基于引文共现层次采样的学术文献表示学习
2024-05-06丁恒张静陈佳卓曹高辉
丁恒,张静,陈佳卓,曹高辉
(华中师范大学信息管理学院,武汉 430079)
0 引 言
学术文献作为人类社会化进程中不可或缺的知识载体之一,以其无限的方式塑造着人类的思维、行为和决策:科学家通过批判性地阅读学术文献,激发新的思维,展开新的研究并创造新的知识;专业医疗人员依靠学术文献指导临床实践,并为患者提供最新的医疗建议;政策制定者借助最新的学术文献,以科学证据为基础制定政策和规定;商业人员则通过学术文献了解相关市场的消费者行为和偏好,为产品开发和市场推广提供指导。然而,随着学术文献数量的爆炸性增长,如何在信息过载的时代中帮助用户更好地检索和利用学术文献知识,已成为信息资源管理、知识管理、自然语言处理和信息检索领域学者的必答之问。
自图书情报学领域出现以来,学术文献的分类、组织、检索和利用始终是领域内的核心研究课题,在人工智能符号主义时代做出了很多重要贡献。例如,①创造系统化的分类体系、主题词表等工具,用于描述和索引文献内容[1];②发展和应用各种知识组织模式和技术进行文献组织[2];③制定检索策略、构建索引词表、开发检索语言和搜索算法,以提高文献检索效率和准确性[3]。然而,学术文献作为由人类以自然语言形式创作的一种知识形态,本质上属于非结构化的、具有稀疏符号序列特点的文本。对于基于数值计算基础构建的现代信息/计算机系统而言,这种符号序列化的表示方式存在着固有差异和隔阂。
近年来,计算机领域学者针对符号化表示方法的缺陷,以深度神经网络为核心工具,利用非结构化纯文本或结构化知识库作为数据源,将文本表示方法从依赖词汇符号的稀疏表示推进到以数值向量为基础的稠密表示,即所谓的文本/语义/知识表示学习[4]。相较于符号化的稀疏表示,基于数值向量的稠密表示不仅能体现出文本在词汇符号层面的关系,而且适用于挖掘文本间高层语义间的联系。计算机学科对文本表示学习的探索主要集中在:①创造语义表征能力更强的神经网络结构,如ELMo(embeddings from language models)[5]和Transformer[6];②寻找适用于不同领域和任务的模型训练方式,包括训练任务的构造和训练数据的选择,如BERT(bi‐directional encoder representations from transformers)[7]和SpanBERT[8]。图情领域学者敏锐地意识到稠密向量表示对学术文献知识加工和组织具有潜在价值,在实践应用层面展开了积极探索。例如,文献[9-10] 以BERT神经网络构建语言模型,用于学术词语功能识别和学术实体标注任务,利用大规模学术文本数据从词汇层次出发研究学术词语的数学表示方法;文献[11-12] 将深度神经网络模型用于学术文本句子或段落的向量表示,实现学术文本句子分类和学术文本段落结构功能识别任务。
已有研究表明,利用大规模学术语料中无标注文本单元(词与词、句与句)间的邻近关系训练神经网络,能够有效提升模型的语义表达能力,从而有益于学术文献分类、检索和推荐等下游任务[13]。在一项被简称为SPECTER(scientific paper embed‐dings using citation informed transformers)[14]的工作中,研究者不仅采用Transformer神经网络将学术文献编码成表示向量,并且为神经网络输出的表示向量附加限制,即假设存在引用关系的文献间向量距离较近,而不存在引用关系的文献间向量距离较远;研究结果表明,基于引用关系的文献距离假设可显著提升模型表示能力。根据图情领域关于引文的研究可知,引用动机是复杂的,被引文献与施引文献不一定在语义内容上十分相关,而非引用文献之间不一定完全无关,因此,我们认为SPECTER的假设可能引入噪声训练样本,从而影响模型最终的性能。
尽管SPECTER由计算机科学家提出,但基于引用关系衡量文献间相关性的思想在图情领域早已有论述[15]。此外,有些图情领域学者发现引文共现层次关系[16]和引文邻近距离[15]均可被用于衡量文献间距离。例如,Elkiss等[16]发现,“在相同的章节、段落或句子内共同引用的论文更相似”(以下简称“引文共现层次关系假设”);Eto[15]提出“彼此距离较远的两个引文比彼此距离较近的引文关系弱”的假设(以下简称“引文邻近关系假设”)。基于上述观点,本文提出了一种新的引文共现层次采样算法,该算法首先将文献的篇章结构转换为引文共现层次树,然后对多文献的引文共现层次树进行融合构造异构引文共现网络,最后基于异构引文共现网络进行正负样本采样,优化学术文本的语义表征向量;并且通过论文分类、用户行为预测、引文预测和论文推荐四类下游任务,证实该方法在学术文献特征表示上的有效性,从而回答以下两个研究问题:(1)引文共现层次关系假设是否有助于学术文献表示学习?(2)引文邻近关系假设是否有助于学术文献表示学习?
1 相关研究概述
1.1 通用文本表示学习研究
文本表示是指将自然语言符号转化为计算机可处理、可计算的数学形式,是自然语言处理、文本分析挖掘任务中一个基础且重要的步骤。当前,文本表示方法主要有基于向量空间模型的方法[17]、基于主题模型的方法[18]、基于图的方法[19]、基于知识库的方法[20]以及基于神经网络的方法[21]。
基于向量空间模型的方法通过特征空间构造和特征权重计算两个步骤,将文本表示为特征空间中的高维向量,维度对应于文本的特征项,特征空间不同方向的坐标对应文本在不同特征项上的权重值。不同的向量空间模型主要是在特征项选择方式或特征权重计算公式两个方面进行差异化设计,常见的特征项包括词根[22]、词[23]、短语[24]及n-gram[25]等,特征项权重则主要采用词频、对数频率权重、TF-IDF(term frequency-inverse document frequency)[26]和内部类频率[27]等计算方法。向量空间模型方法的特征项选择建立在词项组合和筛选的基础上,容易导致特征项数量,即特征空间维度过高,从而陷入维数灾难[28]。
基于主题模型的方法通过概率生成模型将高维词项空间映射到低维的主题空间,在降低空间维数的同时尽可能保留文本的主题语义信息,主题模型特征空间中的每个维度对应一个主题,而主题则通常是一组词的聚类。经典概率主题模型LDA(latent Dirichlet allocation)[29]依据“文档-主题”及“主题-词项”的先验分布来估计一个概率图生成模型,从而实现将“文档-词项”矩阵转化为“文档-主题”矩阵和“主题-词项”矩阵,该模型假设主题随机变量服从Dirichlet分布且主题之间相互独立,忽视了语料中不同主题之间的相关性。有些研究针对LDA模型的假设缺陷进行了优化。例如,模型CTM(correlated topic model)[30]假设主题随机变量符合逻辑斯蒂-正态概率分布,模型CGTM(correlated Gaussian topic model)[31]则运用词潜入技术把主题描述为向量空间中的多维高斯分布。也有些研究则在文档、主题、词项之外引入新的建模变量,如情感主题模型[32]、链接主题模型[33]、作者主题模型[34]等。
基于图的文本表示方法的核心思想是依据某种规则将自然语言文本转化为图结构,图中的节点为文本单元,边则表示文本单元之间的关系,文本单元节点和边类型的不同是该系列方法间的主要差异来源,常见的文本单元节点包括字、词、短语、实体、句子等,边关系则可以考虑共现关系、句法关系和语义关系等。例如,TextRank模型[35]将名词、动词、形容词等组合起来构造关键词节点,然后采用关键词共现关系构建节点之间边。
基于知识库的文本表示方法主要借用外部知识库中的文本关联关系对文本进行表示建模,相较于其他方法,其构造的语义特征空间更符合人类认知。例如,ESA(explicit semantic analysis)模型[36]利用维基百科知识库中的概念构造语义特征空间,NTEE(neural text-entity encoder)模型[37]则在DBpe‐dia摘要语料和维基百科语料上捕捉词、实体之间的语义联系,构造文本和实体的表示向量。
基于神经网络的方法利用多层深度神经网络的语义特征抽取能力,能够从海量无监督数据中逐级学习文本的有效特征表示,当前该方法研究的主要优化思路包括神经网络架构优化和无监督训练任务优化。其中,前者发展出LSTM(long short-term memory)、CNN(convolutional neural network)、Transformer等神经网络模型架构,而后者发展出word2vec(中心词预测和邻居词预测)[38]、BERT(邻居句预测和掩码预测)[39]、ALBERT(a lite BERT)(句子顺序预测)[40]、BART(bidirectional and auto-regressive transformers)(句子排列)[41]、PEGASUS(pre-training with extracted gap-sentences for abstractive summariza‐tion sequence-to-sequence models)(空白句填写)[42]等研究工作。
相较于其他文本表示方法,基于神经网络的方法具有更强的表征能力,近期的大语言模型研究表明,拓展网络深度和增大模型参数能够极大地改善模型表征能力上限,并在零样本学习、少样本学习等任务上展现了令人惊叹的优势[43]。
1.2 学术文本表示学习研究
不同领域中语言可能呈现截然不同的特质,有必要开展针对特定领域的文本表示学习研究。相较于社交媒体、文学小说、商务信件等日常生活类文本,学术文本具有语言结构规范、词汇语义丰富、概念关系复杂等特点。如何充分挖掘学术文本间的关系、有效进行学术文本特征表示始终是情报学、语言学、计算机科学等学科领域的重要研究内容[44]。
根据处理文本粒度的差异,学术文本表示研究可分为词汇层次、句段层次和文献层次。其中,词汇层次研究学术词语的数学表示方法,主要用于学术词语功能识别[9]、学术实体标注[45]、学术实体链接等任务;句段层次研究学术文本句子或段落的向量表示方法,主要用于学术文本句子分类[46]、学术文本段落结构功能识别[47]、学术段落检索等任务;文献层次的学术文本表示是研究如何构建文献整体层面的语义表示方法,它与文献分类、学术搜索和论文推荐等下游任务具有天然的适配性,因此,当前学术文本表示研究焦点已从词汇句子层次转移到文献层次[48-50]。
文献[13] 通过在大规模学术文献语料库(生物医学和计算机科学)上微调BERT神经语言模型参数,构建了面向学术文本表示的SciBERT模型,并使用SciBERT模型抽取文献标题和摘要文本的语义向量作为文献层次的表示向量。文献[44] 使用无监督图神经网络方法,从学术文献关系网络(引文网络、共被引网络和文献耦合网络)中学习通用的学术文献特征表示向量,与SciBERT模型强调文本字面语义关系不同,该方法抽取的是文献间的结构关系特征。文献[13] 提出一种SPECTER模型,该方法结合文献间的相互引用关系构建训练数据微调Sci‐BERT模型,从而将文献间的结构关系特征融入文本语义向量。
从自监督对比学习的视角来看,SPECTER模型成功的关键在于采用学术文献间的关系构造代理任务(pretext task),且通过三元组对比损失将目标(query)文献与正样本(positive)文献的距离拉近,而将目标文献与负样本(negative)文献的距离拉远。文献[51] 指出如何有效挖掘正样本文献以及负样本文献的选择是影响学术文献表示学习的关键,SPECTER模型将目标文献引用的文献作为正样本,将随机文献作为目标文献的负样本,这种采样方法有两个缺陷:①引用文献的动机是复杂的,被引文献与施引文献不一定在语义内容上十分相关;②随机负样本文献不一定与目标文献无关,即不精准的采样方法会引入噪声训练样本,从而影响模型最终的性能。针对上述问题,本文提出了一种新的引文共现层次采样算法,可以有效地排除噪声训练样本,弥补SPECTER模型采样方法的缺陷。
2 模型架构与算法
2.1 模型概述
对于给定的文献集合D=(d1,d2, …,dn),di是D中的一篇文献,文本表示学习的目标是找到一个映射函数F,对于任意文献di可将其表示为k维向量,即F(di)→(x1,x2,…,xk),且该语义向量可适用于不同的下游任务。已有研究表明,自监督对比学习框架能够对学术文本进行有效语义表征[13],挖掘文献间的引用关系有利于优化文献层次的学术文本表示[51]。受此启发,本文采用自监督对比学习框架,提出了一种基于引文共现的层次树采样算法,从结构化全文数据中挖掘文献间的潜在关联,构造自监督前置训练任务用于训练文献级的学术文本表示模型,模型总体框架如图1所示,主要包括3个部分。
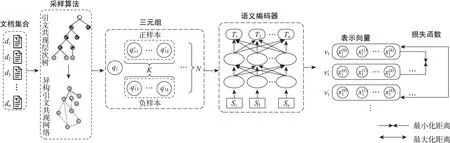
图1 模型总体框架
(1)引文共现层次采样算法。该模块从结构化全文数据中挖掘不同层次的引文共现关系,构建引文共现层次树,然后融合成异构引文共现网络,并进行采样构造三元组训练数据(q,q+,q-)。
(2)语义编码器。该模块采用Transformer神经网络架构,对输入的学术文本进行特征抽取,将di∈D映射为特征空间中的特征向量vi=(x1,x2,…,xk)。
(3)三元组对比损失函数。该模块定义了模型的优化目标,使训练数据中相关样本(q,q+)的特征向量距离缩小,不相关样本(q,q-)的特征向量距离拉大。
2.2 引文共现层次采样
自监督对比学习中,三元组(q,q+,q-)是指由3个样本构成的一条训练数据,其中q称为目标样本,q+和q-分别为正样本和负样本。在本文中,若q是给定的一篇学术文献,q+代表与q相关/相似的学术文献,q-则可以代表:①与q不相关/不相似的文献,常称为简单负样本;②与q相关/相似但相关/相似程度小于q+的文献,又称困难负样本。已有研究表明,自监督对比学习易受前置任务即三元组训练数据挖掘的影响[40,49];具体而言,对于任意目标文献q,如何定义相关与非相关,并从无标注数据中选择正样本q+和负样本q-,是利用对比学习有效进行学术文本表示的核心问题。文献[51] 认为,若目标文献q引用了文献q+,则两者相关且q+可作为三元组中的正样本;若目标文献q未引用文献q-,则q-可作为三元组中的负样本。本质上,是将文献引用看作语义相关,而无引用关系看作语义无关,然而目标文献q引用的文献q+不一定与文献q语义相关,而文献q未引用的文献q-也可能与q语义相关,因此,该方法易导致引入噪声数据。考虑到研究者在书写学术论文时往往将相似的参考文献并列/近邻论述,即相关文献在学术文献结构化全文数据中分布距离较近,本文提出了一种引文共现层次采样算法,具体如图2所示。该算法将文献的篇章结构转换为引文共现层次树,然后对多文献的引文共现层次树进行融合构造异构引文共现网络,最后基于异构引文共现网络进行正负样本采样,具体如下。
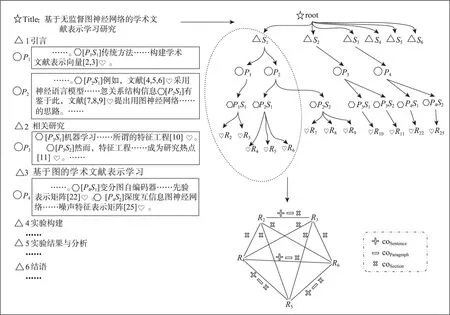
图2 引文共现层次采样
(1)单文献引文共现层次树构建。对于文献集合中的每一篇文献d,其参考文献列表记为REFL=(ref1,…,reft),依据参考文献REFL在文献d的篇章结构布局构建引文共现层次树tree(d),具体过程如下:首先,将文献标题作为根节点,并以章节标题作为根节点的子节点,即章节层子节点;其次,对于每个章节节点,将该章节下的每个段落作为对应章节节点的子节点,即段落层子节点;再其次,对于每个段落节点,将该段落中的每个句子作为该段落节点的一个子节点,即句子层子节点;最后,对于每个句子节点,将句子中包含的参考文献(引文)作为句子节点的叶子节点。对于任意引文refi和refj且i,j∈(1,t),若refi和refj拥有同一个章节祖先节点,则称refi和refj为章节共现;若refi和refj拥有同一个段落祖先节点,则称refi和refj为段落共现;若refi和refj拥有同一个句子父节点,则称refi和refj为句子共现。
(2)跨文献引文共现融合。对于文献集合D=(d1,d2, …,dn)中所有文献均可构建对应的引文共现层次树tree(di),i∈(1,n)。算法第二步以所有引文共现层次树为输入,输出一个异构引文共现网络G,网络G中的节点v为文献集合D中出现的参考文献,网络的边etype=(refi, refj), type∈{coSection,coParagraph, coSentence},分别表示文献refi和refj曾经同时在某文献的章节/段落/句子中共现。对于引文共现层次树tree(d),遍历该树上的所有参考文献节点refi∈REFL,若网络G中不存在refi,则在G中添加refi。从tree(d)中任取两个参考文献节点refi和refj,若两者在tree(d)中句子共现,则在网络G中添加边(refi,coSentence, refj);若两者在tree(d)中段落共现,则在网络G中添加边(refi,coParagraph, refj);若两者在tree(d)中章节共现,则在网络G中添加边(refi,coSection,refj)。对文献集合D中所有文献的引文共现层次树重复上述操作,即可完成异构引文共现网络G的构造。
(3)训练数据采样。给定异构引文共现网络G=(V,E),V表示网络中的节点集合,即文献集合D包含的所有参考文献;E表示网络中节点间存在的边,即任意两节点在文献集合D中是否存在章节/段落/句子共现。对于一篇目标文献q,在异构引文共现网络G中,随机选择K个邻居节点作为正样本q+,随机选择K个非邻居节点作为负样本q-,即构建K个三元组训练数据。同理,对于一组N个目标文献,重复上述过程构建N×K个三元组数据。
2.3 语义编码器
语义编码器是一个能够将学术文献d的文本转换为k维向量v=(x1,x2,…,xk)的神经网络,理论上该模块可采用任意神经网络模型,鉴于Transformer架构[52]在自然语言处理任务中的优异表现,本文基于Transformer模型构建了具有提取上下文功能的语义编码器Encoder,Transformer模型能够利用自注意力机制捕获单词之间的长距离依赖关系,并根据上下文信息动态调整词嵌入,相较于其他文本特征表示模型表现更好。学术文献全文的长度一般在8000~10000单词,超出了绝大多数Transformer模型的处理能力,考虑到文献的标题和摘要提供了全文的简洁而全面的概括,本文用特殊分割符[SEP] 将标题文本和摘要文本拼接起来,输入语义编码器获取文献的特征表示,即
2.4 对比损失函数
自监督对比学习框架中,损失函数定义了模型优化的方向,它指导语义编码器Encoder调整神经网络层中的权重,输出更符合优化目标的表示向量。本文采用三元组对比损失作为目标优化函数,其公式为
其中,vq、vq+、vq-分别表示目标文献q、正样本文献q+和负样本文献q-的表示向量,对应于文献在语义编码器上的输出向量。m表示用于控制正负样本距离间的偏离量,使模型不需要考虑优化过于简单的负例。dist(*)是距离函数,本文采用欧几里得距离,表示文献i特征向量第m维的数值,计算公式为
3 数据与实验设置
3.1 数据及预处理
本文使用艾伦人工智能研究院(Allen Institute for AI)发布的S2ORC(The Semantic Scholar Open Research Corpus)数据集[53]抽取数据训练模型,数据集静态存储版本为20200705v1。该版本数据集包含8100万篇学术文献元数据,其中1200万篇文献存在结构化的全文数据,囊括文献ID、标题、摘要、章节标题、段落文本、参考文献列表及参考文献出现的位置等信息。首先,遍历1200万篇全文文献数据,依据2.2节中的单文献引文共现层次树构建及跨文献引文共现融合方法,构造异构引文共现网络G,该网络共有52620852个节点和2216391068条边。其次,从SPECTER的训练集三元组中抽取所有目标文献的标题,并通过文本匹配获取其在S2ORC数据集中对应的文献ID,共计获取目标文献261821篇。最后,以上述文献ID作为三元组采样的目标文献集合,采用2.2节中介绍的训练数据采样方法构造三元组数据,每个目标文献采样5个正样本和5个负样本,共计构造1309105个三元组。具体实验中,进行了多组采样策略,每组采样策略均构造1309105个三元组,然后训练对应的模型,采样策略设置详见3.3节。
3.2 评测任务和指标
本文采用SciDocs基准测试集[8]对实验结果进行评估,该测试集包含论文分类、用户行为预测、引文预测和论文推荐四类任务,每个任务均不对学术文献表示向量进行额外微调,而是直接将文本表示模型输出的表示向量作为输入特征执行任务。例如,在论文分类任务中,每篇论文被文本表示模型转化成向量后与一个简单分类器相连,执行分类并汇报结果。在引文预测任务中,成对的文献被文本表示模型转化成两个向量,然后与一个分类器相连进行二分类,其中,0表示两个文献没有引用关系,1表示两个文献存在引用关系。除文本特征由文本表示模型抽取外,其他具体任务均由SciDocs评测脚本执行,以保证评价的公平性。论文分类包含MeSH(medical subject headings)医学主题词分类[54]和MAG(Microsoft academic graph)领域标签分类两个子任务,其任务评价指标为F1值,计算公式为
其中,Precison表示精确率;Recall表示召回率;F1值的取值范围在0到1之间,越接近1,代表模型的分类效果越好。
用户行为预测包括co-view共浏览和co-read共阅读两个子任务。co-view共浏览旨在预测用户在同一会话中浏览的文献集合,co-read共阅读则是预测用户在观看某篇文献页面时是否会点击其他文献的获取链接。该类任务采用nDCG(normalized dis‐counted cumulative gain)和MAP(mean average pre‐cision)两个指标进行评价。nDCG值越大,代表模型的排序效果越好,即推荐结果和用户真实兴趣度的匹配程度越高;MAP反映的是平均精度,越接近1,说明排序效果越好。计算公式分别为
其中,f(di)表示文献di的价值得分;K表示截取文献数;|R|表示按价值得分从大到小排列的前K条文献;AP值表示Precision和Recall曲线下的面积;N表示相关样本总数。
引文预测任务分为引用预测和共引预测,即给定某篇文献,预测其引用文献和共引文献,该类任务也采用nDCG和MAP两个指标进行评价。论文推荐任务是根据查询文献向用户推荐相似文献列表,并通过点击事件获取用户反馈,该任务采用倾向调整P@1和两个指标进行评价,计算公式分别为
其中,R@1表示排在第一位的文献是否与用户的查询相关,相关则其值为1,否则为0;T@1表示在模型返回的排序结果中,排在第一位的文献总数;P@1表示第一篇文献的预测准确率;N表示多个查询总数;nDCGn表示第n个查询的nDCG值;值通常用于评估排序算法的性能。
SciDocs基准测试集的数据构建及任务详情参见文献[14] 。
3.3 实验设置与对比基线
为了回答引言中提出的两个研究问题,本文基于以下采样策略训练了多个模型。
(1)随机采样。按照2.2节所述,对于每一个目标文献随机从异构引文共现网络取5个邻居节点作为正样本,随机取5个非邻居节点作为负样本。基于随机采样可构建三元组训练模型,记为CCHT(Random)。
(2)正样本固定层次采样。在随机采样的基础上,限制正样本邻居节点必须来源于同一类边。例如,固定正样本采样层次为同句共现时,在异构网络中找到与目标文献相连且类型为coSentence的边,并以这些边连接的邻居节点为候选集合,随机抽取5个作为正样本,且负样本采样随机采样。分别固定正样本采样层次为句子共现、段落共现和章节共现,可构建三个三元组集合,基于不同三元组集合分别训练3个模型,记为CCHT(Sentence)、CCHT(Paragraph)、CCHT(Section)。
(3)困难负样本采样。已有研究表明,选择与目标文献完全不相似的随机负样本无法为模型训练提供有效梯度,在采样过程中引入困难负样本有利于特征表示学习[14]。考虑不同层次共现关系,本文设计了一种困难负样本选择方法,具体如下:Q+表示与目标文献q句子共现的文献集合,Q-表示与目标文献q段落或章节共现的文献集合,表示目标文献q的非共现文献集合,取q+∈Q+为正样本,正样本数量为5;取q-∈Q-为困难负样本,困难负样本数量为kq-;取为简单负样本,简单负样本数量为5-kq-。此时,研究假设相较于段落或章节共现的文献,句子共现的文献具有更高的语义相似度。为分析困难负样本数量对模型的影响,kq-的取值设置为[1,2,3,4,5] ,并基于不同三元组集合训练5个模型,分别记为CHTT(0.2)、CHTT(0.4)、CHTT(0.6)、CHTT(0.8)和CHTT(1.0),括号中的数值表示困难负样本占总负样本的比例。
随机采样和正样本固定层次采样策略均采用引文共现层次关系假设,即在相同的章节、段落或句子内共同引用的论文更相似。困难负样本采样策略则采用引文邻近关系假设,即句子共现的文献比段落或章节共现的文献更相似。
语义编码器采用Transformer模型架构,模型架构参数与SciBERT[13]相同,包括12层Transformer网络,每层的隐藏状态尺寸为768,每层包含12个自注意力头。实验采用Adam优化器进行模型训练,学习率设为2e-5,dropout始终保持为0.1,beta1设为0.9,beta2设为0.999,batch size设置为8,且使用梯度累计技术将实际批次大小增大到256,每个模型均在V100 GPU上进行两个周期的迭代训练,即epoch=2。模型在2个V100 GPU上进行并行训练,每个迭代周期耗时约25小时。
本文与多个基线方法进行了比较,包括基于词向量的通用文本表示方法doc2vec[55]、FastText-sum[56]、SIF(smooth inverse frequency)[57]、ELMo[5]和Citeo‐matic[58],基于图卷积的通用文本表示方法SGC(simple graph convolution)[59],基于句向量的通用文本表示方法Sentence-BERT[60],学术文本表示方法SciBERT[13]和SPECTER[14],以及非监督对比学习表示方法Unsup-SimCSE(simple contrastive sentence embedding)[61]、Contriever[62]和DiffCSE(differencebased contrastive learning for sentence embeddings)[63]。
4 结果与分析
4.1 模型对比实验分析
表1汇总了各模型在SciDocs测试集各任务上的效果。总体而言,可以观察到本文提出的CHTT(Random)学术文献表示模型在所有任务上均取得了显著的改进,所有任务指标的平均值为81.1,比次优基线(SPECTER)提高了1.1。
对于MAG分类任务而言,SPECTER性能表现最优,F1值为82;其次是CCHT(Random),F1值为81.1,比SPECTER略低。在MeSH分类任务中,CCHT(Random)得分最高,其F1值高达88.9,比SPECTER高出2.5。此外,针对所有的用户活动预测和引文预测任务,CCHT(Random)相对于所有基线表现更为出色。最后,就推荐任务而言,SPEC‐TER的P@1指标表现最佳,达到了20,而CCHT(Random)的P@1指标得分为19.3。然而,在指标方面,CCHT(Random)表现与SPECTER相当。
本文旨在评估CCHT方法中三元组训练数据集选择对性能的影响。结果显示,基于引文共现的层次树采样算法可以明显提升SciDocs测试集任务上的性能表现,特别是在用户行为预测和引文预测任务上的提升效果最为明显。由表1可以发现,平均性能分数从80.0提升至81.1,其提升效果较为显著,这有助于在实际应用中为学术界和产业界提供更加准确可靠的分类、推荐、用户行为预测和引文预测服务。
4.2 正样本采样层次的影响
表2展示了3个学术文献表示模型——CCHT(Sentence)、CCHT(Paragraph)和CCHT(Section)与最优基线SPECTER在SciDocs测试集任务上性能表现。总体而言,CCHT(Sentence)、CCHT(Paragraph)和CCHT(Section)在所有指标上的平均性能达到了81.3、81.2和81.1,比之前最先进的SPECTER模型分别提高了1.3、1.2和1.1。由表2可知,CCHT(Sentence)性能优于CCHT(Paragraph)和CCHT(Sec‐tion),这说明句子共现相关性>段落共现相关性>章节共现相关性。因此,句子共现、段落共现和章节共现这3种不同层次的相关性明显会影响到学术文献的表征学习,进而导致模型在SciDocs各任务中的性能变化。

表2 正样本固定层次采样模型在SciDocs测试集上的评价结果
对于MAG分类,SPECTER表现效果最好,F1达到了82.0;其次是CCHT(Section),F1为80.9,降低了1.1。对于MeSH分类,CCHT(Section)得分最高,F1为88.9,比SPECTER(86.4)高出2.5。在用户活动预测(user activity prediction)任务中,CCHT(Sentence)、CCHT(Paragraph)和CCHT(Section)模型的MAP和nDCG评分均高于其他基线。此外,对于引文预测任务,也存在类似的趋势,本文模型的性能表现均超过了SPECTER。在推荐任务上,CCHT(Sentence)在该任务上的表现明显优于SPEC‐TER(次优基线),和P@1分别达到了54.7和20.8。
总之,本文的研究结果表明,基于不同细粒度层级的共现关系对CCHT模型的性能至关重要,均会使其在SciDocs测试集上的性能得到提升。
4.3 困难负样本采样比例的影响
图3显示了当困难负样本采样比例取值分别为0、0.2、0.4、0.6、0.8和1.0时,CCHT(Sentence)模型在SciDocs测试集中4个任务上的平均性能变化趋势。当困难负样本采样比例逐步增大时,模型在论文分类、用户行为预测、引文预测和论文推荐四类任务上的指标平均值均呈现下降趋势,且当困难负样本数量取值为0时,模型性能达到峰值。
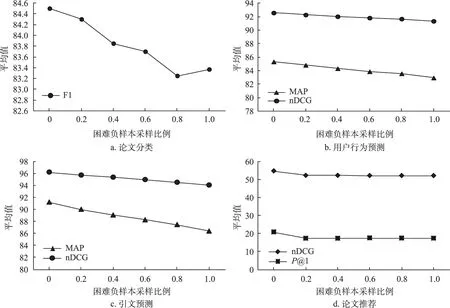
图3 困难负样本采样比例在SciDocs测试集上的结果变化趋势
Cohan等[14]已证实在采样过程中引入有效困难负样本有利于特征表示学习。本文假设,相较于段落或章节共现的文献,句子共现的文献具有更高的语义相似度,并基于此进行困难负样本采样。研究结果表明,该方法易引入噪声数据,导致模型性能随困难负样本比例升高而降低。CCHT(Sentence)模型的困难负样本候选集Q-是与目标文献段落或章节共现的文献集合,理论上来说,研究者在书写学术论文时,往往将相似的参考文献并列/近邻论述,即同句中的参考文献相关性更高,而困难负样本与目标文献距离较远,相关性更低。但实际上,由于各研究者思维逻辑和书写风格的多样化,在学术文献结构化全文数据中,分布距离较远的文献之间相关性也可能较高。例如,在图4中,假设目标文献q取11,则其困难负样本集合Q-为(50, 51),由该片段可知,q与Q-均表示被引量预测主题相关研究,即目标文献与困难负样本之间的语义相似度并不如理论而言是较低的;反之,是较高的。因此,本文在异构引文共现网络中,根据层次采样引入困难负样本,容易导致引入噪声数据,从而影响模型最终性能。

图4 同段落文献结构片段(截取自文献[64] )
4.4 可视化分析
为进一步深入分析CCHT模型的表达性,本文利用t-SNE(t-distributed stochastic neighbor embed‐ding)算法在SciDocs文本分类任务MeSH数据集上执行可视化,Unsup-SimCSE、SPECTER以及CCHT这3个模型抽取的学术文献表示向量被投影为二维平面中的点,具体如图5所示,图中点的颜色代表文献原本所属的医学类型。由图5可知,非监督对比学习表示方法Unsup-SimCSE在不同类之间呈现模糊的边界,难以学习到判别性强的低维表示。针对已有方法中最优模型SPECTER,虽然多数类型的节点被清晰地分类,但部分类别间仍然存在一定重叠,少数类型数据点无法被清晰地识别。本文的CCHT模型将点清晰地划分成不同的部分,即CCHT模型的表示向量具有更显著的区分能力,CCHT模型有能力将同类型的文献投射到距离相近的空间中,并将不同类型文献间的距离拉开。

图5 不同方法表示向量的可视化分析(彩图请见https://qbxb.istic.ac.cn)
5 结 语
有效进行学术文本特征表示,是实现学术文献的分类、组织、检索和推荐的关键。本文将图情领域的引文共现层次关系假设[16]及引文邻近关系假设[15]引入自监督对比学习框架,提出一种基于引文共现层次采样算法的学术文本表示学习方法,在SciDocs基准测试集上,针对论文分类、用户行为预测、引文预测以及论文推荐四大下游任务进行了相关实验。实验结果表明,CCHT(Random)模型在SciDocs基准测试集中性能优于其他先进的基线模型,且比已有研究的最佳模型SPECTER提高了1.1,即引入引文共现层次关系假设能够有效提升学术文献表示学习模型效果。针对引文邻近关系假设(句子共现的文献比段落或章节共现的文献更相似),本文通过引入困难负样本采样构造三元组训练模型。实验结果表明,该方式易引入噪声数据,即引文邻近关系假设在学术文献表示学习研究中不完全成立。这可能是因为本文定义的困难负样本为同段/同章共现引文,这些文献之间的语义关系十分接近,在构建正负样本对时容易出现对撞数据,即目标文献与正样本的距离大于目标文献与负样本的距离,在模型训练过程引入了噪声数据,从而影响了模型最终的性能。如何排除困难负样本中的噪声数据是后续研究可改进的方向之一。
此外,受限于GPU计算资源,本文根据经验设置了部分超参数,如实验中对每个目标文献仅采样k=5个三元组数据,改变超参数设置可能也会对模型训练产生积极影响,值得进一步探索。另外,如何考虑文献共现次数构建加权异构共引网络,改进三元组采样也是值得探索的研究方向。最后,在对比学习框架下损失函数是关键核心组件,设计更适合于学术文献表示学习的对比损失函数是未来研究的重要方向之一。
