基于多模态特征频域融合的零样本指称图像分割
2024-06-01林浩然刘春黔薛榕融谢勋伟雷印杰
林浩然 刘春黔 薛榕融 谢勋伟 雷印杰

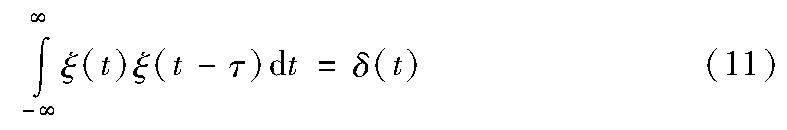

摘 要:為了解决语义分割应用到现实世界的下游任务时无法处理未定义类别的问题,提出了指称图像分割任务。该任务根据自然语言文本的描述找到图像中对应的目标。现有方法大多使用一个跨模态解码器来融合从视觉编码器和语言编码器中独立提取的特征,但是这种方法无法有效利用图像的边缘特征且训练复杂。CLIP(contrastive language-image pre-training)是一个强大的预训练视觉语言跨模态模型,能够有效提取图像与文本特征,因此提出一种在频域融合CLIP编码后的多模态特征方法。首先,使用无监督模型对图像进行粗粒度分割,并提取自然语言文本中的名词用于后续任务;接着利用CLIP的图像编码器与文本编码器分别对图像与文本进行编码;然后使用小波变换分解图像与文本特征,可以充分利用图像的边缘特征与图像内的位置信息在频域进行分解并融合,并在频域分别对图像特征与文本特征进行融合,并将融合后的特征进行反变换;最后将文本特征与图像特征进行逐像素匹配,得到分割结果,并在常用的数据集上进行了测试。实验结果证明,网络在无训练零样本的条件下取得了良好的效果,并且具有较好的鲁棒性与泛化能力。
关键词:指称图像分割; CLIP; 小波变换; 零样本
中图分类号:TP391 文献标志码:A 文章编号:1001-3695(2024)05-040-1562-07
doi:10.19734/j.issn.1001-3695.2023.08.0387
Zero-shot referring image segmentation based onmultimodal feature frequency domain fusion
Abstract:In order to solve the problem that semantic segmentation cannot handle undefined categories when applied to downstream tasks in the real world, it proposed referring image segmentation to find the corresponding target in the image according to the description of natural language text. Most of the existing methods use a cross-modal decoder to fuse the features extracted independently from the visual encoder and language encoder, but these methods cannot effectively utilize the edge features of the image and are complicated to train. CLIP is a powerful pre-trained visual language cross-modal model that can effectively extract image and text features. Therefore, this paper proposed a method of multimodal feature fusion in the frequency domain after CLIP encoding. Firstly, it used an unsupervised model to segment images, and extracted nouns in natural language text for follow-up task. Then it used the image encoder and text encoder of CLIP to encode the image and text respectively. Then it used the wavelet transform to decompose the image and text features,and decomposed and fused in the frequency domain which could make full use of the edge features of the image and the position information in the image, fused the image feature and text feature respectively in the frequency domain, then inversed the fused features. Finally, it matched the text features and image features pixel by pixel, and obtained the segmentation results, and tested on commonly used data sets. The experimental results prove that the network has achieved good results without training zero samples, and has good robustness and generalization ability.
Key words:referring image segmentation; CLIP; wavelet transform; zero-shot
0 引言
语义分割(semantic segmentation)是计算机视觉中的基本任务,是按照“语义”给图像上目标类别中的每一点打一个标签,使得不同种类的东西在图像上被区分开来,需要将视觉输入分为不同的语义可解释类别。语义分割可以用于医学图像中检测疾病和身体损伤,也可以用于检测城市街景。语义分割技术还可以帮助自动驾驶汽车提高对道路上物体的识别能力,从而更好地保障行车安全。
近年来,以深度学习为中心的机器学习技术引起了人们的关注。比如汽车自动驾驶已经逐渐成为可能,但在整个深度学习过程,需要算法识别原始数据提供的图像,在这一过程中,就需要用到语义分割技术。
现有的语义分割网络能够在测试集上有效实现分割的功能,但是现有网络在应用到现实世界的下游任務时存在很多局限性,现实世界中存在着大量训练时未见过的类别,这些网络无法处理未定义的类别,因此实现这些未定义类别的分割具有挑战性,进而提出了指称图像分割(referring image segmentation,RIF)[1]。这个任务能够在给定描述区域的自然语言文本的条件下在图像中找到与自然语言文本匹配的特定区域,其目标是对自然语言表达所描述的物体进行分割。通过一段自然语言表述(query)在图像中分割出对应实例,在人机交互、照片编辑等场景有着广泛应用。
解决指称图像分割问题的一个常用方法是利用一个强大的视觉语言(“跨模态”)解码器来融合从视觉编码器和语言编码器中独立提取的特征。最近方法利用Transformer[2]作为跨模态解码器在多种视觉语言任务中获得了显著的成功。CLIP(contrastive language-image pre-training)[3]是一个对比语言-图像预训练模型,具有强大的跨模态编码能力,是一种可以同时处理文本和图像的预训练模型。CLIP的核心思想是学习图像和文本之间的匹配关系来提高模型的性能。CLIP基于多模态对比学习,与计算机视觉中常用的一些对比学习方法如MoCo[4]和SimCLR[5]不同的是,CLIP的训练数据是文本-图像对,因此本文考虑使用CLIP来提取文本与图像的特征。但是CLIP只能提取图像的粗粒度特征,想要找到文本对应的区域需要预先将图像进行分割,将分割后的掩码进行编码后与文本进行匹配。FreeSOLO[6]是一种完全无监督的学习方法,可以在没有任何注释的情况下对实例进行分割。但是直接融合经过CLIP编码的图像特征与分割后的图像特征,无法充分利用图像的边缘信息。小波变换是一种在频域进行信号处理的方式,当用于图像处理时,小波变换的高通滤波器可以提取图像的边缘特征,低通滤波器可以有效利用数据之间的信息,因此可以用于细粒度的特征处理。文献[7]使用小波变换来对丢失的人脸特征进行提取,使人脸图像更加清晰。文献[8]提出了一种多级离散小波融合的方法,能够有效地融合特征。
当使用前述方法进行指称图像分割时,都存在着特征与文本难以匹配或者图像特征提取不充分的问题。因此,本文提出了一种使用小波变换在频域融合通过CLIP提取图像与文本特征的方法,用于zero-shot的指称图像分割。
1 相关工作
1.1 语义分割
语义分割是将像素按照图像中表达语义含义的不同进行分割,如将原始图像中不同类别的像素分配相应的标签。语义分割的目标是将语义标签分配给图像中的每个像素,其中语义标签通常包括不同范围的物体类别(人、狗、公共汽车、自行车)和背景成分(天空、道路、建筑物、山)。不同于目标检测和识别,语义分割实现了图像像素级的分类,能够将一张图片或者视频(视频以帧来提取的话其实就是图片),按照类别的异同,分为多个块。
语义分割的开山之作FCN[9]第一次将卷积用于语义分割并进行了不同尺度的信息融合。U-Net[10]解决了小样本的分割问题并实现了更加丰富的信息融合。SegNet[11]为了防止信息丢失,提出了一种带有坐标的池化。DeepLab[12]提出了带孔卷积并引入ASPP(atrous spatial pyramid pooling)结构,融合了不同层级的特征,还添加了一个简单有效的解码器模块来修正分割结果,并将深度可分离卷积用于ASPP提升网络运算速度。文献[13]提出了一种使用空洞卷积融合多级特征信息的方法,不断迭代深层特征来丰富低级视觉信息,并与高级语义特征融合,得到精细分割结果的方法。文献[14]使用了轻量化卷积神经网络,在样本数量较少的条件下实现了SAR图像的语义分割。
1.2 视觉与语言编码
视觉编码是指将图像输入到神经网络中,通过一系列的操作,将图像转换成一定维度的向量,这个向量就是图像的特征向量。视觉编码的目的是将图像信息转换为机器可以理解和处理的形式,以便于后续的任务处理。语言编码同理,是为了将自然语言文本转换为计算机能够处理的形式。
指称图像分割的目的是在给定输入的自然语言表达的情况下,对图像中的目标物体进行分割。对于该任务,目前已经提出了几种全监督的方法[15~19],其中使用图像和文本作为输入,并给出目标掩码进行训练。大多数研究[15,16]的重点是如何融合从独立编码器中提取的不同模态特征。早期的研究[17,18]通过简单地拼接视觉和文本特征来提取多模态特征,并将其输入文献[9]提出的分割网络,以此预测分割mask。文献[16]提出了基于注意力机制的编码器融合多模态特征,还有使用基于Transformer解码器的跨模态解码器融合多模态特征[15]方法的文献。最近,已经提出了一种基于CLIP的方法[19],该方法使用对比预训练学习分离的图像和文本转换器。这些全监督的指称图像分割方法总体上表现出良好的性能,但需要对目标掩码进行密集的标注和对目标对象进行全面描述。为了解决这个问题,Strudel等人[20]提出了一种弱监督指称图像分割方法,该方法使用基于文本的图像级监督学习分割模型。然而,该方法仍然需要对特定数据集的图像进行高级引用表达式注释。Yu等人[21]提出了一种无训练的方法,使用CLIP对全局-局部上下文特征进行提取实现了分割,但是在图像的特征提取方面仍然可以改进。因此本文使用CLIP的编码器提取特征并在频域进行特征融合。
1.3 指称图像分割
指称图像分割需要在给定描述区域的自然语言文本条件下,在图像中找到与自然语言文本匹配的特定区域,现有方法中通常有两个步骤:a)分别从文本和图像输入中提取特征;b)融合多模態特征来预测分割掩码。在第一个过程中,之前方法采用递归神经网络和Transformer[22]对文本输入进行编码。为了对输入图像进行编码,在之前的方法中先后使用了vanilla全卷积网络[1]、Deeplab v3[12]和DarkNet[23],目的是学习判别表示。多模态特征融合是现有方法的一个关键环节。文献[1]提出了第一种串联操作的方法;文献[18]采用循环策略对其进行了改进;文献[24]通过各种注意机制对语言和视觉特征之间的跨模态关系进行建模;文献[25]利用句子结构知识捕获多模态特征中的不同概念(如类别、属性、关系等);文献[22]利用词间的句法结构指导多模态上下文聚合。本文采用一种使用已有CLIP的编码器对图像和文本进行编码的方法,可以实现无训练、零样本的图像分割。
2 整体框架
为了解决指称图像分割任务,首先要学习投影到多模态嵌入空间中的图像与文本特征。为此,本文提出频域融合指称图像分割方法(frequency domain fusion referring-image-segmentation,FDFR),采用CLIP[3]的图像和文本编码器来处理图像和自然语言的跨模态特征。网络框架由三部分组成,如图1所示:a)用于图像特征的CLIP编码器;b)用于文本特征的CLIP自然语言编码器;c)用于频域融合的小波变换特征处理器。给定一组由FreeSOLO[6]生成的预测掩码,本文首先对每个预测掩码进行裁剪,使用CLIP对裁剪后的特征以及完整的图像进行编码,在频域对两种编码特征进行分解并将分解后的特征融合,再进行反变换得到图像特征。输入文本使用NLTK提取到名词,使用CLIP对完整的自然语言文本和名词进行编码,使用1D的小波变换对文本进行处理并在频域融合后进行反变换提取到文本特征,最后将特征进行匹配得到分割结果。
本文会详细介绍模型的各个模块。首先展示方法的总体框架,然后给出具体的图像特征与文本特征的提取方法,提取全局特征与局部特征并进行融合的方法,总体框架如图1所示。
2.1 多模态特征提取
指称图像分割任务需要充分利用图像特征,因为CLIP是为了学习粗粒度图像级表示设计的,不支持细粒度像素级的表征,并不能直接适用于完成图像分割的任务,对此本文采用一种提取分割后图像的局部特征的匹配方式。本文首先使用FreeSOLO对输入的图像进行分割来获取分割后的图像,后续使用CLIP的编码器对分割后的图像进行处理。
对于每一个预测掩码,FDFR首先使用CLIP预训练模型提取并进行编码。然而,CLIP的原始图像特征处理器是使用单一的特征向量来描述整个图像。为了解决这个问题,需要对CLIP中的图像编码器进行修改,以提取包含被遮挡区域和周围区域信息的特征,学习多个对象之间的特性。
CLIP具有两种图像编码器,分别使用了ResNet和Vision Transformer(ViT)两种不同的架构。本文使用了两种编码器对特征进行处理并对比结果。
其中:image是输入的图像;CLIPresnet-50和CLIPvit-B/32分别代表了使用CLIP的ResNet-50和Vit-B/32两种不同架构的编码器;fv-res和fv-vit表示的两种编码器分别对图像的编码结果。
上一步本文得到了分割后的图像,对分割后的图像和原本的图像同时使用相同的CLIP编码器处理,得到flocal和fglobal两种特征,用于后续在频域的特征融合。
与图像的处理相似,CLIP的文本编码器在训练时使用的是仅有少量单词的短句,因此缺乏上下文的语义理解能力,无法应对复杂的长句,所以需要对自然语言文本中的名词进行提取,并与分割后的图像进行匹配。因此本文输入完整的文本并使用NLTK提取文本中的名词,可以表示为
textnoun=NLTK(text)(2)
其中:text是输入的完整文本;textnoun是使用NLTK提取后的名词,使用CLIP的文本编码器分别对文本和名词进行处理获得文本特征。
其中:fsentence代表完整文本的特征;fnoun代表名词特征。后续将对得到的完整文本特征与名词特征进行融合。
2.2 频域特征融合
提取到需要的图像特征后,此时的边缘特征是不完善的,使用这样的图像特征与文本特征直接进行匹配,无法有效判断文本描述的内容在图像中的位置,并且难以辨别图像中相似的内容,导致分割结果出现误差。为了有效利用边缘特征以及判别图像中的相似内容,需要进一步对特征进行处理,采取哈尔变换[26]来实现并融合。哈尔变换(图2)包含了一个高通滤波器(high pass filter)和一个低通滤波器(low pass filter),其中高通滤波器用于提取边缘特征,低通滤波器用于图像近似。
本文将前面得到的图像特征与分割后的图像特征均使用哈尔小波进行分解,可以得到低频与高频的特征,分别对低频与高频的特征进行融合(图2),再进行反变换得到用于对比的图像特征。
哈尔小波的母小波可以表示为
且对应的尺度函数可以表示为
其滤波器h[n]被定义为
使用式(8)对特征进行处理。
其中:f是输入的前面使用CLIP编码的特征;α和τ代表尺度因子和平移量。
利用小波变换得到flocal和fglobal在频域的特征fl_wave和fg_wave,在频域对特征进行融合:fw=λfl_wave+(1-λ)fg_wave(9)
其中:fw是在频域融合后的频域特征;λ是在[0,1]的超参数。使用小波逆向变换,将频域特征变换为融合后的图像特征:
其中:fv是逆变换后得到的图像特征,这里的小波函数ξ(t)是一个满足正交条件的函数,即
其中:δ(t)是单位冲激函数。
和上面的图像特征相似,在频域进行融合并逆变换,因为文本特征维度的缘故,这里使用1D小波变换。将前面得到的自然语言特征与名词特征使用1D小波进行分解得到高频与低频特征,并分别对高频与低频特征进行融合(图3),再进行反变换得到用于对比的文本特征,如图3所示。
其中:DWT1D代表1D小波变换;fs_wave和fnoun_wave分别是完整文本和名词文本在频域的特征。
其中:ft是逆变换后的最终文本特征;IDWT1D代表逆变换。
2.3 文本-图像匹配
通过上面的操作,能够得到融合后的图像特征fv和文本特征ft。给定图像和文本特征的输入,通过计算余弦相似度对比所有的预测掩码与文本特征,在所有预测掩码中找到其图像特征与文本特征之间相似性最高的掩码,这个相似性最高的掩码即为分割的结果。
pred=arg max sim(fv,ft)(15)
其中:pred是匹配的预测掩码结果;fv是融合后的图像特征;ft是融合后的文本特征;sim是计算两种特征的余弦相似度。
余弦相似度计算公式如下:
通过余弦相似度的匹配计算,可以找出和文本特征相似度最高的预测掩码,也就是分割结果。
3 实验与分析
3.1 数据集介绍
实验训练使用的数据集是RefCOCO、RefCOCO+[27]、RefCOCOg[28],这三个数据集是三个从MS COCO(Microsoft common objects in context)中选取图像和参考对象的可视化接地数据集。
a)RefCOCO数据集。共有19 994幅图像,包含142 209个引用表达式,包含50 000个对象实例。遵循train/validation/test A/test B的拆分,testA中的图像包含多人,testB中的图像包含所有其他对象。每个文本表达式平均3.5个单词,平均每张图像具有1.6个对象。
b)RefCOCO+数据集。共有19 992幅图像,包含49 856个对象实例的141 564个引用表达式。遵循train/validation/test A/test B的拆分,并且查询不包含绝对的方位词,如描述对象在图像中位置的右边。每个文本表达式平均3.5个单词,平均每张图像具有3.9个对象。
c)RefCOCOg数据集。共有26 711幅图像,指称表达式104 560个,对象实例54 822个。数据集在非交互场景中收集。每个文本表达式平均包含8.4个单词,平均每张图像具有3.9个对象,相比之下更难完成任务。相比前两个数据集,RefCOCO+的一个特点是在文本表达中禁止使用位置词,使该数据集在指称图像分割任务中更具挑战性,因此该数据集可以更好地评估算法理解实例级细节的能力。
3.2 数据预处理与实现细节
本文实验使用的操作系统为Ubuntu 18.04,使用PyTorch 1.10深度学习框架,使用显卡为NVIDIA GeForce RTX 3090,24 GB显存,使用的CPU为Intel Xeon CPU E5-2630 v4 @ 2.20 GHz×40,256 GB RAM。
初始图像存在研究之外的区域,导致图像的质量不佳,而将进行图像裁剪可以改善图像质量,消除噪声,统一图像灰度值及尺寸。因此本文在对图像进行预处理时,需要对图像进行裁剪,用于后序特征提取。输入图像维度是[3, 428, 640],将其裁剪为[3, 224, 224]。同时为了文本的统一,需要将文本内容转换为小写字母。
然后使用FreeSOLO对图像进行分割,并使用NLTK对完整的自然语言文本进行提取,FreeSOLO分割得到图像的预测掩码,NLTK提取到输入文本中的名词。使用CLIP的图像编码器分别对完整图像与分割后的图像进行编码,使用CLIP文本编码器对完整文本与名词进行编码。
接着在频域融合编码后的特征,首先使用哈尔小波对输入的图像特征进行分解,然后在高频与低频进行图像的特征融合,最后进行反变换,得到最终的图像特征。文本特征与图像特征有一点区别,文本是一维的信息,因此文本特征使用1D的哈尔小波进行分解,然后分别在高频与低频融合编码后的文本特征,再进行反变换。文中设置的频域融合的超参数为λ=0.9,=0.6。
最后计算图像特征与文本特征的余弦相似度来找出最合适的预测掩码,也就是分割的结果,例如图像特征维度是[88,512],文本特征的维度是[1,512],代表需要从这88个预测掩码中对比得到相似度最高的掩码。
本文在RefCOCO、RefCOCO+、RefCOCOg三个数据集上对FDFR进行测试,并与其他方法使用相同编码器得到的分割结果进行对比。
3.3 評估标准
交并比(intersection over union,IoU)是目标检测中使用的一个概念,IoU计算的是预测边框和真实边框的交叠率,即它们的交集和并集的比值。最理想的情况是完全重叠,即比值为1,IoU的公式为
本文采用oIoU(overall intersection over union)与mIoU(mean intersection over union)[15]来对模型进行度量,这两个指标是指称图像分割任务的常用指标。oIoU是用所有测试样本的总相交面积与总结合面积之比来衡量的,每个测试样本都是一个语言表达和一个图像,这个度量适用于大型对象。
其中:Ai代表每一個测试样本的预测掩码;Bi代表测试样本的标签。
mIoU是所有测试样本中预测值与真实值之间的IoU。
其中:pii、pij、pji分别表示预测正确、将i预测为j、将j预测为i的概率;k为预测的类别数。
3.4 定量性能对比实验
本文将与一些使用CLIP[3]编码器进行编码的零样本指称图像分割的baseline进行比较,为了保证对比的效果,本文在所有的baseline中均使用FreeSOLO生成掩码提议。
a)Grad-CAM[29]。第一个baseline是使用基于Grad-CAM生成的梯度加权类激活映射。利用图像-文本对的相似度得分获得激活映射后,对所有预测掩码进行评分,选择得分最高的掩码。
b)score map[30]。这是一种是从MaskCLIP中提取score map的方法。与MaskCLIP一样,将注意力池化中的一个线性层和最后一层转换为两个连续的1×1卷积层。将从ResNet中提取的特征直接连接到这两层,然后与CLIP的文本特征对比并计算余弦相似度。在获得score map后,本文将预测掩码投影到score map。对不同掩码的分数取平均值,然后选择得分最高的预测掩码。
c)region token[31]。这种方法使用了Adapting CLIP,本文对CLIP视觉编码器中所有attention层的每个预测掩码使用region token,而不是使用超像素。最后,本文计算每个预测掩码与CLIP编码后的文本特征之间的余弦相似度,然后选择得分最高的掩码。
d)cropping[32]。最后一个baseline和本文方法相似,也进行了局部特征的提取。在使用CLIP作为编码器的零样本密集预测任务中,常常会用到cropping。因此,本文将裁剪作为零样本指称图像分割的baseline之一。
表1、2展示了频域融合CLIP图像与文本编码特征的方法在RefCOCO、RefCOCO+和RefCOCOg三个数据集上的表现,本文与其他使用CLIP图像编码器的方法,通过oIoU和mIoU两种指标对指称图像分割能力进行评判。本文方法在很大程度上优于其他方法。
与其他的baseline对比oIoU,FDFR使用CLIP的Vit-B/32编码器进行编码的方法在所有数据集中达到了最佳的效果,同时使用ResNet-50编码时,也在不同程度上领先于其他的baseline。
同时,使用FDFR得到的mIoU与其他的baseline相比也具有一定的优势。在RefCOCO与RefCOCO+这两个数据集上,本文使用ResNet-50进行编码的方法优于所有的baseline,在RefCOCOg数据集上,本文使用Vit-B/32进行编码的方法取得了最优的效果。
3.5 定性可视化分析
图4是使用本文方法得到的指称图像分割与标签之间的对比,下面给出了三种图像的示例与可视化对比。从图中结果可以看出本文方法,可以更好地提取图像的细节,能够有效区分与目标相似的掩码。
3.6 消融实验
为了证明单个模块的有效性,本文分别对用于图像预分割的FreeSOLO网络、提取自然语言文本主语的NLTK和频域融合这三个模块进行了消融。本文分别使用CLIP的ResNet-50和Vit-B/32两个图像编码器对图像进行编码,消融实验的结果如表3所示。
首先对于ResNet-50图像编码器,本文通过FreeSOLO[6]对图像进行分割并融合分割后的掩码特征,消融FreeSOLO后oIoU降低0.87,mIoU降低1.77;消融其他模块,也出现了类似的情况,具体结果在表格中显示。
然后对于Vit-B/32图像编码器,与上面的类似,对本文的三个模块进行消融后性能都有不同程度的下降。从上面的结果可以看出,在加入了FreeSOLO、NLTK和频域融合的模块后,系统性能会有所提升。
4 结束语
针对指称图像分割中图像特征提取不充分的问题,本文提出了FDFR,即通过现有的网络CLIP[3]与FreeSOLO[6]并在频域进行特征融合来实现的指标图像分割算法。利用FreeSOLO提取分割后的图片,利用NLTK提取自然语言文本中的名词,再使用CLIP的两种图像编码器对处理后的图像编码,并使用文本编码器对自然语言文本和文本名词进行编码,利用2D小波变换对图像特征进行分解,1D小波变换对文本特征进行分解,在频域实现特征融合并反变换得到最终的图像与文本特征,并计算特征的余弦相似度,得到分割结果。
本文目的在于利用小波变换的特点,使用高通滤波器提取图像边缘特征,低通滤波器分析图像近似性,为指称图像分割的零样本研究提供有力支撑。本文的研究证明,小波变化在图像分割任务中提取细粒度特征的有效性,未来将继续在此领域研究,利用更多的方法进行更加细粒度特征的提取。
参考文献:
[1]Hu Ronghang, Rohrbach M, Darrell T. Segmentation from natural language expressions[M]//Leibe B, Matas J, Sebe N, et al. Computer Vision. Cham: Springer International Publishing, 2016: 108-124.
[2]Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[C]//Proc of the 31st International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2017: 6000-6010.
[3]Radford A, Kim J W, Hallacy C, et al. Learning transferable visual models from natural language supervision[C]//Proc of the 38th International Conference on Machine Learning.[S.l.]: PMLR, 2021: 8748-8763.
[4]He Kaiming, Fan Haoqi, Wu Yuxin, et al. Momentum contrast for unsupervised visual representation learning[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2020: 9729-9738.
[5]Chen Ting, Kornblith S, Norouzi M, et al. A simple framework for contrastive learning of visual representations[C]//Proc of the 37th International Conference on Machine Learning.[S.l.]: PMLR, 2020: 1597-1607.
[6]Wang Xinlong, Yu Zhiding, De Mello S, et al. FreeSOLO: learning to segment objects without annotations[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2022: 14176-14186.
[7]劉颖, 孙定华, 公衍超. 学习小波超分辨率系数的人脸超分算法[J]. 计算机应用研究, 2020,37(12): 3830-3835. (Liu Ying, Sun Dinghua, Gong Yanchao. Wavelet based deep learning algorithm for face super resolution[J]. Application Research of Computers, 2020,37(12): 3830-3835.)
[8]王婷, 宣士斌, 周建亭. 融合小波变换和编解码注意力的异常检测 [J]. 计算机应用研究, 2023, 40(7): 2229-2234,2240. (Wang Ting, Xuan Shibing, Zhou Jianting. Anomaly detection fusing wavelet transform and encoder-decoder attention[J]. Application Research of Computers, 2023,40(7): 2229-2234,2240.)
[9]Long J, Shelhamer E, Darrell T. Fully convolutional networks for semantic segmentation[C]//Proc of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2015: 3431-3440.
[10]Ronneberger O, Fischer P, Brox T. U-Net: convolutional networks for biomedical image segmentation[C]//Navab N, Hornegger J, Wells W, et al. Medical Image Computing and Computer-Assisted Intervention. Cham: Springer, 2015: 234-241.
[11]Badrinarayanan V, Kendall A, Cipolla R. SegNet: a deep convolutional encoder-decoder architecture for image segmentation[J]. IEEE Trans on Pattern Analysis and Machine Intelligence, 2017,39(12): 2481-2495.
[12]Chen L C, Zhu Yukun, Papandreou G, et al. Encoder-decoder with atrous separable convolution for semantic image segmentation[C]//Proc of European Conference on Computer Vision. Cham: Springer, 2018: 801-818.
[13]冯兴杰, 孙少杰. 一种融合多级特征信息的图像语义分割方法[J]. 计算机应用研究, 2020, 37(11): 3512-3515. (Feng Xingjie, Sun Shaojie. Semantic segmentation method integrating multilevel features[J]. Application Research of Computers, 2020,37(11): 3512-3515.)
[14]水文澤, 孙盛, 余旭,等. 轻量化卷积神经网络在SAR图像语义分割中的应用[J]. 计算机应用研究, 2021,38(5): 1572-1575,1580. (Shui Wenze, Sun Sheng, Yu Xu. Application of lightweight convolutional neural network in SAR image sematic segmentation[J]. Application Research of Computers, 2021,38(5): 1572-1575,1580.)
[15]Ding Henghui, Liu Chang, Wang Suchen, et al. Vision-language transformer and query generation for referring segmentation[C]//Proc of IEEE/CVF International Conference on Computer Vision. Pisca-taway, NJ: IEEE Press, 2021: 16321-16330.
[16]Feng Guang, Hu Zhiwei, Zhang Lihe, et al. Encoder fusion network with co-attention embedding for referring image segmentation[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Re-cognition. Piscataway, NJ: IEEE Press, 2021: 15506-15515.
[17]Li Ruiyu, Li Kaican, Kuo Yichun, et al. Referring image segmentation via recurrent refinement networks[C]//Proc of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2018: 5745-5753.
[18]Liu Chenxi, Lin Zhe, Shen Xiaohui, et al. Recurrent multimodal interaction for referring image segmentation[C]//Proc of IEEE International Conference on Computer Vision. Piscataway, NJ: IEEE Press, 2017: 1271-1280.
[19]Wang Zhaoqing, Lu Yu, Li Qiang, et al. CRIS: CLIP-driven referring image segmentation[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2022: 11686-11695.
[20]Strudel R, Laptev I, Schmid C. Weakly-supervised segmentation of referring expressions [EB/OL]. (2022-05-12). https://arxiv.org/abs/ 2205.04725.
[21]Yu S, Seo P H, Son J. Zero-shot referring image segmentation with global-local context features[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2023: 19456-19465.
[22]Hui Tianrui, Liu Si, Huang Shaofei, et al. Linguistic structure guided context modeling for referring image segmentation[C]//Proc of the 16th European Conference on Computer Vision. Berlin: Springer-Verlag, 2020: 59-75.
[23]Jing Ya, Kong Tao, Wang Wei, et al. Locate then segment: a strong pipeline for referring image segmentation[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2021: 9858-9867.
[24]Shi Hengcan, Li Hongliang, Meng Fanman, et al. Key-word-aware network for referring expression image segmentation[C]//Proc of European Conference on Computer Vision. Cham: Springer, 2018: 38-54.
[25]Huang Shaofei, Hui Tianrui, Liu Si, et al. Referring image segmentation via cross-modal progressive comprehension[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Pisca-taway, NJ: IEEE Press, 2020: 10488-10497.
[26]Chen C F, Hsiao C H. Haar wavelet method for solving lumped and distributed-parameter systems[J]. IEEE Proceedings-Control Theory and Applications, 1997, 144(1): 87-94.
[27]Nagaraja V K, Morariu V I, Davis L S. Modeling context between objects for referring expression understanding[C]//Proc of the 14th European Conference. Cham: Springer, 2016: 792-807.
[28]Kazemzadeh S, Ordonez V, Matten M, et al. ReferitGame: referring to objects in photographs of natural scenes[C]//Proc of Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2014: 787-798.
[29]Hsia H A, Lin C H, Kung B H, et al. CLIPCAM: a simple baseline for zero-shot text-guided object and action localization[C]//Proc of IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway, NJ: IEEE Press, 2022: 4453-4457.
[30]Zhou Chong, Loy C C, Dai Bo. Extract free dense labels from CLIP[M]//Avidan S, Brostow G, Cissé M, et al. Computer Vision. Cham: Springer, 2022: 696-712.
[31]Li Jiahao, Shakhnarovich G, Yeh R A. Adapting clip for phrase localization without further training[EB/OL]. (2022-04-07). https://arxiv.org/abs/2204.03647.
[32]Ding Jian, Xue Nan, Xia Guisong, et al. Decoupling zero-shot semantic segmentation[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2022: 11583-11592.
