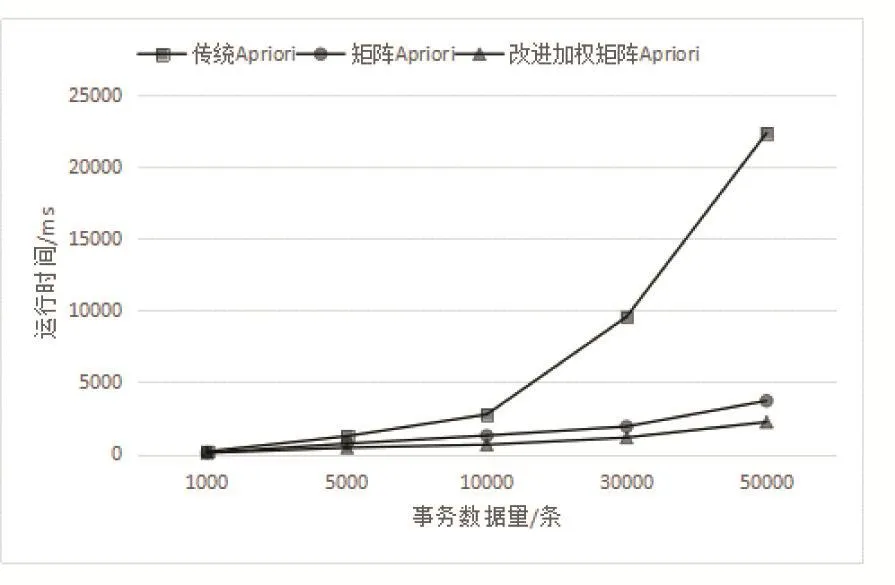
图3 不同算法的性能测试比较
从图3所示结果中我们可以看出,在相同数据集的情况下,选择不同事务数据量的情况下,改进的加权矩阵Apriori算法的性能比较传统的Apriori算法有着大幅度的提升,同时相对传统的基于矩阵的Apriori算法也有一定程度的提高,并且在事务量逐渐增大的情况下,改进的算法运行效果的提升越来越明显。
4 结语
本文研究了多源安全日志的关联分析方法,首先介绍了多源安全日志的基本概念和常见关联分析方法,研究了基于数据挖掘的日志分析方法,针对传统Apriori算法在运行过程中效率低下的缺陷,提出了一种基于Apriori矩阵结合权重向量的改进方法,并通过与传统Apriori算法、传统矩阵Apriori算法的对比实验分析,结果证明了本文提出的改进算法的有效性,为多源安全日志关联分析方法的进一步研究提供了可靠依据。
