基于粗糙注意力融合机制与Group Transformer的视网膜血管分割网络
2024-12-09王海鹏高自强董佳俊胡军陈奕帆丁卫平*











摘要:视网膜血管的形态学变化对早期眼科疾病的诊断具有重要意义,除眼科疾病外,糖尿病、心血管疾病等同样可以通过视网膜血管的形态判别疾病进展。然而,视网膜血管本身具有复杂的组织结构,且易受到光线等因素的影响,对其准确分割并不容易。针对上述问题,提出了一种视网膜血管分割网络。该网络中首先设计了粗糙注意力融合模块(rough attention fusion module,RAFM),该模块基于粗糙集上下近似理论,利用全局最大池化与全局平均池化对注意力系数进行上下限描述,并串行融合通道注意力机制与空间注意力机制;然后,将粗糙注意力融合模块融入Group Transformer U network (GT U-Net),构建一种基于粗糙注意力融合机制与Group Transformer的视网膜血管分割网络;最后,基于公开DRIVE彩色眼底图像数据集进行对比实验,该网络结构在测试集上的准确率、F1分数、AUC值分别达到了0.963 1、0.848 8和0.981 2,与GT U-Net模型相比,F1分数、AUC值分别提升了0.35%、0.21%;与其他当前主流的视网膜血管分割网络进行对比,具有一定优势。
关键词:粗糙集;注意力机制;眼底视网膜血管;图像分割;Transformer
中图分类号: TP181" " " " " " " " " " " " " 文献标志码: A文章编号: 1673-2340(2024)01-0028-10
Abstract: The morphological changes in retinal vessels play a crucial role in the diagnosis of early ophthalmic diseases. Beyond eye diseases, conditions such as diabetes and cardiovascular diseases can also be identified through the morphology of retinal vessels. However, retinal vessels possess a complex tissue structure and are easily influenced by factors such as lighting, making their accurate segmentation challenging. To address these issues, a retinal vessel segmentation network that initially incorporates a rough attention fusion module (RAFM) is proposed. This module is based on the theory of rough set upper and lower approximations, employing global max pooling and global average pooling to describe the upper and lower bounds of attention coefficients, and sequentially integrates channel attention mechanisms with spatial attention mechanisms. Subsequently, the RAFM is integrated into the Group Transformer U network (GT U-Net), constructing a retinal vessel segmentation network based on the rough attention fusion mechanism and Group Transformer. Finally, comparative experiments conducted on the publicly available DRIVE color fundus image dataset demonstrate that the network achieves an accuracy, F1 score, and AUC of 0.963 1, 0.848 8, and 0.981 2, respectively, on the test set. Compared to the GT U-Net model, the F1 score and AUC were improved by 0.35% and 0.21%, respectively; and when compared to other contemporary mainstream retinal vessel segmentation networks, it exhibits certain advantages.
Key words: rough set; attention mechanism; fundus retinal blood vessels; image segmentation; Transformer
视网膜血管的形态结构变化是诊断高血压、动脉硬化、冠心病等疾病的重要指标之一。视网膜血管作为人体内唯一可以通过无创手段观察到的清晰血管,其检测与分析对预测和诊断上述疾病有非常重要的应用价值[1]。由于视网膜血管复杂的树状结构,以人工进行视网膜血管分割存在判错率高、耗时长及操作繁琐等问题[2]。基于深度学习的图像分割算法可以帮助医生处理并分析复杂的眼底图像,进一步提高计算机图像分割的速率与准确度,其优化方法受到学者们越来越多的关注[3]。
随着近年来深度学习的进步,基于深度卷积神经网络(convolutional neural network,CNN)的方法已成功地打破传统手工提取特征方法的瓶颈[4],逐渐成为一种主流的图像处理方法。Ronneberger等[5]在全卷积神经网络的编解码结构基础上,构建了一种U型对称网络(U-Net),并在对应层之间添加跳跃连接,实现低层特征和高层特征的拼接和融合。Xiao等[6]在U-Net模型的基础上进行了改进,在每层卷积处加入了残差连接,缓解了模型训练中的梯度爆炸和消失现象,同时加速了收敛。吴晨玥等[7]提出了一种改进卷积神经网络,在编码器-解码器结构的网络中加入了空洞卷积,在不增加参数的情况下增加了感受野。
随着研究的推进,用于自然语言处理的Transformer[8]跨领域地被引入到计算机视觉任务中。利用Transformer在特征图中捕捉长距离依赖的优势,解决CNN因局部偏置和权值共享对全局信息把握不足的缺点[9]。Dosovitskiy等[10]提出视觉转换器(vision Transformer,ViT)模型,利用Transformer全局感受野特性得到比CNN更好的性能,但ViT只使用全局特征,忽视了局部特征。结合两者优势的CNN与Transformer融合网络模型在目前的图像分割任务中比较流行,并在医学图像分割领域获得了较好的效果。Zhang等[11]提出了一个Transformer与ResNet的并行特征提取与融合网络;Chen等[12]基于U-Net的架构,构建了一个联合CNN-Transformer的结构作为编码器,并在解码器中加入可以获得精确位置信息的级联上采样操作。上述方法将卷积神经网络与Transformer模型进行合理融合,取得了不错的图像分割效果。然而Transformer通常需要较大的计算资源与较大的内存资源,将CNN与ViT模型直接融合具有较高的计算复杂度。
注意力机制是一种在深度学习中常用的技术,它可以让模型在处理序列数据时,更加关注当前处理的元素,将注意力机制与深度学习模型结合可以使模型更好地在图像中识别需要关注的部分。Oktay等[13]提出了用于医学成像的新型注意力门模型,抑制输入图像中的不相关区域,突出有价值的显著特征。Gu等[14]提出了一种联合空间注意力模块和一种新颖的通道注意模块:空间注意力模块使网络更加关注前景区域;通道注意力模块自适应地重新校准通道特征响应,并突出最相关的特征通道。Yuan等[15]提出了多级注意力网络以整合从扩展路径中提取的多层次特征,充分利用了低级别的详细信息和不同层中编码的补充信息。
本文提出的视网膜血管分割网络使用Li等[16]提出的Group transformer U network(GT U-Net)为基础框架,将GT U-Net中每层准备跳跃连接的特征图先通过粗糙注意力融合模块(rough attention fusion module,RAFM),再与扩展路径的特征图相拼接,进而减少冗余特征的数量,提升模型的分割效果。
本文主要贡献如下:
1)为了解决ViT模型计算量大、消耗资源多等问题,本文使用GT U-Net为基础框架,其Group Transformer结构有效减少了Transformer的计算复杂度。
2)为了解决视网膜血管分布密集杂乱、血管边界不清晰等问题,本文基于粗糙集上下近似理论,构建了粗糙空间注意力模块(rough spatial attention module,RSAM)和粗糙通道注意力模块(rough channel attention module,RCAM),得到更加合理的注意力系数。
3)为融合粗糙空间注意力模块与粗糙通道注意力模块,本文提出一种粗糙注意力融合机制RAFM,将空间注意力模块和通道注意力模块串行结合,以提高模型的表达能力。
1" "相关工作
1.1" "粗糙集的上下近似理论
粗糙集[17-19]理论用于对不精确、不一致、不完整信息进行分析与处理,是一种在不确定环境中广泛使用的数学工具。它使用近似空间、集合的上下近似运算来处理模糊性和不确定性,通过上下界逼近的方式来刻画不可定义集,这就是粗糙集理论中的上下近似算子。
假设信息表R = {U,At,{Vα∈At}},{Iα∈At},其中:U = {x,x,…,x}是有限非空对象的集合,n为对象的个数;At为有限非空属性集合;V表示属性α∈At的属性值的范围;I为对象属性关系函数,若A?哿At,则I(x)表示论域U中的对象x的属性值。
在信息表R中,称子集X?哿U是可以被属性子集A?哿At定义的,当且仅当由属性子集A定义的逻辑决策语言L(A)中存在一个公式φ使得X = g(φ);否则X称为不可定义的。其中φ为一个对象属性关系对;g(φ)为具有公式φ性质的对象的全体。针对不可定义集,只能通过上、下界对其进行逼近,即粗糙集理论中的上下近似算子。上近似算子(X)是包含X的最小可定义集,下近似算子(X)是包含在X中的最大可定义集。
对于子集X?哿U,论域U将被划分为正域POS(X)、负域NEG(X)与边界域BND(X) 3个区域,分别定义为
POS(X) = (X),(1)
NEG(X) = POS(~X) = U - (X),(2)
BND(X) = (X) - (X)。(3)
若BND(X) = ,说明集合X是精确的;若BND(X)≠,说明集合X是粗糙的。
1.2" "Group Transformer
Transformer起初在自然语言处理领域取得了很好的效果。近年来,以ViT为代表的Transformer模型在计算机视觉领域得到迅速发展,并表现出优异的效果。多头自注意力机制(multi-head self attention,MHSA)是Transformer的核心结构,MHSA的输出为
MHSA(Q,K,V) = Concat(head,…,head)W,(4)
其中:h是头的数量;head表示第i个头部的输出;W是输出线性变换的权重矩阵。
对于MHSA中的一个头部,注意力权重为
Attention(Q,K,V) = soft max()V,(5)
其中:Q是查询向量序列;K是键向量序列;V是值向量序列;d是键向量序列中每个向量的维度。
然而,ViT模型往往需要较大的计算资源与较大的内存资源,且依赖于由大型图像数据库预训练的权重,这导致其在数量不足的数据集上表现不佳。Jiang等[20]提出了一种瓶颈结构将维度为d的嵌入特征投影到维数为d/r的较小空间,其中r为缩放比例。这在很大程度上节省了自我注意力的计算成本,并使得注意力头部产生更紧凑和有用的注意力信息。
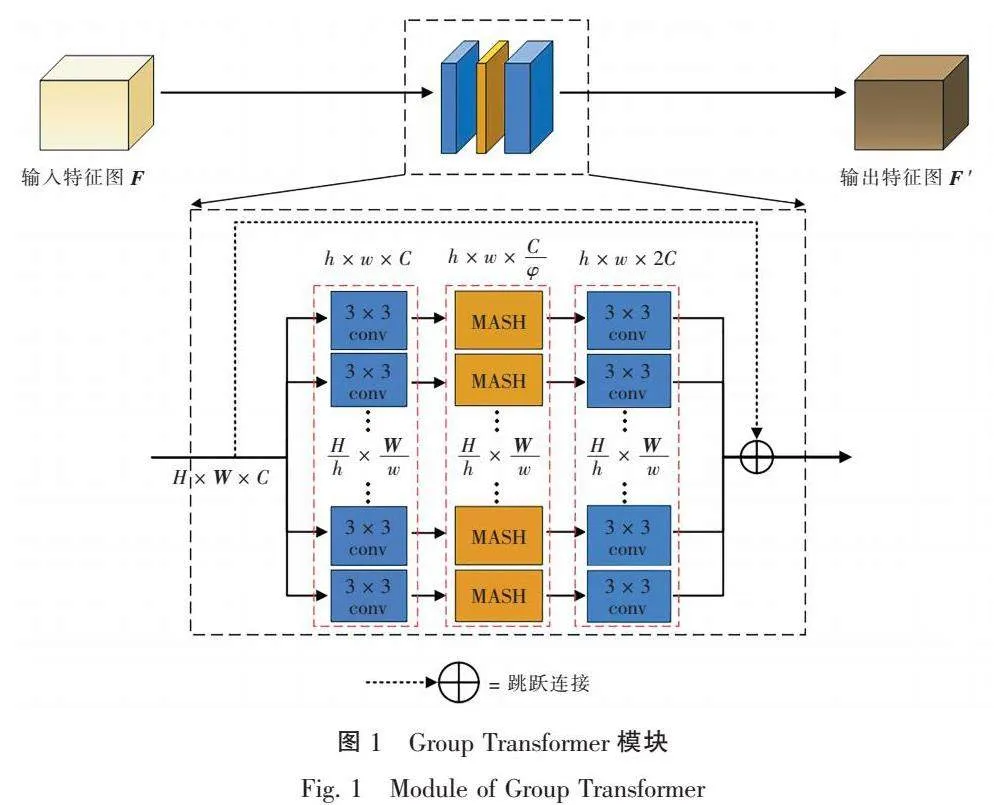
结合医学图像的特点,Li等[16]设计了Group Transformer模块,并构造了GT U-Net网络。如图1所示,Group Transformer模块由跳过连接、分组模块、3 × 3卷积、多头自注意力模块和合并模块组成。其设计的分组模块和3 × 3卷积减少了MHSA的计算量,同时3 × 3卷积弥补了Transformer缺少局部性和全局不变性的劣势。
假设原始特征图大小为H × W × C,MHSA的头部个数为 4,通过分组结构和瓶颈结构,MHSA的计算量将大大减少。改进前的MHSA[21]计算量和Group Transformer(GT)的计算量分别为
Ω(MHSA) = 4HWC + 2(HW)C,(6)
Ω(GT) = HWC + (HW)C,(7)
其中:φ是瓶颈结构的通道缩放因子;h × w是每个Group Transformer单元的大小。
2" "粗糙注意力及融合机制
图像信息包含大量的随机性、粗糙性等不确定性信息,比如眼底视网膜血管的分布杂乱、形状不规则、边缘粗糙不清。这些不确定性信息使得深度神经网络难以取得较好分割的效果。在本节中,将完整地介绍所提出RAGT-Net模型,该模型能够很好地适应视网膜血管的形态特性,处理不确定性信息,获得精确的分割结果。
2.1" "粗糙通道注意力
通道注意力机制[22]主要用于捕捉卷积层中通道间的相关性。具体来说,假设特征图F∈R,首先对特征图分别进行全局平均池化,将特征图F压缩为维度为1 × 1 × C的特征图;然后将压缩后的特征图通过2个全连接层映射成每个通道的权重,2个全连接层之间使用ReLU激活函数,增强了模型的非线性特征并且降低了梯度消失的概率,使用Sigmoid激活函数对每个通道的特征权值进行归一化操作;最后将最终得到的特征图与原先的特征图相乘,对原特征图进行通道特征重标定,并作为下一级的输入数据。
一般而言。全局平均池化在一定程度上具有全局感受野,全局最大池化在一定程度上具有局部感受野。如图2所示,粗糙通道注意力依据粗糙集的上下近似理论,使用全局最大池化和全局平均池化对特征通道重要性进行上下限描述,使得注意力系数值兼具全局信息和局部细节信息。在此基础上进行特征重标定,得到新的视网膜血管特征图。
首先,采用全局平均池化层建立通道之间的依赖关系,并保留全局信息;用全局最大池化层建立通道之间的依赖关系,并保留局部信息。可表示为
F = max(F(m,n)),(8)
F = ∑∑F(m,n),(9)
其中:0 lt; m≤H;0 lt; n≤W;F,F∈R。
其次,将得到的2张维度为1 × 1 × C的特征图分别通过2个全连接层映射成每个通道的权重,表示为
F = Sigmoid(W·δ(W·F)),(10)
F = Sigmoid(W·δ(W·F)),(11)
其中:δ表示ReLU激活函数;W∈R,W∈R分别表示2个全连接层的权重矩阵;r为压缩的比例,本文设置r = 16。
然后,对所得到的通道重要性值的上下限进行加权操作,得到更合理的通道依赖关系,表示为
F = α·F + β·F,(12)
其中,α和β分别表示上下神经元的权重信息。
最后,将得到的通道权重特征图与原先的特征图相乘,对原特征图进行通道特征重标定,并作为下一级的输入数据,表示为
F = F·F。(13)
2.2" "粗糙空间注意力
空间注意力机制[23]是通过一个空间权重矩阵赋予每层像素点不同的权重。具体来说,假设特征图F∈R,首先对特征图分别进行全局最大池化与全局平均池化,将特征图F压缩为2张维度为H × W × 1的特征图;其次将得到的特征图进行堆叠,得到维度为H × W × 2的特征图;然后通过一个卷积层,最终得到的特征图维度从H × W × 2变为H × W × 1,特征图上每个像素点的数值大小代表其重要程度,使用Sigmoid激活函数对每个通道的特征权值进行归一化操作;最后将最终得到的特征图与原先的特征图相乘,对原特征图进行像素点特征重标定,并作为下一级的输入数据。
如图3所示,粗糙空间注意力机制同样是通过全局最大池化和全局平均池化对各通道像素点的重要性进行上下限描述。
首先,利用全局平均池化层建立空间之间的依赖关系,并保留全局信息;利用全局最大池化层建立空间之间的依赖关系,并保留局部信息。可表示为
F = max(F(k)),(14)
F = ∑F(k),(15)
其中:0 lt; k≤C;F,F∈R。
其次,将得到的2张维度为H × W × 1的特征图分别通过一个卷积层,表示为
F = Up(δ(Conv(F))),(16)
F = Up(δ(Conv(F))),(17)
其中:Conv表示一个卷积核大小为7 × 7的卷积运算;δ表示ReLU激活函数;Up表示采用双线性插值法的上采样操作。
然后,对所得到的空间重要性值的上下限进行加权操作,得到更合理的空间依赖关系,表示为
F = αF + βF,(18)
其中,α和β分别表示上下神经元的权重信息。
最后,将得到的空间权重特征图与原先的特征图相乘,对原特征图进行空间特征重标定,并作为下一级的输入数据,表示为
F = F·F。(19)
2.3" "粗糙注意力融合模块
Fu等[24]提出了一种双注意力网络(dual attention networks,DANet),实现了自适应集成场景分割任务中局部特征及全局依赖关系。Mei等[25]提出了自我注意融合模块(self-attention fusion,SAF),该模块将空间注意力和通道注意力并行结合,提高了经典模型对单图像超分辨率的全局特征表征能力。受此启发,本文引入了粗糙注意力融合模块RAFM。
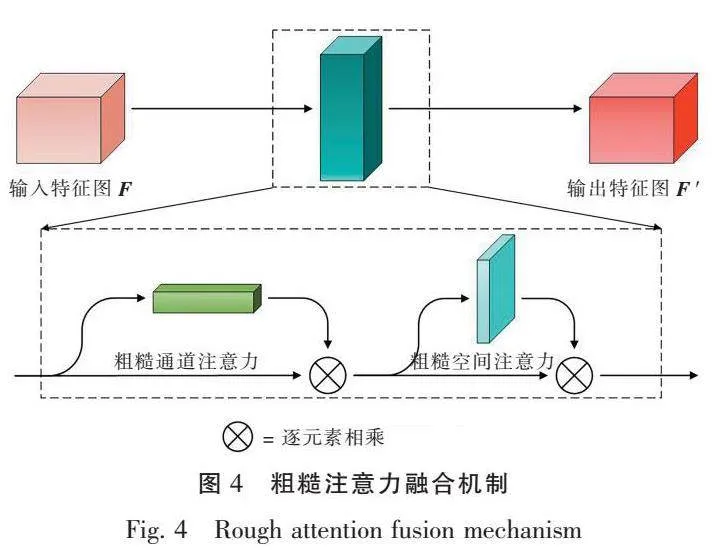
如图4所示,整个模块将空间注意力模块和通道注意力模块串行结合。空间注意力单元主要在不同图像区域之间建立长程相关性,使模型具有全局特征的学习能力;通道注意力单元主要对有效通道进行加权,对无用通道进行弱化,以提高模型的表达能力。经过粗糙化的空间注意力机制与通道注意力机制,对全局平均池化与全局最大池化得到的全局信息和局部信息粗糙化,对确定性的数值进行重标定,得到了更为合理且准确的空间与通道注意系数。融合模块表示为
F ′ = RSA(RCA(F)),(20)
其中:RCA表示粗糙通道注意力机制;RSA表示粗糙空间注意力机制。
通过结合Group Transformer与粗糙注意力融合机制,本文提出rough attention Group Transfomer网络(RAGT-Net)模型,网络结构如图5所示。该模型以GT U-Net为基础框架,将GT U-Net中收缩路径的特征图通过粗糙注意力融合模块后,再与扩展路径的特征图相拼接。在组合模型中引入粗糙注意力融合机制有利于提升图像边缘的权重,抑制不相关区域中的激活,进而减少冗余特征的数量,提升模型的分割效果。RAGT-Net模型的算法伪代码如表1所示。
3" "实验部分
3.1" "数据集
DRIVE数据集[26]是2004年发布的用于视网膜血管分割的数据集,它由40张彩色眼底图像组成,其中病理异常图像7张,每张图像分辨率为584 × 565,一般情况下,40张图像被平均分为20张训练集和20张测试集。
鉴于单通道灰度图像比RGB图像能更好地显示血管与背景之间的对比度,同时视网膜图像是小样本数据,本文对数据进行了预处理操作。首先,将RGB图像转换为灰度图像,并对视网膜血管灰度图像进行归一化;其次,采用对比度受限的自适应直方图均衡化,增强视网膜血管与背景之间的对比度,以使眼底图像中血管的结构和特征更易受到关注;最后,使用Gamma变换进行图像增强,对漂白或者过暗的图像区域进行校正。同时,采用对原图进行分块的方式进行数据扩充,将训练图像和相应的掩码图划分成大小为48 × 48的图像子块,从中随机选取一定数量的图像子块进行训练,部分的图像子块随机整合图像如图6所示。
3.2" "实验参数设置
本文的实验在Python 3.9,Pytorch 1.11.0和NVIDIA TITAN RTX GPU上完成。在模型的训练过程中,采用交叉熵损失函数作为训练的损失函数,批大小设置为64,模型迭代的次数设置为120,模型初始学习率设为0.000 5,选择Adam优化器对模型的参数进行更新。
3.3" "评价指标
视网膜血管分割任务就是将像素点分类为血管类或非血管类。血管类是分割的目标,叫做正类,其他部位是负类。通过对比分割算法的结果与真实值,可以得到混淆矩阵中的真阳性N,即正确预测血管类为血管类;假阳性N,即误判非血管类为血管类;真阴性N,即正确预测非血管类为非血管类;假阴性N,即误判血管类为非血管类。
为了评价视网膜血管分割算法的好坏,本文引入准确率Acc、灵敏度Sen、特异性Spe和F分数这4个评价指标,各评价指标公式分别表示为
Acc = ,(21)
Sen = ,(22)
Spe = ,(23)
F = 2 × 。(24)
同时,也引入ROC与PR的曲线面积评价模型,ROC曲线综合考虑了敏感度和精确性,PR曲线综合考虑了召回率和精确率,ROC与PR的曲线面积越大,表明模型具有更好的性能。
3.4" "实验结果分析
表2是本文提出的视网膜血管分割网络和其他5种当前流行的方法在DRIVE数据集上的分割性能对比。由表2可知,本文提出的RAGT-Net模型在准确率、灵敏度、特异性及F分数指标上都表现出良好的分割结果。与其他分割网络对比,准确率提升了0.52%~0.98%,灵敏度提升了4.85%~11.46%,F分数提升了2.18%~5.20%。
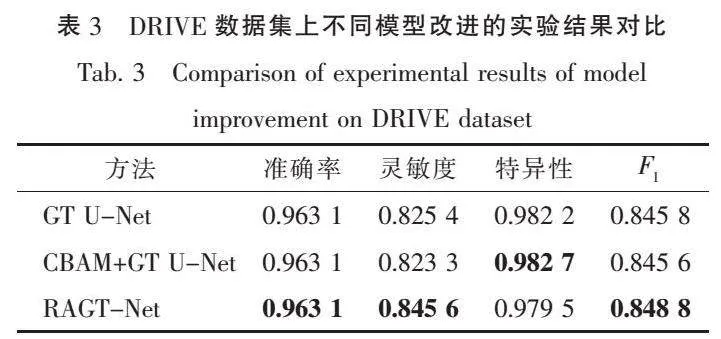
同时,为验证本文提出的粗糙注意力融合机制的有效性,将RAGT-Net与GT U-Net、CBAM[23] + GT U-Net网络在DRIVE数据集上的分割性能进行对比。如表3所示,RAGT-Net相比于GT U-Net,在总体性能上获得了提升,准确率保持不变,灵敏度、F分数分别提升了2.39%、0.35%;CBAM + GT U-Net相比于GT U-Net,在总体性能上无明显变化。
如图7与图8所示,RAGT-Net模型在DRIVE数据集上的ROC曲线面积,即AUC值为0.981 2,相比GT U-Net与CBAM + GT U-Net模型分别提升了0.28%和0.21%;RAGT-Net模型的PR曲线AUC值为0.924 8,相比于GT U-Net与CBAM + GT U-Net模型分别提升了0.32%和0.12%,证明了本文提出的粗糙注意力融合机制的有效性。
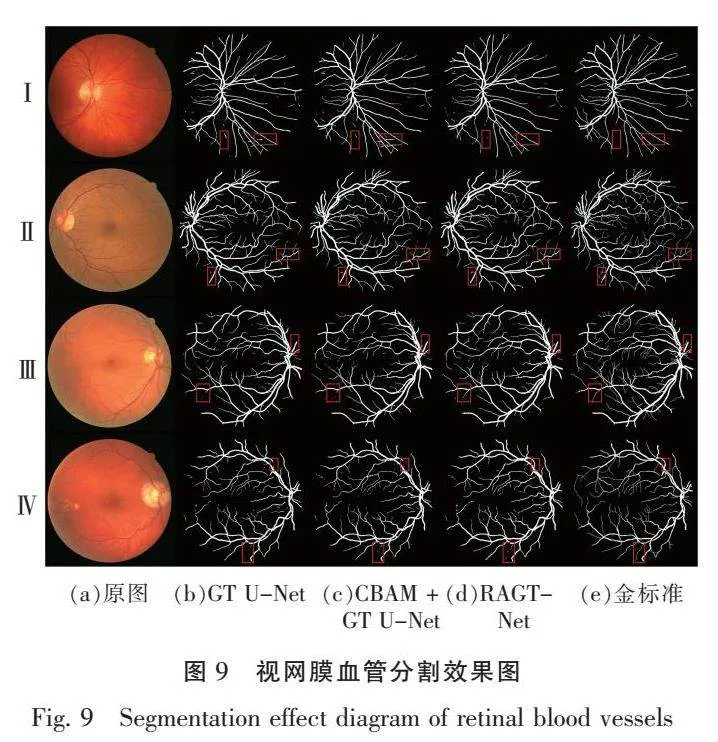
如图9所示,本文提出的RAGT-Net模型的分割结果和金标准基本一致,其在矩形区域内的细小血管分割上比GT U-Net和CBAM+GT U-Net两个模型效果更好。
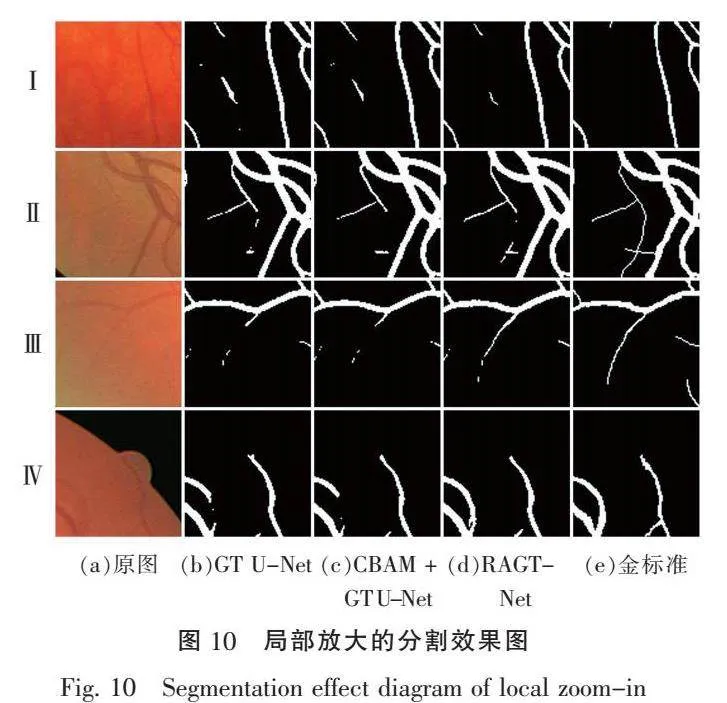
如图10所示,对图9中部分矩形区域内的分割结果进行局部放大。可以更加直观地看出,在第Ⅰ行的效果对比中,RAGT-Net模型处理背景噪声的干扰拥有更好的效果,误检率更低;在第Ⅱ行、第Ⅲ行及第Ⅳ行的效果对比中,RAGT-Net模型在矩形区域内对细小血管的分割更加精细、漏检率更低。
为了展示本文模型对于存在病灶的眼底图像的分割效果,图9中第Ⅳ行的选用的眼底图像存在视网膜病变现象,如色素上皮变化、中央凹色素型瘢痕等。如图11所示,对图9中第Ⅳ行的眼底图像的病灶区域进行局部放大,可以直观地看出,本文提出的模型能够精确地检测血管,但是在病变严重的视网膜上,分割结果会受其影响。
综上所述,本文提出的视网膜血管分割方法与U-Net、R2U-Net等主流方法相比,具有更好的分割效果。同时,本文提出的粗糙注意力融合机制有效提升了GT U-Net网络对视网膜血管的分割精度。其主要原因在于,RAGT-Net选用GT U-Net为基础框架,在减少Transformer计算量的同时使用卷积弥补了Transformer缺少局部性和全局不变性的劣势。同时,RAGT-Net合理使用粗糙集上下限的概念,合理融合全局最大池化与全局平均池化得到的局部信息和全局信息,通过加权操作,得到更合理的通道与空间注意力系数,并串行融合了通道注意力与空间注意力。
4" "结论
本文提出了一种基于粗糙注意力融合机制和Group Transformer的视网膜血管分割网络。由于视网膜血管的结构复杂且边界模糊,因此,我们在编码器中添加粗糙注意力融合机制,并串行连接粗糙通道注意力和粗糙空间注意力,以此提升图像边缘的权重,抑制不相关区域中的激活。同时,本文选用GT U-Net为基础框架,该网络在融合卷积和Transformer的优势基础上,减少了Transformer计算量。从评价指标上看,本文方法与目前流行的方法相比,整体上取得了更精确的分割性能,同时通过与GT U-Net的对比,证明了所提出的粗糙注意力融合机制的有效性;从可视化结果上看,本文方法的分割结果也更加完整。今后,我们会进一步研究将Transformer轻量化的方法,以及将粗糙集相关理论与神经网络相结合,来处理图像特征中不确定性信息。
参考文献:
[ 1 ] 梅旭璋, 江红, 孙军. 基于密集注意力网络的视网膜血管图像分割[J]. 计算机工程, 2020, 46(3):267-272.
MEI X Z, JIANG H, SUN J. Retinal vessel image segmentation based on dense attention network[J]. Computer Engineering, 2020, 46(3):267-272. (in Chinese)
[ 2 ] JIN Q G, MENG Z P, PHAM T D, et al. DUNet:a deformable network for retinal vessel segmentation[J]. Knowledge-Based Systems, 2019, 178:149-162.
[ 3 ] LI X, JIANG Y C, LI M L, et al. Lightweight attention convolutional neural network for retinal vessel image segmentation[J]. IEEE Transactions on Industrial Informatics, 2021, 17(3):1958-1967.
[ 4 ] 蒋芸, 刘文欢, 梁菁. 联合注意力和Transformer的视网膜血管分割网络[J]. 计算机工程与科学, 2022, 44(11):2037-2047.
JIANG Y, LIU W H, LIANG J. Retinal vessel segmentation network with joint attention and Transformer[J]. Computer Engineering amp; Science, 2022, 44(11):2037-2047. (in Chinese)
[ 5 ] RONNEBERGER O, FISCHER P, BROX T. U-net:convolutional networks for biomedical image segmentation[C]//Proceedings of the 18th International Conference on Medical Image Computing and Computer-Assisted Intervention, October 5-9, 2015, Munich, Germany. Cham:Springer, 2015:234-241.
[ 6 ] XIAO X, LIAN S, LUO Z M, et al. Weighted res-U Net for high-quality retina vessel segmentation[C]//Proceedings of the 2018 9th International Conference on Information Technology in Medicine and Education (ITME), October 19-21, 2018, Hangzhou, China. New York:IEEE Xplore, 2018:327-331.
[ 7 ] 吴晨玥, 易本顺, 章云港, 等. 基于改进卷积神经网络的视网膜血管图像分割[J]. 光学学报, 2018, 38(11):1111004.
WU C Y, YI B S, ZHANG Y G, et al. Retinal vessel image segmentation based on improved convolutional neural network[J]. Acta Optica Sinica, 2018, 38(11):1111004. (in Chinese)
[ 8 ] VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[EB/OL]. (2017-12-06)[2023-02-21]. https://arxiv. org/abs/1706. 03762v4.
[ 9 ] 傅励瑶, 尹梦晓, 杨锋. 基于Transformer的U型医学图像分割网络综述[J/OL]. (2022-07-12)[2023-02-21]. https://kns.cnki.net/kcms/detail/51.1307.TP.20220711.1509. 012.html.DOI:10.11772/j.issn.1001-9081.202204 0530.
[10] DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16 × 16 words:Transformers for image recognition at scale[EB/OL]. (2021-06-03)[2023-02-21]. https://arxiv.org/abs/2010.11929.
[11] ZHANG Y D, LIU H Y, HU Q. TransFuse:fusing transformers and CNNs for medical image segmentation[C]// Proceedings of the 24th International Conference on Medical Image Computing and Computer-Assisted Intervention, September 27-October 1, 2021, Strasbourg, France. Cham:Springer, 2021:14-24.
[12] CHEN J N, LU Y Y, YU Q H, et al. TransUNet:Transformers make strong encoders for medical image segmentation[EB/OL]. (2021-02-08)[2023-02-21]. https://arxiv.org/abs/2102.04306.
[13] OKTAY O, SCHLEMPER J, LE FOLGOC L, et al. Attention U-net:learning where to look for the pancreas[EB/OL]. (2018-05-20)[2023-02-21]. https://arxiv.org/abs/1804. 03999.
[14] GU R, WANG G T, SONG T, et al. CA-net:comprehensive attention convolutional neural networks for explainable medical image segmentation[J]. IEEE Transactions on Medical Imaging, 2021, 40(2):699-711.
[15] YUAN Y C, ZHANG L, WANG L T, et al. Multi-level attention network for retinal vessel segmentation[J]. IEEE Journal of Biomedical and Health Informatics, 2022, 26(1):312-323.
[16] LI Y X, WANG S, WANG J, et al. GT U-net:a U-net like group transformer network for tooth root segmentation[C]//Proceedings of the 12th International Workshop on Machine Learning in Medical Imaging, MLMI 2021, September 27, 2021, Strasbourg, France. Cham:Springer, 2021:386-395.
[17] 王国胤, 姚一豫, 于洪. 粗糙集理论与应用研究综述[J]. 计算机学报, 2009, 32(7):1229-1246.
WANG G Y, YAO Y Y, YU H. A survey on rough set theory and applications[J]. Chinese Journal of Computers, 2009, 32(7):1229-1246. (in Chinese)
[18] PAWLAK Z. Rough sets[J]. International Journal of Computer amp; Information Sciences, 1982, 11(5):341-356.
[19] 胡可云, 陆玉昌, 石纯一. 粗糙集理论及其应用进展[J]. 清华大学学报(自然科学版), 2001, 41(1):64-68.
HU K Y, LU Y C, SHI C Y. Advances in rough set theory and its appliations[J]. Journal of Tsinghua University (Science and Technology), 2001, 41(1):64-68. (in Chinese)
[20] JIANG Z H, YU W H, ZHOU D Q, et al. ConvBERT:improving BERT with span-based dynamic convolution[EB/OL]. (2020-08-06)[2023-02-21]. https://arxiv.org/abs/2008. 02496.
[21] LIU Z, LIN Y T, CAO Y, et al. Swin Transformer:hierarchical Vision Transformer using Shifted Windows[C]//Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), October 10-17, 2021,Montreal, QC, Canada. New York:IEEE Xplore, 2021:9992-10002.
[22] HU J, SHEN L, ALBANIE S, et al. Squeeze-and-excitation networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020, 42(8):2011-2023.
[23] WOO S, PARK J, LEE J Y, et al. CBAM:convolutional block attention module[C]// Proceedings of the European Conference on Computer Vision, September 8-14, 2018, Munich, Germany. Cham:Springer, 2018:3-19.
[24] FU J, LIU J, TIAN H J, et al. Dual attention network for scene segmentation[C]//Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 15-20, 2019, Long Beach, CA, USA. New York:IEEE Xplore, 2019:3141-3149.
[25] MEI H, ZHANG H, JIANG Z. Self-attention fusion module for single remote sensing image super-resolution[C]// Proceedings of the 2021 IEEE International Geoscience and Remote Sensing Symposium IGARSS, July 11-16, Brussels, Belgium. New York:IEEE Xplore, 2021:2883-2886.
[26] STAAL J, ABR?魥MOFF M D, NIEMEIJER M, et al. Ridge-based vessel segmentation in color images of the retina[J]. IEEE Transactions on Medical Imaging, 2004, 23(4):501-509.
[27] ALOM M Z, HASAN M, YAKOPCIC C, et al. Recurrent residual convolutional neural network based on U-Net (R2U-Net) for medical image segmentation[EB/OL]. (2018-05-29)[2023-02-21]. https://arxiv.org/abs/1802.06955.
[28] AZAD R, ASADI-AGHBOLAGHI M, FATHY M, et al. Bi-directional ConvLSTM U-net with densley connected convolutions[C]//Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), October 27-28, 2019, Seoul, Korea (South). New York:IEEE Xplore, 2019:406-415.
[29] 孙颖, 丁卫平, 黄嘉爽, 等. RCAR-UNet:基于粗糙通道注意力机制的视网膜血管分割网络[J]. 计算机研究与发展, 2023, 60(4):947-961.
SUN Y, DING W P, HUANG J S, et al. RCAR-U Net: retinal vessels segmentation network based on rough channel attention mechanism[J]. Journal of Computer Research and Development, 2023, 64(4):947-961. (in Chinese)
(责任编辑:仇慧)
收稿日期: 2023-03-06 接受日期: 2023-04-13
基金项目: 国家自然科学基金面上项目(61976120);江苏省自然科学基金面上项目(BK20231337);江苏省高校重大自然科学基金项目(21KJA510004);江苏省研究生科研与实践创新计划项目(SJCX22_1615);国家级大学生创新创业训练计划项目(202210304030Z)
第一作者简介: 王海鹏(1999— ), 男, 硕士研究生。
* 通信联系人: 丁卫平(1979— ), 男, 教授, 博士, 博士生导师, 主要研究方向为数据挖掘、机器学习、粒计算、演化计算和大数据分析等。
E-mail:dwp9988@163.com
