基于数据增强和ViT的印章识别方法研究
2024-05-06张志剑夏苏迪刘政昊王文慧陈帅朴霍朝光
张志剑,夏苏迪,刘政昊,王文慧,陈帅朴,霍朝光
(1. 武汉大学信息管理学院,武汉 430072;2. 武汉大学大数据研究院,武汉 430072;3. 武汉大学信息资源研究中心,武汉 430072;4. 南京中医药大学卫生经济管理学院,南京 210023;5. 中国人民大学信息资源管理学院,北京 100872)
0 引 言
我国印章文化源远流长,最早的印章可以追溯到殷商晚期三方铜印,著录于《邺中片羽》,距今约有3700年历史[1]。印章文化流行于战国时期,其功能、章法和规制在隋唐时期初步形成并不断完善,与诗歌、绘画和书法共同构成我国重要的四大传统艺术形式。恰如黄宾虹[2]所言,“一印虽微,可与寻丈摩崖、千钧重器同其精妙”。印章文化不但展示了中华民族独特的审美特质和情怀,也传承和弘扬了中华文化的精神内涵[3]。印章通常可以分为官印和私章两种,作为一种身份凭证,被广泛应用于权利和身份认证、财物封存和文书递送等场景[4]。当下的印章文化更多在于文化传承上,用于寄托主人的志趣。由于书法绘画作品通常具有极高的鉴赏和收藏价值,历代藏家都会悉心保存,作品上的印章也能够得以保留。因此,观赏和了解印章有助于人们领悟作品背后的文化内涵,提高自身审美修养和艺术鉴赏能力,增强民族文化自豪感。
篆书是一种具有结构规整、笔画长短精确、形态简洁美观等特点的字体,它通过篆刻技艺应用于印章上,能够确保印文的清晰、准确和规范。然而,与简体字相比,篆书的使用场景较为有限,不再被人们所熟知。此外,印章作为主人的一种精神寄托,通常体现主人的巧思和独特性。在印章内容和布局的设计上,人们更加注重创新和个性化。因此,印章的样式千差万别,每个印章都有其独特的魅力。此外,还演变出了象形印章。但上述情况也增加了人们理解印章的难度。在公众欣赏书法字画时,常常会看到大量复杂的印章,这些印章记录了作品的创作信息和历史流传过程。只是这些印章主要为篆书或象形表示,非专业人士往往难以辨识。现有的识图软件和方法无法识别印章内容,而通过翻阅专业印章书籍来识别印章不仅耗时耗力,往往还难以得到满意的结果,导致欣赏者在面对印章图像时产生沮丧感,失去了欣赏书法字画的兴趣,这也是导致中国传统文化艺术作品不易推广的重要原因之一。因此,急需一种印章图像识别方法,降低用户的理解与鉴赏的负担,并激发公众对传统文化艺术的兴趣,推动中华传统文化的传承和发展。
由于印章类别繁多,印章识别任务属于超多分类问题,只有当印章数据充分时,神经网络模型才能发挥其较强的特征提取能力,从而准确地识别不同印章。然而,古代印章存世数量有限,而多次出现的印章也较少。因此,在训练集数据缺乏的情况下,难以对神经网络模型进行充分训练。数据增强方法可以通过对有限的数据进行变换得到新的数据,在保证标签不变的前提下,可以对数据集进行扩展。但是数据增强方法并非总是有效的,当数据存在较多噪声和错误标签时,数据增强方法在扩充数据集的同时也将噪声和错误进行了放大,导致模型学习到错误信息。某些任务无法通过数据增强捕捉到数据的关键信息,例如,在医学影像任务中,病变的形状和位置具有较强的多样性,常规的数据增强无法满足需求。一枚相同的印章在钤印和传承过程中受到不同因素的影响,表现出较强的多样性;但是同一枚实体印章钤印出的印章图像具有同源性,导致同一枚印章的图像在形状、尺寸、内容等方面具有一定程度的相似性。通过分析印章图像的特点进行数据增强可以有效提升模型在复杂场景下的识别能力。因此,本文使用数据增强的方法应对上述问题,并针对不同场景设计不同的数据增强策略,以确保训练数据的充分性。由于经过数据增强的数据集较为充分,可以使用特征提取能力较强的ViT(vision transformer)模型提取印章特征并进行识别,以取得较好的识别效果。
1 研究进展
鉴于印章识别任务属于图像分类任务,且本文使用了数据增强方法,本节从图像分类方法、数据增强方法和印章识别方法三个角度探讨当前研究进展。
1.1 图像分类方法
图像分类任务是计算机视觉领域的核心问题,其目的是将输入的图像分配到预定义的多个类别之一[5]。早期的图像分类方法主要依赖于手工构建特征。Lowe等[6]提出了一种尺度不变性较好的SITF(scale-invariant feature transform)方法,其在图像旋转、缩放、平移等变换情况下具有较强的鲁棒性,并且能够抑制局部遮挡和形变;然而该方法计算量较大,且对于模糊和边缘平滑图像的特征提取效果较差。Dalal等[7]提出一种梯度方向直方图(histo‐grams of oriented gradient,HOG)方法,该方法通过对图像进行灰度化表示和gamma校正来抑制噪声的影响。因此,该方法具有对光照和噪声不敏感以及计算量较小的优点,但是该方法的尺度不变性较差。为了降低SITF方法的计算量,Bay等[8]提出了SURF(speeded up robust features)方法,Rublee等[9]提出了ORB(oriented FAST and rotated BRIEF)方法。此外,Ojala等[10]提出了一种局部二值模式(local binary pattern,LBP)方法,该方法是一种描述图像局部纹理的方法,具有旋转不变性和灰度不变性等优点。Viola等[11]提出了一种基于一维Haar小波变换的Haar方法,可以较好地描述明暗变化,该方法常被用于人脸检测任务。
传统的图像分类方法通常需要先手工构建特征,再使用支持向量机、决策树、朴素贝叶斯等算法进行分类[12]。然而,手工构建特征的过程不仅耗时费力,而且无法完整地表达数据中的全部有用特征。神经网络具备的强大特征提取能力和自适应学习特征的优势逐渐取代了手工构建特征的过程。例如,LeCun等[13]提出了卷积神经网络(convolution‐al neural network,CNN)用于手写数字识别,并在图像识别领域中获得了良好的分类效果。CNN模型在情感分类[14-16]、期货价格预测[17]、股票指数预测[18]等任务中也表现出了卓越性能。许多研究人员针对CNN模型进行了改进。Simonyan等[19]提出了VGG(visual geometry group)模型,通过加深网络的隐藏层以提取图像中的隐藏特征,获得了较好的分类效果。Szegedy等[20]提出了GoogleNet模型,该模型采用了inception module结构,通过多个分支提取图像特征,并在不同分支间进行拼接,进一步提升了模型的性能。He等[21]提出了ResNet(residual network)方法,该方法基于深度残差网络,通过引入residual block结构有效抑制了神经网络的退化问题,提升了模型的训练稳定性。还有研究基于循环神经网络(recurrent neural network,RNN)提出了RNN-CNN方法,该方法使用CNN提取图像特征,并使用RNN来处理这些特征序列,在性能上取得了一定的提升[22]。此外,Bahdanau等[23]提出了注意力机制,作为一种机器翻译模型。注意力机制可以区分不同特征的重要性,因此在图像分类任务上逐渐处于领先位置,基于注意力机制的改进方法ViT模型依然是当今较为先进的模型之一[24]。
1.2 数据增强方法
数据增强方法通过对原始数据进行一定程度的变换来增加训练数据,从而提神经网络模型的泛化能力[25]。数据增强的思想可以追溯到1998年,Le‐Cun等[13]在过采样应用的讨论中使用过采样方法缓解类别数据不平衡的问题。过采样方法旨在复制或生成数量较少的类别数据,后续改进的过采样方法也均可视为数据增强算法[26-28]。数据增强可以分为基于图像变换的方法和基于生成模型的方法两大类别。
基于图像变换的方法主要包括三种类型:基于几何变换的方法,通过翻转、模糊、缩放和裁剪等方式实现[29-31];基于像素变换的方法,通过改变图像的亮度、对比度和锐化处理等方式实现[32];基于混合样本的方法,通过将不同的样本进行混合从而生成新的图像数据。其中,mixup方法通过对两个不同样本和标签进行线性插值,模拟样本和标签间的线性关系,从而生成新的训练数据,提高模型的泛化能力[33]。AdaMixUp方法可以自适应地选择混合参数,更好地适应不同数据样本的特征分布,解决了mixup中存在生成图像与原始图像都不相似的问题[34]。sample pairing方法通过将一个Batch的数据划分为两个子集,并将两个子集的样本两两组合生成新的数据样本[35]。另外,RICAP(random im‐age cropping and patching)方法随机选择四个样本,并从上述样本中随机剪裁一部分进行拼接,进而生成新的样本[36]。MixStyle是一种基于风格迁移的数据增强方法,该方法通过对输入样本的样式和内容进行分离和混合,生成新的训练样本以提高模型的鲁棒性和泛化能力[37]。这些方法可以有效增加训练数据的多样性,从而提升模型的泛化性能和鲁棒性,已被广泛应用于计算机视觉领域。
基于生成模型的数据增强方法是通过生成对抗网络直接生成新的图像样本,并将这些生成的样本加入训练集中。生成对抗网络由生成器和判别器组成,二者相互博弈,生成器负责生成逼近真实的新样本,判别器负责区分真假样本,使生成的样本质量不断提升[38]。常见的生成模型包括GANs(gener‐ative adversarial networks)[38]、CGANs(conditional generative adversarial networks)[39]、ACGANs(aux‐iliary classifier generative adversarial networks)[40]、DAGANs(data augmentation generative adversarial networks)[41]等,这些模型设计了不同的机制来提高生成样本质量和多样性。另外,自动编码器(auto-encoder,AE)[42]和变分自动编码器(varia‐tional auto-encoder,VAE)[43]也可用于样本生成。AE通过编码器和解码器实现样本重构,而VAE在AE基础上约束了潜在空间,使其生成的样本更加清晰。GAN与VAE结合的VAE-GANs模型[44]可以进一步改善生成样本的真实性。
虽然基于生成模型的数据增强方法通常具有较强的通用性,但是这类方法的本质是学习并模仿训练数据的底层特征,对关键特征进行保留和组合,从而生成相似但不相同的数据。在印章识别任务中,印章图像是由实体印章钤印所得,具有客观的物理形态特征。生成模型在模仿训练数据的过程中,可能改变或扭曲印章图像的关键物理特征,从而生成不符合实际情况的样本图像。失真的训练集会降低模型的识别能力,因此,在印章识别任务中选择基于图像变换的数据增强方式更为有效。
1.3 印章识别方法
印章识别技术研究主要针对字画印章和公文印章两大类,虽然两者的应用场景不同,但其识别技术具有较强的通用性。相关研究主要聚焦印章定位、印章提取和印章识别三个方面。印章定位主要用于识别印章的位置,印章提取能将印章主体从复杂背景中分离出来,而印章识别则需对印章含义进行识别。由于印章数据集一般较小,因此,鲜有研究直接使用深度学习进行模型训练。
杨琴等[45]提出了一种高光谱成像系统,可对模糊印章进行信息增强,提高其辨识度。牟加俊等[46]开发了一种印章定位算法,该算法可通过双板滤波和颜色增强,准确定位印章区域。杨有等[47]提出了UNet-S(UNet for seal)方法,可用于精准分割民国档案图像中的印章。周新光等[48]利用高光谱成像技术采集图像,结合最小噪声分离和波段剪裁来提取辨识度不高的印章。康雅琪等[49]首先将印章图像转换到SN色彩空间,并提取印章主体,然后使用基于双边滤波的自适应Canny算子来提取印章边缘,抑制伪边缘。葛怀东等[50]提出了一种基于HSV(hue, saturation, value)颜色空间和自适应红色连通分量的算法,能够有效去除背景噪声。陈娅娅等[51]提出了一种基于ResNet和迁移学习的古印章文本识别方法,可避免模型过拟合,提高识别准确率和泛化能力。欧阳欢等[52]提出了一种多特征融合决策的印章识别算法,该算法具有准确率高和抗造性好等优点。戴俊峰等[53]提出了一种基于极坐标转换的方法,该方法根据印章元素排列特点展开中文印章图像极坐标,缓解了印文方法不统一的问题。
2 研究框架
印章识别的难点在于缺乏足够的标注数据,导致神经网络模型无法得到充分训练,使得印章识别效果不理想。为解决这一问题,通常会采取包括数据增强、迁移学习、生成对抗网络以及数据采集等四种策略。然而,迁移学习的应用前提是源任务和目标任务存在一定的相似性,而在印章识别任务中,往往难以找到具有相似数据分布的源任务或模型。生成对抗网络可以通过生成与真实数据相似的新数据来缓解数据匮乏的问题,但在印章识别任务中,可能生成与印章本体偏离的图像,这可能会对现实中印章图像的识别造成干扰。数据采集则依赖于领域专家对额外数据进行标注得到的扩充数据集,然而受制于印章图像的多样性,难以覆盖所有特殊情况的印章图像。印章图像均由实体印章钤印所得,通过对印章图像的出现情况进行分析,使用数据增强方式对上述情况进行模拟,可以有效提高模型的泛化和识别能力。因此,数据增强方法与任务更为契合。在数据集充足的前提下,ViT模型使用Transformer作为特征提取器,更容易捕获印章图像的全局特征,从而适应印章图像的多种复杂情境。基于上述分析,本文提出了一种基于数据增强和ViT的印章识别方法,其流程如图1所示。本文方法主要分为印章数据获取与标注、数据增强模块和印章识别模块三个部分,其中印章数据获取与标注负责从作品中截取清晰的印章图像,并由领域专家标注印章的主人和内容。然后,使用数据增强模块对标注数据进行多维度增强。最后,使用增强数据训练印章识别模块中的ViT模型,并保存效果最佳的模型用于最终印章识别。
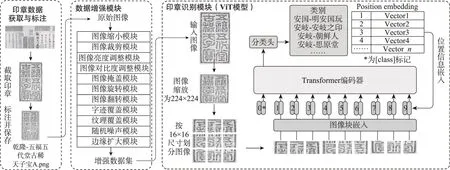
图1 基于数据增强与ViT的印章识别模型
2.1 印章数据获取与标注
数据增强需要基于一定规模的高质量数据集,首先需要标注一定数量的印章图像。图1左侧为印章数据获取与标注模块,为保证基础印章图像具有较高的清晰度,需要获取TIFF(tag image file for‐mat)格式的字画作品图像。TIFF格式是一种非失真的压缩格式,可以保留原始图像的颜色和层次。然后,从作品中逐个截取印章图像,在截取过程中剔除缺损严重或无法识别的印章图像。同时,尽可能减少截取图像中的非印章部分,即截取的印章图像要贴近印章边缘。最后,由领域专家对印章的所有人和内容进行识别和标注。
如图2所示,印章所有人可能拥有多枚内容一致但样式不同的印章。因此,本文在标注过程中使用“人物-内容-样式-编号”格式,其中人物为印章的所有人,内容为印章所包含的内容,样式使用英文字母进行区分。同一枚印章可能钤印在不同地方,在采集过程中可能多次出现。为避免重复命名的情况,需要为每个印章赋予一个编号。根据这个标注格式,图2a的印章标注为“乾隆-五福五代堂古稀天子宝-A-1”,图2b的印章标注为“乾隆-五福五代堂古稀天子宝-B-1”。在训练神经网络模型时,去除编号后的“人物-内容-样式”即数据集的标签。

图2 “五福五代堂古稀天子宝”印章
2.2 数据增强
数据增强是一种通过旋转、裁剪、亮度与对比度变换、潜在空间变换等方式对数据集进行扩增的方法。然而,原始数据集本身包含的信息有限,数据增强方法可以通过人工先验知识添加部分信息,但这些信息不能无限增加。若采用与任务不符合的数据增强方式,则会在数据集中引入噪声,导致模型识别能力下降。因此,选择与人物特性相符的数据增强方式至关重要。
在印章识别任务中,印章图像无论钤印在何处,都无法脱离原始实体印章。模拟印章图像出现场景可有效扩充印章数据,提升模型泛化能力。领域专家通过深入分析印章图像的形状、纹理、颜色、大小、种类和分布情况,在全面了解印章数据的整体特性后,结合印章图像所处的不同复杂场景,制定了相应的数据增强方法(表1),字迹覆盖模块、纹理覆盖模块、边缘扩大模块的详细流程见附录。
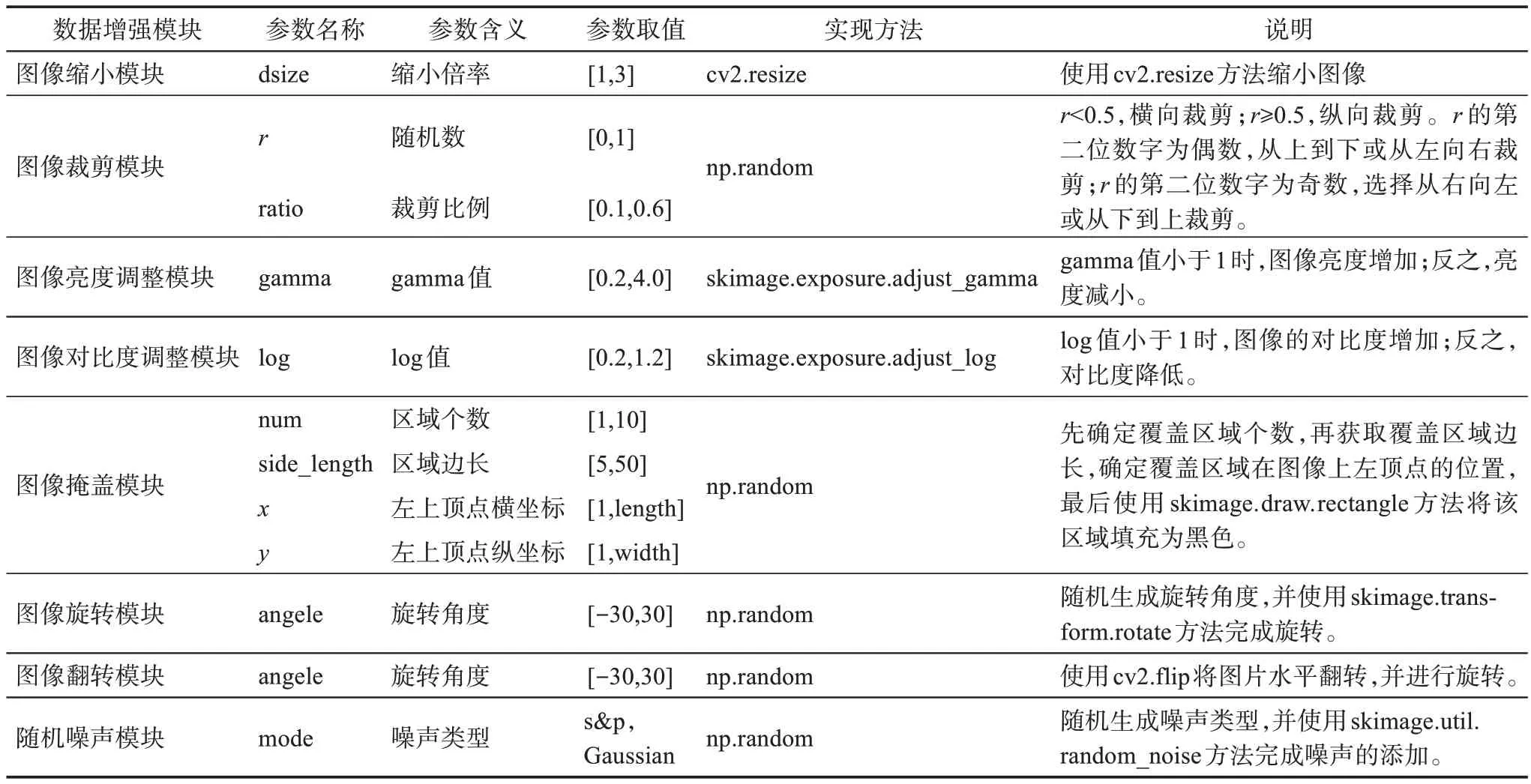
表1 数据增强模块参数
涉及图像尺寸和方向调整类的数据增强方法通过改变图像大小和方向,模拟特定现实场景。通过图像缩小模块对图像按比例缩小,模拟由于图像采集设备质量低、拍摄晃动、网络传输对图像压缩等因素导致的模糊情况。图像裁剪模块则按不同方向和尺寸对图像进行裁剪,模拟作品在重新装裱或拍摄角度不当等情况下,印章图像出现横向或纵向缺失的情况。图像旋转模块将图像随机旋转不同角度,模拟拍摄或印章钤印时角度不正导致的印章图像偏转。由于印章实体和印章图像为水平翻转关系,通过图像翻转模块能够模拟印章本体图形。同时,拍摄印章实体时,更容易存在图像不正的情况,需要同时搭配印章旋转模块。
有关图像质量调整的数据增强通过改变印章图像亮度和对比度以及添加噪声点的方式,提升模型识别能力。在采集过程中,印章图像可能出现图案过亮或过暗的情况,可以通过图像亮度调整模块模拟不同光照条件。相机硬件的差异、智能手机在拍摄时采用的不同白平衡算法、色彩还原算法、HDR(high dynamic range)模式或曝光补偿等策略,都可能对图像对比度造成显著影响,导致对比度存在较大差异。为模拟这种现象,可以使用图像对比度调整模块。图像的噪声情况是另一种需要模拟的现实世界中的图像采集情况。随机噪声模块通过添加高斯噪声和椒盐噪声来实现这一模拟。这些模拟有助于使模型更好地应对真实世界的噪声干扰,从而提高其识别能力。
有关图像内容修改的数据增强则通过掩盖部分区域和添加字迹与纹理来模拟现实场景。图像掩盖模块用于模拟书法字画在长期保存过程中可能出现的污渍和斑点,或在鉴赏、借阅、展览过程中可能对画面产生的损坏。该方法详细流程可参见附录的算法1。字迹覆盖模块则通过生成少量文字并将其覆盖到印章图像上,模拟在题跋过程中因规划不佳而导致字迹与印章图像的重叠。此外,作者在题跋上钤印印章以标识身份,也可能导致字迹与印章图像的重叠。该方法的实现代码可参见附录的算法2。纹理覆盖模块则用于模拟印章图像因不当保存而导致的细密纹路的褪色,以及因不同材质载体(如纸张或丝绸布帛)而导致的印章图像多样性纹理。这些模拟有助于模型更好地处理现实世界中的各种复杂情况,从而提升其识别能力。
附录:关键数据增强模块算法
算法1. 图像掩盖模块算法

算法2. 图像字迹覆盖模块算法

有关图像边缘处理的数据增强为边缘扩大模块。在钤印过程中,印章可能蘸取过多的印泥导致印章图案存在粘连现象,增加了印章识别的难度。因此,本文通过提取印章的印文区域并扩大数个像素点来模拟这种情境。首先,需要将印章图像转换到HSV颜色空间,该色彩空间使用色调(hue)、饱和度(saturation)和亮度(value)三个分量来表示颜色。通过将色调的取值范围限定在[0,36] ∪[216,300] ,可以提取印章图像中的红色区域。其次,使用skimage中的morphology模块对红色区域进行膨胀操作,本文在水平和垂直方向扩大r像素,r∈[5,15] 。最后,将扩大的区域填充为红色区域内的平均颜色。该模块的具体过程见附录的算法3。
算法3. 图像边缘膨胀模块算法

使用上述方法进行数据增强,增强后的数据集可以提高模型在复杂场景下对印章的识别能力。图3为“安歧-㯟邨”印章图像的数据增强示例。
2.3 印章识别
如图1右侧所示,本文方法使用ViT模型来完成印章识别任务。与CNN模型不同,ViT模型使用Transformer替换卷积层提取图像特征。由于CNN受到卷积核尺寸固定的限制,难以获取输入序列的全局特征。而Transformer中的自注意力机制却能够捕捉输入序列所有元素之间的关系,从而获取输出序列的全局特征。因此,在面临图像遮挡(occlu‐sion)、数据分布偏移(distribution shift)、存在对抗patch(adversarial patch)和图像分割重排列(per‐mutation)等情况下,ViT模型具有比CNN更强的鲁棒性[54]。这些情况与印章被字迹覆盖、钤印位置材质不同导致的纹理不同、印章图像存在污渍、印章图像被裁剪或缺失的情况相似,因此,ViT模型对印章识别的复杂情境具有较强的适应能力。原始的印章数据难以满足ViT模型的训练要求,经过数据增强的印章数据恰好解决了该问题。此外,由于Transformer具有较强的可扩展性,随着模型参数和数据量的增长不存在性能饱和的现象。因此,使用ViT模型可以较好地适应后续数据集增加情况。综上所述,基于数据增强的ViT模型可以较好地应用于印章识别任务。
使用ViT模型进行印章识别可以分为数据预处理、特征提取和印章分类三步。首先,数据预处理模块将输入图像转换为可供Transformer编码器接受的形状。该模块通过将图像大小缩放至[224,224,3] ,其中的参数分别表示图像的高度、宽度和通道数。其次,将其分割为196个边长为16的正方形图像块,在图像块嵌入模块中将其从三维降至一维,使用长度为768的向量来表示每个大小为[16,16,3] 小图像块,此时输入图像的维度变为[196,768] 。然而,在不同的印章图像中,最重要的图像块位置是不固定的,无法用某一个图像块来代替全局特征。因此,在ViT模型的头部位置添加[class] 标记。由于该标记本身不包含印章图像信息,在该标记与其余196个图像块向量一起输入Transformer中进行学习后,即可得到印章图像的全局特征。同时,位置信息也是印章图像中重要的特征,需要在模型训练前加入位置信息,此处的位置信息是一个维度为[197,768] 的可训练矩阵。随后将图像块嵌入和位置嵌入相加,即可得到用于Transformer学习的矩阵。在特征提取步骤中,使用16层叠加的Transformer编码器对输入的矩阵进行学习,此时的[class] 标签已经包含了输入印章图像的全局特征信息。最后,将[class] 标签输入分类器进行印章分类,该分类器是一个长度为印章类别数的全连接层,使用soft‐max作为激活函数。分类器的输出是输入印章图像对应每个类别的概率,输出概率最大的类别即可得到印章的识别结果。
3 实验结果与分析
3.1 数据集及对比方法
实验选取了16幅著名的书法字画,包括《兰亭序》《祭侄文稿》《寒食帖》《伯远帖》《韭花帖》《快雪时晴帖》《资治通鉴残稿》《中秋帖》《仲尼梦奠帖》《上阳台帖》《洛神赋》《松风阁帖》《蜀素帖》《自叙帖》《秾芳诗帖》和《清明上河图》。获取上述作品的TIFF格式高清图像,由领域专家在其中截取并标注了1259枚印章图像,共计529类。每一类都代表一个实体印章所钤印出的图像,如图2左侧印章的类别为“乾隆-五福五代堂古稀天子宝-A”。该类别也是模型的预测目标,通过模型预测可以获取印章图像的所有者和印章内容。印章的所有者包含古代皇室、贵族、书画家、收藏家、官员、机构等多种类型,内容涵盖了姓名字号、收藏、格言志趣、年号、职务等方面。数据集中的印章图像时间跨度大且种类丰富,可用于合理评估模型的识别能力。
训练集和测试集的构建过程如下。初始训练集包含1259枚印章图像,对此初始训练集进行数据增强,利用不同的模块生成新的印章图像。这包括使用10个数据增强模块(除图像翻转模块外)对原始印章进行增强,每个模块根据一枚原始的印章图像生成10枚新的印章图像。由于图像翻转模块对印章图像进行水平方向的翻转,其结果具有唯一性,因此对原始印章图像进行一次水平翻转。总的来说,每枚印章图像通过增强生成了101张新的图像。经过上述步骤,形成两个训练集,即原始训练集和数据增强训练集。为了更全面地评估本文方法在复杂情境下的印章图像识别能力,并避免数据泄露,测试集应独立于训练集并尽可能覆盖所有类别。因此,从互联网上获取独立的印章数据作为测试集,该集合包含了模糊、不完整、亮度和对比度差异大、角度偏斜、字迹覆盖、纹理不同以及边缘粘连等各种情况的印章图像。对上述数据集分别进行随机排序,最终,初始训练集、数据增强数据集和测试集分别包含了1259、127159和522枚印章图像。
3.2 实验环境及参数设置
本文使用武汉大学超级计算机中心的GPU(graphics processing unit)服务器集群作为实验平台,该服务器采用Intel(R) Xeon(R) E5-2640 CPU和Nvidia Tesla V100 GPU,配备了128 GB内存,操作系统为CentOS 7.7。实验代码基于python 3.8和Ten‐sorflow 2.5框架编写。为了降低随机误差的影响,采用重复实验的方法。具体地,每个实验均重复10次,取结果的平均值作为最终实验结果。此外,实验采用了early stop策略来避免模型过拟合和降低实验时间开销。在训练过程中,当验证集的损失值连续3个epoch(训练轮次)没有降低时,停止模型的训练并保存损失值最小的模型。该方法在保证实验结果可靠的前提下,提高了实验效率。为了确定最优的模型参数组合,实验采用网格搜索策略,为每个参数设置了候选值列表,通过遍历循环的方式得到每一种参数组合的实验结果,最终选择效果最佳的组合作为模型的最终参数,具体的参数和取值如表2所示。

表2 模型参数设置
模型的评价指标为精确率P(precision)、召回率R(recall)和F1值。在多分类任务中,实际计算的是宏平均值(macro average)。单独计算每个类别的P、R和F1,然后求所有类别的平均值。当计算某一类别样本时,该类样本为正样本,其余样本为负样本。各指标定义为。
其中,n表示类别总数;TPi表示识别为第i类的样本中,识别正确的样本数;FPi表示负样本被识别为正样本的个数;FNi是正样本被识别为负样本的个数;P表示被正确识别为第i类的样本数和所有被识别为第i类的样本数的比值,即被正确识别为第i类的占比;R表示被正确识别为第i类的样本数和实际为第i类的样本数的比值;F1值表示P和R的等权调和平均值,综合了P和R对模型性能的评价。
3.3 实验结果与分析
实验使用CNN、VGG和ResNet作为对比模型,其中CNN模型的隐藏层由三层卷积层和三层池化层交替叠加所构成,卷积层的神经元个数分别为64、128和256,输出层为两层全连接层。VGG模型具有结构简单和迁移性强的优点,是计算机视觉领域最常用的方法之一。ResNet通过引入残差块的概念可以在不发生梯度消失的前提下构建更深的网络结构。为了探究模型深度对印章识别结果的影响,本实验采用了不同规模的ResNet模型,包括ResNet50、ResNet101和ResNet152。其中,VGG、ResNet和ViT模型通过加载TensorFlow Hub在Ima‐geNet数据集上进行预训练,引入一定的先验知识。上述实验的结果如表3所示。
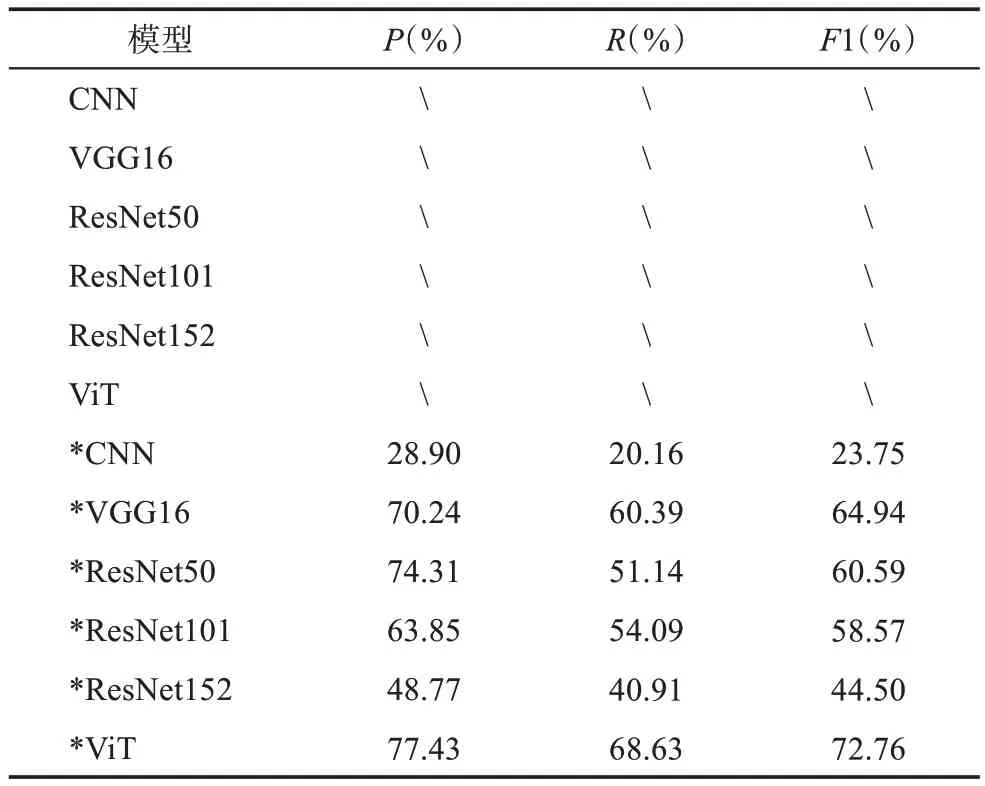
表3 数据增强对印章识别精度影响的模型性能评估
根据表3可以发现,所有未经数据增强的模型都无法实现有效拟合。这种情况主要是因为原始数据集中印章图像的数量不足,平均每类只有2.4张印章图像。在这种数据稀疏的情况下,模型难以学习到不同印章之间的差异,进而导致严重的过拟合现象,无法准确识别测试集中的印章图像。尽管VGG16、ResNet和ViT模型在ImageNet数据集上进行了预训练,获得了一定的先验知识,这仍然无法帮助模型实现有效拟合。然而,当应用了数据增强方法后,所有的模型都能够实现有效拟合,这说明在印章图像识别任务中,数据增强方法可以有效地解决因数据稀疏所导致的过拟合问题,同时提升模型的鲁棒性。
具体而言,CNN、VGG16、ResNet50、ResNet101、ResNet152和ViT模型的F1值分别提高至23.75%、64.94%、60.59%、58.57%、44.50%和72.76%。经过数据增强后,模型需要处理更丰富且更复杂的图像特征。由于CNN模型的结构相对简单,难以捕获到充足的特征用于印章识别,导致其F1值最低,相比之下,VGG16模型具有更深的网络结构,包含13个卷积层和3个全连接层,因此,其特征提取能力较强,增强了印章识别能力,F1值比CNN模型提高了41.19个百分点。一般而言,浅层的卷积核用于学习简单的边缘、纹理和颜色特征,深层的卷积核则用于组合浅层特征,进而学习到针对特定任务的区分性特征。ResNet50模型具有更深的网络结构,但其F1值相较于VGG16降低了4.35个百分点。其原因可能是ResNet50更深的网络结构可以捕获到更复杂的组合特征,但印章图像的内容和颜色特征相对简洁,过强的特征提取能力可能导致过拟合现象。类似地,ResNet101和ResNet152的F1值相较于VGG16分别降低了6.37和20.44个百分点。印章识别任务不仅需要考虑局部细节,还需要考虑全局特征及其排布情况。ViT模型由于其Transformer中的自注意力机制,能够更好地捕获每个图像块之间的关系,而非像卷积核那样主要关注局部信息。因此,在经过数据增强方法后,ViT模型可以得到更为丰富的全局特征,并且实现了最佳的印章识别结果。
综上所述,数据增强方法与印章识别任务的相容性较高,能有效提升模型的性能并促进其拟合过程。然而,不同架构的模型可能产生不同的数据增强效果。对于特征提取能力较弱的模型,可能难以充分提取训练集中的特征信息,导致识别效果较差。相反地,如果模型的特征提取能力过强,那么可能导致过度学习训练集中的特征。由于训练集无法完全覆盖印章图像可能出现的所有场景,过度的特征提取可能降低模型的泛化能力。在这种情况下,模型可能难以识别与训练集有一定差异的印章图像,而对于与训练集相似的印章图像则能准确识别。这导致了实验结果中模型的召回率低于精确率。因此,对于小规模的数据集进行数据增强时,选择具有针对性的策略以及合适的深度学习模型至关重要。
4 结 语
为了降低用户查询和识别印章的难度并提升印章文化的推广水平,急需一种可以快速、准确识别印章图像内容的方法。由于印章识别任务的类别数目较多且每一类样本数量少,直接使用深度学习模型进行训练会导致模型识别效果欠佳。即使通过细致的调参使其勉强拟合,也难以识别处于复杂情境下的印章图像。因此,面对上述困境通常需要更大的数据集。然而印章图像数据本身较为稀缺,同时对标注人员本身印章知识的要求较高,导致印章识别领域缺少大规模的标注数据集。
为解决上述问题,本文提出一种基于数据增强和ViT模型的印章识别方法。通过分析印章图像的特征,有针对性地对上述场景进行数据增强,有效提升了模型在印章识别任务中的泛化能力。同时,使用特征提取能力优秀且扩展性较强的ViT模型作为印章识别任务的特征提取器,取得了较好的印章识别结果。因此,本文方法对印章文化的传播具有一定应用价值,为快速、准确识别复杂情境下的印章图像提供了新的研究思路,针对印章图像的数据增强模式还可以为后续印章识别研究提供基础。但本文方法缺乏语义推理能力,模型通过建立印章图像的全局特征与标签间的映射完成识别过程,尚无法对印章图像进行逐字识别。在未来的工作中,需要构建具有语义推理能力的印章识别模型,通过图像分割、文字识别、内容排序来完成对印章语义层次的理解和识别,从而识别未知印章,扩展深度学习模型在传统文化领域的应用,并为传统文化的普及和传承提供技术支持。
