异策略模仿-强化学习序列推荐算法
2024-06-01刘珈麟贺泽宇李俊
刘珈麟 贺泽宇 李俊

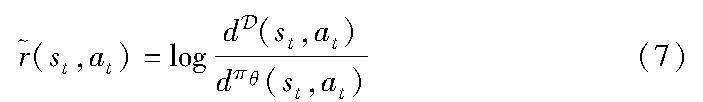
摘 要:最近,強化学习序列推荐系统受到研究者们的广泛关注,这得益于它能更好地联合建模用户感兴趣的内动态和外倾向。然而,现有方法面临同策略评估方法数据利用率低,导致模型依赖大量的专家标注数据,以及启发式价值激励函数设计依赖反复人工调试两个主要挑战。因此,提出了一种新颖的异策略模仿-强化学习的序列推荐算法COG4Rec,以提高数据利用效率和实现可学习的价值函数。首先,它通过异策略方式更新分布匹配目标函数,来避免同策略更新密集在线交互限制;其次,COG4Rec采用可学习的价值函数设计,通过对数衰减状态分布比,模仿用户外倾向的价值激励函数;最后,为了避免模仿学习分布漂移问题,COG4Rec通过累积衰减分布比,强化用户行为记录中高价值轨迹片段重组推荐策略。一系列基准数据集上的性能对比实验和消融实验结果表明:COG4Rec比自回归模型提升了17.60%,它比启发式强化学习方法提升了3.25%。这证明了所提模型结构和优化算法的有效性。这也证明可学习的价值函数是可行的,并且异策略方式能有效提高数据利用效率。
关键词:异策略评估; 模仿学习; 逆强化学习; 序列推荐
中图分类号:TP391 文献标志码:A 文章编号:1001-3695(2024)05-010-1349-07
doi:10.19734/j.issn.1001-3695.2023.10.0447
Off-policy imitation-reinforcement learning for sequential recommendation
Abstract:Recently, reinforcement learning sequence recommender systems have received widespread attention because they can better model the internal dynamics and external tendencies of user interests. However, existing methods face two major challenges: low utilization of same-strategy evaluation data causes the model to rely on a large amount of expert annotation data and heuristic value incentive functions rely on costly repeated manual debugging. This paper proposed a new hetero-strategic imitation-reinforcement learning method to improve data utilization efficiency and achieve a learnable value function. Firstly, it updated the distribution matching objective function through different strategies to avoid the intensive online interaction limitations of same-strategy updates. Secondly, COG4Rec adopted a learnable value function design and imitated the value incentive function of outdoor tendencies through the logarithmic decay state distribution ratio. Finally, in order to avoid the problem of imitation learning distribution drift, COG4Rec strengthened the recommendation strategy for recombining high-value trajectory segments in user behavior records through the cumulative attenuation distribution ratio. The results of performance comparison experiments and ablation experiments on a series of benchmark data sets show that COG4Rec is 17.60% better than the autoregressive model and 3.25% better than the heuristic reinforcement learning method. This proves the effectiveness of the proposed COG4Rec model structure and optimization algorithm. This also proves that the design of a learnable value function is feasible, and the heterogeneous strategy approach can effectively improve data utilization efficiency.
Key words:off-policy evaluation; imitation learning; inverse reinforcement learning; sequential recommendation
0 引言
推荐系统对探索如何感知用户真实兴趣和解决信息爆炸问题具有重要意义[1]。在推荐任务中,用户与系统的交互过程可以被表示为一个动态序列,该序列包含了用户的反馈信息。一个典型的应用是电子商务[2],用户在平台的活动促销页面浏览、点击、添加购物车,直到促销选项满足其兴趣倾向进而购买该推荐选项。序列推荐系统[3~5]基于序列化的交互反馈信息挖掘用户的兴趣倾向,来提供满足用户个性化需求的服务,极大地改善了人们的平台使用体验,因而具有重要的潜在商业价值。
一般来说,序列推荐系统中存在短期互动和长期互动两种不同类型的用户-商品交互行为。短期互动反映了用户当前的偏好,具有高度的动态性(内动态)[6],例如由最近点击商品ID组成的交互序列;而长期互动反映了用户在平台交互历史当中的兴趣倾向[7,8],特点是时变缓慢相对稳定(外倾向),例如点击、收藏、喜欢、购买等多种类型不同价值的反馈信号。近期研究工作指出,用户兴趣内动态方面的充分挖掘,短期来看有助于提升推荐的相关性,进而刺激用户的活跃度,但忽略用户外倾向方面的关注会降低推荐多样性,进而减少用户长期对平台的黏住度。因此,联合建模内动态和外倾向对实现个性化推荐既重要,又面临诸多挑战[9~11]。
经典序列推荐算法[6,12]有效提升了用户内动态方面的挖掘。为了同时挖掘用户的外倾向方面,最近的研究提出一系列基于强化学习的序列推荐算法[7,8,13,14],将外倾向定义为价值激励的累积,并通过累积价值激励函数最大化过程的同时学习用户的外倾向反馈和序列内动态反馈(图1)。虽然强化学习序列推荐算法有效地建立了联合优化的序列推荐模型,但作为推荐策略网络优化指导信号的价值激励函数受任务驱动,需要反复工程调试才能平衡不同反馈信号的价值区分度需求和强化学习训练过程的稳定性需求。由于系统数据库积累了丰富的用户历史行为记录,逆强化学习方法[15~17]提供了一种新的推荐范式,通过数据驱动价值激励函数的学习,与启发式设计的思路[7,14]相比,降低了任务复杂度(图2)。同时,由于累积价值激励函数最大化过程使得交互轨迹依照价值高低拆分成不同的轨迹片段,并重组成新的、更高价值的完整轨迹成为可能,故该类方法不需要假设用于学习价值激励函数和最大化累积价值的历史数据是完备的(即历史数据完备性)[17~19]。文献[20]指出“完备”的含义包括数量大和质量覆盖高价值推荐模式两个方面)。然而,基于逆强化学习的序列推荐算法通常需要密集的在线交互来评估当前推荐策略的性能(即同策略评估)。由于欠优化的待估策略与真实用户的即时交互可能会导致直接的商业损失和潜在的用户流失[8],所以同策略评估在序列推荐任务中的应用存在较大限制。同时,相比异策略评估(利用平台数据库中未知但较优的专家策略采集的历史行为记录数据评估当前推荐策略的更新方法),同策略评估方法数据利用效率较低[21]。
针对逆强化学习存在的问题,提出了一种异策略模仿-强化学习的序列推荐算法COG4Rec。鉴于启发式激励函数形式通常未知,而平台容易积累用户-系统交互行为模式(该行为演示模式由已部署的系统采集,采集系统πE通常未知),已有研究工作[19]指出,模仿学习在平台数据完备条件下收敛到反映用户真实行为模式的推荐策略,而强化学习在数据采集随机非完备情况下,可以有效提高外倾向的累计价值函数。受该研究启发,COG4Rec的核心思路是模仿真实用户行为,并通过参数化可学习的模仿度(由对数衰减状态分布比表示)作为隐式价值激励函数,避免了启发式设计过程。鉴于模仿学习过程假定用户行为积累数据涵盖最优行为策略(完备假设)且独立同分布,COG4Rec从被模仿行为轨迹中挖掘高价值的片段重组以强化长时累计价值,在不损失内动态的建模条件下,累计价值反映了用户的外倾向分布,该强化学习过程避免了模仿学习分布漂移问题。COG4Rec是一种基于衰减状态分布匹配的逆强化学习方法。a)该方法通过匹配衰减状态分布挖掘用户外倾向,并通過自注意力机制学习用户序列的内动态;b)Donsker-Varadhan展开将同策略更新的分布匹配目标函数转换为异策略更新;c)COG4Rec的策略评价网络Critic采用随机混合集成[22],避免异策略评估的探索误差[8]。COG4Rec的贡献包括:提出了一种新的异策略模仿-强化学习序列推荐算法,避免强化学习启发式价值激励函数设计增加推荐任务复杂度的同时,联合挖掘用户的外倾向和内动态以提高综合推荐性能。在序列推荐基准数据集上的总体性能对比和消融实验分析证明了COG4Rec模型结构和优化算法的有效性。在真实场景的基准数据集上的实验结果表明,与深度自回归序列推荐模型相比,COG4Rec相对提升17.60%;与启发式强化学习序列推荐模型相比,COG4Rec相对提升3.25%。
1 研究基础和术语
1.1 术语
强化学习通常将序列推荐问题定义为马尔可夫决策过程(S,A,P,R,ρ0,γ),其中:
最大化累积奖励函数的过程是系统对用户外倾向的挖掘,该过程弥补了深度序列模型仅挖掘内动态面的不足,故自适应的奖励函数R直接影响强化学习在推荐系统中的成功应用。
1.2 研究基础
序列推荐[3,23]作为推荐系统的重要研究分支,受到研究人员的广泛关注,其研究思路经历了深度学习时代前的协同滤波、深度序列推荐模型和强化学习序列推荐三个阶段。本节首先总结了强化学习和模仿学习工作,两者组成COG4Rec的研究基础,最后详细阐述了不同阶段的研究工作进展。
1)逆强化学习
强化学习通过学习参数化的目标策略πθ(a|s)来最大化累积奖励,该目标反映了用户的长时外倾向:
其中:轨迹τ=(s0,a0,s1,a1,…,s|τ|,a|τ|)根据目标推荐策略πθ(a|s),与用户及时在线交互采样获得。
逆强化学习的目标是根据专家演示集D={τexp1,…,τexp|D|},学习一个最优的价值激励函数R*,使得
其中:价值激励函数的一种实现方式是特征线性映射。
R(s)=wT(s)(3)
2)模仿学习
行为克隆[24]是模仿学习中较早提出的一类方法。其思路是根据专家演示集,最小化推荐策略πθ(a|s)在专家演示集上的交叉熵,来使得推荐策略与专家行为策略相似:
分布匹配的思路是利用衰减因子γ优化动作-状态分布比,避免了式(4)面临的分布漂移问题。推荐策略的衰减状态分布dπθ(s,a)可定义为
其中:s0~p0(·),st~p(·|st-1,at-1),at~πθ(·|st)。
演示数据集Euclid Math OneDAp:={(st,at,st+1)k}Nk=1根据未知的专家策略πdata采集。衰减分布匹配方法(discounted stationary distribution ratio,DDR)[25]通过最小化dπθ和dD之间KL散度来学习πθ,该最小化过程可转换为强化学习累积激励最大化:
其中:式(6)的状态分布比对应强化学习的激励函数为
值得指出的是,式(7)既可以利用同策略强化学习,也可以通过异策略强化学习优化,但考虑到推荐任务对用户隐私的保护[8],COG4Rec采用异策略评估的方法。
3)序列推荐系统
传统推荐算法假设相似的用户具有相似的喜好倾向,提出了基于矩阵分解的协同滤波算法,代表工作有BPR[26]、NCF[27]、FPMC[28]。BPR提出一种贝叶斯个性化排序推荐方法(成对型排序损失函数),使用一个有偏估计的分解矩阵作为推荐系统。针对有偏估计矩阵分解的问题,NCF首次提出使用深度神经网络估计用户-商品协同矩阵。FPMC方法则针对矩阵分解方法无法建模用户-商品交互过程的问题,提出一种基于马尔可夫链的协同过滤模型,将交互序列近似为一阶马尔可夫链,并在序列化增强的成对型排序损失上优化。上述方法无法建模高阶用户-商品交互过程。
传统推荐算法的缺点在于无法建模高阶用户-商品交互过程。基于深度学习的推荐模型将用户-商品交互过程建模为时序序列,模型的潜状态向量通过模型学习可以挖掘用户的高阶动态兴趣倾向。GRURec[29]应用序列化神经网络预测下一时刻用户的兴趣倾向。为了解决循环神经网络的梯度消散问题和计算效率问题,Caser[12]使用卷积神经网络作为推荐骨干网络。SASRec[6]受机器翻译等序列化生成任务的启发,使用Transformer结构作为推荐骨干网络。由于序列推荐系统中存在多种用户反馈信号,不同类型的反馈信号对系统具有不同的价值,深度模型的局限是没有考虑不同反馈信号的价值。
基于强化学习的序列推荐旨在优化不同反馈信号的累积奖励函数。已有工作可以分为:a)基于策略梯度的方法,考虑到推荐问题对实时用户交互的限制,off-policy REINFOCE[30]采用异策略估计的方法實现YouTube平台的视频推荐,针对异策略估计需要对采样行为策略样本矫正的问题,该方法提出一种基于倾向性分数的重估方法;b)基于价值函数的方法,SQN模型[7]利用动作-状态价值函数时序差分优化[31]来学习累积价值奖励最大化,并通过联合优化交叉熵时序预测来学习用户的动态兴趣变化趋势,VPQ[14]在SQN的基础上利用重采样方法降低时序差分学习的方差;c)基于动作-评价结构的方法,SAC[7]利用动作-状态价值函数作为样本权重加权交叉熵时序预测。基于强化学习的序列推荐的激励函数设计主要由任务导向,需要反复调试。基于强化学习的序列推荐系统需要依赖专家知识设计激励函数,作为累积奖励最大化过程的优化信号,而该设计任务驱动需要大量调试才能使强化学习训练过程稳定。
受到上述研究工作启发,本文提出一种基于衰减状态分布匹配博弈(min-max)的激励函数优化方法,并且通过Gumbel max算子保证激励函数具有高区分度,从而避免了激励函数的调试;同时,推荐策略网络试图降低推荐策略和专家行为策略的衰减状态分布比来优化推荐策略,策略评价网络试图优化隐激励函数(式(9))的估计来最大化累积奖励函数,从而捕捉到不同反馈信号代表的价值信息。
2 异策略模仿学习方法
针对上述逆强化学习序列推荐方法存在的问题,本文提出了一种异策略模仿-强化学习的序列推荐算法COG4Rec(off-poliCy imitatiOn learninG):对于价值激励函数设计的挑战,通过对数衰减状态分布比模仿用户外倾向的价值激励函数;对于同策略交互的挑战,通过Donsker-Varadhan展开得到异策略更新的优化目标。同时,因为推荐问题缺乏公认的基准仿真器,COG4Rec提出了一种基于随机混合集成[22]的策略评价网络,以随机性增加多样性。
2.1 问题定义
序列推荐系统利用用户-商品交互记录来强化未来的推荐:给定用户最近t个交互的商品序列(i1,i2,…,it)和用户反馈类型(如点击和购买),系统旨在利用平台收集的历史行为样本作为专家演示集,将其表示为集合Euclid Math OneDAp,预测下一个候选的it+1,同时限制序列的最大长度为n,即t<n,如果长度短于n,采用右补齐的方式到最大长度。
2.2 框架概述
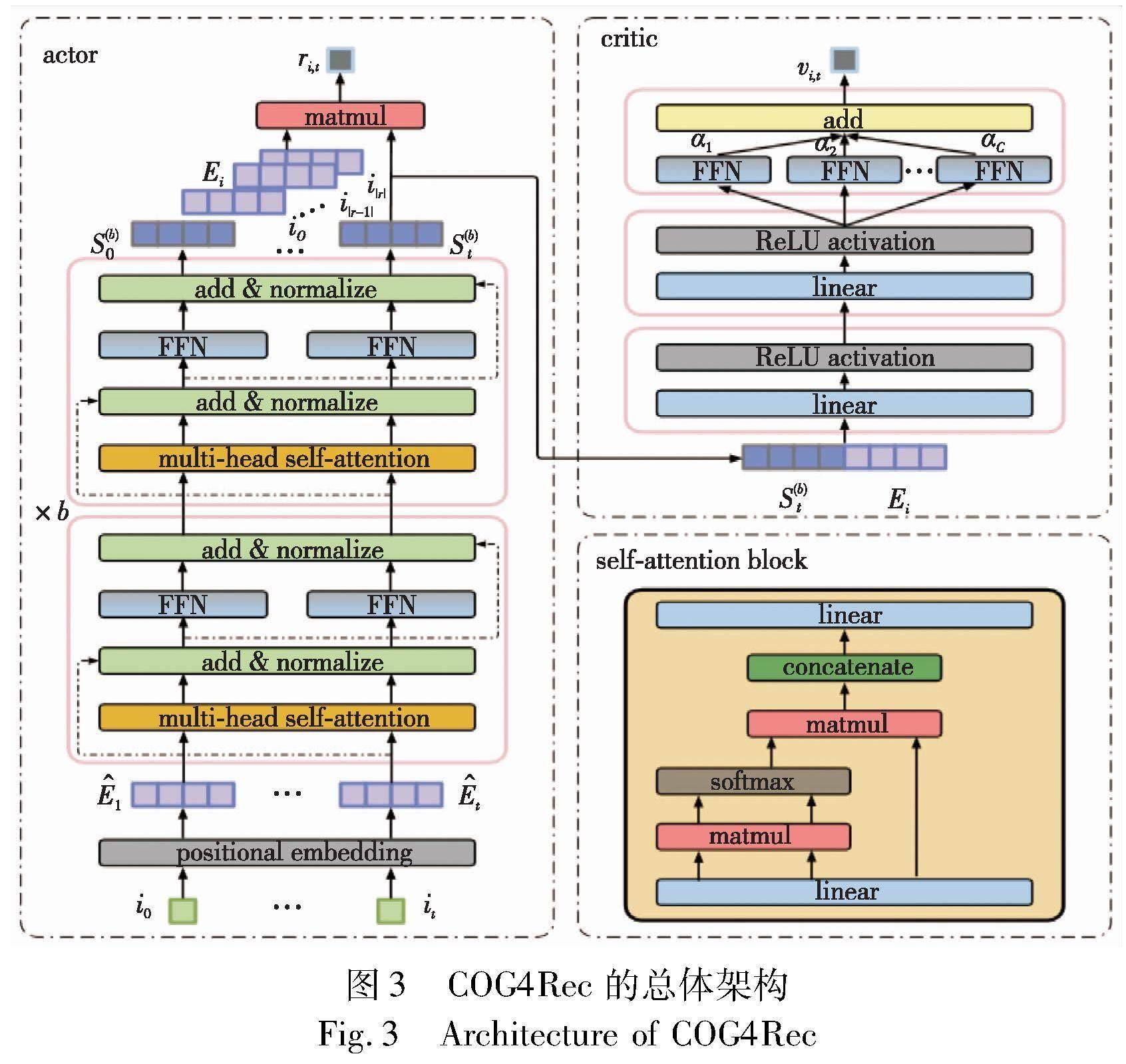
如图3所示,COG4Rec包含用于推荐的推荐策略网络actor和用于评估推荐的策略评价网络critic两个主要部分。推荐策略网络actor首先用可学习的位置感知编码将推荐项目空间映射到编码空间,进而基于注意力机制编码表示用户状态向量。策论评价网络critic采用前馈神经网络的结构,基于actor推荐动作和用户状态预测可能的累积奖励,并使用多簇随机混合集成弥补数据集Euclid Math OneDAp的多样性不足。下一时刻的推荐候选项采用协同滤波的思路,通过actor注意力模块输出结果与用户潜在状态编码向量的内积得到。
2.3 模型结构
为了实现式(8)提出的基于衰减状态分布匹配的生成对抗学习过程,COG4Rec设计了一种基于actor-critic模型架构,如图3所示。
2.3.1 推荐策略网络actor
为了挖掘用户的内动态倾向,推荐策略网络actor采用了多头自注意力模块作为主干网络,本节依次介绍网络结构设计。
b)自注意力模块。注意力机制计算的是取值按维度系数缩放的加权和,可定义为
其中:j∈{1,2,…}表示当前交互序列的前j项。为了增加actor的网络深度从而学习更高阶的用户表征向量,COG4Rec采用了残差连接和层归一化增强,如图3的self-attention所示。
c)预测层。为了预测用户的候选推荐项,actor在自注意力模块的基础上,利用用户编码共享的商品编码空间进行内积矩阵因式分解[6],得到相关预测分数:
ri,t=S(b)tETi(15)
其中:ri,t表示商品i与当前用户状态S(b)t的相关性,即成为下一个候选项的可能性。虽然共享用户与商品编码空间存在一致对称过拟合的风险,但逐点前馈网络(式(12)所示)引入的非线性能确保式(15)学习到非对称的商品编码转换。
值得注意的是,虽然策略评价网络critic和推荐策略网络actor均可完成预测层任务,其中critic强调序列外倾向估值,actor关注序列内动态相关性,但是由于离线环境的限制,相关研究工作[7]指出,critic作为推荐预测端,会导致actor梯度估计方差上升。因此COG4Rec采用actor网络进行推荐预测。
2.3.2 策略评价网络critic
为了挖掘用户历史交互的外倾向,COG4Rec采用策略评价网络critic最小化推荐策略分布和用户行为记录分布的状态分布匹配差异,来最大化代表外倾向的累积价值激励,网络结构如图3 critic所示。具体来说,critic在逐点前馈神经网络的基础上采用了C簇随机混合集成[22],以随机性缓解专家演示样本Euclid Math OneDAp多样性不足的问题,并通过集成方式,避免随机混合引入的噪声。具体来说,critic以当前状态编码向量和推荐项目编码向量作为输入:
综上所述,图4给出了COG4Rec模型的推荐流程,首先初始化参数模型,进而根据推荐结果是否得到正反馈(更新最大似然估计)和是否得到高价值正反馈(更新衰减匹配分布)来更新模型参数,并利用actor网络通过贪心搜索的方式得到推荐列表,反复迭代得到完整的交互轨迹。
2.4 模型优化
为了解决有效利用作为专家演示的历史记录数据Euclid Math OneDAp,并联合挖掘用户兴趣的内动态方面和外倾向方面,COG4Rec采用衰减状态分布匹配的生成对抗优化过程:策略评价网络critic最小化推荐策略分布和用户行为记录分布的状态分布匹配差异,避免了强化学习启发式设计价值激励函数的过程;COG4Rec的推荐策略网络actor最大化累积对数衰减状态分布比,避免了模仿学习分布漂移的问题。
2.4.1 外倾向学习
为了挖掘用户历史交互的外倾向,COG4Rec提出了一种基于衰减状态分布比的优化学习过程。具体来说,式(6)Donsker-Varadhan展开得到:
其中:r(s,a)通过对式(6)进行贝尔曼算子转换得到
其中:策略评价网络ν(s,a)作用相当于状态-动作价值函数,充分优化学习后可近似对数衰减分布比(式(19)右侧所示),贝尔曼算子定义为
其中:为简化表示,将t+1时刻状态动作表示为t′标记,代入贝尔曼算子得到优化目标JDDR。
其中:因为衰减状态分布(式(19)所示)的引入使同策略的采样(式(18)第二项)化简为利用专家演示集进行的采样(式(21)第二项),故式(21)是异策略的。
2.4.2 内动态学习
为了挖掘用户当前序列的内动态倾向,COG4Rec采用最大似然估计(maximum likelihood estimation,MLE)作为内动态的学习目标,如下:
该目标基于当前交互历史,自回归地优化下一时刻的预测,因此,能够使得模型向着挖掘内动态方向更新参数。
算法1 优化算法
2.4.3 整体优化目标
如算法1所示,用户内动态和外倾向的整体优化如下:
其中:推荐策略网络actor通过最大化衰减状态分布比来逼近专家策略; 策略评价网络critic通过最小化衰减状态分布比来评估生成的策略。策略评价网络critic收敛的解析最优解可以表示为(对式(21)两侧求导等于0可得)
值得指出的是,式(24)为同策略逆强化学习方法GAIL[15]及GCL[16]的显式优化目标,直接估计式(23)的分布比需要大量同策略交互,故GAIL[15]和GCL[16]的策略更新数据利用率较异策略更新方法有所下降。
3 实验结果及分析
为了验证COG4Rec的有效性,实验工作在两个基准序列推荐数据集(Yoochoose和Retailrocket)上進行了广泛的对比研究。首先,对COG4Rec与代表性的推荐系统基线方法比较了top-k推荐性能,以进行总体性能对比;然后,在Retailrocket数据集上,对COG4Rec进行详细的消融实验分析,以证明该算法关键设计对系统性能提升的贡献。
a)实验设置。基准序列推荐数据集Yoochoose和Retailrocket分别包含点击和购买两类交互反馈。为了保持不同推荐模型对比的一致性,实验中遵照文献[7]的预处理过程,删除了Yoochoose和Retailrocket中互动次数少于三次的序列,得到的数据集统计结果如表1所示。实验用于衡量推荐性能的两个指标是:表征top-k排序性能(k∈{5,10,20})的归一化折损累计增益NG;反映召回性能的命中率HR[7]。
b)对比基线。选择了具有代表性的序列推荐算法:(a)深度自回归序列推荐系统GRURec[29]、Caser[12]、SASRec[6],其自回归网络结构(GRU、CNN、Transformer)能有效地学习用户内动态特性,其表现性能优于一阶马尔可夫协同分解[28];(b)基于强化学习的序列推荐模型,基于状态-动作价值函数的VPQ[14]和SSQN[7]、基于“actor-critic”神经网络架构的SSAC[7]和两种离线强化学习方法作为骨干网络的CQL[32]和UWAC[33]。
c)实现细节。两个数据集采用的输入序列长度均为10个当前时刻的近期交互,并使用数据集交互商品数作为右补齐的掩码向量,编码向量均采用64维,批量输入(batch size)大小为128,实验统一采用与VPQ相同的激励函数设置方法(购买价值为1,点击价值为0.2)。CQL超参数α设为0.5,VPQ的λ=20,UWAC的λ=1.6。VPQ、SSQN、SSAC和COG4Rec从actor网络预测下一时刻推荐,CQL和UWAC的推荐策略采用maxaQ(s,a)的贪心搜索得到。COG4Rec采用了单头两层自注意力模块,实现过程参考SASRec结构(SASRec代码地址:https://github.com/kang205/SASRec)。推荐策略网络actor的学习率为1E-4,策略评价网络critic的学习率為1E-3,通过Adam执行模型反向传播优化。actor网络在自注意力模块之后通过两层前馈神经网络(为了节省计算资源,实验中采用两层前馈神经网络作为非线性映射)映射用户状态编码和商品编码(隐藏层64维),并通过内积函数式(24)预测相关分数r。策略评价网络critic的折扣系数设为0.95,两层前馈神经网络(隐藏层64维,非线性函数为ReLU)映射后,通过15簇(C=15)随机混合得到评价分数v,actor和critic同步更新。
3.1 总体性能对比
表2、3分别列出了Retailrocket和Yoochoose的性能比较,其中:最优结果粗体表示,次优结果下画线表示,“*”表示双边t检验,p<0.05。a)与传统序列推荐模型GRU4Rec、Caser和SASRec相比,COG4Rec的提升归功于衰减状态分布优化的同时建模了用户的累计外倾向,而传统模型则仅依赖用户序列行为内动态,使得策略网络缺失长时累计价值反馈的监督引导,因此只反映了序列动态转移的用户兴趣倾向。由于深度自回归模型存在梯度消散的问题,故模型本身无法有效建模长时兴趣。b)与SSQN和SSAC相比,SSQN和SSAC的特点是均采用深度Q学习,Q学习依靠与环境交互来纠正异策略估计的偏差,而离线学习要求导致评估偏差会在当前任务中累积,从而阻碍这两种方法有效学习用户的外倾向,而COG4Rec将异策略估计偏差(表现为KL散度)作为critic网络优化的学习目标。c)基于强化学习的序列推荐模型VPQ、CQL和UWAC通过Q函数的不确定性来估计预测方差,并使用乘性加权(VPQ、UWAC)或减性归一化(CQL)的方法来消除不确定性,而不确定性由启发式设计得到,因而缺乏自适应性。式(8)的收敛点等价于对数分布比形式的激励函数式(9),因此actor最大化累积激励的过程式(11)避免了启发式设计,COG4Rec更具适应性。
综上所述,COG4Rec通过异策略衰减状态分布匹配学习的方式解决强化学习策略评估的及时交互挑战,提高了数据使用效率,并通过收敛到对数分布比形式的价值激励函数来避免启发式设计激励函数形式的挑战。
3.2 消融实验分析
为了验证COG4Rec关键设计的有效性,本文在Retailrocket数据集上进行了消融实验(表4给出k=20的结果,其他k值具备类似的统计趋势)。表4第一行(“val-only”)表示仅基于 IDDR(r,v) 优化actor和critic两个网络,该策略强调对用户外倾向的捕捉,与仅依靠 IMLE(r) 优化actor网络去掉critic网络的预测结果(“rel-only”)相比,它的性能有所下降,这是因为状态-动作价值函数时序差分学习无法通过在线交互矫正异策略方差较大的问题,如前所述基于隐私安全性的考虑,欠优化的推荐系统与用户的在线互动受到限制。用户外倾向IDDR(r,v)和内动态IMLE(r)联合优化的预测结果(“val+rel-rem”)效果更好,证明了COG4Rec优化目标(式(15))的有效性。引入随机混合集成的联合优化预测结果(“val+rel+rem”)进一步分散了数据样本,从而实现了最佳性能。
综上所述,进一步的消融实验验证了衰减状态分布匹配的联合优化目标(式(13)所示)和随机混合集成方法(式(24)所示)对提升COG4Rec推荐性能的重要性。
4 结束语
本文提出了一种基于异策略衰减状态分布匹配的新型序列推荐算法COG4Rec,在收敛到对数分布比形式的价值激励函数的同时,保证了累积用户反馈激励最大化。此外,COG4Rec采用异策略更新的方式迭代推荐策略,因而提高了数据使用效率。值得指出的是,COG4Rec使用的随机混合集成是增加演示数据多样性的初步折中方案,而基于用户模型因果建模的模仿学习则是未来进一步值得探索的方向。
参考文献:
[1]Zangerle E, Bauer C. Evaluating recommender systems: survey and framework[J]. ACM Computing Surveys, 2022,55(8): 1-38.
[2]Zhao Xiangyu, Zhang Liang, Ding Zhuye, et al. Recommendations with negative feedback via pairwise deep reinforcement learning[C]//Proc of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. New York: ACM Press, 2018: 1040-1048.
[3]Fang Hui, Guo Guibing, Zhang Danning, et al. Deep learning-based sequential recommender systems:concepts, algorithms, and evaluations[M]//Bakaev M, Frasincar F, Ko I Y. Web Engineering. Cham: Springer, 2019: 574-577.
[4]張杰, 陈可佳. 关联项目增强的多兴趣序列推荐方法[J]. 计算机应用研究, 2023, 40(2): 456-462. (Zhang Jie, Chen Kejia. Item associations aware multi-interest sequential recommendation method[J]. Application Research of Computers, 2023,40(2): 456-462.)
[5]欧道源, 梁京章, 吴丽娟. 基于高斯分布建模的序列推荐算法[J]. 计算机应用研究, 2023,40(4): 1108-1112. (Ou Daoyuan, Liang Jingzhang, Wu Lijuan. Algorithm of sequential recommendation based on Gaussian distribution modeling[J]. Application Research of Computers, 2023,40(4): 1108-1112.)
[6]Kang W C, Mcauley J. Self-attentive sequential recommendation[C]//Proc of IEEE International Conference on Data Mining. Pisca-taway, NJ: IEEE Press, 2018: 197-206.
[7]Xin Xin, Karatzoglou A, Arapakis I, et al. Self-supervised reinforcement learning for recommender systems[C]//Proc of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval. New York: ACM Press, 2020: 931-940.
[8]Xiao Teng, Wang Donglin. A general offline reinforcement learning framework for interactive recommendation[C]//Proc of AAAI Confe-rence on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2021: 4512-4520.
[9]Xu Chengfeng, Zhao Pengpeng, Liu Yanchi, et al. Recurrent convolutional neural network for sequential recommendation[C]//Proc of the World Wide Web Conference. New York:ACM Press, 2019: 3398-3404.
[10]Duan Jiasheng, Zhang Pengfei, Qiu Ruihong, et al. Long short-term enhanced memory for sequential recommendation[J]. World Wide Web, 2023,26(2): 561-583.
[11]Xu Chengfeng, Feng Jian, Zhao Pengpeng, et al. Long-and short-term self-attention network for sequential recommendation[J]. Neurocomputing, 2021,423: 580-589.
[12]Tang Jiaxi, Wang Ke. Personalized top-n sequential recommendation via convolutional sequence embedding[C]//Proc of the 11th ACM International Conference on Web Search and Data Mining. New York: ACM Press, 2018: 565-573.
[13]Bai Xueying, Guan Jian, Wang Hongning. A model-based reinforcement learning with adversarial training for online recommendation[C]//Proc of the 33rd International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2019: 10735-10746.
[14]Gao Chengqian, Xu Ke, Zhou Kuangqi, et al. Value penalized Q-learning for recommender systems[C]//Proc of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval. New York: ACM Press, 2022: 2008-2012.
[15]Ho J, Ermon S. Generative adversarial imitation learning[C]//Proc of the 30th International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2016: 4572-4580.
[16]Finn C, Levine S, Abbeel P. Guided cost learning: deep inverse optimal control via policy optimization[C]//Proc of the 33rd International Conference on Machine Learning.[S.l.]: JMLR.org, 2016: 49-58.
[17]Fu J, Luo K, Levine S. Learning robust rewards with adverserial inverse reinforcement learning[EB/OL]. (2018-02-23). https://openreview.net/forum? id=rkHywl-A-.
[18]Kumar A, Hong J, Singh A, et al. When should we prefer offline reinforcement learning over behavioral cloning?[EB/OL]. (2022-04-12). https://browse.arxiv.org/abs/2204.05618.
[19]Rashidinejad P, Zhu Banghua, Ma Cong, et al. Bridging offline reinforcement learning and imitation learning: a tale of pessimism[J]. IEEE Trans on Information Theory, 2022,68(12): 8156-8196.
[20]Jing Mingxuan, Ma Xiaojian, Huang Wenbing, et al. Reinforcement learning from imperfect demonstrations under soft expert guidance[C]//Proc of AAAI Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2020: 5109-5116.
[21]Kostrikov I, Agrawal K K, Dwibedi D, et al. Discriminator-actor-critic: addressing sample inefficiency and reward bias in adversarial imitation learning[EB/OL]. (2018-10-15). https://browse.arxiv.org/abs/1809.02925.
[22]Agarwal R, Schuurmans D, Norouzi M. An optimistic perspective on offline reinforcement learning[C]//Proc of the 37th International Conference on Machine Learning. [S.l.]: PMLR, 2020: 104-114.
[23]Zhang Shuai, Yao Lina, Sun Aixin, et al. Deep learning based recommender system: a survey and new perspectives[J]. ACM Computing Surveys, 2019, 52(1): article No. 5.
[24]Atkeson C G, Schaal S. Robot learning from demonstration[C]//Proc of the 14th International Conference on Machine Learning. San Francisco, CA: Morgan Kaufmann Publishers Inc., 1997: 12-20.
[25]Nachum O,Chow Y,Dai Bo,et al. Dualdice: behavior-agnostic estimation of discounted stationary distribution corrections[C]//Proc of the 33rd International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc.,2019:article No.208.
[26]Rendle S, Freudenthaler C, Gantner Z, et al. BPR: Bayesian personalized ranking from implicit feedback[C]//Proc of the 25th Conference on Uncertainty in Artificial Intelligence. Arlington, Virginia: AUAI Press, 2009: 452-461.
[27]He Xiangnan, Liao Lizi, Zhang Hanwang, et al. Neural collaborative filtering[C]//Proc of the 26th International Conference on World Wide Web. Republic and Canton of Geneva, CHE: International World Wide Web Conferences Steering Committee. 2017: 173-182.
[28]Rendle S,Freudenthaler C,Schmidt-Thieme L. Factorizing personalized Markov chains for next-basket recommendation[C]//Proc of the 19th International Conference on World Wide Web. New York: ACM Press, 2010: 811-820.
[29]Hidasi B, Karatzoglou A, Baltrunas L, et al. Session-based recommendations with recurrent neural networks[EB/OL]. (2016-03-29). https://arXiv.org/abs/1511.06939.
[30]Chen Minmin, Beutel A, Covington P, et al. Top-k off-policy correction for a REINFORCE recommender system[C]//Proc of the 12th ACM International Conference on Web Search and Data Mining. New York: ACM Press, 2019: 456-465.
[31]Mnih V, Kavukcuoglu K, Silver D, et al. Human-level control through deep reinforcement learning[J]. Nature, 2015,518(7540): 529-533.
[32]Kumar A, Zhou A, Tucker G, et al. Conservative Q-learning for offline reinforcement learning[C]//Proc of the 34th International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2020: article No. 100.
[33]Wu Yue, Zhai Shuangfei, Srivastava N, et al. Uncertainty weighted actor-critic for offline reinforcement learning[EB/OL]. (2021-05-17). https://arxiv.org/abs/2105.08140.
