基于煤矿井下不安全行为知识图谱构建方法
2024-03-01付燕刘致豪叶鸥
付燕, 刘致豪, 叶鸥
(西安科技大学 计算机科学与技术学院,陕西 西安 710054)
0 引言
近年来虽然煤矿井下事故发生率逐年降低,但每年仍有较多的煤矿井下安全生产事故发生。据相关统计,由于工作人员的不安全行为导致的安全生产事故在中国煤矿井下安全生产事故中占比高达97.67%[1]。因此,研究井下工作人员的不安全行为对降低事故发生率、实现煤矿井下安全生产具有重要意义。
由于煤矿数据的复杂性,利用大数据安全管理系统难以实现结构化不安全行为知识的语义关联及知识推理。知识图谱拥有较好的知识结构性及较强的表达性,能更加直观地描述各类概念之间的关系,从而实现井下不安全行为数据挖掘。知识图谱按照构造方式的不同可分为基于规则的知识图谱构建方法、基于统计的知识图谱构建方法和基于深度学习的知识图谱构建方法3 类。① 基于规则的知识图谱构建方法。N. Guarino 等[2]提出基于本体学的知识表示和推理方法OntoClean,其通过定义本体的基本概念、属性和关系等方式来表示和推理知识,OntoClean 已广泛应用于语义Web 和知识图谱的构建。但OntoClean 只能处理简单、单一的知识,难以应用于丰富、复杂的知识领域中。Horrocks 等[3]提出SWRL(A Semantic Web rule language combining OWL and RuleML),该方法可与OWL(Web Ontology Language)等本体语言结合使用,以表示更加丰富和复杂的知识,可处理多层次和不对称的语义关系。但SWRL和OWL 这2 种基于规则的方法需领域专家对知识进行抽象和分类,且需手动构建规则和逻辑表达式,知识图谱的构建过程较耗时和复杂,且缺乏自适应性。② 基于统计的知识图谱构建方法。A.Bordes 等[4]提出了一种基于超平面转换的知识图谱嵌入方法,称为TransE,该方法使用向量空间中的超平面来表示实体和关系之间的转换,以便在低维空间中对知识图谱进行建模。但该方法只能处理单一类型的实体。 Wang Zhen 等[5]对TransE 进行了扩展,提出了一种适用于含有异质实体的知识图谱嵌入方法,称为TransH,该方法将实体投影到不同的超平面上,以处理不同类型的实体。但基于统计的知识图谱构建方法只能对语言表面的信息进行提取,难以理解语言中的隐含信息和语义,难以准确捕捉实体之间的关系。③ 基于深度学习的知识图谱构建方法。刘文聪等[6]采用双向长短时记忆(Bidirectional Long Short-Term Memory,BiLSTM)模型与条件随机场(Conditional Random Field,CRF)模型相结合的方式抽取中文地质时间信息,在一定程度上解决了传统方法特征提取不足的问题。吴闯等[7]利用BERT(Bidirectional Encoder Representations from Transformers)-BiLSTM-CRF 模型对航空发动机设备润滑系统进行命名实体识别,先利用BERT 模型进行词向量化,再进行实体识别,在一定程度上改善了实体识别的效果。然而,传统的BERT 模型在进行词语向量化时易造成大量实体和语义丢失。
虽然知识图谱已广泛应用于各个领域,但在煤矿安全方面,尤其在煤矿井下不安全行为方面的研究较少。因此,本文提出了一种基于煤矿井下不安全行为知识图谱构建方法。首先,针对煤矿井下不安全行为的命名实体识别问题,结合现有的知识,用传统机器学习和深度学习算法相结合的方法进行命名实体识别,采用RoBERTa(Robustly Optimized BERT pretraining Approach)进行词语向量化后,通过BiLSTM 对向量进行标注,提高网络模型对上下文特征的捕捉能力。其次,根据语句的结构特点,设计了基于知识三元组的依存句法树结构,并根据该数据结构对井下不安全行为领域的知识资源进行知识抽取与表示。最后,利用图数据库Neo4j 存储煤矿井下不安全行为知识,形成井下不安全行为知识图谱。
1 相关理论方法
知识图谱的主要任务是使用符号的方式去描述本体的概念及其相互之间的关系,其本身是具有属性的实体通过关系链接而成的网状知识库。其基本组成单位是“实体-关系-实体”及“实体-属性-属性值”三元组[8-10]。当前,知识图谱主要分为自顶向下及自底向上2 种构建方式。
1.1 自顶向下的知识图谱构建方法
自顶向下的知识图谱构建方法是从较高质量的结构化数据源中获取数据资源,并根据结构化数据源中预先定义的实体关系来构建完整的知识图谱[11-12]。自顶向下的知识图谱构建分为以下3 个步骤:① 通过大量结构化数据源完成本体知识库的构建,包括本体学习和相应规则制定。② 进行实体学习,主要包括实体链接和实体填充2 项任务。③ 构建图谱。
1.2 自底向上的知识图谱构建方法
自底向上的知识图谱构建方法是从大量知识密度小且没有固定关系的半结构化[13-14]、非结构化数据源中获取知识资源,从而完成知识图谱的构建。自底向上的知识图谱构建主要包含知识抽取、知识融会及图谱构建3 个步骤。其中知识抽取包含实体识别、关系抽取及属性抽取3 个任务,知识融会的主要任务是进行实体消歧。
2 知识图谱构建方法
由于本文采用的是开放数据源,其中包含大量半结构化、非结构化数据,故而采用自底向上的知识图谱构建方法。
2.1 数据的获取、预处理
本文采用的数据源主要为开放的文献知识资源及《煤矿安全规程》中的相关规定。其中文献知识资源是从知网中主题或关键词为“不安全行为 煤矿”检索得到的文献。经筛选,保留其中210 篇作为实验数据。本文采用BIO(Beginning-Inside-Outside)标准标注策略对不安全行为实体进行标注。通过参考中国国家标准化管理委员会发布的煤矿科技术语汇总表,对文献[1]、文献[15]中关于不安全行为的研究内容进行分析,将井下不安全行为实体分为遗忘性行为、粗心性行为、错误性行为、违反性行为、关联因素影响行为及导致后果6 种,见表1。将属于一个命名实体开始的token 标记为B-label,对于属于命名实体类型但不是第1 个字的token 标记为I-label,其他不属于命名实体范围的统一用O 进行标记。

表1 实体待预测标签Table 1 Entity to be predicted labels
2.2 实体识别
针对井下不安全行为实体识别中实体数量庞大、交替频繁、语义复杂等问题,需选择合适的命名实体识别方法。基于监督的统计学习方法在实体识别过程中依赖大型标注语料库进行模型训练,不适合没有专业大型语料库的井下不安全行为,容易出现实体识别不准确的情况。因此,本文采用改进神经网络模型实现井下不安全行为实体识别。在BiLSTM-CRF 基础上引入RoBERTa 及多层感知机(Multilayer Perceptron,MLP)作为井下不安全行为命名实体识别模型(RoBERTa-BiLSTM-MLP-CRF)。将预处理后的数据分为训练集和测试集,训练集通过RoBERTa 模型将输入的文本序列转换为具有丰富上下文语义的词向量,RoBERTa 模型的输出向量作为BiLSTM 模型的输入,以提取上下文的特征值。由于所获得的煤矿井下不安全行为语料数据量少,为了获得更好的模型训练效果,在BiLSTM 层与CRF 层中间加入MLP,并将开源数据集的输出维度与煤矿数据集输出维度进行统一,达到迁移学习的目的。CRF 模型用于标注输入注释序列的实体。具体实体识别流程如图1 所示。

图1 基于RoBERTa-BiLSTM-MLP-CRF 实体识别过程Fig. 1 RoBERTa-BiLSTM-MLP-CRF based entity recognition
2.2.1 RoBERTa 模型
RoBERTa 模型是一种基于Transformer 神经网络的预训练模型。当前,基于神经网络的预训练技术主要分为静态词向量与动态词向量2 大类。① 静态词向量。Word2Vec[16]词向量模型能从大规模语料库中得到高精度的词向量。Glove[17]模型结合了 Word2Vec 及矩阵分解模型(Singular Value Decomposition,SVD)的优点,训练速度显著提高。静态词向量模型在一定程度上可得到较为精准的词向量,但无法解决一词多义的问题。② 动态词向量。ELMo 模型[18]采用长短时记忆(Long Short-Term Memory,LSTM)模型,在一定程度上解决了一词多义的问题。但ELMo 模型采用的双向拼接特征融合方式比一体化的融合方式要弱。BERT 模型[19]采用双向语言模型、掩码语言模型(Masked Language Model,MLM)和NSP(Next Sentence Prediction)3 种技术,在现阶段自然语言领域中被广泛应用,但BERT 庞大的参数量使得实际应用面临困难。RoBERTa 模型对 BERT 模型的超参数进行改进,与BERT 模型相比,RoBERTa 模型拥有更优越的模型性能。RoBERTa采用动态掩码的方式学习不同的特征,解决了传统BERT 训练时大量短语和实体丢失的问题。由于煤矿井下不安全行为文本数据比较复杂,存在大量一词多义的现象,导致实体识别效果较差,因此,本文选择RoBERTa 作为词向量抽取模型,其模型如图2所示,其中X1—X4为词的向量化特征,E1—E4为输入文本序列。
2.2.2 BiLSTM 模型
LSTM 模型在进行文本特征提取时,利用其复杂的网络结构可较好地捕获长距离依赖关系,但对于输入信息无法进行反方向解码,不能捕获双向语义依赖关系。煤矿井下不安全行为文本数据具有冗余特性,其数据文本语句通常较长且关系复杂。因此,提出BiLSTM 模型,如图3 所示,Xt为当前时刻t的词向量化特征,ht为当前时刻t的隐藏状态,表示BiLSTM 模型的输出结果。BiLSTM 模型在命名实体识别模型中的作用是捕获文本序列的上下文特征,对双向语义依赖关系进行捕捉。

图3 BiLSTM 模型Fig. 3 BiLSTM model
2.2.3 MLP 模型
由于煤炭领域数据的复杂性,能够收集到的煤矿井下不安全行为数据量较小,模型训练结果相对较差。为解决该问题,本文在BiLSTM 层与CRF 层中间加入MLP[20],将开源数据集输出维度与煤矿数据输出维度进行统一,利用知识迁移的方式弥补数据量不足的问题。首先,通过RoBERTa、BiLSTM与清华大学的开源数据集THUCNews 进行训练,得到1 个初始模型,该模型已获得THUCNews 数据集中包含的一些特征参数,将其作为煤矿数据集训练初始模型参数;其次,通过MLP 将开源数据集THUCNews 输出维度与煤矿数据集输出维度进行统一。MLP 模型结构如图4 所示。

图4 MLP 模型Fig. 4 MLP model
2.2.4 CRF 模型
虽然经过BiLSTM 及MLP 模型之后输出的信息是选择输出概率最高的标签,但没有考虑到不同单词之间的关系,输出的标签可能会混淆且缺乏逻辑。因此,引入CRF 模型来解决单词关系不识别问题,并捕获全文信息和预测结果。该模型可表示为P(x|y),其中,x为输入变量,表示输入的观测序列;y为输出序列,表示对应x的标签序列。假设给定一个输入序列x=(x1,x2,···,xn)和相应的标注序列y=(y1,y2,···,yn),且每个(xi,yi)对是线性链中最大团,若同时满足式(1),则称P(x|y)为线性链的条件随机场。
式中:i为当前字符所在位置;n为输入句子长度;yi和yi-1分别为当前单词的标签及前一个单词的标签。
给定预设的观测序列x,CRF 模型求解隐态序列y的公式为
式中:tj为i处的传递特征; λj为tj对应的权重;sl为i处的状态特征; µl为sl对应的权重;j和l为特征函数的数量;z(x)为归化因子。
线性链CRF 模型(图5)对标签之间的约束关系进行预测,以此提高命名实体识别的准确性。

图5 线性链CRF 模型Fig. 5 Linear chain CRF model
对每个单词进行评分,条件概率模型P(x|y)通过最大似然估计来计算。在实际预测过程中,对于给定的观测序列,计算其最大标签序列。评分公式为
式中:ui为i处词向量的特征;fj为ui对应的权重;m为特征函数的总数量。
2.2.5 RoBERTa-BiLSTM-MLP-CRF 模型
RoBERTa-BiLSTM-MLP-CRF 模型如图6 所示,其中xt为当前时刻的输入特征。模型从下往上依次是字向量层RoBERTa、融合层、Farward LSTMBackward LSTM、输出层、MLP 和CRF 层。该模型输入的是序列化文本,如图中输入层输入的文本“井下打架”。在CRF 层输出相应的注释序列,输出序列采用BIO 标注方式进行标注。

图6 RoBERTa-BiLSTM-MLP-CRF 模型Fig. 6 RoBERTa-BiLSTM-MLP-CRF model
2.2.6 模型评估标准
采用精确率P、召回率R和F1值3 个标准来评价RoBERTa-BiLSTM-MLP-CRF 模型对井下不安全行为实体识别的效果。
式中:NTP为被预测为正样本的正样本数量;NFP为被预测为正样本的负样本数量;NFN为被预测为负样本的正样本数量。
2.3 关系抽取
本文数据来源于开放的相关文献及《煤矿安全规程》,其中《煤矿安全规程》中的文本数据为一条条规章制度,满足依存句法的单句中只能存在一个核心成分、每一个词语仅有一个依存对象、核心词不可与其两边的词产生依存关系等条件,且开放的文献文本知识一般高度凝练,故采用依存句法进行关系抽取。王志广等[21]在进行地址领域实体关系抽取时提出联合抽取模型,该方法在一定程度上解决了并列句三元组抽取丰富的问题,但依然比较容易出现模式不匹配的现象,会造成大量知识不能被抽取。针对该问题, 本文将句子的依存关系转换为语法树,分析比对三元组知识的枝条结构,利用树的遍历去搜索整个句子的语法树结构;并将每个并列句视为单独存在的句子,分步对其进行三元组抽取,更深度地抽取语句知识。
2.4 知识融会
知识融会的主要任务是对知识信息进行有效融合统一,将上述流程中得到的一些缺乏层次性与逻辑性的冗余信息及错误概念剔除,从而提高知识图谱数据库的知识质量[22]。知识融会主要包含实体消歧[23]和共指消解2 个任务。实体消歧的任务是解决相同表述指代不同实体的问题。例如,“煤炭运输”在本文中指的是“井下劳作中的煤炭运输”,有的描述则是指“运货火车的煤炭运输”,因此,要联系上下文的语义,明确命名实体的确切含义。共指消解的任务是处理多种描述指代同一实体的问题,例如,“个体因素”“个体原因”“单人因素”均对应的是“个体因素”这一单元实体,在人工撰写的安全报告、事故报告中,用语不规范现象普遍存在。为解决此问题,本文采用余弦距离和Jaccard 相关系数相结合的方式计算井下不安全行为实体之间的相似度。通过相似度确定对齐实体是否匹配,从而实现知识融会,得到统一规范的井下不安全行为实体名称。
式中:Sconsine为余弦相似度;SJarccard为Jarccard 相似度;A和Q为2 个实体的属性字符串。
任意2 个实体之间的语义相似度大小与余弦相似度和Jarccard 相似度的大小成正比。井下不安全行为文本知识实体表述见表2,可看出对于“不安全动作”和“不安全行为”2 个不同表述的实体,其Jarccard 相似度SJarccard为0.43,余弦相似度Sconsine达到0.60,进而得到“不安全动作”和“不安全行为”2 个实体实际上为同一概念,应该融合为同一实体。

表2 实体相似度计算实例Table 2 Example of entity similarity calculation
2.5 知识存储
井下不安全行为文本数据经过上述流程处理后,从多元异构状态转换为结构化状态。知识存储的任务就是将各类知识存储为“实体-关系-实体”或“实体-关系-属性”的三元组形式。
本文采用图数据库Neo4j 来实现井下不安全行为知识的存储。考虑Neo4j 只需插入节点与边就可实现数据的高效存储和查询[24],利用带属性的图模型将实体存储为节点,实体属性存储为节点属性,边和边的属性表示关系与关系属性,标签表示描述知识的概念。基于Neo4j 的知识存储方案见表3。

表3 基于Neo4j 的知识存储方案Table 3 Neo4j-based knowledge storage solutions
3 实验结果与分析
3.1 模型参数设置
本次实验采用TensorFlow1.15.5 框架进行模型的搭建,实验中批尺寸为32,学习率为0.001,迭代次数为50。
3.2 实体识别结果
实验采用预处理的井下不安全行为文本语料库进行训练。基于该文本数据集,本文预定义了遗忘性行为、粗心性行为、错误性行为、违反性行为、关联因素影响行为、导致后果6 种实体类型,识别效果见表4。

表4 实体类型识别效果Table 4 Entity type identification effect%
由表4 可看出,本文模型对于导致结果、违反性行为、错误性行为及粗心性行为4 类实体具有较好的识别效果,其准确率分别为86.7%,80.3%,80.7%,77.4%,对于遗忘性行为及关联因素影响性行为识别效果较差,其准确率分别为63.5%,73.0%。这是因为导致后果、违反性行为、错误性行为及粗心性行为包含的实体表达形式较为固定,而遗忘性行为及关联因素影响性行为包含的实体语义复杂且较长,从而导致识别效果较差。
为了验证本文模型的有效性,将本文模型与BiLSTM-CRF, BERT-BiLSTM-CRF, RoBERTa-BiLSTM-CRF 模型进行对比,结果见表5。
由表5 可看出,BERT-BiLSTM-CRF 模型的准确率比 BiLSTM-CRF 模型提高了3.7%,这表明进行实体识别之前进行词向量化是必要的;RoBERTa-BiLSTM-CRF 模型的准确率较BERT-BiLSTM-CRF模型提高了0.7%,这表明RoBERTa 模型比BERT 模型更适合本次任务;RoBERTa-BiLSTM-MLP-CRF模型的准确率、召回率、F1较RoBERTa-BiLSTM-CRF模型分别提高了1.6%,1.5%,1.6%,这表明添加MLP后能够学习更多公共数据集的特征,用此模型对公共数据集进行训练,对于本次实验有正确的导向作用。
3.3 知识图谱构建结果
以井下不安全行为文本中的实体为节点,以实体之间的关系为边,将其存储在Neo4j 图数据库中,从而构成煤矿井下不安全行为知识图谱。部分煤矿该图谱井下不安全行为知识图谱如图7 所示。可看出该图谱通过“包含”“关联”等关系将不安全行为与影响因素及行为类别连接起来,通过“违规作业”等关系将行为实体与发生部门连接起来,构建了井下不安全行为不同实体间的相关关系,为煤矿井下进行员工管理提供了强有力的支持,进而提高了井下安全管理效率 。
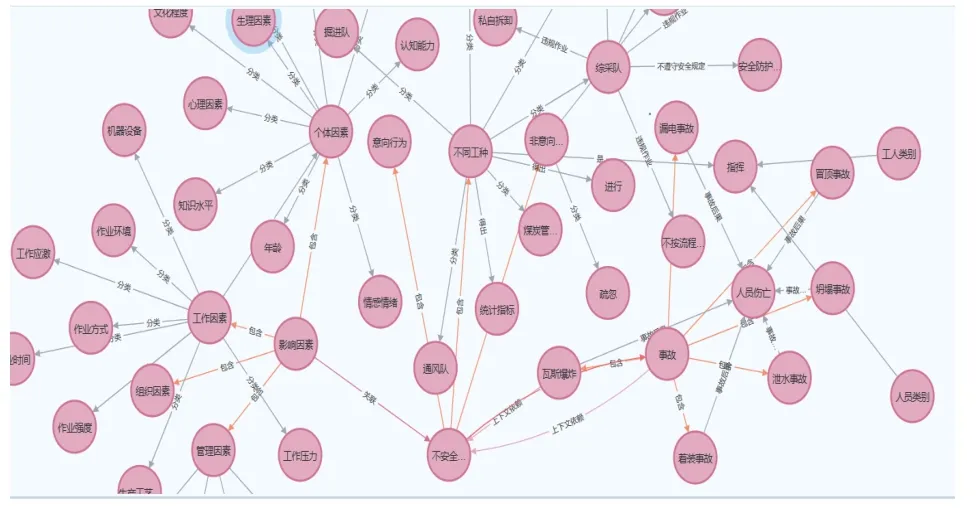
图7 部分煤矿井下不安全行为知识图谱Fig. 7 Knowledge graph of underground unsafe behavior in some underground coal mines
4 结论
1) 提出将句子的依存关系转化为语法树,分析比对三元组知识的枝条结构,利用树的遍历去搜索整个句子的语法树结构,实现煤矿井下知识三元组抽取。
2) 构建了煤矿井下不安全行为知识图谱,为煤矿井下进行安全管理提供了强有力的支持,进而提高了煤矿井下安全管理效率。
3) 在构造煤矿井下不安全行为命名实体识别与知识三元组抽取时,由于收集文本数据集只包含部分煤矿井下不安全行为,使得命名实体识别与知识三元组抽取具有局限性且不可避免地会出现缺失和错误。因此,下一步将逐步补充和完善煤矿井下不安全行为知识体系。
