基于隐藏分类算法的电网隐私数据多层级加密研究
2023-12-13宋永占奚磊崔巍袁凌风
宋永占, 奚磊, 崔巍, 袁凌风
(南瑞电力设计有限公司, 江苏, 南京 211106)
0 引言
双向通信网络作为一种基础技术,是智能电网发展的基础[1]。在智能电网中,存在不同形式的发电,通过实时分析和处理用户的用电信息,可以满足用户各种用电需求。同时也伴随着用户隐私数据泄露的风险。如果无法有效保护电网电力数据,非法分子可以窃取数据以获取利益,电网在运行过程中也可能遭受恶意攻击,威胁到隐私数据[2]。因此,在此背景下,亟须一种有效的隐私数据加密方法。
赵丙镇等[3]利用区块链技术建立了隐私数据保护模型,引入概率公钥加密算法用于隐藏用户真实身份,结合零知识证明技术和承诺方案保护交易金额,并设计了身份加密机制来保护隐私数据。然而,该方法加解密数据所需的时间较长,存在加解密效率低和空间占用高的问题。王姝妤等[4]采用IDMAKE2协议在双线性对的基础上验证用户的身份信息,并通过同态加密算法对电网中的用户隐私数据展开加密处理。但该方法能耗高且无法抵御网络中的攻击,安全性较差。
为了解决上述方法中存在的问题,本文提出基于隐藏分类算法的电网隐私数据层级加密方法。
1 电网传输路径信息隐藏
电网系统执行相关程序时容易泄露路径信息,为了提高数据在路径中传输的安全性,采用分支混淆算法对电网路径信息展开隐藏处理,主要思路:利用二态非透明谓词改变路径形式,获得相应的控制流;对控制流展开平展化处理,混淆其原本的逻辑顺序;采用分支混淆算法隐藏经混淆处理后控制流中存在的路径信息。具体过程如下。
针对电网路径中控制流的单一形式,将二态非透明谓词穿插在路径和节点中,以此改变路径形式,提高路径复杂度。
在电网程序中,二态非透明谓词A的本质是布尔表达式,根据输出结果可将二态非透明谓词A分为以下几类:
(1) 当A在电网程序中的输出始终为真时,记为AT;
(2) 当A在电网程序中的输出始终为假时,记为AF;
(3) 当A在电网程序中的输出存在真、假2种情况时,记为A?。
根据后继基本块的唯一特性在电网原始的控制流图中确定插入非透明谓词的位置,通过随机插入混淆策略在确定位置处插入上述类型的非透明谓词,非透明谓词在控制流中具有混淆作用,改变了路径形式。
采用平展化处理上述插入非透明谓词后的控制流,消除其中存在的嵌套结构和分支结构以及基本块之间的差异,使基本块在电网路径中均处于并列位置。通过平展化处理可以混淆控制流之间原本的逻辑关系[5]。控制流平展化流程如图1所示。
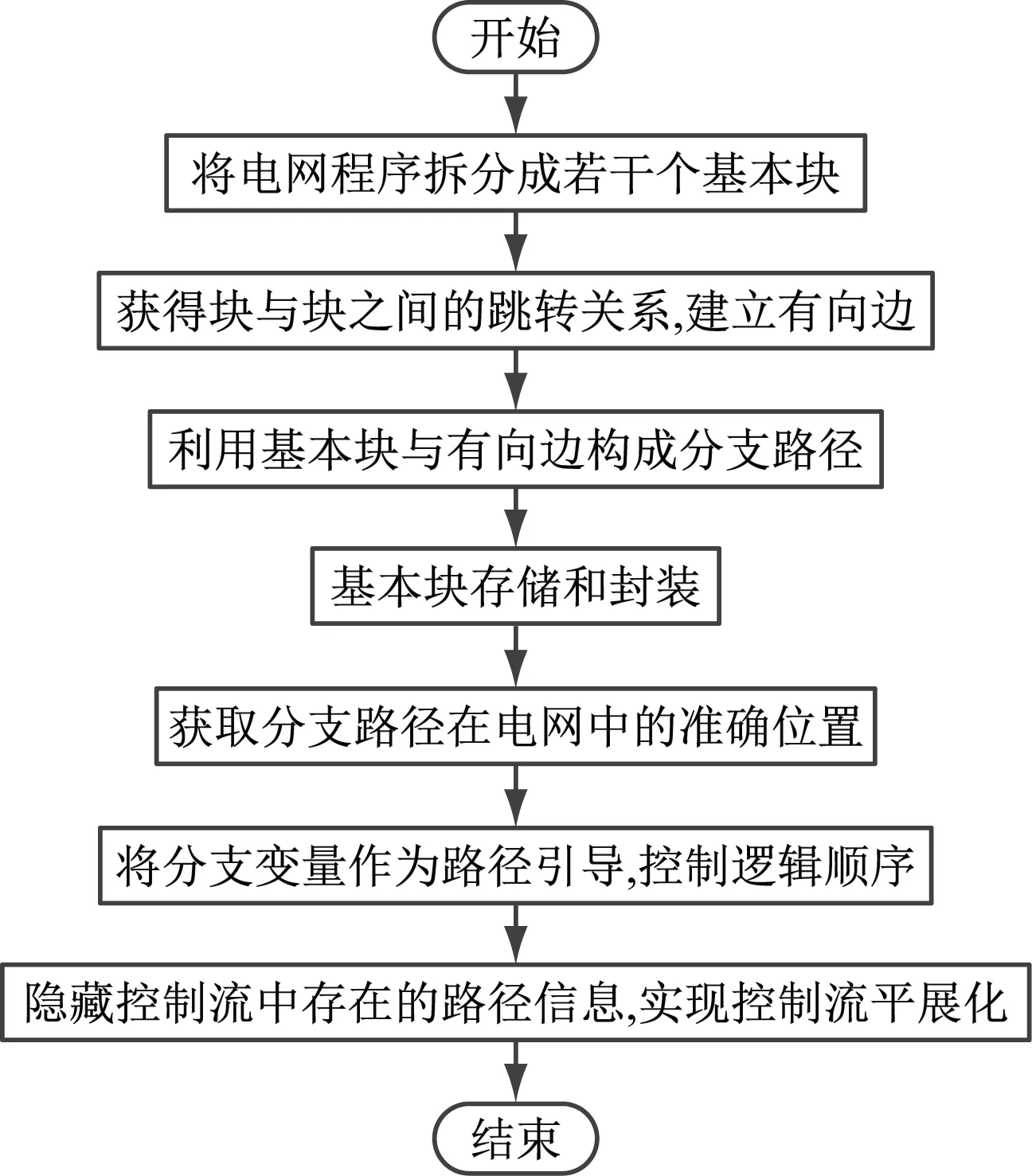
图1 控制流平展化流程
(1) 拆分电网程序,获得若干个基本块。
(2) 根据基本块的转移指令获得块与块之间存在的跳转关系,以此为依据建立有向边。
(3) 利用基本块和步骤(2)中建立的有向边构成分支路径。
(4) 将层级不同的基本块存储在相同层级中。
(5) 封装基本块,获取分支路径在电网中的准确位置。
(6) 针对电网运行过程中处于执行状态的分支路径,设置分支变量St用于该路径的引导,以此控制其逻辑顺序。
通过上述过程打乱控制流在电网中的逻辑关系,可以提高控制流的安全性,在此基础上采用分支混淆算法隐藏控制流中存在的路径信息,具体过程如图2所示。

图2 基于分支混淆算法的控制流路径信息隐藏流程
(1) 在不相关基本块中插入信息A,破坏电网程序原始的控制流信息,根据插入位置的上下文,在混淆过程中随机选择2个控制流信息AT、AF。
(2) 用O、M标记基本块的类型,其中,O为插入非透明谓词混淆过程中相关度为零的基本块,M为原始电网程序混淆前控制流图中存在的基本块。
(3) 利用后继基本块BN、前驱基本块BP和自身基本块BS组件基本块的三元组。
(4) 将控制流图输入switch-case分发器中,对其展开平展化操作。电网中存在的分支路径St可用基本块表示,电网程序对目前分支路径St的参数值展开分析,根据分析结果选择下一个运行的分支路径。
(5) 建立调度函数G(St)=(A,BN,b,St,c),函数参数c、b分别为基本块在当前时刻下对应的分支变量St和BN布尔值,下一个St分支路径值的计算可参考当前基本块的类型属性、St和b。
(6) 运行调用函数动态赋值算法实现信息隐藏。
运行调用函数动态赋值算法实现电网传输路径信息隐藏的具体流程如图3所示。
步骤1:设置分支变量f,根据St值和BN布尔值调用函数生成新的基本块BB。
步骤2:根据BB的类型属性Attr值判断是否执行该基本块,并将基本块BB的St值赋给f。
步骤3:当BB属于M类时,存在BB->Attr==M。此时将BB的分支变量值赋给f,存在f=BB->St。
步骤4:当BB属于O类时,存在BB->Attr==O。利用随机函数rand()生成随机数1或0。
① 在r=0条件下,将BB的分支变量直接赋给f,此时执行O。
② 当r=1时,采用调度函数动态幅值算法将BB的下一个分值变量值赋给f,此时不执行O。
步骤5:返回f,执行f在电网中的分支路径,并将该条路径隐藏,通过不断迭代,直至所有数据传输路径均被隐藏。
2 电网隐私数据多层级加密
2.1 电网隐私数据分层级
电网隐私数据可以分为以下2个层级。
(1) 电力数据。电力数据包括电力消耗数据、电力质量数据、供电质量数据等,这些数据主要反映了用电设备的使用情况和电力供应的质量。
(2) 用户数据。用户数据包括用户基本信息、用户行为数据、使用惯量数据、生活习惯数据等,这些数据主要反映了用户的个人隐私和使用习惯。
对于这2个层级的电网隐私数据,都需要得到妥善的保护和处理,避免泄漏、污染或者恶意利用对用户隐私和权益造成危害。电网系统需要采取专业的隐私保护措施,例如数据安全加密、数据权限管理、数据访问日志等技术手段,确保系统安全、数据隐私和用户利益的双重保障。
k-means可将数据集划分为k类,属于一种无监督的聚类算法[6-8]。该算法的原理是随机生成数据的k个聚类中心,划分数据时遵循最近邻原则,使其归类到最近的聚类中心内。
最小化各类误差平方和eSSE是k-means聚类算法的目标[9],建立电网隐私数据聚类目标函数:
(1)
式中,p代表第i个聚类Ci中存在的电网隐私数据,mi代表Ci的聚类中心,k代表聚类中心总量。
结合最小二乘法原理和拉格朗日定理[10-11]确定误差平方和:
(2)
通过上述过程将电网隐私数据划分为电力数据和用户数据,数据分类结果如下:
(3)
式中,ni代表聚类Ci中存在的电网隐私数据总量。
2.2 数据加密
将电网隐私数据中的电力数据Di划分为用电负荷数据和电力质量数据两个部分,用Dib、Dia表示。分别采用Fiestel加密算法和RC6加密算法[12]展开数据加密。
(1) 用电负荷数据Dia加密过程:Dia通常存储在4个w为RC6寄存器中,即A、B、C、D。预白化处理寄存器B、D,控制A、B、C、D展开内循环,Dia经过上述处理后,转变为密文。
(2) 电力质量数据Dib加密过程:设F代表Fiestel加密过程中的轮函数,L0,L1,…,Li代表子密钥,等量划分数据Dib获得DibL、DibR,通过式(4)对DibL、DibR展开加密处理[13]:
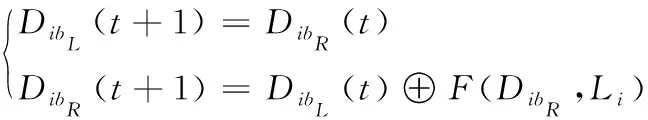
(4)
式中,t代表轮数,DibR(t)代表第t轮的DibR加密密文,DibR(t+1)代表第t+1轮的DibR加密密文,DibL(t)代表第t轮的DibL加密密文,DibL(t+1)代表第t+1轮的DibL加密密文,F(DibR,Li)代表Fiestel加密的轮函数。
通过上述过程获得密文DibL、DibR。
通过SM4算法完成用户数据的加密处理。SM4算法的结构如图4所示。
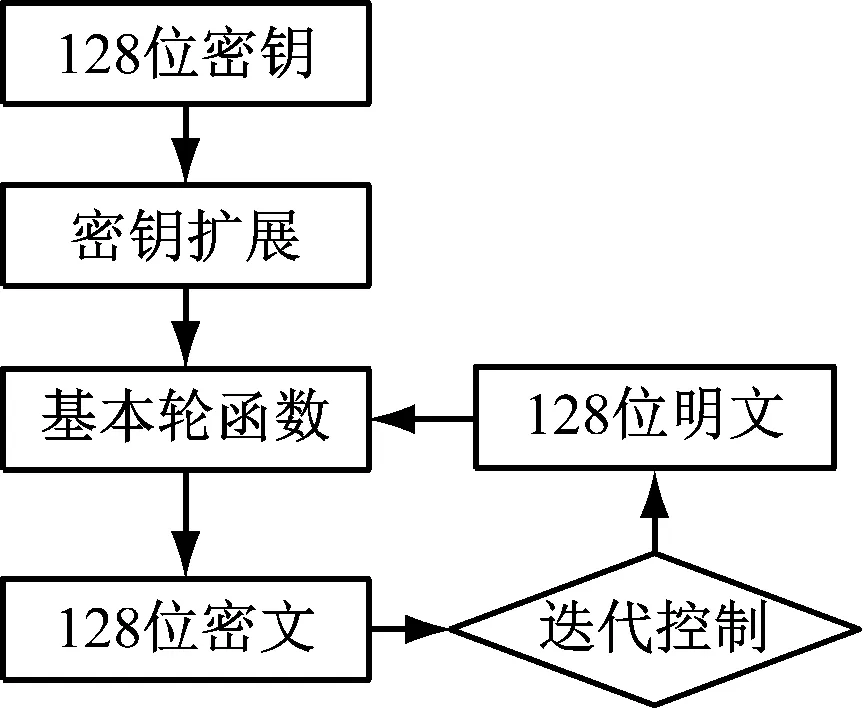
图4 SM4算法
用户在注册阶段需要在信任机构中注册相关凭据,完成身份验证[14]。验证通过后,可以在电网中访问数据。用户将指纹、视网膜等生物特征和ID/密码提供给信任机构,接收到凭证后,电网的信任机构会为用户分发伪ID。用户经过身份验证后,可以读取电网中存在的信息和数据,以确保电网隐私数据的安全性。多级身份验证流程如图5所示。
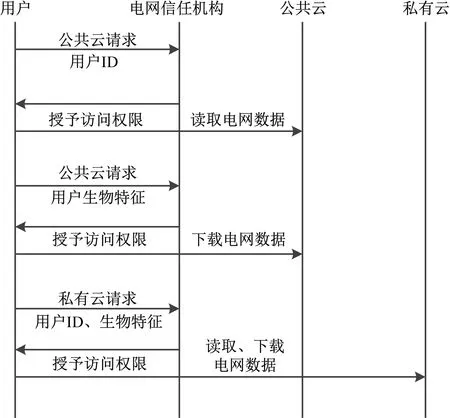
图5 多级身份验证流程图
3 实验与分析
为了验证基于分支混淆算法的电网隐私数据多层级加密方法的整体有效性,需要对其展开测试。利用数据爬虫技术采集电网中的电力数据、用户数据,将这2个数据进行合并处理,得到电网隐私数据集,以此对不同方法的有效性进行检验。实验环境如下:
操作系统为Linux Mint 19.3(64位);
加密算法库为OpenSSL 1.1.1 g;
编程语言为Python 3.7.6;
数据库为MySQL 8.0.19。
实验参数如下:
钥匙位数为2048位;
对称密钥算法为AES-256;
数据分片数为4个;
新生成的AES密钥的数量为2个;
新生成的RSA密钥的数量为4个;
RSA算法加密的AES密钥每个分片的大小为128位;
起始对称密钥的生成方式为随机生成。
在该实验环境下,可以使用Python调用OpenSSL库来实现RSA和AES加密算法,将加密后的数据存储在MySQL数据库中。通过改变实验中的参数值,例如钥匙位数、数据分片数、生成新的AES和RSA密钥的数量和加密方式等,来探究不同参数值对加密算法的性能和安全性的影响。从数据加解密时间、空间占用、能耗以及安全性方面测试基于分支混淆算法的电网隐私数据多层加密方法、文献[3]方法和文献[4]方法的有效性。
(1) 数据加解密时间
采用本文方法、文献[3]方法和文献[4]方法对电网隐私数据展开加解密测试,比较不同方法的加解密时间。不同方法数据加密实验数据如表1所示。
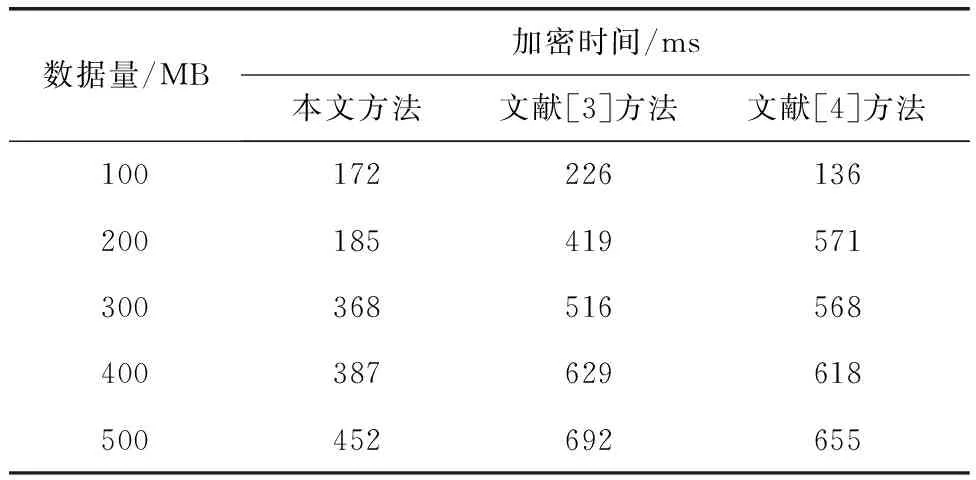
表1 数据加密实验数据
数据加密时间测试结果如图6所示。
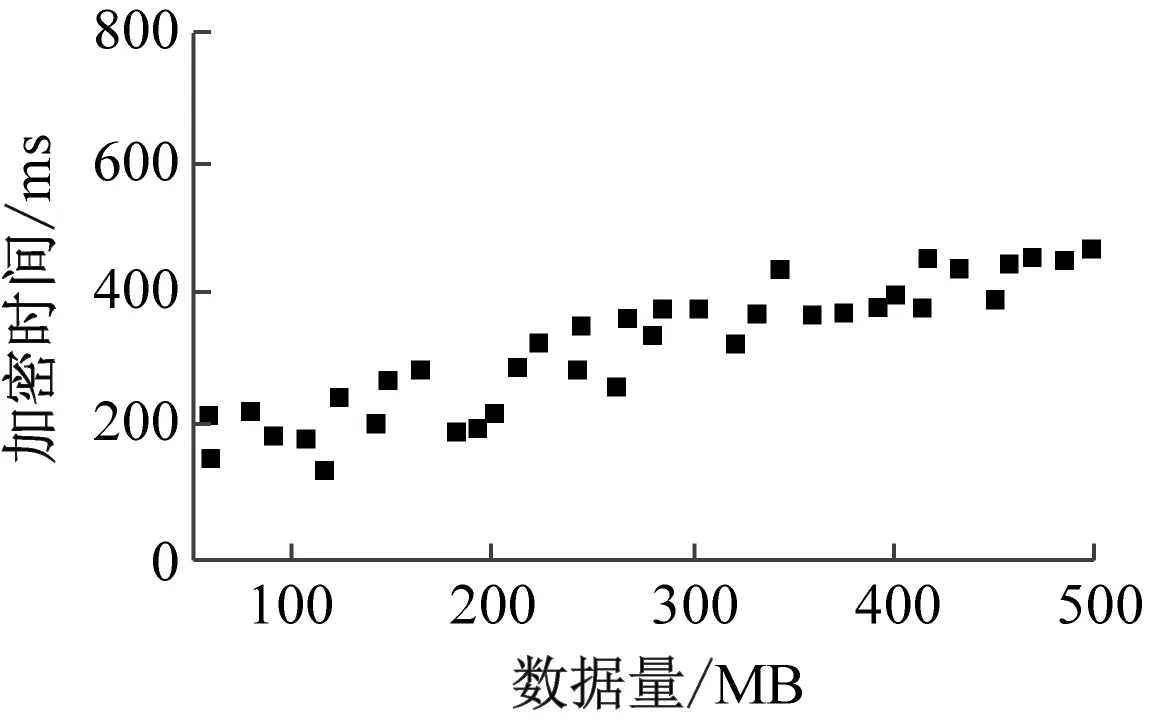
(a) 本文方法
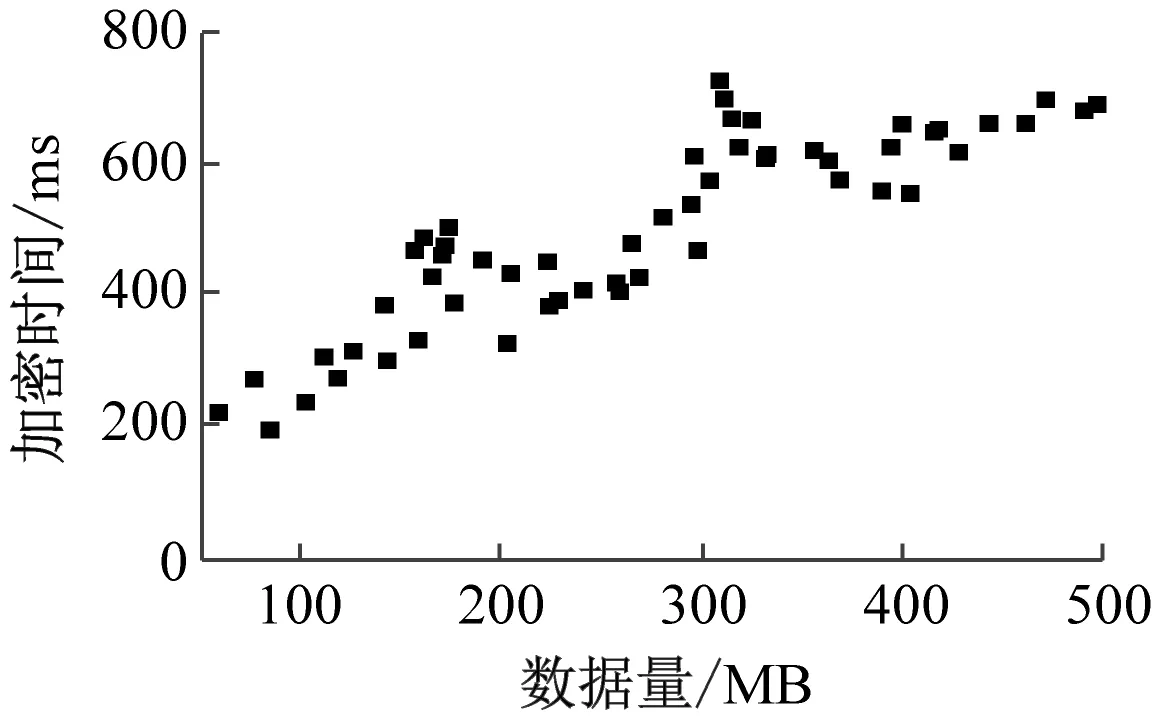
(b) 文献[3]方法
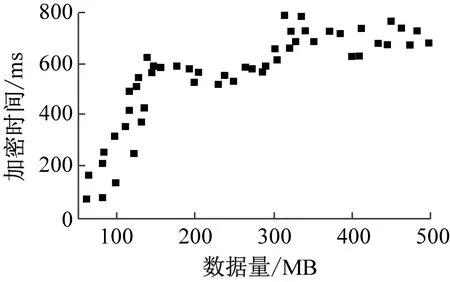
(c) 文献[4]方法图6 数据加密时间
分析表1与图6可知,随着实验数据量的增加,3种方法的数据加密时间均呈现波动上升趋势。当数据量为300 MB,本文方法的数据加密时间为368 ms,文献[3]方法的数据加密时间为516 ms,文献[4]方法的数据加密时间为568 ms;当数据量为500 MB,本文方法的数据加密时间为452 ms,文献[3]方法的数据加密时间为692 ms,文献[4]方法的数据加密时间为655 ms。从整体上来看,本文方法的数据加密时间更短,效率更高。
不同方法数据解密实验数据如表2所示。数据解密时间测试结果如图7所示。
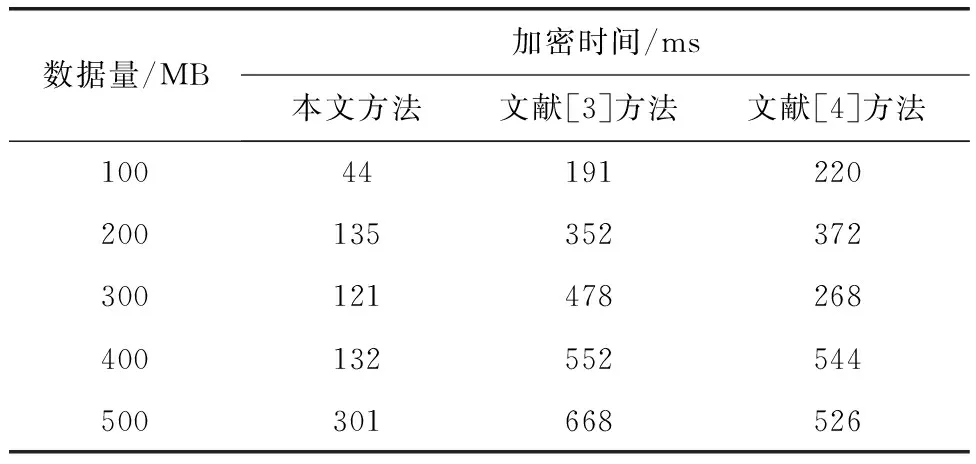
表2 数据解密实验数据
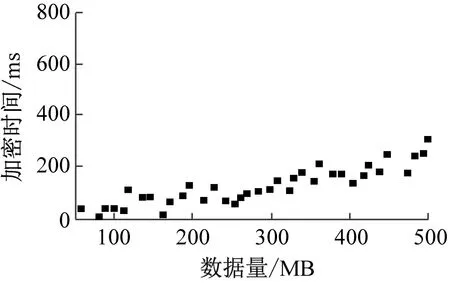
(a) 本文方法
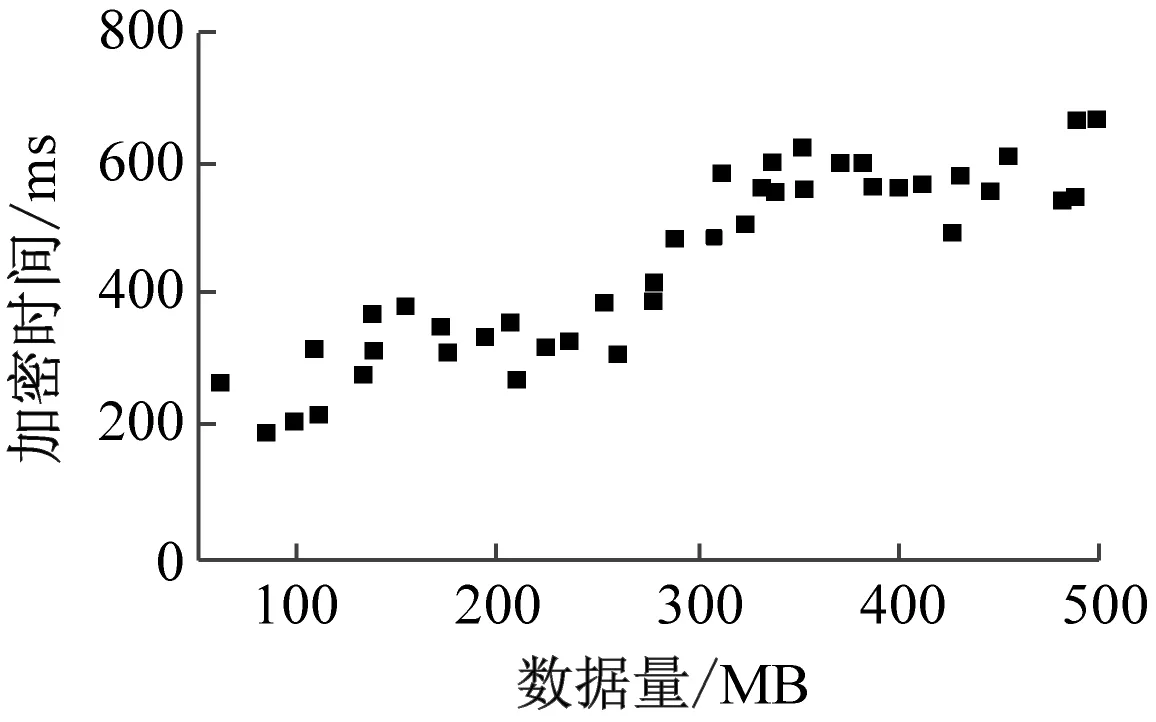
(b) 文献[3]方法
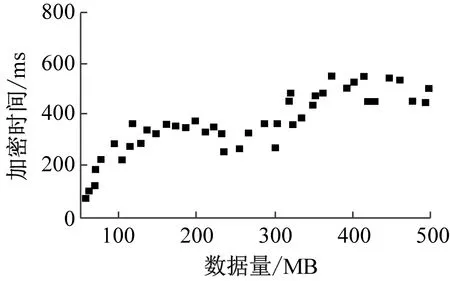
(c) 文献[4]方法图7 数据解密时间
分析表2与图7可知,随着实验数据量的增加,3种方法的数据解密时间均呈现波动上升趋势,但本文方法的解密时间曲线波动更为稳定,时间更短。与文献[3]方法、文献[4]方法相比,本文方法的数据解密时间最大值为301 ms,文献[3]方法的数据解密时间最大值为668 ms,文献[4]方法的数据解密时间最大值为526 ms。本文方法的解密时间更短,效率更高。
(2) 空间占用
上述方法在加密数据的过程中会占用一定的字节数。不同方法的空间占用实验数据如表3所示。

表3 空间占用实验数据
不同方法的空间占用情况如图8所示。
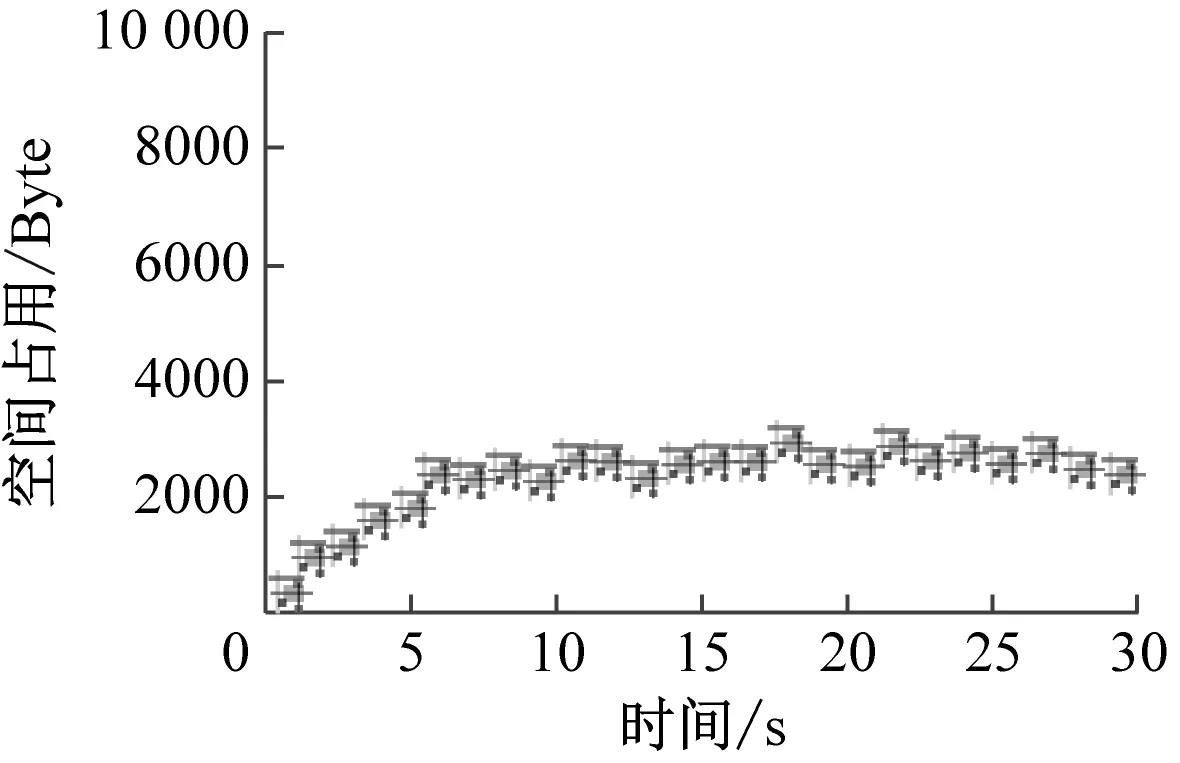
(a) 本文方法

(b) 文献[3]方法
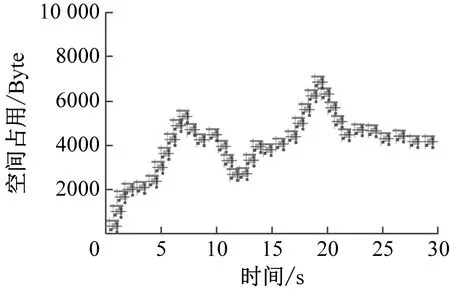
(c) 文献[4]方法图8 不同方法的空间占用情况
由表3和图8可知,本文方法对数据展开加密时的空间占用一直控制在3000 Byte以内,不会影响电网系统的正常运行。文献[3]方法和文献[4]方法的空间占用分别高达5800 Byte和7200 Byte,对数据加密的空间占用较高,会影响电网系统的数据传输性能。
(3) 能耗
不同方法的能耗测试结果如图9所示。
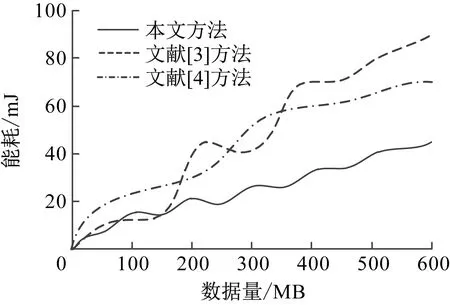
图9 不同方法的能耗测试结果
由图9可知,数据量与能耗之间成正比,在相同数据量下本文方法的能耗始终在46 mJ以下,是3种方法中最低的,表明本文方法适用于大规模的隐私数据加密。
(4) 安全性
在电网数据传输过程中,引入不同类型的攻击并测试其安全性,以评估方法的抵御能力。
表4中,√表示成功抵御攻击,×表示无法抵御攻击。根据表4可知,针对引入的攻击,本文方法均可成功抵御。这是因为本文方法设计了多层级加密,利用分支混淆算法对电网数据传输路径展开了隐藏处理,在此基础上加密数据,并设置了身份验证机制,因此本文方法可成功抵御多种类型的攻击,具有较高的安全性。
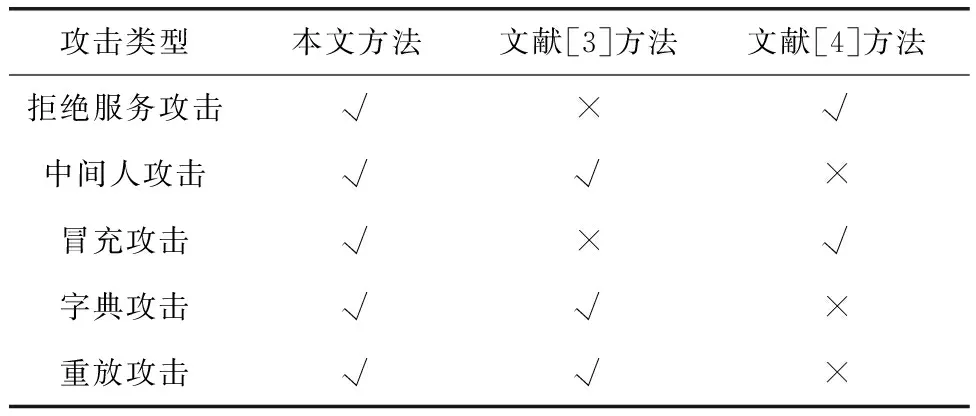
表4 不同方法的安全性
4 总结
针对目前电网隐私数据存在加解密效率低、空间占用高、能耗高、安全性差等问题,本文提出基于分支混淆算法的电网隐私数据多层级加密方法。该方法不仅对数据展开了加密处理,同时隐藏了电网的数据传输路径信息,并增设了身份验证机制,以此保护电网隐私数据的安全。经验证,当数据量为500 MB,本文方法的数据加密时间为452 ms,数据解密时间最大值为301 ms,对数据展开加密时的空间占用一直控制在3000 Byte以内,能耗始终在46 mJ以下,能够抵御拒绝服务攻击、中间人攻击、冒充攻击、字典攻击、重放攻击。综合来看,该方法加解密数据所需的时间较短,且占用空间少、能耗低,而且多层级的加密可抵御多种类型的网络攻击,提高了电网隐私数据的安全性。
