基于对象模型的煤矿数据采集融合共享系统
2024-03-01尚伟栋王海力张晓霞王浩徐华龙
尚伟栋, 王海力, 张晓霞, 王浩, 徐华龙
(1. 山西天地王坡煤业有限公司,山西 晋城 048021;2. 煤炭科学研究总院有限公司 矿山大数据研究院,北京 100013;3. 煤炭科学技术研究院有限公司,北京 100013)
0 引言
当前煤矿智能化发展尚处于初级阶段[1],其发展理念和技术体系还不够成熟,“人、机、料、法、环”各个子系统通信协议、数据接口难以统一,数据难以融合,形成信息壁垒[2-4]。
数据采集、融合与共享是推动煤炭行业大数据技术发展的关键环节,有利于统一智能化煤矿的建设思路,众多学者对此展开了研究。杜毅博等[5]提出了基于位号的煤矿数据编码标准,便于后期处理过程中的数据关联分析。韩安[6]提出了利用Kafka 消息队列作为数据接入的协议,用Hadoop 作为数据存储的载体;数据共享采用SDK 函数接口为应用提供数据访问的方式。方乾等[7]提出了自动化系统采用EIP,Modbus,OPC,S7 协议采集数据,安全监测系统采用HTTP,WebSocket 等协议接入数据;关系型数据采用MySQL 存储,非关系型数据采用HBase,InfluxDB 等存储;数据共享采用WebService,Restful API,WebSocket 接口提供服务。
然而,随着煤矿智能化建设推进,矿山对数据融合的数量和质量要求大幅度提高。目前,基于大数据平台的数据融合系统在煤矿信息化发展过程中逐渐暴露出一定的局限性,主要表现如下。
1) 采用基于位号的煤矿数据编码标准能对设备按照统一规则进行数字编码,但编码的使用是松散的,不是整体访问的方式,更适合主数据管理场景使用,且对于查询整个设备断面数据的场景中,缺少设备对象化的标准。
2) 为了能够采集各种类型设备数据,数据采集支持多种通信协议,但由于通信协议格式各异,直接按照采集的格式存储数据,造成数据应用困难,大数据应用、分析数据需要多种语义解析才能实现相互理解。同时,数据采集规约实现大多基于Windows平台实现,不能满足煤炭行业基于Linux 内核国产化操作系统的要求。
3) 针对煤矿监控应用场景,从基于文件存储的Hadoop 中获取数据为监视界面提供实时刷新,但存储方式为散点方式,不能满足监视界面秒级数据刷新的要求。
4) 大部分基于互联网思想建设的煤矿大数据平台对历史数据的存储往往采用一种设备一张表模式,即为每一种设备设计一张表来存储历史数据,每一张表提供3 种接口(查询、删除、修改)访问历史数据。然而,由于煤矿设备种类繁多,该模式导致数据共享接口数量众多,且对于数据的准确性和完整性缺少治理,导致数据共享效率低、效果差。
本文提出一种基于对象模型的煤矿数据采集融合共享系统,首先通过规约采集或其他采集方式接入数据,其次将松散数据经过对象化映射、数据治理后存储到数据库中,然后以对象方式提供共享接口,最后通过数据融合共享安全规范验证及调用共享接口访问数据,以实现煤矿数据高效采集、融合和共享。
1 系统架构
基于对象模型的煤矿数据采集融合共享系统架构如图1 所示。设备层和感知层为系统提供数据源;数据接入层、数据融合层、数据共享层、应用层是系统的核心。
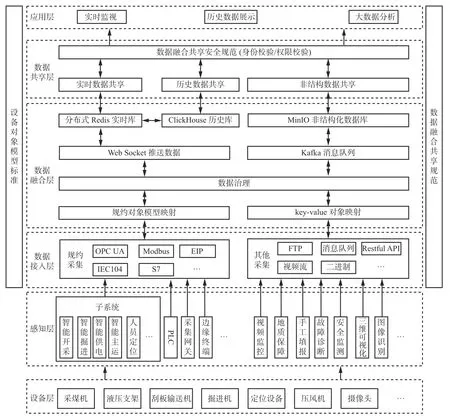
图1 基于对象模型的煤矿数据采集融合共享系统架构Fig. 1 Architecture of coal mine data acquisition, fusion and sharing system based on object model
1) 数据接入层。该层通过各种协议接入感知层从设备层采集的多源异构数据,向数据融合层提供原始数据源。数据接入方式:① 规约采集。采用即插即拔的工业协议库框架,支持常用的规约(如Modbus、S7、IEC101 和IEC104 等),可采集子系统(主要包括智能开采、智能掘进、智能主运、人员定位等系统)转发的数据或直接采集设备(主要包括PLC、采集网关、边缘终端等设备)的数据。② 其他采集。支持协议包括FTP、Restful API、视频流、文本和消息队列等,一般采集子系统(主要包括视频监控、地质保障、手工填报、故障诊断、安全监测、三维可视化、图像识别等系统)转发的数据。
2) 数据融合层。该层首先对数据接入层的数据进行标准化处理,规约采集的数据按照设备对象模型进行映射,其他采集数据采用key-value 方式进行映射。其次,根据数据治理标准,对对象化数据进行治理。然后,将治理后的实时数据存储到Redis 实时数据库中。最后,将对象化数据进行历史存储,存储方式分为2 种:① 规约对象方式。历史数据存储接口按照每个对象数据的采集周期从Redis 实时数据库中遍历及存储对象数据。② key-value 对象方式。将数据接入到Kafka 消息队列,通过Kafka 提供的组件直接存入MinIO 数据库。
3) 数据共享层。该层提供实时数据共享、历史数据共享和非结构数据共享3 种接口,为应用层提供数据服务。实时数据共享接口从分布式Redis 实时数据库获取数据,为应用层提供服务,由于实时监视对数据的访问速度要求很高,需要秒级刷新界面,而很多设备数据在1 s 内基本变化不大,所以采用变化推送的方式向界面推送数据;历史数据共享接口从ClickHouse 历史数据库获取数据,为应用层提供Restful API 接口访问服务;非结构数据共享接口从MinIO 数据库中获取数据,为应用层提供Restful API 接口访问服务。根据数据融合共享规范安全要求,应用访问需通过身份校验才能登录数据共享服务,通过权限校验才能获取具有授权的数据。
4) 应用层。该层是数据使用层,调用数据共享层提供的接口查询数据进行使用。
2 系统关键技术
2.1 设备对象模型标准化
煤矿设备种类多,且每种设备生产厂家采用的工艺不同,导致设备参数存在不统一的现象[8-10]。虽然基于位号的煤矿数据编码标准提供了设备和属性点的命名规范,但缺少软件层面的实现。为使设备能够在软件层面抽象表达,本文基于煤矿数据编码标准设计设备对象模型,如图2 所示。该模型可兼容设备参数之间的差异,具有可扩展性,灵活度高。

图2 设备对象模型Fig. 2 Device object model
设备对象模型涵盖公共信息和扩展信息。
1) 公共信息。用于定义煤矿设备的通用模型,包括基础模型、通信模型、位置模型、属性点模型:① 基础模型包括设备的名称、生产厂家、状态、版本信息、铭牌参数等。② 通信模型包括设备联网方式、网络参数等。③ 位置模型包括位置描述、经度、纬度等。④ 属性点模型包括类ID、属性点ID、名称、单位类型、数据类型、数据长度、读写标志等,其中类ID 和属性点ID 是固定的。固定的类ID 有利于应用区分不同种类的设备,避免不同应用之间的语义转换;在工程复制的场景中,由于属性点ID 是固定的,复制源工程中的设备属性生成目标工程中的设备属性,不需要修改属性点ID,减少工程开发工作量。
设备对象模型模版采用json 格式实现,描述如下:

其中,uuid 通过雪花算法自动生成,保证矿井设备的唯一性,避免设备识别错误,points 以数组的方式表示。
2) 扩展信息。因为不同厂家的设备除了具有公共信息模型的属性外,还有一些个性化属性,为保证设备对象模型的完整性,需将这些个性化属性存放到扩展模型中。
2.2 数据接入
数据接入的方式分为工业规约采集、Restful API 问答式采集和文件数据采集。
1) 工业规约采集。煤炭行业部分厂家基于Windows 操作系统开发通信规约[10],而近年煤炭行业规定要求使用基于Linux 内核的国产化操作系统,基于Windows 操作系统的通信规约采集不能运行在基于Linux 内核的操作系统中。本文采用跨操作系统的C++语言开发规约。工业规约采集实现关键技术:① 即插即拔机制。每一种规约封装成动态库,框架采用动态加载规约库的方式实现即插即拔,由于每种操作系统的动态库加载函数不一致,设计一个函数对描述操作系统的宏定义(如Windows 的宏定义为Win32)判断,对不同的操作系统,调用对应的动态库加载函数,实现动态库的动态加载。② 报文解析。虽然每种工业规约都发布了标准,但设备厂家对不能满足其要求的标准规约进行非标扩展,导致1 种规约产生多个变种。为兼容多个变种,标准部分定义基类,其他变种采用C++的继承机制,继承基类,重写非标准部分的函数,为规约扩展提供了灵活的机制。③ 报文监视。上位机作为客户端按照规约的规范从下位机采集数据,下位机作为服务端按照规约的规范为上位机提供数据转发服务。当上位机和下位机规约通信出现数据不一致的问题后,需要查看报文才能快速排查错误。规约运行在基于Linux 内核的操作系统中,而报文监视工具为了方便查找问题,运行在Windows 操作系统中。虽然采用跨操作系统的C++语言实现报文解析, 但Windows 和Linux 存在字节存储大小端的问题,如果不经过转换,会导致数据不一致。为避免该错误,采用统一的网络字节序进行数据交互。网络字节序采用大端方式存储数据,Windows 操作系统采用小端字节序存储数据,需要调用函数将数据转换成网络字节序,而基于Linux 内核的操作系统采用大端字节序存储数据,不需要转换。工业规约采集框架如图3 所示。
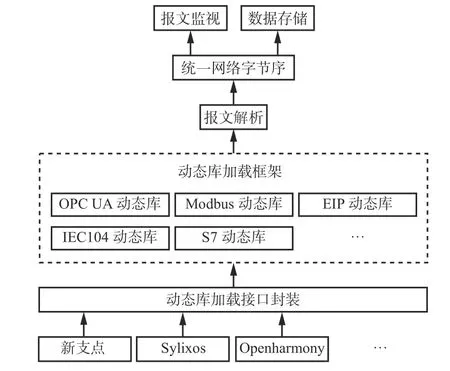
图3 工业规约采集框架Fig. 3 Industrial protocol acquisition framework
2) Restful API 问答式采集。目前煤矿上位机采集下位机数据时,采用下位机向上位机post 的方式推送数据,其弊端是上位机不能快速定位数据传输异常原因是网络中断还是下位机程序崩溃。为避免该问题,采用“一问一答”方式,上位机调用Restful API 接口,周期查询下位机数据,根据接口各响应状态返回值(200,400,404,500 等)判断通信异常情况。
3) 文件数据采集。图片文件、地质保障文件、二进制文件(包括视频流)等数据一般作为一个整体采集[10-12],按照key-value 的方式存储到MinIO 数据库中。
2.3 数据融合
将接入的数据进行融合:首先对无序的数据进行设备对象模型映射,然后对模型化后的数据进行治理,最后对治理后的对象数据进行存储。
2.3.1 设备对象模型映射
由于煤矿设备数量、种类众多,数据类型多样[13-14],工业规约采集的数据不含描述信息,需要额外的信息来描述其语义[15-16],导致数据的准确性、完整性、一致性和可靠性等方面存在问题,所以需要按照对象模型映射数据,确保融合后的数据按照标准化对象模型为数据应用提供服务。
通过规约采集的数据测点杂乱无章[17],命名规范、数据内容、数据字典、数据格式不能在规约中体现,需要设计一个测点映射表。测点映射表包含源测点信息和目的映射信息:源测点信息包括规约的点号和数据长度;目的映射信息包括名字、映射的数据类型、数据长度、对象属性ID 和单位。当数据标准化映射时,进程根据映射表的映射规则解析,将规约的点号映射到对象模型属性点的点号中,同时,将采集值按照映射的目标类型和长度进行转换,然后动态对转换后的采集值进行对象化缓存,供下一步数据治理使用。
通过Restful API 采集的数据大多数是json 数据格式,这类数据带有名称、值等信息,但这些信息对于设备对象模型映射来说还不够全面。需设计一个json 数据映射表,增加数据描述(包括名称、数据类型、值、数据长度、单位),从而提供对象映射全量信息。当数据标准化映射时,进程根据映射表的映射规则解析,将源json 中key 和目标json 中key 匹配,将源json 中属性值取出,按照映射的目标类型和长度进行转换,写入目标json 中属性值,实现json 格式数据的对象化采集。
设备对象模型映射过程如图4 所示。
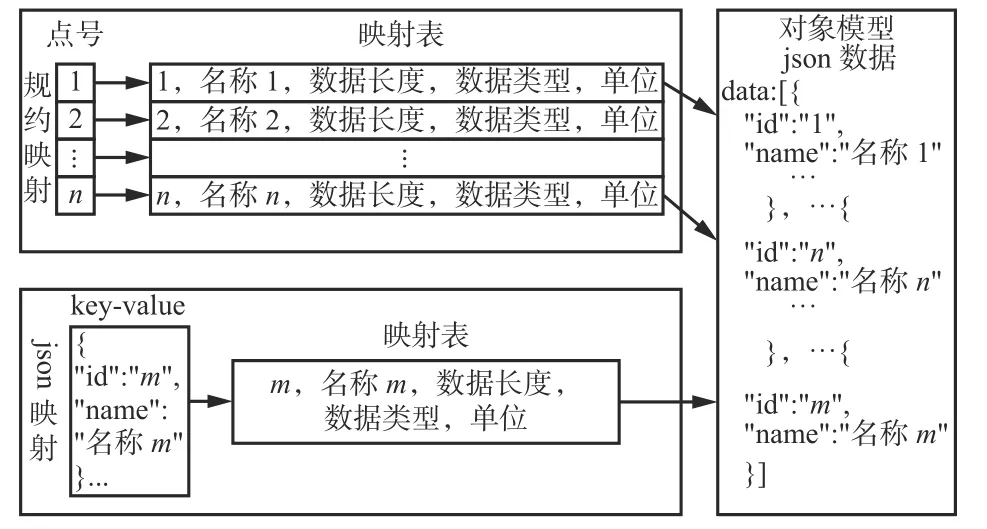
图4 设备对象模型映射过程Fig. 4 Device object model mapping process
2.3.2 数据治理
数据治理采用的方式主要包括公式计算和数据监视报警2 种。
1) 公式计算。煤矿采集的数据大多是原始数据,数据应用需要利用原始数据进行计算、统计、转换等[18-21]。目前采用的方式是在数据使用时进行计算,但由于煤矿数据系统众多、数据来源复杂、数据类型多样,如果请求的数据量很大,会出现计算性能瓶颈问题,导致数据计算效率低。本文按照数据治理规则,在数据存储之前对统一采集的数据进行公式计算和处理,提高数据的计算性能。公式计算的关键点是在规约解析后,在存储之前对测点进行数学运算,主要包括加法、减法、乘法、除法等基本运算,以及开方、平方、取模等高级运算,还可对值进行取反计算。实现步骤:首先制定公式模板,其次将计算的采集点作为公式参数输入到模板中,然后模板调用系统集成的Python math 数学库,最后实现复杂的数学计算。采集的数据在存储之前,按照配置的信息调用函数模板周期性执行计算,实现数据计算、统计、转换的目的。
2) 数据监视报警。包括异常值和越限阈值报警:① 数据采集设备在长时间工作过程中可能出现异常值,此外由于网络通信故障,不能保证采集数据的完整性。对异常、不完整的数据进行报警、删除或更正,异常值不参与公式计算,确保最终结果可靠和准确[7]。② 设备运行参数受到约束条件的影响而不能超出一定范围,如果测量参数超过了设定的极限值,需触发越限报警信号,供用户对设备工作状态进行判断。数据监视报警的步骤:先根据经验配置数据异常值或越限阈值,采集的数据在存储之前与阈值比较,如果超过阈值,产生相应的报警记录并存到报警表中,为挖掘传感器故障率和设备故障预警等分析提供数据支撑。
2.3.3 数据存储
设备数据按照对象模型的方式存储是指将采集的松散信息映射成对象模型后进行集中存储,这是一种存储海量数据的高速存储方案,将设备多个参数1 次存储,减少网络访问和数据存储的操作次数,从而提高数据存储效率,节省存储空间。
数据存储分为内存存储和文件存储,对于实时性要求高的监视类应用,将采集的数据存储到内存数据库中,将文件和视频流(回放视频)等实时性要求不高的数据存储到基于文件的数据库中。
1) 内存存储。针对煤矿数据量大、处理速度快的需求,内存数据库采用分布式部署的Redis。Redis分布式部署需要基于slot 计算存储节点,采用CRC16 算法计算存储节点,利用测点的key 对16 284取模,得到的结果就是对应的slot,调用Redis 分布式访问接口Jedis,根据slot 位置把测点值存到Redis 库中。采用Redis String 数据类型(key-value 方式)存储设备对象化数据:对于测点的key,利用对象模型的优点,采用四维参数(即通道号、类ID、实例号、属性点ID),同一通道的测点可分配到同一slot,提高数据访问速度,满足监控秒级数据刷新的要求;对于测点的value,则采用json 格式的对象数据。为提高存储效率和节省存储空间,动态变化的属性点模型数据采用周期更新同一条记录的方式,其他基础模型、网络模型、位置模型变化频次较少,数据变化时才更新记录。
2) 文件存储。包括结构化数据和非结构化数据存储:① 结构化数据一般存储在ClickHouse 中,ClickHouse 采用分布式部署。针对煤矿数据规模大的需求,通常采用分表(即按照每日或每月一张表)的方式来存储数据,对于跨年、跨月的数据查询需要查询多张表,效率非常低;此外,按照互联网的方式,为每一种设备设计一张表存储数据,导致数据库表数量众多,为数据使用带来麻烦。为避免该情况,所有的对象数据用一张表存储,这得益于ClickHouse分布式表具有分布式存储数据的功能。需制定分布式存储策略,采用对象模型设备ID 对ClickHouse 节点数取模的方法计算存储节点,将对象存储到相应的节点中。② 非结构化数据一般是文本文件、视频流、二进制文件,采用MinIO 数据库以整体方式存储此类数据。MinIO 通过Kafka 接入流式数据,按照key-value 对象化方式存储,采用分布式存储和访问的策略,提高数据存储和访问性能。
2.4 数据共享接口
系统提供对象化的数据共享接口,为应用层应用提供数据服务。鉴于非结构化的MinIO 数据共享接口直接通过key-value 方式访问,比较简单,所以本文重点介绍实时数据共享接口和历史数据共享接口关键技术。
如果采用一种设备一张表存储数据的方式[20],由于煤矿设备种类多,数据服务接口至少有200 个,数据应用访问与之匹配的接口也很多,给数据使用者增加了工作量。由于本文所有的对象数据存储是基于一张表,所以对象化的数据共享接口可简化到实时数据共享接口和历史数据共享接口。
1) 实时数据共享接口。输入参数为设备ID 数组。首先根据设备ID 进行权限校验,如果通过权限校验,对16 284 取模获取数据存储的slot,然后按照slot 查找到对应的Redis 节点,接着遍历该节点的key 获取value(对象化数据),最后返回对象化数据数组。如果设备数据不存在,用NULL 表示空值返回;如果没有通过权限校验,返回“没有权限,获取数据错误”。另外,对于实时性要求高的场景,采用Web Socket 服务端向客户端推送数据的方式,减少客户端和服务端的网络通信时间,提高数据访问性能。
2) 历史数据共享接口。输入参数为设备ID 数组、开始时间、结束时间。首先根据设备ID 进行权限校验,如果通过权限校验,对ClickHouse 节点数取模,然后根据取模结果得到存储节点,接着结合输入时间等条件查询历史数据,最后返回对象化数据数组。如果设备数据不存在,用NULL 表示空值返回。
对象化的数据共享接口具有查询效率高的特点,仅需通过1 次查询,即可将整个设备属性数据以对象方式存储到缓存中,再按照请求的属性点从对象模型中抽取解析返回需要的数据,解决了松散式数据共享接口需多次查询导致耗时长的问题。
3 系统应用
基于对象模型的煤矿数据采集融合共享系统目前在山西天地王坡煤业有限公司进行了工程实践。在设计阶段对全矿井设备进行了对象模型规划,形成了全矿井的设备对象模型,实现了对象模型标准化建设,解决了数据采集和数据共享以对象模型交互的标准问题,显著降低了数据使用过程中语义解析的难度。
通过工业规约对综采工作面、综掘工作面、主运输系统、排水系统、通风系统、供电系统、智能污水处理系统、智能压风系统、铁路智能装车系统和汽车智能装运系统的设备进行数据采集,通过Restful API 方式对安全监测设备进行数据采集,通过私有协议对人员定位系统的设备和人员进行数据采集,通过二进制流式方式对视频进行数据采集,并按照对象模型的映射标准,将各种设备数据以对象化方式进行融合和存储,为智能化业务场景的指标分析、能耗计算、故障诊断、实时监视等提供对象化共享接口,为大数据分析提供保障。
目前煤矿数据采集融合共享系统接入2 000 多个生产设备,每日产生上亿条生产数据,在设备对象模型管理和数据计算、统计、转换等方面取得显著效果。
在硬件配置和运行环境相同的条件下,收集现场应用过程数据进行如下对比测试。
1) 重复进行数据计算,数据存储前和数据使用时计算性能对比见表1。可看出数据存储前计算比数据使用时计算的准确率稍有提高,且计算速率提高了4 倍。

表1 数据计算性能对比Table 1 Comparison of data calculation performance
2) 重复进行数据存储,松散数据和对象数据存储性能对比见表2。可看出对象数据存储速率比松散数据存储速率有显著提升,在Redis 数据库中提升了9 倍,在ClickHouse 中提升了49 倍。

表2 数据存储性能对比Table 2 Comparison of data storage performance
3) 重复进行全矿井数据查询,松散数据和对象数据查询性能对比见表3。可看出对象数据查询速率比松散数据查询速率有大幅度提升,在Redis 数据库中提高了3 倍,在ClickHouse 中提升了9 倍。

表3 数据查询性能对比Table 3 Comparison of data query performance
4 结论
1) 基于煤矿数据编码标准设计设备对象模型,包括基础模型、通信模型、位置模型、属性点模型、扩展模型,可兼容设备参数之间的差异,具有可扩展性强、灵活度高的优点。
2) 利用跨操作系统的工业规约和Restful API 问答式接口,实现了设备数据接入,满足煤矿操作系统国产化的发展趋势,解决了采用post 方式采集数据不能判断数据传输过程中异常情况的弊端。
3) 采集的数据经过设备对象模型映射、数据治理和数据存储后,实现了数据融合。通过无序的数据标准化,解决了数据语义不统一的问题;通过数据治理,保证了数据的可靠性、准确性;通过设备数据对象化的存储,提高了存储效率,节省了存储空间。
4) 对象化的数据共享接口可简化为实时数据和历史数据共享接口,通过1 次查询整个对象数据,从中提取所需的属性点,显著提高了数据访问性能。
