基于带噪声数据集的强鲁棒性隐含三元组质检算法*
2023-08-31王梓铭张思佳安宗诗
王梓铭 张思佳,2 安宗诗
(1.大连海洋大学信息工程学院辽宁省海洋信息技术重点实验室 大连 116023)
(2.设施渔业教育部重点试验室(大连海洋大学) 大连 116023)
1 引言
知识图谱的基本存储单元是三元组,三元组由头部实体、关系和尾部实体组成。三元组之间通过关系联系在一起从而构成一张巨大的有向图。DBpedia[1]、NELL[2]等大型知识库均是从多个网站上爬取,清洗制作得到的,其复杂的知识结构往往难以有效的进行质检和分析。制作知识图谱过程中往往会引入一些噪声数据,如虚假的关系,错误的实体,甚至无中生有的三元组。由于制作知识图谱过程各种不可避免引入噪声三元组,这些三元组破坏了知识图谱的网络结构,使得知识难以得到有效的展示,基于知识图谱的知识推荐和搜索会产生致命错误。
为对知识图谱进行有效质检,Ruobing Xie[3]等提出的三元组置信度算法,三元组的置信度可在图谱构建前后进行,置信度计算的结果隐含了知识图谱的内部特征和三元组之间的隐含信息。Shengbin Jia[4]等基于深度学习模型将三元组的内部语义特征、节点的全局语义依赖信息、以及三元组组成要素之间的可信度整合在一起,构建强鲁棒性的噪声三元组质检算法,其性能远远超出了传统的TransE[5]、TransR[6]等算法。Yu Zhao[7]等将头尾结点实体词向量表示进行了一定的扩充,主要是考虑到实体本就包含了丰富的语义信息。Shengbin Jia和Yu Zhao等均将Trans系列算法作为基础算法,在多个层次上对实体和关系向量进行整合达到较好的结果。但是目前的知识图谱质检存在如下问题:1)大多数学者均是基于常见的开源知识图谱设计质检算法,人为构建噪声数据集,将知识图谱的质检转换成常见的分类任务,噪声数据集的构建缺乏有效的方法;2)复杂的知识图谱如FB15K-237 知识图谱包含237 种关系,三元组之间具有复杂的关系传递[8],仅以孤立的三元组作为正样本,会极大削弱知识图谱包含的知识。本文提出的算法能够有效解决以上问题,主要创新点如下:
1)提出基于搜索深度的关系强弱表征方法。复杂知识图谱节点之间通过关系进行链接,基于链接深度,本文将每个三元组赋予预置权重,表征三元组为真实的置信度;
2)使用基于有向图的深度搜索算法,搜索所有可能的路径,基于搜索路径构建新的三元组,用以扩充源三元组的规模;
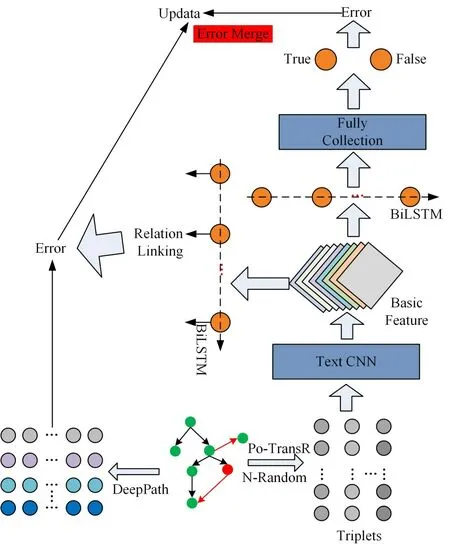
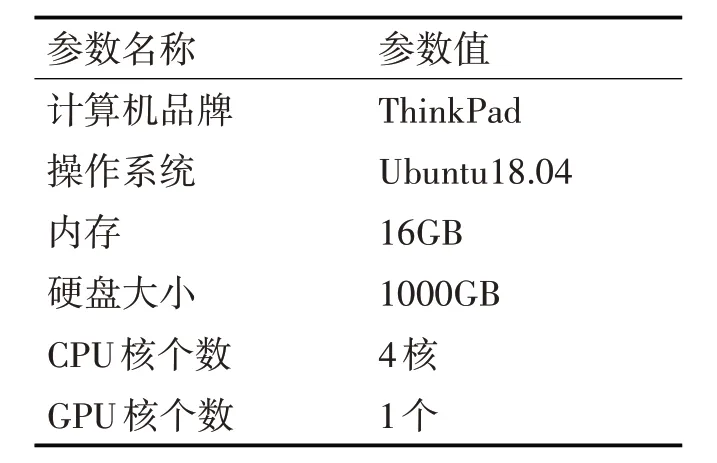
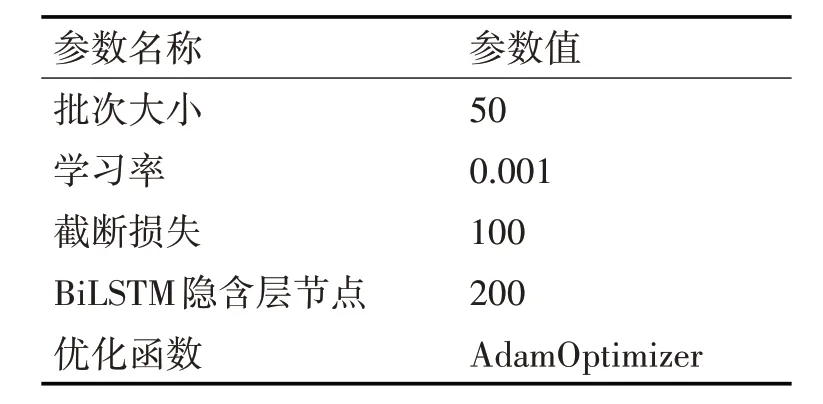
3)基于扩充的三元组构建噪声三元组,本文构建的噪声三元组有三种,分别是替换头实体<?,r,t>、替换关系 4)本文使用基于TransR 对扩充后的真实三元组进行预训练,得到实体和关系的初始表达,然后使用多种深度学习算法对三元组建模,特征融合最后完成质检。 本文中隐含三元组是指复杂知识图谱中,实体之间的关系传递导致实体之间存在间接关系,基于关系传递构建的新三元组被称为隐含三元组。为更准确的挖掘知识图谱节点之间的隐含语义关系,本文首先对数据集进行预处理,得到隐含三元组数据集,对源图谱中的三元组进行扩充。 首先基于FB15K-237 数据集构建Neo4J 数据库。以实体为搜索起点,搜索以该实体为起点的最长有向路径。遍历数据集的所有实体,得到所有搜索路径,然后删除被包含的子路径,最终得到互不包含的所有路径,并构建实体-关系矩阵E。基于实体关系矩阵利用关系传递方向构建隐含三元组。实体-关系矩阵E如式(1)所示。 其中,sigi,j={0,1},D 是数据集中不重复实体的数目,sigi,j是实体Eni与Enj之间的关系,sigi,j=0,表示这两个实体之间无关联,sigi,j=1,表示这两个实体之间有关联。由于该矩阵是基于有向图搜索得到的,三元组 由于每一条搜索路径均要求相邻节点之间存在有向边,且由头部实体指向尾部实体,故本文基于有向搜索路径构建基于搜索深度的三元组置信度矩阵,该置信度矩阵用来标识每一个三元组中头部和尾部实体关联强弱。考虑到某些实体可能同时包含于多条搜索路径,且由于深度不同造成置信度计算混乱,为解决这个问题,本文只以矩阵E 标识的最长搜索路径为基准计算构建的隐含三元组的置信度,每条最长搜索路径之间相互独立。置信度计算方式如式(3)所示。 其中,F 指包含三元组<Eni,sigi,j,Enj>的最长搜索路径个数,dk指当前三元组在当前所属三元组中的搜索深度,pk是当前搜索路径总长度,即包含三元组的个数,L 是所有最长搜索路径的最大长度,通过参数L将所有的置信度进行归一化。 正三元组。本文中,正三元组指头部和尾部实体间存在直接或传递关系而构成的三元组。正三元组的来源有两种:1)训练集提供的原始三元组;2)基于式(1)生成的隐含三元组。 噪声三元组。噪声三元组是指不与正三元组有交集,并且不包含于扩充的知识图谱的假三元组。为充分检验本文算法对知识图谱的质检效果,本文集每个原始数据集构建三套噪声数据集,分别是 HR_FAKE_T、 H_FAKER_T、 FAKEH_R_T。HR_FAKE_T是在正三元组基础上随机替换尾部实体、H_FAKER_T 是在正三元组基础上随机替换关系、FAKEH_R_T 是在正三元组基础上随机替换头部实体。三套噪声数据集的构建过程如算法1 所示。 算法1 噪声数据集构建 //假设关系集合OR,正三元组集合OP,不重复三元组集合OT,不重复实体集合OE //假设原始数据集搜索路径集合OS,3套噪声数据集规模分别是j1,j2,j3 1)输入:OR、OP、OT、OS、OE、j1、j2、j3 2)输出:HR_FAKE_T、H_FAKER_T、FAKEH_R_T 3)For k in random(OP)/**Work in OP**/ 4) If length HR_FAKE_T 5) temp=Check(k.h,random(OE),k.t,0) 6)HR_FAKE_T←temp 7) Else pass 8) If length FAKEH_R_T 9) temp=Check(random(OE),k.r,k.t,1) 10)FAKEH_R_T←temp 11)Else pass 12)If length H_FAKER_T 13) temp=Check(k.h,random(OR),k.t,2) 14)H_FAKER_T←temp 15)Else pass 算法1 中,Check 函数分别实现对三种噪声三元组的选择,伪代码如算法2所示。 算法2 Check(选择噪声三元组) 1)输入:RTRIP、OR、OE、OS、find=True/**RTRIP 是传进来的随机三元组**/ 2)输出:噪声三元组 3)While 4) For triplets in OS 5) If 6) find=False Break 7) If find is True 8) Return 9) Else 10) If RTRIP.flag==0 11) RTRIP=(RTRIP.h,random(OE),RTRIP.t,0) 12) If RTRIP.flag==1 13) RTRIP=(random(OE),RTRIP.r,RTRIP.t,1) 14) If RTRIP.flag==2 15) RTRIP=(RTRIP.h,random(OR),RTRIP.t,2) 算法1和算法2实现了三种类型噪声数据集的选择和过滤,过滤条件包含两个:1)新产生的噪声三元组不应出现在经扩展的正三元组集合;2)新产生的噪声三元组不应出现在实体-关系关联矩阵E中。通过以上两种过滤方法,能够极大地避免噪声三元组的头部和尾部实体之间不存在传递关系。将正三元组和噪声三元组合并得到新的数据集。 由于FB15K-237 数据集内存在大量的1∶N 和N∶N 的关系,本文基于TransR 算法训练正三元组,得到实体和关系的向量表示,然后遍历三个数据集的噪声三元组,使用TransR 训练好的模型参数初始化所有的噪声三元组。所有正三元组的嵌入与其置信度进行内积,得到加权特征向量。 ITQI 算法的基本框架如图1 所示。其中,Po-TransR 表示基于TransR 算法初始化的正三元组,N-Random 表示噪声三元组。噪声三元组和正三元组均使用相同的维度的向量进行初始化。DeepPath是基于实体-关系矩阵构建的搜索路径。 图1 算法的基本框架 ITQI算法包含两个主要分支:当前批次样本的搜索路径矩阵建模和三元组质检分类建模。 当前批次样本的搜索路径矩阵建模。此分支的输入是经向量化的三元组,输出是当前批次三元组中每个实体与其他实体之间的关联关系矩阵。一个批次样本中,每个实体与其他实体间均在在两种互斥关联:存在间接关系或直接关系;不存在任何关系。ITQI 算法采用TextCNN 以及多层BiLSTM构成实体间互斥关系预测模型,学习实体间的直接关联和间接关联关系。 三元组质检分类建模。此分支的输入仍然是经向量化的三元组,输出是当前批次三元组的质检结果:真三元组、假三元组。 考虑到本文对知识图谱进行深度预处理时已经得到了一定规模的有向搜索路径,实体间的时空语义关联对实体向量的深层表示具有一定意义。王斌[9]等人使用TransE 训练三元组得到三元组的向量表示,基于三元组的向量分布及有向子图直接求解三元组的局部特征、全局特征以及包含语义的路径特征。本文使用多层BiLSTM实现对原始输入的空间语义关系进行建模,学习实体之间的局部关联关系;然后使用BiLSTM提取三元组的内部特征,最后使用局部损失和内部损失共同优化网络参数。局部特征建模输入如式(4)所示。 其中,B 指BatchSize,及当前训练的输入批次大小,a 是所有批次样本的关联深度,且a≤B,局部特征建模的目标输出标签如式(5)所示,标签含义如式(6)所示。 符号↦表示实体Eni和实体Enj之间不存在关联关系,两者的关联标签为0,符号→表示实体Eni和实体Enj之间存在关联关系,两者的关联标签为1。 本文算法中,局部特征建模过程中,通过多标签分类算法实体间关联关系的训练和预测,将不存在关联关系的实体进行区分,使用二分类方式实现真假三元组的质检。将两者的损失进行聚合共同优化网络参数。局部特征建模过程中实体关联关系损失如式(7)所示。 三元组质检为常见的二分类交叉熵损失[10~11],与式(7)合并之后得到总损失,见式(8)所示。 其中,y-表示三元组质检标签表示神经网络对每个三元组质检分类概率;yj表示局部特征建模过程中实体关联关系标签,pj表示神经网络对每个实体关联关系预测概率。 本文提出的ITQI 算法可在GPU 快速部署运行,与其他算法在CPU 上进行对比实验,对比实验的配置如表1所示。实验基本设置如表2所示。 表1 实验硬件条件 表2 实验条件设置 本文使用FB15K-237 数据集共有14541 种实体类别、237个关系、训练集272115组数据、验证集17535组数据和测试集20466组数据。 本文第3.2节使用基于有向最长路径搜索算法将所有实体之间有无关联关系映射至实体关系关联矩阵E,实体之间有直接关系或间接关系的均被认为能够构建为正三元组,基于矩阵E,极大的扩展了原有的正三元组,拓展后训练集的数据规模增加75179个三元组。 噪声三元组依据算法1 和算法2 进行构建,其三元组规模分别与各数据集的训练集、测试集和验证集规模基本相同。 本文实验所使用的对比算法如表5 所示。评估指标分别是:Accuracy、Precision、Recall-Score、F1-Score、Quality。这四个评估指标的计算公式直接调用Sklearn.metrics封装好的计算公式计算这四个指标值。Quality 指标时衡量三元组质检质量的评估指标,本文借鉴Shengbin Jia 等提出的计算Quality指标公式,将0.5作为三元组质检的分界线,即预测为正的三元组其概率如果小于0.5则认为预测错误,预测为正的三元组其概率如果大于0.5 则认为预测错误。对比试验与现有的较好模型TransE、TransR、TransD[12]、TransH[13]、PTransE[14]、KGTtm[15]、MLP和Bilinear[16]进行对比。 本文算法首先在FB15K-237 数据集上进行质检实验,实验对象分别如下: 1)正三元组+HR_FAKE_T; 2)正三元组+H_FAKER_T; 3)正三元组+FAKEH_R_T。 其 中HR_FAKE_T、H_FAKER_T 及FAKEH_R_T 等三个噪声数据集的创建已在前文进行详细介绍,三组实验的评估指标分别是Accuracy、F-Score、Precision、Recall 实验结果如图2 所示,实验结果汇总如表6所示。 表6 三个数据集上的实验结果 从本文算法在三个数据集上的实验结果可看出,本文实验具有较好的鲁棒性,四种评估指标下的实验结果均较高。为验证本文提出的ITQI 算法对实体间隐含关系学习的有效性以及对隐含三元组识别的准确性,ITQI 算法与Shengbin Jia 等提出的算法及其对比试验结果进行对比,评估指标为Recall 及Quality,ITQI 算法与对比算法实验结果如表7所示。 表7 对比实验结果 从表7 可看出,本文所提算法ITQI 在FB15K-237 数据集的三个扩展集上的实验结果优于其它算法在原始数据集上的实验结果。相对于其它对比算法的平均召回率和质检质量均值而言,本文算法在三个拓展集的召回率最大提升6.09%、最小提升2.92%;Quality 指标下的最大提升15.09%,最小提升12.09%;和KGTtm-、PTransE-以及TransR-相比,本文算法召回率最大提升7.275%,最小提升0.201%;Quality 指标上最大提升14.98%,最小提升1.251%。基于以上对比结果,本文算法在两个对比指标上的平均提升率和在单个对比算法上的提升率均为正,实验表明本文算法具有一定的优势。 针对现有三元组质检算法极少考虑到知识图谱中由于关系转递存在的大量隐含三元组对质检效果的影响,本文提出基于带噪声数据集的强鲁棒性隐含三元组质检算法ITQI,首先对FB15K-237数据集进行了扩充得到更大规模的三元组,并使用算法1和算法2分别生成三组噪声数据集。通过本文算法与对比算法在数据集上的实验表明,本文算法具有更高的准确率,且优于其它算法。从评估指标对比结果来看,本文算法在正三元组+FAKEH_R_T 这类数据集上有更高的召回率,三元组的质检质量更高。2 隐含三元组
3 ITQI算法
3.1 三元组构建及初始化
3.2 ITQI算法基本框架
4 ITQI算法对比实验
4.1 实验环境
4.2 数据集
4.3 实验


5 结语
