基于数据集扩充的即时软件缺陷预测方法
2024-12-09杨帆夏鸿崚

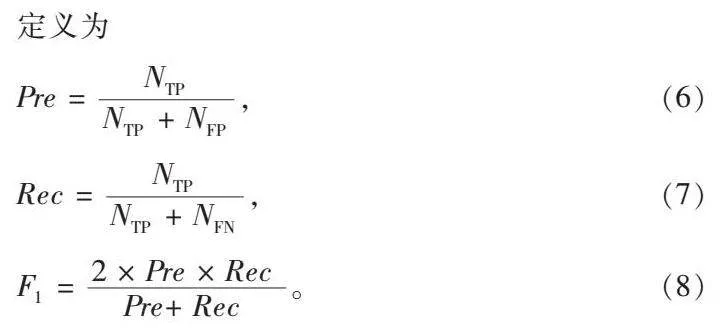








摘要:即时软件缺陷预测针对项目开发与维护过程中的代码提交来预测是否会引入缺陷。在即时软件缺陷预测研究领域,模型训练依赖于高质量的数据集,然而已有的即时软件缺陷预测方法尚未研究数据集扩充方法对即时软件缺陷预测的影响。为提高即时软件缺陷预测的性能,提出一种基于数据集扩充的即时软件缺陷预测(prediction based on data augmentation,PDA)方法。PDA方法包括特征拼接、样本生成、样本过滤和采样处理4个部分。增强后的数据集样本数量充足、样本质量高且消除了类不平衡问题。将提出的PDA方法与最新的即时软件缺陷预测方法(JIT-Fine)作对比,结果表明:在JIT-Defects4J数据集上,F指标提升了18.33%;在LLTC4J数据集上,F指标仍有3.67%的提升,验证了PDA的泛化能力。消融实验证明了所提方法的性能提升主要来源于数据集扩充和筛选机制。
关键词:数据增强;深度学习;即时软件缺陷预测;样本生成;类不平衡问题
中图分类号: TP311.5" " " " " " " nbsp; " " " " 文献标志码: A文章编号: 1673-2340(2024)01-0058-08
Abstract: Just-in-time (JIT) software defect prediction aims to predict whether code commits during project development and maintenance will introduce defects. In the field of JIT software defect prediction research, model training relies on high-quality datasets. However, the impact of dataset augmentation methods on JIT software defect prediction has not been thoroughly investigated in existing methods. To enhance the performance of JIT software defect prediction, a method based on dataset augmentation, named prediction based on data augmentation (PDA) is proposed. PDA includes four parts: feature stitching, sample generation, sample filtering, and sampling processing. The augmented dataset has an ample number of samples with high quality and eliminates the class imbalance problem. Comparing the proposed PDA method with the latest JIT software defect prediction method (JIT-Fine), results indicate: an 18.33% improvement in the F score on the JIT-Defects4J dataset; and a 3.67% improvement on the LLTC4J dataset, demonstrating PDA′s generalization ability. Ablation studies have confirmed that the performance improvement of the proposed PDA method mainly comes from dataset augmentation and filtering mechanisms.
Key words: data augmentation; deep learning; just-in-time defect prediction; sample generation; imbalanced datasets
软件开发中不可避免出现软件缺陷问题,其中大部分缺陷是由软件演化过程中提交的代码变更引起的。当含有缺陷的软件发布后,易给日常生活带来巨大的负面影响,造成严重的经济损失[1]。因此,在软件的开发和维护工作中,能够即时预测软件缺陷是必要的[2]。为了解决这个问题,研究者们深入研究了即时软件缺陷预测技术。即时软件缺陷预测(如LApredict、Deeper、DeepJIT、CC2Vec、JITLine和JIT-Fine等方法)针对项目代码每次提交的变更预测是否会引入缺陷,即提交变更级的软件缺陷预测[3]。与传统缺陷预测方法主要关注文件级预测粒度相比,针对代码提交的即时软件缺陷预测具有预测粒度更细和即时性更强的优点。即时软件缺陷预测的性能高度依赖用于训练的数据集质量和数量;然而现有的数据集常常面临数据量不足、数据样本类不平衡等问题,继而导致现有方法训练出的模型精确率和召回率不高。
为了缓解这个问题,本文将数据集扩充方法应用于即时软件缺陷预测领域,提出了一种适用于即时缺陷预测模型的数据集扩充(prediction based on data augmentation,PDA)方法,它包括特征组合、样本生成、样本过滤和采样处理4个部分。采用PDA方法得到的数据集具有数量足、质量高和没有类不平衡问题等特点,应用PDA后预测模型的精确率和召回率得到提升。
PDA方法首先提取出代码变更提交的专家特征和语义特征并将其拼接成特征向量;再使用随机替换来生成候选样本,使用相对熵和条件熵来筛选生成的候选样本,将筛选后的样本扩充到数据集中;最后对扩充后的数据集中的小类样本进行重复采样,大小类样本数量平衡后训练即时软件缺陷预测分类模型。
为评估PDA方法的有效性,本文首先在原始数据集JIT-Deffects4J[4]上进行实验并测试其性能,然后将训练好的模型应用于数据集LLTC4J,并测试其性能以检验其泛化性。在实验中,本文首先进行数据集扩充,然后在全连接层分类器上应用。实验结果表明,应用了PDA方法的即时缺陷预测模型在自动评估中相较于最新的6种基准模型具有更佳的性能。
1" "相关工作
1.1" "即时软件缺陷预测
即时软件缺陷预测任务旨在尽早地识别出软件缺陷以降低软件维护的成本。为此,Mockus等[5]首次在代码变更层次上进行缺陷预测;2013年,Kamei等[6]正式将这种缺陷预测技术命名为即时软件缺陷预测技术。近年来,研究者们在数据标注、特征提取、模型构建和模型评估等领域提出了大量有价值的理论和技术。Hoang等先后提出了DeepJIT[7]和CC2vec[8]两种使用深度学习提取语义特征的预测模型。随后,为了进一步提升即时缺陷预测的实用价值,在综合考虑成本和效益的基础上,Pornprasit等[9]提出了JITLine。Zeng等[10]对基于深度学习技术的即时软件缺陷预测方法进行了重新审视,并构建了一种基于简单逻辑回归技术的预测模型LApredict。Ni等[4]构建了JITFine模型进行统一的即时软件缺陷预测和定位。现有的即时软件缺陷预测方法直接使用真实项目的代码变更提交信息作为数据集,样本数量较少(27319),且其中91.46%的样本为不引入缺陷的提交信息。这使得现有预测方法在训练过程中更易受到无缺陷样本的影响而忽视有缺陷样本的影响。与之前的工作不同的是,PDA方法使用数据增强方法生成并筛选优质样本扩充数据集,使得样本总量扩充一倍,并且对小类样本重复采样以消除类不平衡问题对模型训练的影响。
1.2" "数据增强
根据候选样本生成的方式,数据增强方法可以分为基于语义和基于规则两种类型。其中,针对基于规则的数据增强方法,Wang等[11]利用同义词替换方法生成候选样本;Wei等[12]提出了EDA方法,该方法包括随机插入、随机替换和随机删除技术;Xie等[13]使用自动生成的错误词汇增加候选样本;Zhang等[14]提出基于插值的方法MIXUP,该方法通过插值两个或多个真实实例的输入和标签来生成候选样本。针对基于语义的数据增强方法,ahin等[15]利用依赖树技术对原有数据进行语义转换;Sennrich等[16]提出回译模型,回译技术通过将句子翻译成其他语言,再将其翻译回原语言来生成候选样本;由于NLP任务的输入具有离散性特点,Chen等[17]提出TMix方法,该方法通过在隐藏空间中插入文本来构建大量的候选样本。PDA方法选择使用针对即时软件缺陷预测改进后的数据增强方法扩充即时软件缺陷预测领域的现有数据集。由于差值方法会生成虚拟的数据信息、随机删除会丢失一部分原有的信息,可能会对即时缺陷预测的准确性产生影响,因此,PDA使用随机替换的方式生成新的样本。在特征向量中随机选取两列特征进行替换生成新的样本用于扩充数据集。
2" "PDA方法
本节主要介绍数据集扩充方法的设计及具体实现,PDA的整体框架如图1所示。本文的数据集扩充方法包括特征组合、样本生成、样本过滤和采样处理4个部分,接下来介绍数据集扩充方法PDA的具体实现细节。
2.1" "特征组合
为了从代码提交变更中挖掘更多的信息,PDA方法提取数据集中每个样本的专家特征和语义特征,并将它们在向量层次拼接[4,18],形成原始样本X。设数据集X中有n个样本,记为
X = {(x,y),(x,y),…,(x,y)},
其中:x为代码提交中特征的向量表示:y为该代码提交是否会引入缺陷的标签。
2.1.1" "专家特征
通过挖掘软件项目管理的版本控制系统和缺陷跟踪系统的信息,得到代码变更的专家特征数据集。首先提取出软件项目管理的版本控制系统中的历史代码变更,再对提取出的代码变更进行度量得到专家特征,形成专家特征数据集。涉及到的专家特征及其含义[4]如表1所示。
2.1.2" "语义特征
通过CodeBERT提取代码变更片段的代码中包含的语义特征,然后将这些语义特征作为代码变更片段的度量,形成语义特征数据集[4]。本文在添加行和删除行之前添加了其他两个令牌(即[ADD]和[DEL])来区分它们。然后,将提交消息、添加行、删除行标记为令牌序列,并将该序列输入CodeBERT模型,生成相应的嵌入向量,称为代码更改提交的语义向量。语义特征提取器的具体结构如图2所示。
专家特征是专家认为与即时缺陷引入判断有关的度量标准,较为主观,但是有明确的含义,具有良好的可解释性;语义特征是从代码变更提交信息中提取出的特征,较为客观,但是没有明确含义,不具备良好的可解释性。最新的研究表明,同时使用专家特征和语义特征比只使用专家特征或只使用语义特征的模型性能更好[4]。因此,PDA方法采用将专家特征和语义特征拼接后的特征向量作为原始样本。
2.2" "样本生成
为了降低训练集不足对模型评估的影响,PDA方法对数据集进行扩充处理,生成若干候选样本。现有的EDA[19]包含4个模块,即同义词替换、随机插入、随机替换和随机删除。本文使用针对即时软件缺陷预测改进后的EDA,而不是直接使用现有的EDA框架。针对即时软件缺陷预测任务,剔除了不适用于本任务的模块(随机插入、随机删除和同义词替换),因为以上模块会导致新增错误信息或丢失原本信息。PDA方法仅使用随机替换对现有特征信息互相替换来生成新的样本。在原始样本X中随机选择两个样本,交换样本向量中随机两个特征的对应取值,获得一个生成候选样本t。然后对生成的候选样本进行过滤,将过滤后保留的高多样性和高质量样本加入到数据集中。
2.3" "样本过滤
为了进一步评估并筛选出高质量的候选样本,PDA首先利用相对熵最大化评估样本的多样性;然后,利用条件熵最小化评估样本的质量[20];最后,在综合考虑样本多样性和质量的条件下筛选出高质量的候选样本。
考虑生成样本的多样性,对于候选样本应最大化,其损失函数为max L(ω,?准(t)),其中:?准:R → R为一个有限维的特征映射;ω∈R为可学习的参数;l为交叉熵损失函数;t为以随机替换为数据集扩充方法对样本进行扩充,以x为输入生成的第j个样本,x生成m个样本。此时候选样本损失函数为
L(ω) = ∑∑l(ω?准(t),y),(1)
该值由相对熵和信息熵组成,其中D为相对熵,H为信息熵,P为概率分布,整个公式可以展开为
L(ω) = ∑∑D(P(ω?准(t)),P(y)) +
H(P(y))。(2)
考虑样本质量时,应该将条件熵函数最小化,以此约束生成的样本与原样本的语义偏差,可以表示为minH(P(ω ?准(t))P(ω?准(x))),由相对熵得到多样性分数
S = D(P(ω?准(t)),P(y)),(3)
由条件熵得到样本质量分数
S = -H(P(ω?准(t))P(ω?准(x))),(4)
因为是条件熵最小化,所以取负值。此时,当样本质量越高时,样本质量分数越高。
由多样性分数和样本质量分数相加得到每个新生成样本的最终得分为
S = S + S,(5)
按最终得分排序得前m个样本即为筛选后的增强样本,注意m的取值通常与原数据集中的样本数量保持一致,即使数据量规模提升一倍[12]。样本过滤的方法示意图如图3所示,其中相对熵负责筛选生成样本的多样性,条件熵负责筛选生成样本的样本质量。
2.4" "采样处理
为了确保最终的训练集正负均衡且尽可能多地保留样本中的信息,本文将过滤后的候选样本与原始样本合并,之后进行重复采样的过采样处理[3],即通过增加少数类样本的采样次数以达到数据集中类的比例平衡。其中小类含有缺陷的样本数量为2 333例,重复采集使其成为和无缺陷的大类数量一样,即为24 986例。大小类样本数量平衡后训练即时软件缺陷预测分类模型。
2.5" "方法应用
为了验证本文数据集扩充方法PDA的有效性,本文将其应用于全连接层分类器上。在训练开始前增加PDA预处理任务,将PDA处理后的数据集输入全连接层分类模型,并得到最终的分类结果。
3" "实验分析
3.1" "实验对象和基准方法
为了验证PDA的有效性,本文选择数据集JIT-Defects4J[4],选取了6种最先进的方法作为基准模型并复用了它们的代码(LApredict、Deeper、DeepJIT、CC2Vec、JITLine和JITFine)。其中,LApredict[8]利用传统逻辑回归分类器来构建缺陷预测模型;Deeper[3]使用深度信念网络来构建缺陷预测模型;DeepJIT[5]使用卷积神经网络来构建缺陷预测模型;CC2Vec[6]使用层级注意力网络来构建缺陷预测模型;JITLine[7]是一种考虑代码标记特征的预测方法;JITFine[4]是一种同时考虑了专家特征与深度语义特征的预测方法。初始的JIT-Defects4J数据集来源为真实项目,有91.46%的样本为无缺陷的样本,8.54%的样本为引入缺陷的代码变更,这表明数据集内部存在严重的类不平衡问题。
LLTC4J数据集是传统的用于即时软件缺陷预测的数据集。本文将在JIT-Defects4J上训练得到的模型,应用于LLTC4J数据集上测试性能,以研究各模型跨项目的泛化性。
3.2" "评价指标
为了评估该模型的有效性,本文采用了两种广泛使用的性能评价指标:非代价感知的指标和代价感知的指标。
3.2.1" "非代价感知指标
非代价感知的指标在不考虑成本的情况下评估预测模型的性能,适用于软件质量保障团队有充足资源的情况下,通常采用F和AUC值作为评价指标。
为了评估本文数据集扩充方法对模型预测性能的提升,本文使用F作为评价指标,它表示精确率Pre和召回率Rec的调和平均数。在数据集中,一个提交有4种可能的预测结果:当一个提交是真正引入缺陷的,并且预测为引入缺陷的(真阳性,TP);当一个提交没有引入缺陷,但预测为引入缺陷的(假阳性,FP);当一个提交是引入缺陷的,但是预测为没有引入缺陷的(假阴性,FN);提交被预测为没有引入缺陷的,并且它是真正没有引入缺陷的(真阴性,TN)。根据这4个可能的结果,F分数可以定义为
Pre = ,(6)
Rec = ,(7)
F = 。(8)
AUC表示受试者工作特征(ROC)曲线[9]下的面积,是y轴上的真阳性率(R)与x轴上的假阳性率(R)的二维说明。ROC曲线是通过改变所有可能值的分类阈值生成的,这可以分离干净有问题的预测。AUC值在0~1之间,一个很好的预测模型可以得到接近于1的AUC值。ROC曲线分析是稳健的,特别是对于不平衡的类分布和不对称的误分类代价。它还表示了模型对随机选择的缺陷实例的排名高于随机选择的干净实例的概率。
3.2.2" "代价感知指标
代价感知的性能指标通过考虑给定的成本阈值来评估预测模型的性能,例如,需要检查一定数量的代码行。这种类型的性能指标非常重要,特别是当软件质量保障团队的资源有限时。开发人员希望在指定的审查代码比例内尽可能多地检测出内在缺陷数。与之前的工作类似,本文使用总代码行的20%作为检查工作的代表。
1)R@20%E为测量根据给定的检查工作发现的实际引入缺陷的提交数量与提交总数之间的比例。在本文中,使用代码行(LOC)作为检查工作的代表,即整个项目20%的LOC。R@20%E较高意味着更多的实际缺陷引入提交被排在要检查的列表的顶部。因此,开发人员会用更少的努力发现更多的实际缺陷引入提交。
2)E@20%R为度量开发人员在检测出数据集中实际引入缺陷提交的20%时所花费的工作量。E@20%R值较低意味着开发人员用更少的代价发现20%的实际引入缺陷的提交。
3)Popt基于Alberg图的概念,表示模型召回率与模型检查代码量之间的关系。为了计算这个指标,需要用到两个预测模型:最优模型(Optimal)和最差模型(Worst)。在最优模型和最差模型中,提交分别按缺陷密度的递减和递增排序。一个好的预测模型比随机模型表现更好,近似于最优模型。对于给定的预测模型M,Popt可以由
Popt(M) = 1 - (9)
计算得到,其中Area(M)表示模型M对应的曲线下面积。
3.3" "实验设计
本文选择数据集JIT-Defects4J[4]作为实验对象,它是最新的大规模行级别数据集。首先,对JIT-Defects4J数据集进行特征提取并组合;然后,使用随机替换生成候选样本;再使用相对熵最大化和条件熵最小化筛选出高质量的候选样本;最后,进行过采样处理,解决样本内的类不平衡问题。在实验对象的选取上,本文首先在最新的JIT-Defects4J数据集上进行实验,比较PDA方法与现有模型的性能;然后,比较各模型在LLTC4J数据集上的性能。JIT-Defects4J数据集是数据筛选过的数据集且数据量较小;LLTC4J数据集未经过数据筛选,更贴近实际情况且数据量更大,在LLTC4J上进行实验以验证经数据集扩充后的模型泛化性是否比现有模型更好。该项工作设置了如下3个研究问题:
RQ1: PDA方法的性能如何?
RQ2: 进行消融实验,依次去除采样方法、多特征、数据集扩充框架测试方法性能,研究对提升性能影响最大的因素是什么?
RQ3:该方法模型是经JIT-Defects4J数据集训练得到的,在LLTC4J数据集上性能效果如何?与现有模型相比是否更有泛化性?
3.4" "实验结果分析
1)RQ1:PDA方法的性能如何?
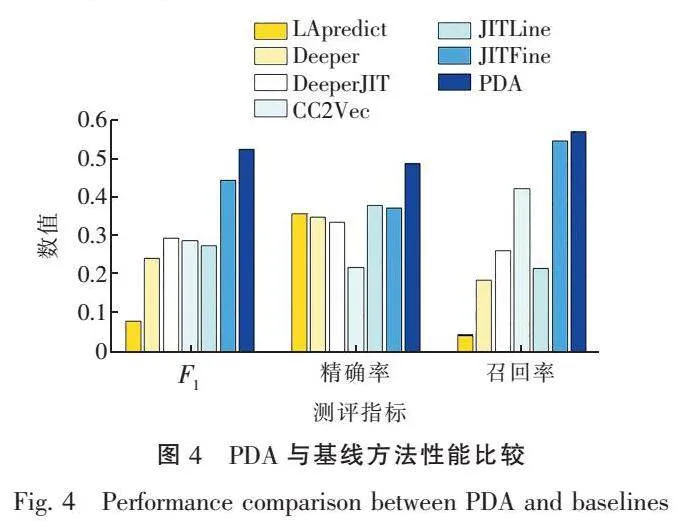
针对RQ1,本文选取6种最新的即时软件缺陷预测方法作为基线方法,实验结果如表2所示,PDA方法在F指标上较其他最新的预测方法提升了18.33%。各方法的精确率和召回率如图4所示。使用PDA方法对数据集扩充之后,丰富了样本多样性,模型减少了对无缺陷样本的过拟合程度,对有缺陷样本的预测精确率提高了30.38%,从而提升了模型性能。该结果表明,F的提升主要由精确率的提升提供。
2)RQ2:进行消融实验,依次去除采样方法、多特征、数据集扩充框架测试方法性能,研究对提升性能影响最大的因素是什么?
针对RQ2,本文设计了消融实验依次去除采样方法、多特征、数据集扩充框架测试方法性能,消融实验的结果如表3所示。在消融实验中,去除采样方法会使F指标下降2.29%;去除数据集扩充和筛选会使F指标下降13.96%;去除语义特征会使F指标下降3.06%;去除专家特征会使F指标下降0.96%。结果表明,性能提升主要是由数据集扩充和筛选提供的,这也证明了PDA方法的有效性。
3)RQ3:该方法模型是在JIT-Defects4J数据集训练得到的,在LLTC4J数据集上性能效果如何?与现有模型相比是否更有泛化性?
针对RQ3,本文在数据规模更大的LLTC4J数据集上进行实验以验证PDA方法的泛化性,具体性能对比见表4。在LLTC4J数据集上PDA方法仍然具有最好的性能,在F上比其他方法高3.67%~642.11%;在AUC上比其他方法高6.35%~21.68%;在R@20%E上比其他方法高2.45%~23.68%;在E@20%R上比其他方法减少6.67%~56.25%;在Popt上比其他方法高2.98%~14.91%。该结果表明PDA方法比其他方法具有更好的泛化性。
4" "结论
本文将数据集扩充方法应用于即时软件缺陷预测领域,提出PDA方法,通过特征组合、样本生成、样本筛选和采样方法解决现有数据存在样本数量少、严重类不平衡的问题,与最新的即时软件缺陷预测方法相比,PDA方法在各项指标上均有提升,特别是在F指标上相对提升了18.33%。实验结果证明了PDA方法的有效性且与其他方法相比有更好的泛化性。在后续研究工作中,建议探索可用于即时软件缺陷预测领域的更为高效的数据集扩充方法。
参考文献:
[ 1 ] WEN M, WU R X, LIU Y P, et al. Exploring and exploiting the correlations between bug-inducing and bug-fixing commits[C]//Proceedings of the 2019 27th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering, August 26-30, 2019, Tallinn, Estonia. New York:ACM, 2019:326-337.
[ 2 ] 陈翔, 顾庆, 刘望舒, 等. 静态软件缺陷预测方法研究[J]. 软件学报, 2016, 27(1):1-25.
CHEN X, GU Q, LIU W S, et al. Survey of static software defect prediction[J]. Journal of Software, 2016, 27(1):1-25. (in Chinese)
[ 3 ] ZHAO Y H, DAMEVSKI K, CHEN H. A systematic survey of just-in-time software defect prediction[J]. ACM Computing Surveys, 2023, 55(10):201.
[ 4 ] NI C, WANG W, YANG K W, et al. The best of both worlds:integrating semantic features with expert features for defect prediction and localization[C]// Proceedings of the 30th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering, November 14-18, 2022, Singapore, Singapore. New York:ACM, 2022:672-683.
[ 5 ] MOCKUS A, WEISS D M. Predicting risk of software changes[J]. Bell Labs Technical Journal, 2000, 5(2):169-180.
[ 6 ] KAMEI Y, SHIHAB E, ADAMS B, et al. A large-scale empirical study of just-in-time quality assurance[J]. IEEE Transactions on Software Engineering, 2013, 39(6):757-773.
[ 7 ] HOANG T, DAM H K, KAMEI Y, et al. DeepJIT:an end-to-end deep learning framework for just-in-time defect prediction[C]//Proceedings of the 2019 IEEE/ACM 16th International Conference on Mining Software Repositories (MSR), 2019, May 25-31, Montreal, QC, Canada. New York:IEEE Xplore, 2019:34-45.
[ 8 ] HOANG T, KANG H J, LO D, et al. CC2Vec:distributed representations of code changes[C]// Proceedings of the 2020 IEEE/ACM 42nd International Conference on Software Engineering (ICSE), October 05-11, 2020, Seoul, Korea (South). New York:IEEE Xplore, 2020:518-529.
[ 9 ] PORNPRASIT C, TANTITHAMTHAVORN C K. JITLine:a simpler, better, faster, finer-grained just-in-time defect prediction[C]//Proceedings of the 2021 IEEE/ACM 18th International Conference on Mining Software Repositories (MSR), May 17-19, 2021, Madrid, Spain. New York:IEEE Xplore, 2021:369-379.
[10] ZENG Z R, ZHANG Y Q, ZHANG H T, et al. Deep just-in-time defect prediction:how far are we? [C]//Proceedings of the 30th ACM SIGSOFT International Symposium on Software Testing and Analysis, July 11-17, 2021, Virtual, Denmark. New York:ACM, 2021:427-438.
[11] WANG W Y, YANG D Y. That′s so annoying!!!:a lexical and frame-semantic embedding based data augmentation approach to automatic categorization of annoying behaviors using #petpeeve tweets[C]//Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal. Stroudsburg, PA, USA:Association for Computational Linguistics, 2015:2557-2563.
[12] WEI J, ZOU K. EDA:easy data augmentation techniques for boosting performance on text classification tasks[C]//Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China. Stroudsburg, PA, USA:Association for Computational Linguistics, 2019:6381-6387.
[13] XIE Z A, WANG S I, LI J W, et al. Data noising as smoothing in neural network language models[EB/OL]. (2017-03-07)[2023-11-06]. https://arxiv.org/abs/1703. 02573.
[14] ZHANG H Y, CISSE M, DAUPHIN Y N, et al. Mixup:beyond empirical risk minimization[EB/OL]. (2018-10-25)[2023-11-06]. https://arxiv.org/abs/1710.09412.
[15] AHIN G G, STEEDMAN M. Data augmentation via dependency tree morphing for low-resource languages[C]//Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium. Stroudsburg, PA, USA:Association for Computational Linguistics, 2018:5004-5009.
[16] SENNRICH R, HADDOW B, BIRCH A. Improving neural machine translation models with monolingual data[C]//Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1:Long Papers), Berlin, Germany. Stroudsburg, PA, USA:Association for Computational Linguistics, 2016:86-96.
[17] CHEN J A, YANG Z C, YANG D Y. MixText:linguistically-informed interpolation of hidden space for semi-supervised text classification[C]//Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online. Stroudsburg, PA, USA:Association for Computational Linguistics, 2020:2147-2157.
[18] CHEN X, ZHANG D, ZHAO Y Q, et al. Software defect number prediction:unsupervised vs supervised methods[J]. Information and Software Technology, 2019, 106:161-181.
[19] ZHAO M Y, ZHANG L, XU Y, et al. EPiDA:an easy plug-in data augmentation framework for high performance text classification[C]// Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics:Human Language Technologies, Seattle, USA. Stroudsburg, PA, USA:Association for Computational Linguistics, 2022:4742-4752.
[20] 李冉, 周丽娟, 王华. 面向类不平衡数据集的软件缺陷预测模型[J]. 计算机应用研究, 2018, 35(9):2806-2810.
LI R, ZHOU L J, WANG H. Software defect prediction model based on class imbalanced datasets[J]. Application Research of Computers, 2018, 35(9):2806-2810. (in Chinese)
(责任编辑:仇慧)
收稿日期: 2023-12-06 接受日期: 2024-01-02
基金项目: 南通市科技计划面上项目(JC2023070)
第一作者简介: 杨帆(1980— ), 男, 工程师, 主要研究方向为软件工程和网络信息安全。E-mail:yangfan@jcet.edu.cn
