基于Web数据挖掘的科研协同服务模式探索
2012-04-29王彩虹
王彩虹
[摘要]Web数据挖掘技术是实现个性化科研协同服务的关键技术。本文以学科馆员协同高校科研教师完成重大科研项目为目标,以Web数据挖掘技术为基础,综述了Web数据挖掘的概念、研究方法、国内外研究现状以及学科化科研协同服务的内涵。设计了科研协同服务平台及其运行机制,力求为学科馆员融入高校科研一线提供新的思路和决策。
[关键词]Web数据挖掘;学科馆员;科研协同服务
DOI:10.3969/J.issn.1008—0821.2012.05.013
[中图分类号]G250.7
[文献标识码]A
[文章编号]1008—0821(2012)05—0051—04
随着我国科技水平的不断发展,高等学校生源和就业问题的加剧,高校生存和发展的竞争变得日益激烈。在全方位的竞争当中,教师的科研实力是衡量学校办学水平的最重要砝码,已经成为高校争取排名的坚强武器。教师科研项目或课题的申报越来越需要强有力的论据材料和论证方法来支撑,其项目研究也不断尖端化细致化。一些骨干教师在繁忙的教学工作中,担负着国家级自然科学基金或社会科学基金等重大项目的研究任务。在其项目申报、项目研究、项目结题发布过程中,迫切希望高校图书馆的学科馆员能为其项目研究提供合理的信息导航和信息过滤等服务工作。因此,研究如何在网络环境下,以“用户为中心”,采用恰当的Web数据挖掘技术,挖掘出科研教师用户急需的信息资源,协助其解决科研过程中遇到的实际问题,是学科服务深层次化、个性化的一个新领域,具有独特的研究优势。
1 Web数据挖掘鲜活科研协同服务
1.1Web数据挖掘
1.1.1Web数据挖掘的概念及研究方法
Web数据挖掘(Web Data Mining),简称Web挖掘。是从大量的、不完全的、有噪声的、模糊的、随机的数据中提取隐含在其中的人们事先不知道但又是潜在有用的信息和知识过程。它是数据挖掘技术在Web环境下的应用,是从数据挖掘发展过来的集Web技术、数据挖掘、计算机技术、信息科学等多个领域的一项技术。Web数据挖掘可分为3类:Web内容挖掘(Web Content Mining)、Web结构挖掘(Web Structure Mining)和Web使用模式挖掘(Web Us-age Mining)。其主要研究方法包括访问路径分析、关联规则发现、序列模式分析、分类规则发现、聚类分析等。其所处理的对象包括静态网页、Web数据库、Web结构、用户使用记录信息等。
1.1.2国内外Web数据挖掘的研究现状
20世纪90年代以来,数据挖掘技术已在国内外掀起了研究热潮。国外的IBM、NEC等机构对Web数据挖掘进行了大量的研究,并取得了一定的成果。S.Charkrabarti对超文本数据挖掘进行了研究,并指出基于知识的算法将会在Web数据挖掘中扮演重要角色;加州理工学院喷气推进实验室与天文科学家开发的SKICAT系统,能够帮助天文学家发现遥远的类星体。而国内对数据挖掘技术研究虽然较迟,但依然持续升温。有研究者将数据挖掘的因子分析法和聚类分析法相结合,分析我国各地区船舶工业发展的现状,为决策者决策提供科学合理的依据,指导我国船舶工业经济发展的规划和战略,缩小各地区我国船舶工业发展的差异。清华大学对科技文献检测算法进行大量研究,并开发了一套面向计算机领域的英文科技文献监测系统——AmetMiner。该系统从公开的文献数据库(如:DBLP、Citeseer等)抓取相关的文献数据,从Web上抽取研究者的Profile信息,然后将其集成在一起,并在此基础上根据合作关系构建学术网络,并进行深入挖掘,提供如权威专家/期刊/会议发现、关联路径发现等服务;中国人民大学开发的KBDL系统也是通过数据挖掘技术研制成功的仅供本馆使用的个性化服务系统。
1.2协同理论与协同科研服务
协同理论一词来自希腊语,意指关于“合作的科学”。创始人是前西德理论物理学家赫尔曼·哈肯。协同理论研究各种完全不同的系统在远离平衡时通过子系统之间的协同合作,从无序态转变为有序态的共同规律。其在自然科学和社会科学的各个领域都有广泛的作用,强调人的合作能力和合作精神。而Web个性化服务实际上是指以用户需求为中心的Web服务,图书馆利用现代技术、人工智能技术和专家系统等,主动获取图书馆用户个性化的特定信息需求,以及特定用户群体的共同信息需求,针对用户需求检索网络信息和馆藏数字信息,并根据用户要求把用户所需信息推送给用户的一种综合服务机制。在网络环境下,Web数据挖掘技术是实现个性化信息服务的关键技术,它将开创个性化协同服务的新局面。因此,我们认为,基于Web数据挖掘的科研协同服务是指为了提高学科化服务的质量和效率,学科馆员与科研教师协同工作,以Web挖掘为基础,以协助科研用户圆满完成研究项目为目标,根据科研教师在前期准备、研究过程和成果发布3个阶段中所必须的关于Web数据挖掘方面的帮助,直接融入用户并实际解决问题,挖掘具有前沿性和权威性的信息资源,提供有针对性的、符合其科研要求的个性化知识挖掘服务。
2 基于Web数据挖掘的科研协同服务平台的构建
2.1科研协同服务平台的设计
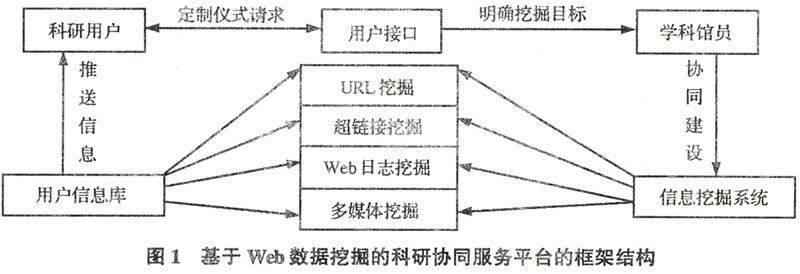
在协同服务平台设计方面,我们以湖北师范学院教师申报的自然科学基金项目中个性化Web数据挖掘信息服务需求为中心;以提供专业化、智能化、深层次化的知识服务为原则;以实现用户在科研过程中不同阶段的隐性知识转化为显性知识为目标;分析用户所提供的数据,创建符合用户特性的访问模式;结合用户的特性,向用户提供符合其特殊需求的信息服务为宗旨。在网络环境下,构建科研协同服务平台如图1:
2.2平台研发的原理
基于Web数据挖掘平台研发的原理为:科研用户通过身份验证进入个性化信息服务系统,通过用户接口模块提出科研项目中自己需要定制的信息请求。学科馆员收集信息请求,明确科研项目的主题和要求挖掘的目标,建立信息挖掘系统,确定Web数据挖掘的方法,并采用先进、合理的数据挖掘技术、计算机技术、数据分析技术等对收集的信息进行过滤、处理、集成。再把这些新获取的信息集合到用户信息库中,最后推送给科研用户,并得到用户的反馈,以便改进和完善个性化、学科化信息服务工作,协助用户进行科学研究。
3 基于Web数据挖掘的科研协同服务平台的运行
3.1运用URL挖掘,集成科研用户定制的特色信息源
统一资源定位符(URL,英语Uniform Resource Locator的缩写),也被称为网页地址,是因特网上标准的资源地址。它最初是由蒂姆·伯纳斯一李发明用来作为万维网的地址。法国图书馆的“网络文献采集项目”BnF就利用了Web结构挖掘的发现功能。它首先利用Web挖掘技术,获得包含相关主题的网络资源的一系列网址,经过分析处理,BnF把这些网址发送给有关专家,以评估是否进行采集;国内清华大学计算机系智能技术与系统国家重点实验室的马亮等设计了智能Web中文主题信息收集系统IRobot,该系统在对已搜集页面的主题相关度评价时综合考虑了页面的标题、段落标题、Anchor文本(所引用URL的说明文本)等对于页面评价具有较高价值的特征区域,并赋予了相对较高的权重系数,以此期望提高评价的准确性。Web上信息量庞大,要想挖掘科研用户定制的重要性较高的信息资源,学科馆员在收集科研教师定制的信息请求后,必须利用Web结构挖掘(Web—Structure Mining)中的URL挖掘方法,通过加权的启发式搜索算法来搜集对用户有利用价值的URL,自己加工处理,尽量使用目录短的、参数少的、关键词靠前的、已经过滤的URL,这些UP&都和科研项目主题息息相关,以便用户能快速地、有选择性地搜集网络空间,发现或下载与研究主题相关的信息,提高科研信息资源采集的速度。因此,根据实际,笔者所在的湖北师范学院教师在申报国家自然科学基金项目过程中,相应院系的学科馆员除了在图书馆现有的外文资源EBSCOhost(全文/文摘)、WordSciNet电子期刊(全文)、SprringerLINK电子期刊(全文)等数据库中找到与申报主题相关的文章或文摘的链接地址推荐给用户外,还在运用URL挖掘过程中,主动预测可能有价值的URL来增加信息发现的主动性;在URL被加入自建数据库时,结果插入进程调用过滤函数对URL进行过滤,同时也对IP地址进行过滤,避免重复的访问和冗余的信息。
3.2使用超链接挖掘,获取研究项目的发展新动态
Web上成千上万的WWW服务器通过网页之间的链接构成海量的信息。通常情况下,网页抓取的步骤是:从任务池中取一个任务地址URL,通过DNS得到其IP地址,用该IP地址与Web服务器建立TCP/IP连接,发出HTTP请求,等待接收HTTP应答,关闭TCP/IP连接,分析收到的网页,将其中包含的新链接加入到任务池中,将网页存放到磁盘数据库中。学科馆员使用超链接挖掘的目的是找出与科研项目主题相关的中心页面和权威页面,减少用户搜索网页的时间,降低重要信息遗漏的几率。因为从页面的作用来看,中心页面是相关信息的链接契合点,通过它很容易找到大批与科研项目相关的链接;权威页面是科研过程中用户必须了解的核心,通过权威页面的浏览,用户能够了解自己所研究项目领域的最新动态、科研进展、成果和思想、发展趋势等。为了协同科研教师了解其所申报主题的新颖性和发展的新动态,湖北师范学院的学科馆员为每个科研用户建立了个性化MyLibrary系统后,该系统采用的是目前主流的Web服务模式。用户通过Cookie的浏览器登录MyLibrary系统,设置账号和密码,并根据自己的知识结构、信息需求对馆藏数字资源和其他网络资源进行筛选、整理。用户完成设置后,动态建立MyLibrary,进入中心页面或权威页面定制自己所需求的内容。定制的内容包括我的教育与研究资源、我的数据库、我的图书馆链接、最新资源通报等。
3.3巧用Web日志挖掘,鼓励科研用户参与互动
Web日志挖掘过程可分为4个阶段:①数据采集阶段;②数据预处理阶段;③模式发现阶段;④知识获取阶段。Web日志挖掘的主要数据来源于服务器端日志,其中服务器日志尤为重要,是目前Web日志挖掘的主要研究对象。由于Web多级缓存机制导致服务器端无法记录用户的访问行为,因此,学科馆员对Web访问日志进行分析和挖掘时,必须经过一系列的数据准备和建模工作。首先,学科馆员应对代理端和客户端的日志数据进行采集,获取完整的科研用户访问信息,提高数据信息采集的完整性和全面性;然后把采集到的日志数据、内容和结构信息转换成数据挖掘阶段所需要的抽象数据;再对经过预处理的日志数据进行挖掘,获取隐藏在这些数据之中的规律或模式;最后通过选择和观察把发现的规则、模式和统计值列举出来,利用模式分析或模式转换成对用户有利用价值的知识,推荐给科研用户并得到反馈。学科馆员巧用Web日志挖掘技术,对担任重大科研项目研究的用户有两个好处:第一,能根据用户的需求对网页的内容、结构、布局进行个性化的定制;对数据负荷进行有效管理,鼓励用户参与信息资源的选择、评价,并允许用户根据个人的需要对学科馆员挖掘并推荐的信息资源进行注释,使馆员和用户的互动性变强,方便馆员对推荐的信息资源进行优化处理,协助教师获取重要的研究资源,提高学科化主动服务的效率;第二,学科馆员通过分析Web页面的缓存模式和访问流量特征,协同高校数字图书馆技术部,采用相应的策略,改善Web服务器的预读机制和负载均衡机制及数据分析机制,从而优化网站服务器的性能,方便教师远程校外访问图书馆数字资源库,提高用户随时访问湖北师范学院数字图书馆的满意度。
3.4选用多媒体挖掘,协助科研用户发布成果
多媒体信息挖掘(Multimedia Mining)就是从大量多媒体数据集中,通过综合分析视听特性和语义,发现隐含的、有效的、有价值的、可理解的模式,得出事件的趋向和关联,为用户提供问题求解层次的决策支持能力。多媒体信息挖掘主要涉及数据挖掘和多媒体信息处理两个研究领域。如何把数据挖掘的基本理论和方法与对多媒体特性的分析结合起来,从多媒体的内容着手,利用多媒体的时间、空间、视觉特性、视听对象及运动特性,挖掘出有价值的隐含的信息线索和知识,已经在国内外多个领域得到应用和发展。如利用多媒体中数据描述与内容通过对相似数据的搜索在医疗诊断、气象预报、TV制作及电子商务等领域得到广泛的应用;多媒体数据的分类和预测分析常被应用于天文学、地震学、地理科学领域;多媒体关联规则挖掘能从大量数据项集中发现有趣的关联或相关联系,从而在商务决策、行为分析、模式匹配等领域被广泛应用。学科馆员利用多媒体数据挖掘技术,结合信息过滤技术,从多媒体数据库选择恰当的文本、图像、视频、音频等数据的目的是为了协同科研用户完成重大项目成果的公开发布,使项目成果能生动形象地得以宣传、演示和实施等,并希望得到合理的评估和奖励。
4 结语
为了应对日益复杂的科学研究问题,科研用户对学科化服务工作的要求越来越高。基于Web数据挖掘的科研协同服务不但使用户在信息检索、信息过滤、数据分析、成果发布等多方面的研究工作效率得以提高,而且使学科馆员真正融入高校科研一线,成为学科服务工作的一个新亮点。但是,由于项目研究具有开创性和尖端性;Web数据挖掘工作具有复杂性和技术性。因此,学科馆员在协同服务工作时应注意两点:
(1)在整个科研项目研究中,由于协同服务工作中存在学科馆员和科研用户的互动比较密切和频繁,因此,学科馆员必须充分保护好用户的隐私,避免用户的研究信息外漏,保护好用户的合法权益。
(2)学科馆员在进行Web数据挖掘时,在进行数据处理、数据挖掘、模式分析等过程中会耗费很多时间和精力,同时也需要很好的耐心和沟通能力,协助科研用户重大项目的研究。因此,学科馆员必须拥有与时俱进、勤钻苦研、吃苦耐劳的精神;更要有强烈的事业心和责任感。
