基于Spark Streaming的海量GPS数据实时地图匹配算法
2024-06-01陈艳艳李四洋张云超
陈艳艳 李四洋 张云超
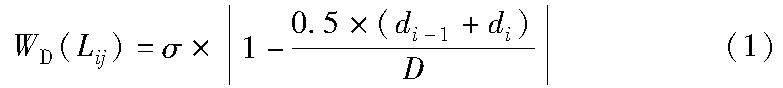

摘 要:浮动车GPS数据作为交通信息处理的基础,随着被监控车辆数量的高速增长,产生了海量GPS数据,对地图匹配提出了挑战。为了解决传统匹配方法难以满足匹配效率和精度的不足,提出一种针对海量GPS数据的实时并行地图匹配算法,能够同时保证较高匹配精度和运算效率。为构建一种面向实时数据流的高效、准确实时地图匹配算法,首先通过引入速度、方向综合权重因子对依赖历史轨迹的离线地图匹配算法进行重构,进而引入Spark Streaming分布式计算框架,实现地图匹配算法的实时、并行运算,大幅提升实时地图匹配效率。实验结果表明,该算法在复杂路段的匹配准确率较常规拓扑匹配算法提高10%以上,整体匹配准确率达到95%以上;在匹配效率方面,较同等数量的单机服务器效率可提高4倍左右。实验结果表明,该算法在由11台机器组成的计算集群上实现8 000万个GPS数据点的实时地图匹配,证明了该算法可以完成城市地区的实时车辆匹配。
关键词:海量; GPS; 并行计算; 地图匹配; 实时计算; Spark
中图分类号:TP391 文献标志码:A 文章编号:1001-3695(2024)05-008-1338-05
doi:10.19734/j.issn.1001-3695.2023.08.0424
Massive GPS data real-time map matching algorithm based on Spark Streaming
Abstract:Floating car GPS data serves as the foundation for processing traffic information, with the rapid increase in the number of monitored vehicles, a massive amount of GPS data is generated, posing great challenges to map matching. To address the shortcomings of traditional matching methods in terms of matching efficiency and accuracy, this paper proposed a real time parallel map matching algorithm for massive GPS data that ensured both high matching accuracy and computational efficiency. This paper firstly reconstructed an efficient and accurate real-time map matching algorithm for streaming data by introducing a comprehensive weight factor that considered velocity and direction to enhance the offline map matching algorithm that relied on historical trajectories. Then,it introduced the Spark Streaming distributed computing framework to achieve real-time and parallel computation of the map matching algorithm, significantly improving the efficiency of real-time map matching. Experimental results demonstrate that the proposed algorithm achieves more than a 10% increase in matching accuracy compared to conventional topological matching algorithms on complex road sections, with an overall matching accuracy of over 95%. In terms of matching efficiency, it achieves approximately a fourfold improvement compared to an equivalent number of standalone servers. The experimental results show that the proposed algorithm achieves real-time map matching of 80 million GPS data points on a computing cluster composed of 11 machines, proving that the proposed algorithm can achieve real-time vehicle matching in urban areas.
Key words:massive; GPS; parallel calculation; map matching; real-time computing; Spark
0 引言
道路上行駛的车辆装备GPS,实时采集其运行的位置数据,是道路实时路况计算、交通事件检测、交通趋势预测等交通监管应用数据的基础。由于GPS数据存在一定的偏移[1],地图匹配处理将车辆GPS轨迹数据纠正到其行驶的路段上,为众多智能交通应用提供必需的车辆行驶路径信息,因此成为智能交通关键支撑算法。当前城市中对车辆实时监测的规模越来越大,例如在首都北京,实时监测的车辆数量已经接近100万辆,同时在线的车辆数量峰值也达到60万辆。意味着在1~5 s的高采样频率下,每秒会产生超过40万条等待处理的车辆GPS数据。爆发增长的GPS数据对地图匹配处理提出了严峻的挑战。当前地图匹配算法多数为串行匹配,运行于单机系统中,其中优秀的算法如Hmm地图匹配算法[2]、PIF地图匹配算法[3]等,匹配效率只能达到2万条/s,远不能满足城市范围大规模GPS数据实时匹配的要求。而将海量数据分散到多个单机系统中进行同步匹配的方法,则遇到计算任务分配困难、缺少负载均衡机制、出错后难以自动恢复等弊端,难以工程化实施。伴随着浮动车轨迹数据的增长和智能交通应用的多样化和智能化,地图匹配的效率和实时性需求越来越高。目前针对实时地图匹配的研究,如文献[4]提出了WI map-matching algorithm,首先使用基于权值的匹配算法将轨迹匹配在路链中,然后使用插值法对匹配路径进行修正,对比实验表明,WIMM效率相对于IVMM与STMM有极大提高。文献[5]将浮动车行驶距离与GPS点偏移映射为状态转移概率与状态显示概率,提出基于隐马尔可夫模型的地图匹配算法。文献[6]设计了基于Hmm的改进实时地图匹配算法,并在新加坡路网的测试中表现较好。以上算法在提高准确率的同时难以兼顾效率,或为满足效率需求而牺牲部分准确率,但在特殊应用场景下,人们希望能够同时提升效率与准确率。
通过以上两方面的分析,考虑到城市路网及路况的复杂性,針对海量GPS数据的实时匹配问题,本文通过引入速度权重因子,重构了一种新的地图匹配算法以应对实时计算的需求,并针对匹配效率不足的问题,基于Spark Streaming计算框架实现了并行实时匹配计算。
1 实时地图匹配算法
1.1 浮动车地图匹配算法难点分析
浮动车数据是一段由时空关联的车辆位置状态信息组成的数据流,代表浮动车从开始到当前时刻的行驶轨迹。对于一辆浮动车,时间段
(t1,t2,…,tk)产生的k个点组成轨迹P,每个点pi由(ID,lat,lng,timestamp,speed,angle)等字段构成,ID代表这辆浮动车的唯一标识,timestamp表示定时数据采集时刻标识,lat和lng分别表示纬度和经度,speed表示车辆当前速度,angle表示车辆当前航向角。地图匹配将浮动车GPS定位数据与数字地图进行匹配,使目标点精确定位到路网中。在保证匹配精准度和强实时性的要求下,浮动车行驶环境、数据质量参差不齐,及存在海量数据等问题,给实时地图匹配带来了挑战,具体难点如下:
a)车辆行驶环境及数据质量。近年来随着定位技术的突破和浮动车采集设备性能的提升,采集到的定位数据精准度大大提升,但是车辆行驶环境受到建筑物、信号干扰、驾驶行为以及采集设备的采样频率等情况的影响,要求匹配算法具有精准度的同时具备较强的鲁棒性,能够应对各类异常数据。
b)海量数据处理及复杂路网。截止到2022年年底,北京市公路里程已达到2.2万km,主要道路达到7 000 km以上,汽车保有量超过600万辆,形成了较为复杂的城市路网和交通运行态势,给地图匹配的准确度和效率增加了难度。
1.2 实时地图匹配算法选型
目前,地图匹配算法可以分为几何地图匹配算法、拓扑地图匹配算法及高级地图匹配算法三大类。几何分析法只考虑了浮动车轨迹与道路形状的几何关系,计算简单,匹配效率较高,但是在实际应用中准确率较低,不适合在大部分路网中使用。高级地图匹配算法[7,8],如模糊逻辑、隐马尔可夫模型地图匹配算法,将地图匹配问题转换为复杂数学模型,虽然匹配准确率较高,但是计算复杂度高、匹配效率低下,不适合海量浮动车数据的地图匹配。而拓扑地图匹配算法在大数据地图匹配场景中应用最为广泛,如文献[9]所述,拓扑地图匹配方法充分考虑了路段之间的拓扑关系,以及车辆定位位置与道路距离、车辆与道路方向夹角等参数对匹配结果的影响。相比于高级地图匹配算法,拓扑地图匹配算法能够在保证较高匹配准确率的情况下尽可能地提高匹配效率[4,10]。文献[11]提出一种LeapFrog拓扑地图匹配算法,即在匹配过程中,当GPS点附近只有一条候选路链时,跳过该点与后续只对应一条候选路链的连续的GPS点。但是,LeapFrog拓扑地图匹配算法使用了后续时刻的GPS点信息辅助判断当前GPS点匹配路链(link),而在实时地图匹配过程中,后续时刻GPS点信息是无法获取的,该算法在离线GPS数据地图匹配中表现良好,但在车辆实时监管、车辆导航等需要实时地图匹配的应用中难以胜任。
通过对上述各类地图匹配算法的分析,各匹配算法在提高准确率的同时难以兼顾效率,或为满足效率需求而牺牲部分场景的准确率。考虑到实时地图匹配算法对匹配效率的要求较高,本文下一步将以匹配效率较高的拓扑地图匹配算法为基础,结合浮动车在城市公路上的行驶特征,构建新的地图匹配算法,兼顾匹配效率的同时提高算法准确率,使其满足交通信息服务准确、实时、快速发布的需求。
1.3 实时地图匹配算法构建
拓扑地图匹配方法(topological map matching)如文献[5]所述,充分考虑了路段之间的拓扑关系,以及车辆定位位置与道路距离、车辆与道路方向夹角等参数对匹配结果的影响。与效率较低的高级地图匹配算法和准确率较差的几何地图匹配算法相比,拓扑地图匹配算法在大部分场景下的计算准确率和效率均可达到较高水平[8],适合海量浮动车数据的实时匹配。
1.3.1 拓扑地图匹配算法计算步骤
拓扑地图匹配算法核心处理由候选路链计算、拓扑关系计算及路径推测三个步骤组成,具体如下:
a)候选路链计算。在完成对车辆历史轨迹{pi-1,pi-2,…}中各点的匹配之后,对于当前时刻GPS点pi ,根据pi的坐标以及地图数据中路链的位置,计算出与点pi相距小于GPS点的最大偏移距离(通常为40 m)的所有候选路链Li,1,Li,2,…,Li,mi,并根据车辆GPS点偏移距离、车辆方向偏移角度计算各候选路链的距离权重和方向权重,其中距离权重WD(Lij) 和方向权重WH(Lij)的计算公式如下:
其中:di-1是前一GPS点与候选路链间的距离;di是当前GPS点与其候选路链间的距离;σ是可调整的权重系数;D是最大定位误差半径,本文设定为40 m。
其中:gi-1是前一GPS点的行进方向与候选路链方向之间的差值;gi是当前GPS点行进方向与候选路链方向之间的差值;μ是权重系数;G是候选路径最大允许夹角,本文设为60°。
b)拓扑关系计算。根据路网拓扑结构,计算点pi-1、pi对应的候选路链Li-1,1,Li-1,2,…,Li-1,mi-1和 Li,1,Li,2,…,Li,mi之间所有可达路径,作为浮动车,由点pi-1移动至pi时所有可能的路径;并通过以下公式计算pi点对应候选路链的总权重值WS(Li,1),WS(Li,2),…,WS(Li,mi)。
其中:WD(Li,j)和WH(Li,j)分别为Li,j的距离权重和方向权重;WTR(Li-1,k,Li,j)和WLC(Li-1,k,Li,j)为候选路链Li-1,k与Li,j的转向权重和拓扑权重。当两条候选路链之间无可达路径时,对应WTR与WLC设为0;当存在可达路径时,WLC设为1,WTR将根据两条路链的几何属性计算得到[12]。
c)路径推测。比较各候选路径的总权重,根据浮动车数据与路链属性,推测出当前时刻浮动车最可能经过的路链,并保留点pi的所有权重值不为0的候选路链,用于支持下一时刻对车辆GPS点pi+1的权重计算。
1.3.2 实时地图匹配算法构建
本文研究的实时地图匹配场景的主要困难在于无法利用后续时刻GPS点的信息来推测候选路径[6],在道路交叉点附近的GPS点对应的两条候选路链(如图1、2所示)距离相距较近、方向相似,对应的距离权重以及航向权重差别较小,难以分辨浮动车正确的行驶路链。但是对于低速运行的轨迹数据,由于在相同距离上采样点的密集度较高,通过多定位点距离权重和方向权重综合验证,可以很好地进行候选路径的推测。但是对中高速轨迹匹配(尤其是采样点距离超过10 m),由于采样点间隔较大,通过定位点距离权重和方向权重得出的候选路链有多条,如图1所示,对于待匹配点P1的候选路链L1和L2,依据距离权重和方向权重,很难得出正确的判断,P2、P3定位点亦是如此。因此,本文引入速度权重以辅助分辨交叉路口附近的浮动车的正确行驶线路。
城市道路主辅路、立交桥、环形路等区域中分叉拓扑结构多为一条主干道分叉为一条主干道与一条连接路,如图2所示。其中主干道限速较高,连接路限速较低[13],通往连接路的浮动车在分叉口处选择减速行驶,引入速度权重将有助于区分限速不同的分叉路链。
本文引入速度权重的权值对拓扑地图匹配算法中的候选路链的总权重值WS进行调整,调整后的总权重WVS计算公式为
2 分布式实时地图匹配算法计算实现
2.1 分布式计算框架选择
实时地图匹配的数据处理有以下几个特点:a)能够记录数据流状态,以便下一批次数据的处理需要上一次处理后的结果;b)对数据处理的效率与吞吐量要求较高;c)需要较高的容错性,但是需保证每批数据仅被处理一次。
目前常用的流式实时分布式计算框架有Spark Strea-ming[14,15]和Storm[16],都能够较好地记录数据流状态。Spark Streaming主要对某段时间的数据进行批量处理,具有较高的吞吐量,处理延时在秒级左右[17,18];在容错性方面,Spark Streaming仅在处理级别上进行操作跟踪,可以保证每个批量的记录都被精确地处理一次,更适合处理事務性较高的场景。因此,相对于吞吐量较低,容错开销较大的Storm平台,Spark Streaming框架更加适合用于并行的实时地图匹配处理。
2.2 地图匹配算法的并行实现
本文设计了一个基于Spark Streaming的分布式实时地图匹配计算流程。在该流程中,首先将地图划分为多个网格,每个网格在经纬度直角坐标系中为等长宽的矩形;然后将不同网格分配至不同的计算单元,每个计算单元只计算指定网格内的浮动车数据。这样,每个计算单元只读取一次对应网格中的路链数据就可以完成网格内所有点候选路链的计算,减少了地图数据加载次数,在理论上能够较大地提升匹配效率。另一方面,将候选路链计算的时间复杂度O(mn)作为每个计算单元计算时消耗的估计量,可以作为每个节点分配计算单元时负载均衡优化的参考,其中m为网格中路链密度,n为网格中浮动车的密度。
在分布式实时地图匹配算法设计过程中,本文基于上述方法进行地图空间划分,设计了一个基于Spark Streaming的并行地图匹配计算流程,如图4所示。图中的步骤虽然与串行的实时地图匹配流程较为相似,但是其输入数据方式不同,使得两者之间的计算效率产生本质的差异。
该计算流程将实时的流式数据作为输入数据,基于Spark Streaming框架,按固定时间间隔(为保证实时性,在这里设置间隔为5 s)将数据流划分为多个Streaming batch data[19,20]。接下来的流程中将对每个Streaming batch data分三步处理:
a)分片数据预处理。首先计算出每个GPS点所属网格的编号(GridID),然后筛选并标记可跳点车辆对应的GPS点所匹配的路链。
b)候选路链计算。首先以预处理计算得到的GridID为key进行分组操作;其次获取对应grid中的路链;然后验证跳点标记的GPS点是否到达路链终点,取消到达终点的GPS点的标记;最后计算无跳点标记的GPS点的候选路链与权重。
c)路径推测。首先使用updateStateby-Key操作获取上一时间分片内各车辆的匹配结果,然后对于每一车辆,计算前后两点第一个候选路链之间的拓扑关系,连接为候选路径;最后根据拓扑关系计算出每个候选路径的权重值,并比较选择出权重最大的候选路径作为匹配结果;对于之后一条候选路径的车辆,将该候选路径作为该车辆的可跳点标记。
在该流程中,浮动车历史定位信息的获取效率优化是依靠Spark的RDD机制,当前时间段的Streaming batch data相应的计算结果将存储至内存存储单元RDD中,以便供下一时间段Streaming batch data计算流程中相应模块通过updateStateByKey算子获取。另外,Spark的流式数据处理框架中,DAG图机制以及内存计算等技术充分利用CPU与内存资源,实现多台机器内存共享管理,并将其抽象为一个整体进行读取、写入、计算等多种操作,其效率远远优于串行算法中多次对单车数据的查找、操作、写入流程,实现了匹配算法在优化计算效率的同时保障计算鲁棒性的目的,使得计算性能进一步提升。
3 实验
3.1 实验环境和数据集
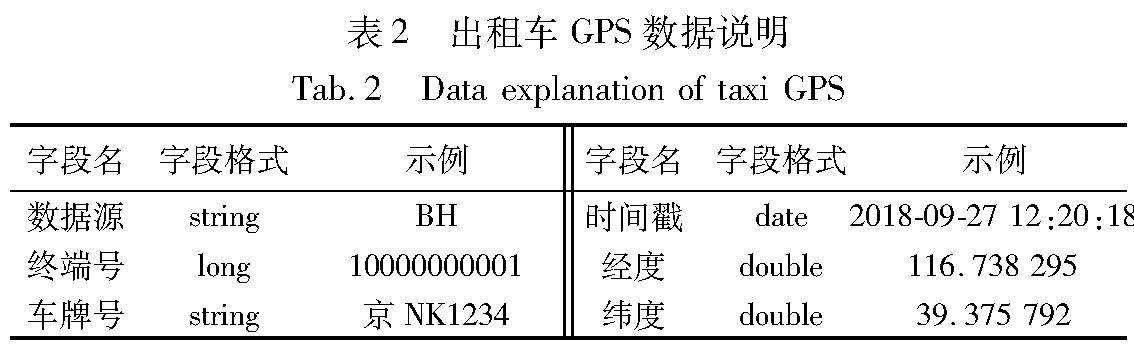
为了更准确地测试本文算法的计算效率和准确性,采用11个虚拟机,每个虚机配置包括8核CPU、36 GB内存、500 GB存储,本文的实验环境不包括大数据平台管理服务和数据接口前置服务器,仅为地图匹配算法处理部分。本文的实验数据为北京市2018年9~11月份采集的部分公交车、出租车运行过程中的轨迹数据,数据采集频率为1 s,数据量1亿条左右。通过数据预处理,去掉部分无效数据和轨迹点缺失较严重的数据,有效数据有8千万条以上,数据容量40 GB,采集数据包含的关键信息如表1、2所示,地图数据为2019年北京市四维地图。为了更好地验证上述基于Spark Streaming构造的分布式实时地图匹配算法的计算效率,本文依托已有的数据进行效率测试,验证不同数据规模下并行匹配效率与单机串行的计算效率差异。
为了更精准地分析本文算法的匹配效果,在本次实验的数据集中,选取54辆采样频率为1 s且具有固定行驶路线的公交车一周的轨迹数据,以及采样频率为1 s的100辆出租车一周的行驶轨迹数据,用于对算法准确率进行分析、验证。
3.2 匹配准确率分析
本文从两个角度进行匹配算法准确度的分析:a)从算法匹配总体准确度角度,本文构造匹配算法与经典拓扑匹配算法、高级匹配算法中的隐马尔可夫模型进行对比分析;b)按照道路等级分析本文算法在各道路结构下的适应性。
3.2.1 匹配精度计算方法
本文将测试城市道路匹配算法准确率,将使用匹配正确的车辆定位点数量与轨迹中总点数数量的比值作为匹配的准确率,用于评价地图匹配算法的效果。本文构造的实时地图匹配算法准确率(accuracy)将使用AN(accuracy by number)度量,这种度量方法被用在文献[11]的实验中。
其中:pi=(p1,p2,…,pn)为采集到的轨迹点;p*j=(p*1,p*2,…,p*n)为匹配正确的轨迹点。
3.2.2 匹配算法准确率对比分析
首先本文从总体地图匹配效果方面对比并分析本文算法与经典拓扑算法、隐马尔可夫模型的匹配准确度。由图5可见,本文算法的准确度明显优于经典拓扑匹配算法,整体匹配精度提高了10%以上,相对于隐马尔可夫模型也有明显的优势。根据前文分析,隐马尔可夫模型计算复杂度较高,不适合应用于实时度较高的处理。
同时,本文随机抽样24组车辆轨迹数据进行验证,为了减少随机因素对结果的影响,每组数据的连续轨迹均超过10 km。验证数据包括3辆公交车和3辆出租车的轨迹数据,通过各算法的处理,为了减少单车影响,对每辆车进行准确率计算。如表3所示,各算法的准确率与图5的准确度基本一致,再次验证了本文算法可以较好地完成实时地图匹配的处理。
针对表3中的car_3轨迹数据,通过本文算法处理,并借助MapInfo软件进行展示,得到了匹配效果如图6所示。在图6中,绿色线代表成功匹配到的道路,而红色虚线则表示车辆实际行驶道路,但算法未能正确匹配的部分(参见电子版)。除了在图中圈出的路口由于轨迹点的偏移過大且数据过于稀疏而导致稍有偏差外,其他部分均能够正确匹配,准确率与表3中所述一致,达到了95%以上。
3.2.3 匹配算法在各道路类型上的准确率分析
接下来,本文按照北京市几类道路类型进行匹配,以进一步分析本文算法的匹配准确度,如图7所示。
本文按照四维地图道路等级提取北京市五环内主路、辅路、快速路各10条,每条长度在2 km以上,以及5座立交桥进行准确度分析。本文算法在各道路类型上的平均准确率均在93%以上,尤其是在快速路和主路上准确度达到了98%以上,在立交桥上的准确度达到95%,完全满足智能交通应用的要求。
3.3 匹配算法效率分析
本文在Spark Streaming计算框架与单机串行计算效率对比实验中,准备了11台相同配置的设备,并把数据随机分成11份,实验结果如图8所示。Spark cluster的运行效率远远高于相同数量的单机服务器,数据量越大,这种趋势愈明显。基于本文8 000万条数据集的测试可以看出,3 min内Spark cluster可以处理完所有数据(相当于10万数量级车辆实时产生的轨迹数据),并且随着数据量的增加,Spark cluster处理效率更高,当数据增长至8 000万条时,Spark cluster的处理能力是相同数量的单机服务器的4倍左右。
4 结束语
随着智慧交通发展和车辆轨迹数据的爆发式增长,精准、实时、快速的地图匹配处理成为道路运行监测、智慧公路建设的迫切需求。为解决传统拓扑地图匹配算法在实时性和计算效率方面的问题,依托Spark Streaming分布式计算框架,本文提出一种针对于海量GPS数据的实时并行地图匹配算法,突破离线地图匹配算法对历史轨迹数据的依赖。其主要贡献如下:首先,通过引入速度和方向权重因子,实现只依靠当前位置点和后续位置点的地图匹配算法,为分布式实时地图匹配处理提供算法支撑;其次,以浮动车轨迹数据流作为实时数据输入,依托Spark Streaming分布式计算框架的RDD数据块和DAG图机制以及内存计算策略,充分利用服务器CPU与内存资源实现实时地图处理;最后,本文通过实时轨迹数据进行了算法和计算框架的对比实验,可为后续实时地图匹配算法的改进、优化提供参考。同时,本文在测试范围上存在一定的局限性,主要以北京营运车辆的轨迹数据进行测试,未能对其他城市进行对比分析,后续研究工作将在算法复用性上进行更为充分的测试和优化。
参考文献:
[1]Manikandan R, Latha R, Ambethraj C. An analysis of map matching algorithm for recent intelligent transport system[J].Asian Journal of Applied Sciences, 2017,5(1):179-183.
[2]Fu Xiao, Zhang Jiaxu, Zhang Yue. An online map matching algorithm based on second-order hidden Markov model[J]. Journal of Advanced Transportation, 2021,2021:1-12.
[3]Hunter T, Abbeel P, Bayen A M. The path inference filter: model-based low-latency map matching of probe vehicle data[M]//Algorithmic Foundations of Robotics X. Berlin: Springer, 2013: 591-607.
[4]盛彩英,席唱白,錢天陆. 浮动车轨迹点地图匹配及插值算法[J]. 测绘科学, 2019,44(8):106-112. (Sheng Caiying, Xi Changbai, Qian Tianlu, et al. Study of map-matching and interpolation algorithm of floating car data[J]. Science of Surveying and Mapping, 2019,44(8):106-112.)
[5]Karamete B K, Adhami L, Glaser E. An adaptive Markov chain algorithm applied over map-matching of vehicle trip GPS data[J]. Geo-spatial Information Science, 2021,24(3): 484-497.
[6]Luo Linbo, Hou Xiangting, Cai Wentong, et al. Incremental route inference from low-sampling GPS data: an opportunistic approach to online map matching[J]. Information Sciences, 2010,512: 1407-1423.
[7]Jin Zhixion, Kim J, Yeo H , et al. Transformer-based map matching model with limited ground-truth data using transfer-learning approach[EB/OL].(2021-10-07). https://doinory/10.1016/j.trc.2022.103668.
[8]Zhang Xiaoyao, Li Xuejing. Map-matching approach based on link factor and hidden Markov model[J]. Journal of Intelligent & Fuzzy Systems: Applications in Engineering and Technology, 2021,40(3): 5455-5471.
[9]Velaga N R, Quddus M A, Bristow A L. Developing an enhanced weight-based topological map-matching algorithm for intelligent transport systems[J]. Transportation Research, Part C: Emerging Technologies, 2009,17(6): 672-683.
[10]Hsueh Y L, Chen H C, Huang Weijie. A hidden Markov model-based map-matching approach for low-sampling-rate GPS trajectories[C]//Proc of the 7th IEEE International Symposium on Cloud and Service Computing. Piscataway, NJ: IEEE Press, 2017:178235-178245.
[11]Huang Jian, Qie Jinhui, Liu Chunwei, et al. Cloud computing-based map-matching for transportation data center[J]. Electronic Commerce Research & Applications, 2015, 14(6): 431-443.
[12]He Mujun, Zheng Linjiang, Cao Wei, et al. An enhanced weight-based real-time map matching algorithm for complex urban networks[J]. Physica A: Statistical Mechanics and Its Applications, 2019, 534: 122318.
[13]Pan Yuyan, Guo Jifu, Chen Yanyan, et al. Incorporating traffic flow model into a deep learning method for traffic state estimation: a hybrid stepwise modeling framework[J]. Journal of Advanced Transportation, 2022, 2022(1): article ID 5926663.
[14]Apache Spark. The Apache software foundation[DB/OL]. https://spark.apache.org/.
[15]Wang Suzhen, Jia Zhiting, Cao Ning. Research on optimization and application of Spark decision tree algorithm under cloud-edge collaboration[J]. International Journal of Intelligent Systems, 2022,37(11): 8833-8854.
[16]Muhammad A, Aleem M, Islam M A. TOP-Storm: a topology-based resource-aware scheduler for stream processing engine[J]. Cluster Computing, 2021,24: 417-431.
[17]Ghesmoune M, Lebbah M, Azzag H. Micro-batching growing neural gas for clustering data streams using spark streaming[J]. Procedia Computer Science, 2015,53(1): 158-166.
[18]Liu Guipeng, Zhu Xiaomin, Wang Ji, et al. SP-Partitioner: a novel partition method to handle intermediate data skew in spark streaming[J]. Future Generation Computer Systems, 2018,86: 1054-1063.
[19]Livaja I, Pripui K, Sovilj S, et al. A distributed geospatial publish/subscribe system on Apache Spark[J]. Future Generation Computer Systems, 2022,132: 282-298.
[20]Hu Fei, Yang Chaowei, Jiang Yongyao, et al. A hierarchical indexing strategy for optimizing Apache Spark with HDFS to efficiently query big geospatial raster data[J]. International Journal of Digital Earth, 2020,13(3): 410-428.
