基于异类数据和语义建构的新兴技术弱信号识别研究
2024-05-06韩盟陈悦王玉奇王康崔林蔚
韩盟,陈悦,王玉奇,王康,崔林蔚
(大连理工大学科学学与科技管理研究所暨WISE实验室,大连 116033)
0 引 言
“弱信号”本意是指物理领域(如声音、电流、光、振动、温度等)的“微弱信号”,是深埋在背景噪声中的、极其微弱的有用信号,不易被捕获或接收。随后,这一概念引起了社会科学研究者的关注。自1975年安索夫(Igor Ansoff)在战略管理领域称弱信号为“具有重大影响的、不确定的早期征兆”[1]以来,其就受到了战略管理、经济金融、竞争情报、公共管理、环境科学和危机管理等学科的持续研究。弱信号的典型例子是与商业竞争、社会发展、危机冲突和环境变化等相关的信息和迹象,扫描和识别这些信息对于预测未来变化、发现新的机会和避免未来威胁具有重要意义。
随着商业竞争的不断加剧,市场对于技术创新和产品迭代的要求越来越高,致使技术创新管理和技术预见的研究不断深入,尤其是新兴技术前瞻性预测的技术竞争情报分析受到前所未有的关注。“与外部技术的威胁、机会或发展的信息,以及这些信息的获取、监控、分析、前瞻和预警过程”[2]成为超前布局新兴产业的关键支撑,由此催生出基于新兴技术预测的弱信号识别研究。已有研究指出,“新兴技术弱信号”预示着未来技术变化的征兆,其往往具有结果不确定性、信息不完全性、解读复杂性、可演化成趋势等特征,分析弱信号有助于提早了解和控制新兴技术的未来发展[3]。Decker等[4]提出新兴技术弱信号识别有助于减轻管理人员的负担,留出时间分配给更为重要的工作,例如,根据发现的弱信号内容制定具体的研发计划;Thor‐leuchter等[5]指出新兴技术弱信号识别可为企业技术研发计划提供支持,辅助战略决策;Yoo等[6]也提出通过探索科技变化的“微弱信号”,可以预测未来科技形态,探寻未来产业发展方向。此外,信息科学和大数据技术发展使得系统记录技术演化的数据库日益完善,新兴技术弱信号识别的条件和机会日益成熟。
当前,新兴技术弱信号识别方法主要分为以专家为主的主观评估法和以数据驱动的客观测度法两类。具体地,Decker等[4]调研了25名金融领域的专家意见,评估识别出未来金融领域的投资弱信号;Uskali[7]基于个人经验,在新闻文本中发现了创新新闻学领域的弱信号;Kim等[8]基于NEST(new and emerging signals of trends)模型,通过专家咨询评估的方式,检测出韩国新兴技术未来趋势的微弱信号。同时,随着信息技术的发展,使用指标评价、组合图和机器学习等的数据挖掘方法来识别弱信号也引起了更多学者的关注。例如,苗红等[9]基于产业融合的视角,提出了技术饱和度增量和相对度中心性增量两个指标,并设定了技术饱和度增量下降而相对度中心性增量上升(或不变)和技术饱和度增量上升而相对度中心性增量下降(或不变)两个条件来识别弱信号;Kim等[10]提出了罕见性和范式无关性指标,利用局部离群因子检验和开发信号组合图的方法探测出AR领域的技术发展弱信号;Yoon[11]使用术语可见度与术语扩散度指标,将弱信号视为与关键词相关的新兴话题,使用组合图法识别出技术创新弱信号;Bouktaib等[12]则使用k-means算法对大数据文本进行语义聚类,结合LDA(la‐tent Dirichlet allocation)、LSA(latent semantic analy‐sis)等聚类方法,使用相似度指标对聚类结果进行合并,减小聚类分歧,实现了弱信号的检测;Eba‐di等[13]在将技术划分为具体子领域的基础上,通过深度学习与组合图法有效识别了超高音速飞行技术的演化脉络,并预测了未来超高音速飞行领域的新兴技术。
已有弱信号的识别研究视角较为广泛,方法也较为全面,但部分问题仍有待进一步研究。
首先,专家评估法一直存在判断主观、成本昂贵和难以适应大数据时代海量信息的研究缺陷;而对于弱信号识别结果进行信息解读和评估时,依靠专家评估法又易受到专家自身知识无法覆盖的局限。基于此,本文拟结合意义建构理论,通过共现算法抽取术语的前后高频词汇,构建其使用语境,共同对弱信号术语含义进行解析,以实现语义构建,有效完成弱信号的解读和转译任务,提升新兴技术弱信号的识别灵敏度。
其次,当前数据驱动的研究方法通常是使用从网络中批量获取的论文或新闻数据,忽略了降噪处理,从而影响本身就淹没在杂乱数据中的弱信号分析。已有研究指出,弱信号具有“与现有范式不兼容的奇怪特征或异常”[14]、“稀有性和范式不相关性”[10]和“超出正常参考框架的异常、不一致和奇点”[15]等特征,这表明弱信号的数据来源往往是不受普遍关注、与现有研究不相关的异类数据信息。同时,技术预测领域的一些研究指出,通过数据筛选能够增强数据处理的信度和速率,有效提升技术机会预测效度[16-18]。因此,基于上述观点,本文尝试从文档离群性和文本相异性两个方面筛选异类数据,进行新兴技术弱信号识别,以更有效地处理新兴技术数据,提升弱信号识别的有效性。
综上,本文将融合弱信号三层过滤器理论和意义建构理论,通过异类数据筛选和文本语义建构的方式,使用特征量化和文本挖掘相关方法,开展弱信号识别研究,以丰富和扩展研究方法,提高弱信号识别灵敏度,辅助技术研发和管理者有效地进行技术研发判断。
1 弱信号识别理论与研究框架
作为弱信号研究的先驱,安索夫提出弱信号定义后,于1984年设计提出了弱信号识别的三层过滤器理论[19],具体包括“观察-认知-决策”三层过滤器,概述了弱信号识别的信息获取、信息分析与解读、决策支持三大步骤。基于该理论,本文设计了弱信号识别研究框架,具体如图1所示。

图1 新兴技术弱信号识别流程
(1)观察过滤器(observation filter):也称为扫描过滤器,在三层过滤器理论中,将观察过滤器定义为观察和收集数据的区域,包括信息获取的方法,为弱信号识别的扫描层。弱信号的有效识别需要保证观察过滤器中来源数据的有效性,而现有研究已指出,新兴技术弱信号主要来源于现有科学研究成果中不受普遍关注、与现有研究不相关的异类数据信息[10,14-15],为保证识别研究的准确性,不仅需要保证数据收集的有效性,更需要对科研数据中的异类数据进行筛选。因此,本文设计的观察过滤器包括数据获取、文本预处理和异类数据筛选三个环节。
(2)认知过滤器(cognitive filter):也称为分析过滤器,被定义为从观察层传递扫描出的与识别主体相关信息的区域,是弱信号识别的分析层。安索夫在提出弱信号识别的过滤器理论时,并未明确给出认知过滤器的实际内容。后来的研究者们基于各自研究设计了符合个人研究需要的认知过滤器模型,但主要涉及科学计量[9-10]和文本挖掘[11-13]两种方式。本文主要参考Yoon[11]提出的组合图法对弱信号内容进行扫描。因此,结合研究需要,本文的认知过滤器具体包括关键术语计算、关键词显现图(keyword emergence map,KEM)和关键词发布图(keyword issue map,KIM)构建以及关键术语提取三个环节。
(3)决策过滤器(power filter):也称为权力过滤器,是指当组织的管理者、决策者或参与者聚集在一起,决定和分析前两个阶段传递信息时的环节,为弱信号识别的决策层。对于弱信号识别而言,因其受信号的微弱性、含义的隐匿性以及决策者的主观性等特点影响,已有研究在设计过程中往往对决策过滤器的重视程度不够,主要通过主题词挖掘方式主观判定弱信号含义,致使识别结果不够明确。对此,本文借鉴意义建构理论中“情境对信息渠道和信息内容选择有重要影响”[20]的观点,尝试将扫描出的弱信号关键术语放入其使用语境中进行解读,通过弱信号语义构建的方式实现决策过滤器的客观评定。具体研究设计中包括弱信号语义建构和识别结果评估两个环节。
2 研究方法
2.1 数据获取及预处理
论文是承载科学研究发现和新型技术研究成果的重要载体,新兴技术未来发展趋势的信号源头应主要附载在科学论文中[11,13]。因此,本文以学术论文作为新兴技术弱信号识别的数据对象,通过学术文献数据库批量获取论文的题录信息,并通过自然语言处理方法,对数据进行预处理,以备后续研究使用。
2.2 异类数据筛选
“异类”往往是指一个在价值上与其他(包括正类和其他异类)具有显著不同的样本[21],计算机学科中将那些不符合大多数数据对象所构成的规律(模型)的数据对象称为异类[22]。在本文中,“异类数据”具体是指在同一数据集内特征评判中与其他数据相异的数据类目。已有研究指出,弱信号具有与现有范式不兼容的“离群性”和超出正常参考框架的异常性、不一致性[14-15]。因此,结合弱信号特征中“含有新兴技术弱信号的数据与其他样本显著不同”的特点,将该类数据称为“异类数据”。同时,对异类数据的分析处理通常被称为异类挖掘或异类数据筛选。数据中的异类可以利用数理统计方法分析获得,即利用已知数据所获得的统计分布模型,或利用相似度计算所获得的相似数据对象分布,分析确认异类数据[22]。本文主要围绕新兴技术弱信号的离群性和不一致性两大特征,从文档离群性和文本相异性两个特征维度筛选异类数据,实现噪声数据的有效消除,从而获得更易包含新兴技术弱信号信息的有效文档,提升弱信号识别的灵敏度。
2.2.1 文档离群性(document outlier,DO)
文档离群性指标用于检测一份文档在整体聚类中的位置,观察数据集中明显异常的数据点。当一份文档处于聚类边缘位置时,其具有明显的离群性,该文档隐含弱信号信息的可能性较大[9-10]。本文选用文献的主题聚类概率表征计算文献的离群性特征。具体地,基于LDA聚类算法,统计文档i归属于技术主题t的主题聚类概率Pit,Pit值越接近于0,则文档i归属于任一技术主题t的概率越小,即该文档具有的离群性特征越明显。计算公式为
其中,MAX(Pit)为Pit的最大值;MIN(Pit)为Pit的最小值;选取DOi值的下四分位数作为离群阈值,即设定满足DOi降序排列后25%的文档i具有离群性特征。
2.2.2 文本相异性(text dissimilarity,TD)
已有研究可以从文本层面对不同文档信息进行向量化处理,并计算不同文献间的相似度。某一文档的文本信息与其他文档内容的相似度越低,则判定其表达内容的差异越大,该文档越有可能包含弱信号。基于此,本文提出的文本相异性特征主要从文本层面筛选异类数据,计算文档i和文档j之间相似度cos (i,j)[23],剔除文档间相似度过高的文献。计算公式为
其中,m为文档数目;Num(cos (i,j)-ω)为文档i与文档j相似度cos (i,j)小于文档间相似性阈值ω的文档数目。参考文献[12] ,设ω=0.2,即若两个文档相似度低于0.2,则设定两个文档互异;设定当TDi≥80%时,即文档i与80%以上的文档互异,满足文本相异性特征。
综上,仅当收集的数据同时满足文档离群性和文本相异性两个特征时,才判定该文档属于异类数据文档,对其进行弱信号的识别与检测。
2.3 关键术语抽取
已有研究通常将与关键词相关的新兴话题视为弱信号[11,24-26],致使抽取表征弱信号的关键词术语成为弱信号识别研究中的重点与难点。本文采用改进的TF-IDF(term frequency-inverse document fre‐quency)模型进行异类数据文档的关键术语抽取。TF-IDF作为用于文本挖掘的重要术语计算方法[20],其中字词的重要性与其在文件中出现的次数成正比,同时与其在语料库中出现的频率成反比,能够有效区分词或短语的重要性;而传统的TF-IDF算法仅能计算出针对某一单篇文档相对重要的关键词术语,无法应用于整个文档集。因此,本文使用改进后的TF-IDF计算方法来获得关键术语,计算公式为
其中,nj为整个文档集术语j出现的频次;N为文档总术语数目|D|表示文档集中的文档总数;|{j:ti∈dj}|表示包含术语j的文档数目。
使用改进后的TF-IDF算法能够有效识别异类文档集中的重要关键词术语,扩大了已有研究中作者关键词限定的识别范围,提升研究结果的准确度,辅助后续新兴技术弱信号识别。
2.4 组合图构建
本文通过组合图法从异类文档的关键词术语中抽取表征弱信号的关键词术语。Yoon[11]提出的组合图法中指出,弱信号关键词应该具有“出现频率很低,增长速度较高”的特点,并设计了关键词可见度指标(degree of visibility,DoV)和扩散度指标(de‐gree of diffusion,DoD)来表征,具体计算公式为
其中,TFij表示在时间段j内术语i出现的总频次;DFij表示时间段j内含有术语i的文档数量;NNj表示时间段j内文档的总数量;tw为时间权重;n为当前时段;DoV指标考察术语在文献集中的出现频率和扩散速度;DoD指标考察出现术语的文档频率和扩散速度。
首先,以DoV的平均值为横坐标,以其年平均增长率(average annual growth rate)AAGRDoV为纵坐标,构建关键词显现图(KEM);其次,以DoD的平均值为横坐标,其年平均增长率AAGRDoD为纵坐标,绘制关键词发布图(KIM);最后,选取KEM和KIM图中各象限同时出现的关键词术语,确定第二象限关键词并集为弱信号关键词术语,如图2所示。
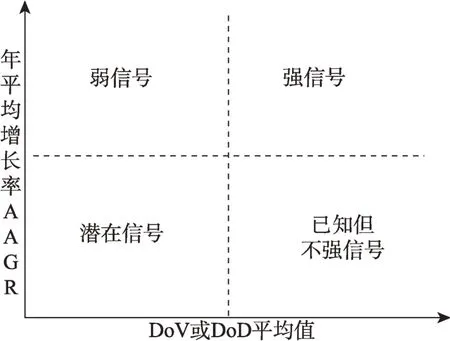
图2 弱信号关键词术语识别示意图[3]
2.5 弱信号语义建构
在有效获取弱信号术语关键词后,如何对术语进行有效解读、将其复杂含义进行解析并有效传达给决策过滤层,对于弱信号识别来说是一项重要研究内容。1983年,布伦达·德尔文(Brenda Dervin)提出了与信号解析相关的,由情境(situa‐tion)、鸿沟(gaps)、使用(uses)和桥梁(bridg‐es)4个要素构成的意义建构理论;该理论是信息科学领域认识范式的重要代表,它不仅强调了以用户为中心的行为构建视角,更是在不同情境中研究人们构建特定信息需求和行为的一套有效理论和方法[27]。同样地,本文认为弱信号识别的解读基础是由信息接受方与环境共同组合而成的,弱信号的解读实质上是一种主观建构行为,人只有通过观察才能理解弱信号的意义,并实现与他人的信息共享。因此,本文借鉴意义建构理论中“情境对信息渠道和信息内容选择有重要影响”[28]观点,认为弱信号的有效解读需要结合关键词术语的使用场景展开分析。
如图3所示,对于组合图法获得的弱信号关键词(如A)而言,其具体情境正是其在术语使用中同一句子内的上下文语境(如G、H、I等词),因此,要想更好地解读和分析弱信号具体含义,需要在原文档中抽取每个弱信号关键词的上下文关联词,通过统计确定与弱信号关键词术语高频共现的一组语境词,共同实现对弱信号的语义建构和解析。在实际操作中,本文通过Python语言编程将弱信号术语关键词整理成列表形式,并在抽取出的异类数据文档中统计各术语同一句子内同所有词汇的共现频次,然后以“弱信号术语A、共现高频词B和共现频次N”的形式输出所有关联词表,以获取每个弱信号术语语境词组。

图3 弱信号术语语义建构示意图
2.6 识别结果评估
识别结果的评估一直是技术预见研究中的难点与痛点。部分现有研究往往选用专家评估的方式进行结果检验,另有少部分研究选用指标量化或同文比对的方式解决该问题。鉴于新兴技术弱信号的微弱性,即使是专家评估仍具有不准确性。因此,本文尝试选用同文比对的方式,检索现有相关文献或新闻报道,对弱信号关键词术语语义建构结果进行解读,并基于论文作者观点和新闻评价内容进行结果评估和检验。
3 实证研究:量子信息技术领域
量子信息既是我国“十四五”规划中聚焦的重点创新领域,也是事关国家安全和发展全局的前沿技术领域,量子信息技术的演化和创新对于未来发展具有重要意义。我国量子信息技术发展快速,已位于世界第一队列。开展量子信息的新兴技术弱信号识别研究,可以有效探测量子信息技术的新兴微弱信号,辅助该领域专家进行量子信息领域的技术创新方向研发判断,推动量子信息的技术发展。
3.1 数据获取及预处理
本文以Web of Science核心合集数据库为数据源,通过线上线下文献调研,确定主题词检索策略,并制定检索式①检索式:TS=(("Quantum" and (("information")OR ("eraser") OR ("classical transition") OR ("coherence") OR ("entangle‐ment") OR ("measurement") OR ("network") OR ("storage") OR ("memory") OR ("communication") OR ("fingerprint") OR ("pro‐cessor") OR ("cavity QED") OR ("clock synchronization") OR ("image") OR ("sensor") OR ("magnetometry"))) OR ((quantum NEAR/5 comput*) OR (quantum NEAR/15 algorithm*) OR (quantum NEAR/10 simulat*) OR (quantum NEAR/10 error*) OR ("quantum circuit" OR "quantum cellular automata" OR "quantum turing machine" OR "quantum register") OR (quantum NEAR/10 communication*) OR(quantum NEAR/15 protocol*) OR (quantum NEAR/15 cryptograph*) OR ("quantum key")));论文类型:期刊论文和会议论文;时间范围:2017年1月1日至2022年5月7日。,检索获得79861条量子信息领域的文献信息,经去重、剔除题录缺失等数据后,共获得79160条文献数据。随后,对数据进行预处理,具体包括统一大小写、去除标点符号、词性标记、词根还原和剔除停用词等。
3.2 异类数据筛选
基于Blei等[29]提出的主题困惑度方法(perplex‐ity)确定最优主题数目后,使用LDA模型聚类,确定主题数目为6类,并基于公式(1)筛选异类文档,获得14880项离群性文档数据。然后,使用训练好的BERT(bidirectional encoder representations from transformers)模型对文档进行向量化处理,依据余弦相似度算法计算不同文本间的相似度,基于公式(2)共筛选出9202项异类文档(表1)。
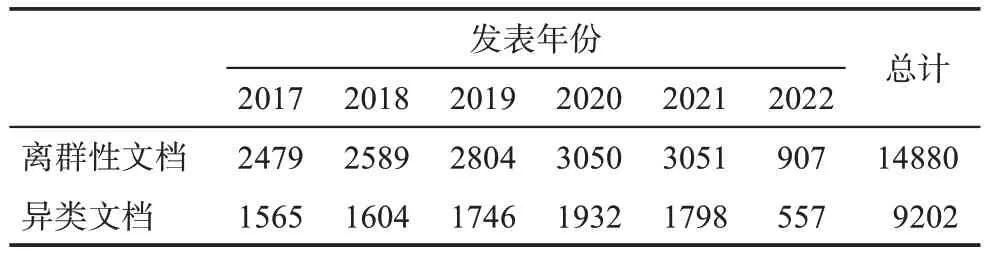
表1 各时间段异类数据筛选结果
3.3 关键术语抽取和组合图法计算
使用改进后TF-IDF模型计算9202篇异类数据中63750个关键术语的TF-IDF值,并提取前1000个重要关键词进行弱信号识别。然后,依据公式(4)和公式(5)(设定时间权重tw=0.05),计算各关键词术语的DoV值和DoD值,并计算两项指标不同年份间的变化率。再分别取DoV平均值和DoD平均值作为横坐标,以DoV或DoD的平均增长率(AAGR)作为纵坐标,绘制关键词显现图(KEM)和关键词发布图(KIM)。其中,设定年均增长率位于前30%和平均出现频率前50%的术语(文档)的值为各象限分界位置,具体如图4和图5所示。

图4 关键词显现图(KEM)

图5 关键词发布图(KIM)
对图4和图5中位于第二象限的术语取并集处理,最终确定出140项表征量子信息领域新兴技术弱信号的关键词术语,部分结果如表2所示。

表2 弱信号术语识别结果(部分)
3.4 弱信号语义建构
基于统计得到的140项弱信号关键词术语,抽取各术语使用的上下文语境词。Python语言编程伪代码如图6所示。统计其中共现频次前10位和共现频次大于100次的重要语境词,部分结果如表3所示。
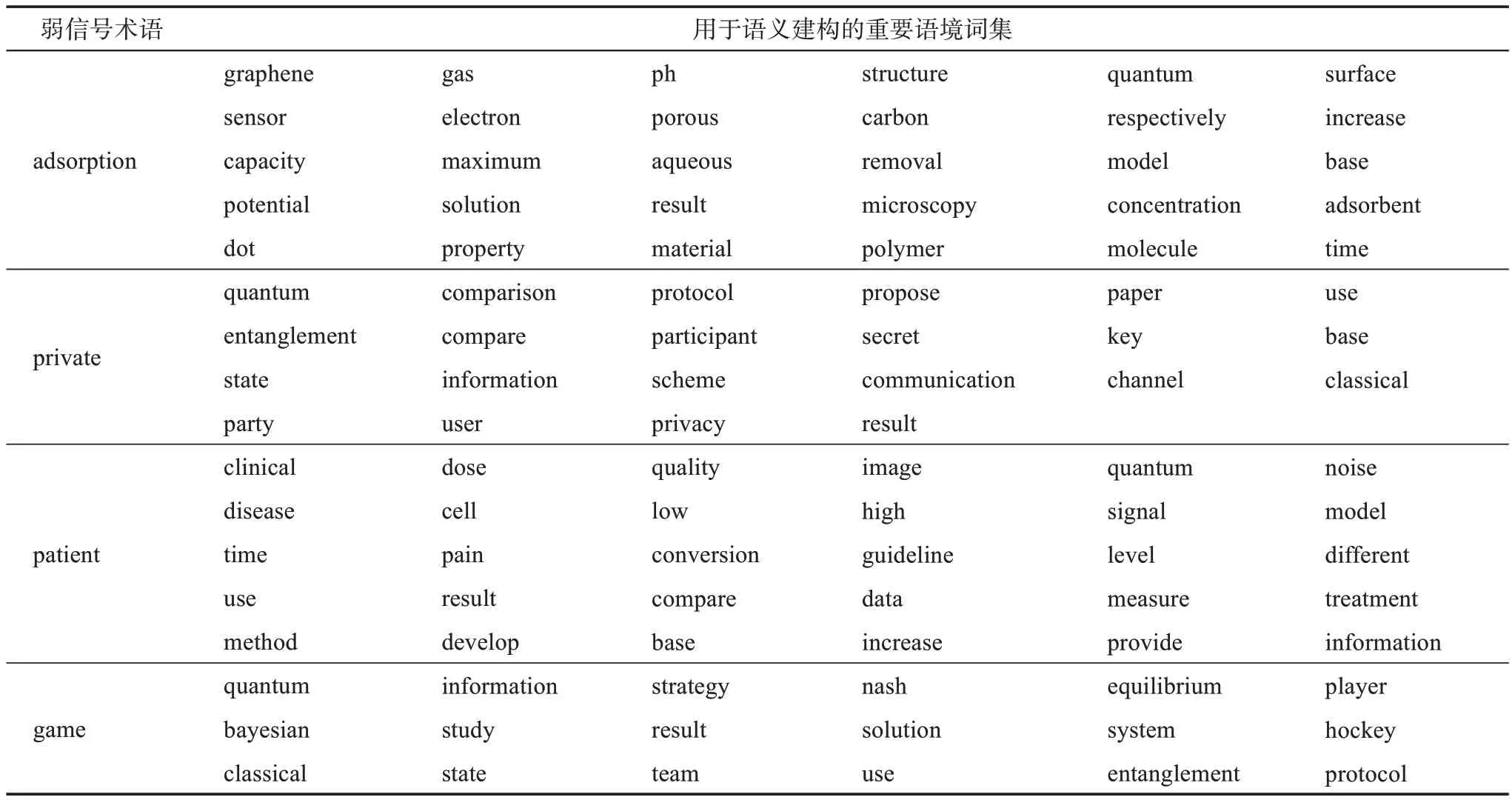
表3 弱信号术语及语义建构词集(部分)

图6 弱信号关键术语上下文语境词抽取伪代码
3.5 弱信号识别结果评估与检验
基于弱信号术语的语境词抽取结果,对140项弱信号术语进行调研讨论。本文选取DoV或DoD平均值和平均增长率(AAGR)较高的adsorption、private、patient和game共4项术语及其语境词(表3)进行弱信号含义解析,用于评估识别结果的有效性。
3.5.1 基于adsorption术语的量子点吸附研究
基于“adsorption”的语义建构词集如图7所示。解析后可将用于金属离子聚合物吸附的量子点吸附剂研究视为量子信息领域弱信号之一。具体来说,量子点(quantum dot)作为一种准零维的纳米材料,具有光稳定性好、生物相容性优和子点荧光寿命长等优点,受到了科学界的广泛关注。近年来,随着工业污染的加剧,学者们开始对量子点用于金属离子聚合物吸附进行探索性研究。例如,2020年,Zare Pirhaji等[30]将石墨烯量子点(graphene quantum dots,GQD)共价固定在NiFe2O4埃洛石纳米管(halloysite nanotubes,HNTs)表面,制备了一种纳米复合材料,用于去除水中Pb(II)离子的活性吸附剂;上海交通大学自主研发的磁性铁基量子点吸附剂,能有效解决水污染处理难以分离沉淀的问题,并基于此申请了多项专利,受到了多家媒体报道[31]。此外,在基于“量子投融资前景”的访谈报道中,“小苗朗程”基金合伙人提出要投资关注自研量子材料领域的最新动向[32]。2022年,德国量子企业Pixel Photonics更是基于其在量子纳米技术领域的杰出表现,获得了德国风险投资基金、法国量子风险投资基金以及光子行业资深人士共计145万欧元的种子轮融资[33]。

图7 基于adsorption术语的语义建构词集
3.5.2 基于private术语的量子保密比较协议研究
基于private的语义建构词集如图8所示,解析后可将量子保密比较协议的相关研究视为量子信息领域弱信号之一。具体来说,随着近年来量子计算机的快速发展,其卓越的计算性能引发了多位用户间集体计算的信任和安全问题,因此,量子领域的多方安全计算问题受到了学者们的关注。2021年,北京邮电大学李剑团队探索了基于单粒子态和最大纠缠态的多方量子保密比较协议研究,能够提升协议的灵活性和安全性,减少资源的消耗,是量子信息领域未来重要的研究方向[34]。此外,在基于“量子投融资前景”的访谈报道中,辰幔资本创始合伙人明确提出投融资机构在短期内更青睐量子保密通信赛道[33]。2023年,量子技术公司Sandbox AQ基于其在量子计算、保密安全方面的研究突破获5亿美元融资[35]。

图8 基于private术语的语义建构词集
3.5.3 基于patient术语的量子点医学研究
基于patient术语的语义建构词集如图9所示,解析后可将量子点医学的相关研究视为量子信息领域弱信号之一。具体来说,随着现代检验医学的不断进步,量子信息与医学、化学、生物学等多学科交叉结合已成为必然发展趋势并受到广泛关注,而量子点作为极具应用前景的新型纳米材料,为医学研究和疾病治疗带来了新的思路。2020年,Perini等[36]提出通过石墨烯量子点(GQD)改变膜通透性,促进U87细胞内Dox的摄取,可用于脑癌的联合治疗,能够提高化疗的疗效,同时减少其剂量需求和副作用,从而改善患者的生活质量。因此,量子点医学的相关研究同样为量子信息领域重要弱信号之一。此外,在“2022年十大量子计算融资排名”报道中,对IQM(1.28亿欧元)和Qubit Phar‐maceuticals(1600万欧元)两家机构的投融资操作中均提出了重点关注运用量子技术来解决疾病治疗、医疗保健领域的挑战性问题[37]。

图9 基于patient术语的语义建构词集
3.5.4 基于game术语的量子决策/博弈研究
基于game的语义建构词集如图10所示,解析后可将基于量子游戏的决策/博弈相关研究视为量子信息领域弱信号之一。具体来说,量子决策是通过对认知科学中的决策现象进行建模,运用量子力学理论的数学方法,研究与描述决策的理论;其目标是在传统经典理论的基础上推进模型。而博弈论的经典模型,如囚徒困境、鹰鸽博弈等,均可以通过量子决策进行新的研究,提出新的解决方案。例如,Jabir等[38]将量子决策应用到鹰鸽博弈中,寻求量子鹰鸽博弈游戏的平衡解,并提供了随机策略的帕累托最优,证实了量子博弈的均衡解是唯一的。此外,量子博弈作为量子计算,甚至是量子体系的底层理论,更是在投融资界受到风险投资基金和资本方的重点关注,世界基金、三星NEXT、深创投、中信证券,甚至东京大学投资集团、牛津科学企业、斯坦福校友投资集团等投资方均有对量子计算领域的投资操作[37]。

图10 基于game术语的语义建构词集
除上述分析实例外,本文识别出的量子信息领域新兴技术弱信号仍有诸多待解释内容。鉴于安索夫提出的弱信号识别中的三层过滤器理论[19],对不同信息需求者而言,其评价认定的弱信号方向也不同,难以论述全部识别结果。但本文提出的结合异类数据筛选和关键术语语义建构的弱信号识别方法仍有助于决策者和研发人员从海量信息中提取有效的弱信号信息,以便辅助和支撑决策。
4 结 语
若要发挥技术预见研究中的“耳目”“尖兵”之作用,就要提早识别和确定新兴技术弱信号之内容。本文结合安索夫三层过滤器理论和意义建构理论,提出了一种基于异类数据和语义建构的新兴技术弱信号识别方法,具体涵盖数据获取、特征量化模型构建、异类数据筛选、关键术语抽取、弱信号术语识别以及语义建构与评估的识别全流程方法,并围绕量子信息技术领域开展实证研究。通过分析和论证,最终发现,未来量子信息领域的新兴技术弱信号包括量子点吸附、量子保密协议、量子点医学和量子博弈等相关研究。识别结果均得到当前研究的支持,证实了本文识别方法的有效性,能够为决策者和技术研发人员提供决策支持。
本文的创新点主要包括:在选题方面,基于已有弱信号的多元研究视角,本文从新兴技术视角开展研究,拓展和丰富了弱信号研究内涵,提出了新兴技术弱信号识别的研究思路,丰富了弱信号识别的研究价值;在理论方面,本文基于安索夫三层过滤器理论设计研究框架设计的“新兴技术弱信号”识别方法是对“观察-认知-决策过滤器”模型的创新实践和有效补充;在弱信号含义解析方面,基于意义建构理论,本文通过语义建构的方式,结合术语上下文语境来挖掘和解析弱信号术语的含义,有效克服了弱信号解析困难,是对已有研究的有效补充。
另外,本文仍有可改进之处。未来可考虑综合多源数据进行识别、优化异类数据筛选指标、扩大技术应用领域等,从而提升本文方法的普适性。
