基于LSTM?Attention神经网络的文本特征提取方法
2018-04-13赵勤鲁蔡晓东李波吕璐
赵勤鲁 蔡晓东 李波 吕璐
摘 要: 针对当前文本分类神经网络不能充分提取词语与词语和句子与句子之间的语义结构特征信息的问题,提出一种基于LSTM?Attention的神经网络实现文本特征提取的方法。首先,分别使用LSTM网络对文本的词语与词语和句子与句子的特征信息进行提取;其次,使用分层的注意力机制网络层分别对文本中重要的词语和句子进行选择;最后,将网络逐层提取得到的文本特征向量使用softmax分类器进行文本分类。实验结果表明,所提方法可以有效地提取文本的特征,使得准确率得到提高。将该方法应用在IMDB,yelp2013和yelp2014数据集上进行实验,分别得到52.4%,66.0%和67.6%的正确率。
关键词: LSTM?Attention; 注意力机制; 文本分类; 神经网络; 文本特征提取; softmax
中圖分类号: TN711?34; TP391.41 文献标识码: A 文章编号: 1004?373X(2018)08?0167?04
Abstract: In allusion to the problem that the current text classification neural network cannot fully extract semantic structural feature information among words or sentences, a text feature extraction method based on long short?term memory?attention (LSTM?Attention) neural network implementation is proposed. LSTM network is used to extract feature information among words or sentences of text. Network layer of hierarchical attention mechanism is used to select important words and sentences in text. Text classification is performed for the text feature vectors obtained from each network extraction by using softmax classifier. The experimental results show that the proposed method can effectively extract text features to improve the accuracy rate. When applying the method to the datasets of IMDB, yelp2013 and yelp2014 in the experiment, the correctness rates of 52.4%, 66.0% and 67.6% are obtained respectively.
Keywords: LSTM?Attention; attention mechanism; text classification; neural network; text feature extraction; softmax
0 引 言
文本分类任务是自然语言处理的一项基本任务,其目的是让文本得到相应的类别标签。文献[1]采用的词袋模型向量实现对文本特征的提取。这种方法分类效果的好坏受文本提取的特征影响较大,在训练时容易造成维度灾难。文献[2]是构建有效的文本特征以及建立文本情感词典来得到文本的类别特征。这样的方式耗费大量的人力并且效率低。随着深度学习在自然语言处理领域的发展,文献[3]使用卷积神经网络对文本单词级别的信息进行分类工作,通过卷积神经网络不同尺寸的卷积核来得到文本的N元特征信息进行文本特征分类。文献[4]使用卷积神经网络在字符级别对文本进行分类工作。目前循环神经网络LSTM已经在自然语言处理任务中被广泛应用,文献[5]使用LSTM递归网络进行文本情感分类任务。但是这些网络都是将一个句子或者一个文本作为网络的输入,经过深度神经网络来提取文本的特征,进而将这些特征使用分类器分类。但是,这样的方法只是关注了整个文本中的信息,没有能够考虑到词语之间以及句子之间的局部信息,为了解决这个问题,文献[6]提出使用分层网络结构对文本的词语信息和句子信息分别进行提取学习。使用分层的CNN/LSTM以及GateNN网络分别对词语和句子之间的语义信息进行提取,实现对文本的分层次信息提取。近几年基于注意力机制的神经网络在自然语言处理各项任务中已经取得了很多重要的进展。文献[7]将注意力机制(Attention)首次引入到自然语言处理任务中,应用在seq2seq机器翻译任务上。文献[8]提出基于注意力机制的池化网络应用在问答系统中。本文提出一种Long Short?term Memory?Attention(LSTM?Attention)神经网络的文本特征提取方法,来实现对词语与词语和句子与句子之间的语义结构信息进行充分提取。
本文结合LSTM以及注意力机制提出LSTM?Attention神经网络,该网络不仅可以对文本分层次对词语与句子之间的特征分别提取,而且还可以实现对重要的词语和句子进行提取。将该网络应用到文本分类任务中,与不使用注意力机制的分层网络相比。最终本文方法可以提取到更有区分能力的文本特征。
1 LSTM?Attention神经网络
本文LSTM?Attention神经网络总共包含六部分:文本向量化层、词语信息特征提取层、词语Attention层、句子信息特征提取层、句子Attention层、文本分类层。网络模型整体框图如图1所示。

1.1 长短期记忆网络
长短期记忆网络(LSTM)是一种时间递归神经网络[9],该神经网络可以有效保留历史信息,实现对文本的长期依赖信息进行学习。LSTM网络由三个门(输入门、遗忘门和输出门)和一个cell单元来实现历史信息的更新和保留。
LSTM数据更新过程如下,在时刻t时,输入门会根据上一时刻LSTM单元的输出结果ht-1和当前时刻的输入xt作为输入,通过计算来决定是否将当前信息更新到LSTM?cell中,可以表述为:
1.2 文本向量化层
本文使用的训练文本d由n个句子组成即d={s1,s2,…,sn},每个句子由m个单词组成,则样本中的第i个句子si可以表示成si={wi1,wi2,…,wim}。本文使用的是word2vec中Skip?Gram无监督模型对语料进行向量化,得到词向量[w∈Rd],通过文本向量化层实现文本向量化。
1.3 词语信息特征提取层
对于一个句子,可以将句子看成是由词语组成的序列信息。首先通过LSTM网络对向量化的句子序列xi1,xi2,…,xit作为LSTM的输入节点数据,在t时刻输入到网络的句子根据t-1时刻的LSTM细胞状态ct-1和隐层状态ht-1进行更新得到hi。这里的xi1,xi2,…,xit是指句子中的每个词语,在不同的时刻LSTM会输出对应节点的隐层输出值hi1,hi2,…,hit。输出隐层信息[hit∈Rn_hidden],n_hidden是LSTM隐层神经单元个数。得到hit作为一个句子的特征向量,输入到下一网络层。通过这样的方式将句子序列的前后信息进行学习,得到句子词语之间的前后信息,对文本句子进行语义编码,可以描述为:
1.4 词语Attention层
在文本中,每一个词语对于文本类别的贡献度是不一样的,为了实现对重要词语的特征进行提取,增加这个层可以进一步地提取文本之间的更深层的信息,在此使用了注意力机制。首先将LSTM隐层的输出信息hit经过非线性变换得到其隐含表示uit,通过随机初始化注意力机制矩阵uw与uit进行点乘运算并对其使用softmax进行归一化操作,最终得到词级别LSTM隐层输出的权重系数,最终通过该方法得到词语注意力机制矩阵,可以描述为:
1.5 句子信息特征提取层
同样,可以把文本看成是由句子组成的序列信息。为了得到整个文本的语义关系特征,將上一网络层得到的句子向量si输入到LSTM网络,在t时刻输入到网络的句子根据t-1时刻的LSTM细胞状态ct-1和隐层状态ht-1进行更新得到hi。通过该网络层得到句子之间的语义关联信息,实现文本特征信息的提取,可以描述为:
1.6 句子Attention层
在一个文本中,不同句子对文本信息重要程度的贡献也是不同的。采用和词级别同样的方式进行对重要句子给予不同权重参数的操作,得到句子的注意力机制矩阵,具体描述为:
式中,us是随机初始化的句子注意力机制矩阵。
1.7 文本分类层
向量V是经过网络由词级别以及句子级别层提取出的文本特征向量。为了把文本的高维特征进行压缩到低维度,增强数据的非线性能力。在softmax分类层之前添加一个非线性层,将该向量映射为长度为c的向量,其中c是文本的类别数。最后经过softmax分类器计算对应类别的分布概率,描述为:
2 实 验
2.1 数据集和实验环境
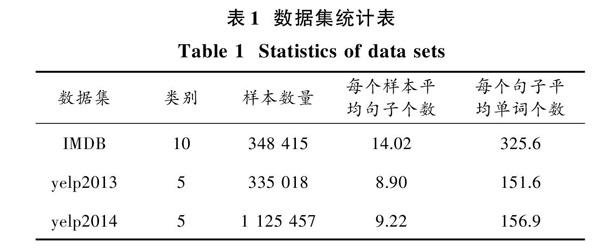
为了验证本文提出的模型的有效性,将此模型应用于IMDB,yelp2013和yelp2014数据集上。实验数据[6]统计如表1所示。本文词向量是使用word2vec[10]对语料产生200维度的词向量,所生成的词向量中包含的单词均在语料中出现三次以上,否则使用word2vec产生的均值向量进行文本向量化工作。本文实验平台的配置包括Intel i5?4460,4×3.2 GHz处理器、8 GB内存、GTX750Ti显卡以及 Ubuntu 14.04操作系统,并使用Theano深度学习开源框架。
2.2 实验设计
本文提出LSTM?Attention和LSTM?LSTM两种神经网络模型进行实验对比,具体模型描述如下:
LSTM?LSTM:LSTM?Attention神经网络是将文本进行向量化后分别使用LSTM网络对词语以及句子进行序列信息进行提取,并分别在词语级别和句子级别之后的LSTM网络后面加入注意力机制层,最终将得到的文本的特征向量送进softmax分类器进行分类器的训练。
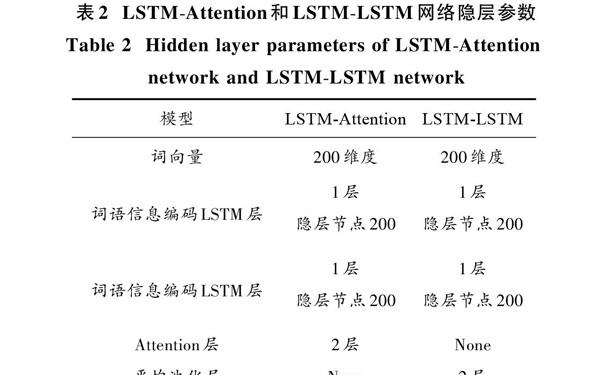
LSTM?LSTM神经网络:将文本进行向量化后分别使用LSTM网络对词语以及句子进行序列信息提取,并分别在词语级别和句子级别之后的LSTM网络后面加入平均池化层,最终将得到的文本特征向量送进softmax分类器进行分类器的训练。其具体网络隐层参数如表2所示。
2.3 实验分析
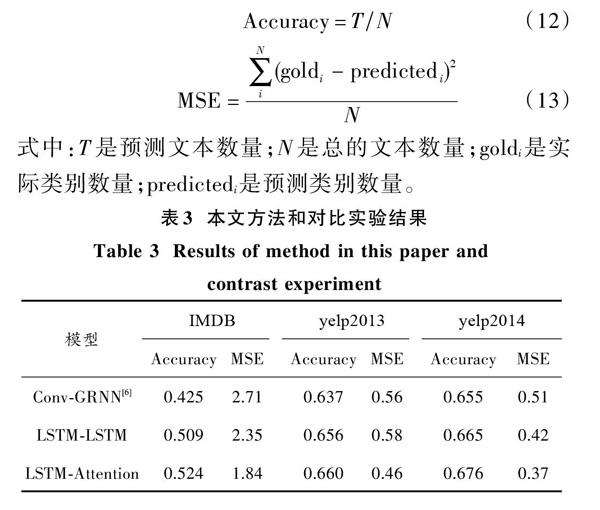
本文所提方法以及对比方法实验结果如表3所示。文献[6]中使用CNN对词语特征进行提取得到词语的N元特征信息。但是这种方法容易忽略词语之间的长期依赖信息。为了解决这个问题使用GRNN对句子特征进行提取从而实现文本特征的提取。本文提出的LSTM?LSTM神經网络,不仅可以对词语之间的长期依赖信息进行提取,而且还可以对句子与句子之间的信息进行特征提取。在IMDB,yelp2013和yelp2014数据集上分别取得了50.9%,65.6%和66.5%的正确率。本文提出的LSTM?Attention网络不仅可以实现对文本进行分层次特征学习提取,通过给予不同的权重参数使用注意力机制实现对文本中重要的词语和句子进行提取。使得网络可以实现对文本的信息给予不同的关注程度。本文所提方法和不使用注意力机制的LSTM?LSTM网络相比均有提高,这也说明了注意力机制的有效性。LSTM?Attention在IMDB,yelp2013和yelp2014数据集上分别取得了52.4%,66.0%和67.6%的正确率。
3 结 论
本文提出一种基于LSTM?Attention的神经网络实现文本特征提取的方法。首先,相比较于Conv?GRNN[6],本文方法LSTM?LSTM通过LSTM网络分别实现对词语之间以及句子之间的特征进行学习提取;其次,通过LSTM?Attention相比较于没有注意力机制的LATM?LSTM可以实现对贡献度不同的词语和句子进行提取;最后,在IMDB,yelp2013和yelp2014数据集上实验,结果证明,本文的方法可以提取出更具区分能力的文本特征,达到52.4%,66.0%和67.6%的正确率。
注:本文通讯作者为蔡晓东。
参考文献
[1] WAWRE S V, DESHMUKH S N. Sentiment classification using machine learning techniques [J]. International journal of science and research, 2016, 5(4): 819?821.
[2] DING X, LIU B, YU P S. A holistic lexicon?based approach to opinion mining [C]// Proceedings of the 2008 International Conference on Web Search and Data Mining. New York: Association for Computing Machinery, 2008: 231?240.
[3] KIM Y. Convolutional neural networks for sentence classification [J/OL]. [2014?09?03]. https://arxiv.org/pdf/1408.5882v2.pdf.
[4] ZHANG X, ZHAO J, LECUN Y. Character?level convolutional networks for text classification [J/OL]. [2017?07?09]. http://www.doc88.com/p?1582873490700.html.
[5] 梁军,柴玉梅,原慧斌,等.基于极性转移和LSTM递归网络的情感分析[J].中文信息学报,2015,29(5):152?159.
LIANG Jun, CHAI Yumei, YUAN Huibin, et al. Polarity shifting and LSTM based recursive networks for sentiment analysis [J]. Journal of Chinese information processing, 2015, 29(5): 152?159.
[6] TANG D, QIN B, LIU T. Document modeling with gated recurrent neural network for sentiment classification [C]// Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing. [S.l.: s.n.], 2015: 1422?1432.
[7] BAHDANAU D, CHO K, BENGIO Y. Neural machine translation by jointly learning to align and translate [J/OL]. [2014?10?11]. http: //nlp.ict.ac.cn/Admin/kindeditor/attached/file/20141011/20141011133445_31922.pdf.
[8] DOS?SANTOS C, TAN M, XIANG B, et al. Attentive pooling networks [J/OL]. [2016?02?11]. http://xueshu.baidu.com/s?wd=paperuri%3A%28f618ebd90de235437fd745ed36080e77%&;29
filter=sc_long_sign&;tn=SE_xueshusource_2kduw22v&;sc_vurl=http%3A%2F%2Farxiv.org%2Fabs%2F1602.03609&;ie=utf?8&;sc_us=17197570488667881682.
[9] HOCHREITER S, SCHMIDHUBER J. Long short?term memory [J]. Neural computation, 1997, 9(8): 1735?1780.
[10] MIKOLOV T, SUTSKEVER I, CHEN K, et al. Distributed representations of words and phrases and their compositionality [J/OL]. [2013?10?16]. https://arxiv.org/pdf/1310.4546v1.pdf.
