基于级联森林的控制流错误检测优化算法
2022-05-10董志腾顾晶晶
董志腾,顾晶晶
(南京航空航天大学 计算机科学与技术学院, 南京 211106)
1 引 言
随着科技的进步,计算机芯片中的晶体管尺寸越来越小,这使得芯片更容易受到外界环境的影响.尤其是在航空航天和医疗领域等高辐射场景下,计算机很有可能会发生瞬时故障[1],这些瞬时故障往往会造成灾难性的后果.预计在未来瞬时故障发生的概率将会呈指数增长[2].1990年发射的“风云一号”气象卫星,由于发生瞬时故障提前退役;1998年有报道显示在心脏除颤器中发生了瞬时故障;2011年,我国一颗探测卫星“萤火一号”发生瞬时故障,导致探测任务失败.
瞬时故障引起的错误如果打乱了程序正常的执行顺序导致程序出错,我们将这种错误称为控制流错误.研究表明,瞬时故障引起的错误中有约33%~77%的错误是控制流错误[3,4].控制流错误主要是由于瞬时故障发生在程序计数器(PC),地址存储单元或者条件判断语句中的变量存储单元.控制流错误会造成计算机程序不按照正确的指令顺序执行,可能会干扰程序的运行结果、造成程序陷入死循环甚至崩溃[5].
针对瞬时故障,现有的故障检测方法可以分为硬件方法和软件方法.硬件方法主要依靠硬件模块的冗余或者设置错误检测电路来实现,需要针对不同的硬件体系专门定制,成本极高且不灵活[6-9].相比于硬件方法,软件方法不需要依赖于硬件体系,成本低、灵活度高且容易配置.
本文提出了一种针对基于标签分析的错误检测方法的通用优化算法.为了寻找出合适的标签插桩位置和数量,本文设计了一种基于级联森林的基本块脆弱性预测模型,该模型经过大量的故障注入实验样本训练,可以识别出脆弱性高的基本块.我们针对性的将这些高脆弱性的基本块进行重新拆分,使其能够更好的配合基于标签的检测算法.我们对MiBench测试集[16]中6个测试程序进行故障注入实验,结果表明,在对程序基本块进行选择并拆分后,CFCSS算法[10]和RCFC算法[11]的检测率均有提升,且相对于随机插桩标签的开销较低,实现了高效费比的基本块拆分.本文的主要贡献如下:
1)本文通过收集分析大量程序数据,使用多粒度级联森林模型[12],对程序中易发生控制流错误的基本块进行识别,取得了不错的识别率.
2)本文使用LLVM编译器[13-15],对程序中的基本块进行重新拆分,并编写LLVM Pass文件实现CFCSS单标签检测算法和RCFC双标签检测算法,在拆分好的程序上自动添加标签.
3)本文在选用MiBench测试集[16]中的6个测试程序进行验证,证明我们的方法使用较低的额外开销可以提升较高的检测率.
2 背景和相关工作
对于控制流错误的检测,相比于基于硬件的检测方法[17],目前的软件检测方法通常是基于标签的检测方法[18],主要流程是将程序划分成基本块,为每个基本块分配若干个标签,并在程序运行期间维护一个随当前基本块变化而变化的全局变量来进行错误检测.
目前实用性最强的基于标签的检测方法是CFCSS[10](Control Flow Checking by Software Signatures),CFCSS将程序划分成若干个指令序列,并正式提出基本块的概念.CFCSS在编译阶段为每个基本块分配静态标签,通过比较静态标签和运行时的全局变量来判断程序是否发生了控制流错误.
RCFC也是一种基于标签的控制流错误检测算法,它提出了一种双标签的检测方法,利用应用程序中的循环嵌套结构将程序基本块分割成有条件的和无条件的基本块,有选择性的对其进行标签跟踪[11].该方法虽然泛化性不高,但是提出的双标签算法为后续的研究工作提供了一些思路.双标签检测方法一般会维护两个全局变量跟踪程序运行时的前驱和后继节点,并通过设计比较规则来判断程序是否发生了控制流错误.
目前主流的控制流错误检测方法,大多与CFCSS或RCFC很相似,只是在标签设置的数量、标签插桩的位置以及标签更新方式上的不同.近些年软件实现的控制流错误检测技术已有了长足的发展.一度陷入了为了提高检测率而不断增加开销的陷阱中.往往牺牲了大量的空间性能,只能提高少量的错误检测率.如何提升标签检测技术的检测率,同时又能控制额外的性能开销,成为基于软件的控制流错误检测及加固领域的研究关键.调整标签插桩的位置和数量可以一定程度上提高错误检测率,但是无限提高标签的数量很明显不是一种好的方法,如何寻找合适的位置添加合适数量的标签是一个亟待解决的问题.
本文着眼于使用软件方法检测控制流错误的问题.针对传统的基于标签的检测算法在标签插桩粒度和错误检测率之间难以平衡的难点以及块内错误难以检测的难点,设计了一套的针对基于标签检测方法的通用优化算法.
3 控制流错误检测优化方案
本文设计了一种对传统控制流错误检测技术的优化方案.如图1所示.主要包括3个部分:1)数据采集模块.为了保证程序的普适性,首先从GitHub上收集大量的使用C语言程序编写的常规算法和数据结构;使用LLVM工具对程序进行预处理和静态特征提取[19];对GDB程序调试工具进行二次开发,通过修改程序运行时的PC寄存器的值完成控制流故障注入,记录程序故障结果同时提取程序运行时的动态特征.计算每个基本块的脆弱性值[20],并构建训练集.2)模型训练模块.使用多粒度级联森林对程序基本块的脆弱性进行预测.3)基于标签的检测算法的优化.针对预测出的脆弱性高的基本块进行重新拆分,验证程序在拆分前后在相同的标签检测算法下控制流错误检测率和时空开销的效费比提高.
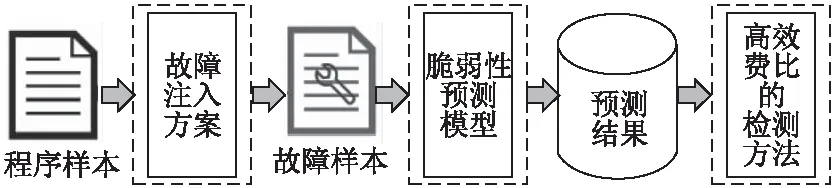
图1 控制流错误检测方案流程图
3.1 相关定义
定义1.指令(Instruction,I)是计算机处理的命令.每个程序都需要编译程指令的形式由计算机执行.
定义2.基本块(Basicblock,bb)是一个最大的连续指令集合,记为bb={Iin,…,Ii,…,iout}.在每个基本块中,指令由第一条顺序执行至最后一条,即每个基本块只有唯一的入口指令Iin和唯一的出口指令Iout.基本块中除了最后一条指令外,不可能包含额外的分支、跳转.同时,每个基本块也不可能分支、跳转或者调用其他基本块中除第一条指令以外的指令.
定义3.控制流(Control flow,CF)是基本块的跳转顺序,这种跳转顺序在程序编译完成就确定了,一般不会改变.定义为E={eij|0≤i,j≤n},其中n表示一个程序中的基本块总数量,eij表示bbi跳转到bbj的分支.
定义4.非法控制流(Illegal Control flow)描述一系列非正常的程序跳转.正常的程序跳转只有两种情况:1)基本块内部的前一条指令顺序执行至下一条指令;2)基本块最后一条指令跳转至合法的后继基本块的第一条指令.除了这两种情况外的其他所有跳转均为非法控制流.程序运行中一旦有非法控制流的存在,即该程序发生了控制流错误.
定义5.基本块脆弱性描述该基本块在程序运行时发生控制流错误的难易程度.脆弱性越高代表该基本块越容易发生控制流错误.
3.2 数据采集模块
3.2.1 原始数据集
程序的控制流在程序编写完成时就已经确定,每个程序只会根据程序的不同输入改变控制流的不同路径,每条路径上的指令执行序列是不会发生改变的.所以程序的控制流信息与程序员的代码风格有关,对于相同功能的程序,不同程序员可能会编写出截然不同的代码.为了得到程序控制流错误发生的一般规律,需要收集大量的程序控制流错误信息.训练数据集中的程序代码来自于GitHub,包括排序算法、数据结构、字符串操作、基础数学运算、最短路径算法等每种程序选择1至3个符合条件的共61个程序,如表1所示.为了方便进一步操作,这61个程序符合以下要求:1)程序输入为空或文件;2)程序输出为文本;3)程序运行时间小于10秒.

表1 原始数据集程序名称
3.2.2 基本块编号插桩
本文讨论的控制流错误主要依赖于程序的基本块信息.每个基本块是一个连续的指令集合,记为bb={Iin,…,Ii,…,Iout},如定义2所描述.为了准确获取程序运行时基本块bb与指令集合的对应关系,需要对基本块进行标号,记作bbi.构建bbi到指令集合的一对多的映射关系.
在程序运行时分析程序当前运行的指令所在基本块的编号是很困难的,而这恰恰是分析程序控制流错误发生位置的关键点.本文提出基本块编号插桩的方法,对程序的每个基本块分配唯一的编号,并使用一个全局变量记录当前程序正在运行的位置.具体的步骤为:
步骤1.使用LLVM工具将程序转换成LLVM IR中间代码;
步骤2.使用LLVM Pass对程序进行分析,遍历所有基本块,依次为其编号;
步骤3.使用LLVM Pass在程序开头声明全局变量记作GSIG(Global Signature),并在每个基本块开头的第一个不为空指令(LLVM规则中phi指令为空指令)之前插桩GSIG赋值语句,将当前的基本块号赋值给GSIG;
步骤4.使用LLVM将中间代码编译成可执行程序.
经过基本块号标签插桩的程序在运行的任何时间点的变量GSIG记录的值都是程序基本块的标号.
3.2.3 故障注入
为了分析程序中每个基本块的脆弱性,需要收集每个基本块发生控制流错误后的数据.收集这类数据一般有两类方案:1)大量的故障注入实验,使得控制流错误覆盖到每个基本块;2)针对每个基本块做相同数量的故障注入实验.程序在运行过程中,每个基本块的执行次数、执行时间有很大的差异,所以,方案1会造成样本的数量很不均衡,在极端情况下会造成部分基本块因为故障注入次数过少使得样本无效.很显然方案2是一种比较合适的方法.
控制流错误故障注入一般分为静态注入和动态注入两种方式.静态注入包含随机删除跳转指令、随机修改(翻转)跳转指令的目的地址、随机添加跳转指令3种,这些都可以在程序执行前完成故障注入,故称为静态故障注入;动态注入主要是在程序运行中,随机修改当前的PC寄存器的值,使得程序在运行期间发生跳转,故称为动态注入.动态故障注入可以模拟出静态故障注入的全部效果,且更具有灵活性,所以本文采用动态故障注入方式.
使用GDB工具模拟动态故障注入,GDB是一Linux环境下最常用的程序调试工具之一,可以在程序运行时获取寄存器中的值,打断点,设置检查点等分析程序运行时的各类信息.并创新地完成了针对基本块的控制流错误故障注入方案.控制流错误故障注入的基本原理是在程序运行时随机暂停程序运行,改变当前程序的PC寄存器的值,使程序执行的下一条指令不再属于正常的指令序列.针对基本块的故障注入则是在随机翻转任意一条指令的PC寄存器的值的基础上做到针对指定基本块内的指令的PC寄存器的值的随机翻转.这就要求随机暂停程序运行的位置在指定的基本块内,首先在程序编译前,在每个基本块头插入全局变量GSIG,记录当前基本块的编号.之后利用GDB的检查点机制,获取基本块号以及其所包含的指令集合中每条指令对应的PC寄存器值的一对多映射关系.具体流程如下:
步骤1.启动GDB工具;
步骤2.针对全局变量GSIG设置检测点;
步骤4.逐条执行指令,保存PC寄存器的值,添加到“基本块号-指令PC寄存器值”映射表中;
步骤5.当GSIG的值发生变化时,重复执行步骤2、步骤3;
步骤6.程序运行结束.
在故障注入时,针对每个不同的基本块,我们只需要随机选取对应映射关系中的PC值,并在该处打断点,当程序运行到该位置时,随机翻转PC寄存器的值,即可完成针对基本块的控制流错误故障注入.在已知程序所有指令所对应的PC寄存器值的情况下,还可以做到指定跳转目的地址,做到控制基本块内、块间以及过程间的控制流跳转.
程序在运行时按照一定的故障发生率[21]进行故障注入,需要收集一些动态特征,首先基本块脆弱性定义为该基本块中发生控制流错误后,程序发生错误的概率与该基本块的占程序总运行时间占比的乘积,具体定义如下:
基本块集合:B={bb1,…,bbi,…,bbN},基本块动态特征集合为:Bdynamic={round1,…,roundi,…,roundN},其中roundi为基本块bbi的执行次数,比如循环体基本块在程序执行过程中会多次执行,假设计算机执行每条指令的时间大致相同,那么每个基本块占程序执行总时间的比重为:
(1)
针对程序的每个基本块故障注入M次,程序发生错误的次数统计为:C={C1,…,Ci,…,CN},基本块的脆弱性定义为:
(2)
3.2.4 静态特征
提升企业形象。四川雅安地震发生后,所属自贡公司继2008年参与汶川抗震救灾后,再次代表中国水务公司,在第一时间组织供水抢修救援队伍奔赴抗震救灾第一线。抢修队的工作得到灾区政府和群众一致好评,中央各大媒体对其表现出高度的关注,新闻联播和新闻30分等栏目给予全方位报道。抢修队树立了中国水务员工英勇、专业、能打硬仗的良好形象,践行了中国水务勇于承担社会责任的庄严承诺。
静态特征是指程序代码在编写完成后就具备的特征.这些特征与程序执行过程中的输入无关,仅仅与代码相关.
LLVM工具可以将程序转换成LLVM IR中间代码形式.对中间代码进行分析,LLVM可以快捷地将程序分解成基本块,我们可以得到程序的每个基本块的信息,对于每个基本块,我们提取它的块号、指令数、不同类别指令数、出度、入度、平均每条指令操作数个数等作为基本块的静态特征.
3.3 模型训练模块
数据采集阶段收集的基本块特征集合,经数据预处理之后,筛除一些无效样本.使用跨样本的滑动窗口技术对数据集进行处理,获得了基本块执行序列的相关特性集合Fexpand,与特征集合Fi合并为初始的输入特征Forigin=
3.4 基于标签检测算法的优化策略
使用Clang编译器[22]将待检测程序编译成LLVM IR中间代码,目标程序待预测的基本块集合为Bpredict={bb1,…,bbi,…,bbN}.其中bbi表示程序中的第i个基本块,N为程序中的基本块数量.通过LLVM Pass对Bpredict集合中的所有基本块进行分析得到基本块的静态特征,并使用GDB工具获取基本块的动态特征,合并得到基本块特征Fi.基于已经训练好的基本块脆弱性预测模型对目标程序的基本块脆弱性进行预测,并输出基本块标号和脆弱性关系到统计文件中.
将预测结果中脆弱性大于阈值的基本块进行拆分,得到的新程序使用基于标签的控制流错误检测算法进行验证.对比算法在程序拆分前后的检测率以及时空开销的变化情况.对比预测模型在多种待测程序和多种标签检测算法上的运行结果,验证本文的基于标签的检测算法优化策略可行.
4 基于多粒度级联森林的基本块脆弱性预测算法描述
4.1 数据分析
通过对进行针对性的故障注入实验后得到基本块脆弱性预测算法的数据集.该数据集包括61个程序中的2505个基本块特征以及每个基本块100次故障注入实验得到的实验结果数据.程序基本块特征包括指令数量、指令类别、出度、入度、平均每条指令操作数个数、基本块运行次数等共16个特征.提取的特征如表2所示,并遵循如下依据:

表2 基本块特征描述表
基本块的指令数量是描述程序基本块大小的特征.计算机执行每条指令的时间大致相同,所以指令数量越多的基本块执行的时间越长,那么在程序运行期间更有可能受到控制流错误的影响.因此本章将指令数量作为特征提取并表示为Vins_num.
不同类别指令数量是描述程序基本块中不同指令数量的特征[23].不同类型的指令代表了程序的不同功能,比如读取存储指令、运算指令数量越多,程序更有可能只是进行单一顺序的执行,这时若发生控制流错误很有可能会造成程序运行结果错误;若跳转指令、函数调用指令数量越多,程序更有可能在发生跳转或者在执行循环操作,这时若发生控制流错误,很有可能会造成程序进入死循环或者挂起.基本块中包含的不同类别的指令数量基本可以表示当前基本块的作用,因此本章将不同类别指令数量作为特征提取并表示为:Vins_type.
程序基本块的出度入度是描述程序基本块执行顺序的特征.程序从入度为零的基本块按照顺序执行直到最后一个出度为零的基本块.基本块的入度出度也描述了该基本块的执行重要程度.比如经常被调用的函数包含的基本块的入度会比较大,包含if、switch等条件跳转语句所在的基本块出度会比较大.这类基本块在发生控制流错误时很有可能会造成程序跳转关系的混乱,造成不可预知的错误.因此,本章将程序基本块的出度入度作为特征提取并表示为:Vin_and_out.
程序中每条指令都有不同数量的操作数,由于操作数的读写需要消耗计算机资源,所以操作数的多少一定程度上影响了指令的执行时间.基本块包含若干指令,所以将每条指令的平均操作数数量作为基本块的特征进行提取并表示为:Vins_avg.
程序中不同基本块由于功能不同,在程序运行过程中,基本块的执行次数相差很大.一些与参数初始化有关的基本块在程序执行过程中只会执行一次,而有些与循环相关的基本块可能会执行成千上万次.基本块的执行次数与该基本块的执行时间直接相关.同时程序在不同测试用例下,相同的基本块执行次数也会有差异,使用单一测试用例进行测试得到的基本块执行次数并不完全准确.LLVM提供了一种启发式算法,可以对程序基本块的执行次数进行预测,预测出的基本块执行次数可以对单一测试用例下基本块执行次数的测量值进行补充,尽可能接近真实的基本块执行次数.因此,本章将程序基本块执行次数作为特征提取并表示为:Vround.
综上所述,基本块特征向量可以表示为:
Vorigin={Vins_num,Vins_type,Vin_and_out,Vins_avg,Vround}
在LLVM IR中间代码表示中,具体的指令类别如表3所示.

表3 指令类别表
基本块特征集合可以定义为:
F=Vorigin
={Vins_num,Vins_type,Vin_and_out,Vins_avg,Vround}
={ins_num,ins_type1,ins_type2,…,ins_type9,
in,out,op_avg,real_rounds,predict_rounds}
其中ins_num表示基本块中的包含的指令数量,ins_type1,ins_type2,…,ins_type9分别表示第1类到第9类的指令数量,in,out表示基本块的入度和出度,opavg表示平均每条指令的操作数数量,realrounds表示程序在单一测试用例下完整运行一次基本块执行的次数,predictrounds表示LLVM启发式算法计算的基本块执行次数.故障注入工具对程序集中所有的基本块逐个进行故障注入,根据程序运行结果统计每个基本块的脆弱性Pi,并结合基本块的静态特征与动态特征构建基本块脆弱性预测模型的特征集合E={(Fi,Pi)}.
4.2 算法描述
gcForest是一种决策树集成方法,在多分类任务中具有与深度神经网络相近的性能.本章介绍级联森林在程序基本块脆弱性预测的构造过程.主要分为两部分:多粒度扫描和级联森林结构.多粒度扫描可以挖掘样本间的特征相关性,构造更适用于级联森林模型的数据集;级联森林可以利用不同森林的特性,提高预测的准确性.
4.2.1 多粒度扫描
为了增强级联森林结构的训练效果,我们采用多粒度扫描对特征进行处理.多粒度扫描的基本思想来源于深度神经网络,类似于深度神经网络中的卷积核滑动过程.但一般情况下单一粒度的滑动窗口扫描只能获取固定序列中的有效特征,而多粒度扫描可以利用样本间的相关性特征.本文的多粒度扫描模型如图2所示.
如图2所示,本文中的样本特征有16个维度,每个程序大约包含数10个基本块,每个基本块特征为一条样本.为了获取基本块的序列特征,我们每次选取10条连续的基本块特征样本拼接成160维的新特征向量.分别设置窗口(Window)大小为32,64和80.以窗口大小32为例,为了获取每条样本之间的相关性特征,每次向前滑动16个单位,共滑动9次生成9个新样本,样本数量记作s.同理,窗口大小为64和80时,可以生成7个和6个新样本.每个子样本都用于完全随机森林和普通随机森林的训练,每个森林都会得到一个长度为5(分类个数)的概率向量,即每个森林都会生成一个5×s的表征向量,最后把每层的随机森林结果拼接得到样本输出.

图2 多粒度扫描模型
4.2.2 级联森林
本文中使用级联森林对程序基本块脆弱性进行预测.级联森林由多层随机森林结构集合而成,每一层由不同的随机森林组成,本文采用普通随机森林和完全随机森林,每一层的训练结果作为下一层的特征信息,从而增强下一层深林的训练结果,如图3所示.
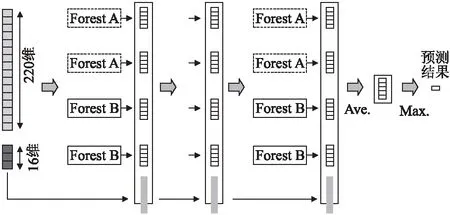
图3 级联森林模型

4.2.3 基本块拆分策略
为了提升控制流错误的检测粒度,本文对脆弱性高的基本块进行拆分,以检测更多发生于该基本块的块间和块内错误.具体策略为:
步骤1.选择待拆分基本块
使用多粒度级联森林模型对基本块脆弱性进行预测,将基本块集合B={bb1,…,bbi,…,bbN}按照脆弱性重新排序,选择脆弱性高的且基本块大小大于阈值(一般选择平均基本块大小作为阈值)的前k个基本块作为拆分对象.
步骤2.拆分基本块
在选取的k个基本块中选择合适的指令位置,使用LLVM Pass将选中的基本块从该指令后一分为二.为了防止基本块拆分过程使程序的代码规则被破坏,在基本块拆分时,不选择phi指令前进行拆分,在LLVM IR中间代码规则中,phi指令记录了当前基本块的前驱,故phi指令之前不允许有其他指令出现.
步骤3.插桩错误检测标签
程序经过基本块拆分后,选择不同的基于标签的检测算法(本文选择CFCSS和RCFC算法)进行检测标签插桩,并确保基本块拆分并插桩检测标签后可以正常运行.
5 控制流错误检测验证实验
本节设计了针对本文提出方法的验证实验.实验环境为:i7-8750H CPU、运行内存16G、Ubuntu Linux操作系统.本文随机选取了MiBench测试套件中的6个程序作为测试集,包括Qsort(快速排序)、Dijkstra(迪杰斯特拉最短路径算法)、FFT(快速傅里叶变换)、Isqrt(整数平方根计算)、Bit string(位类型数据转换为字符转类型数据)和Rad2deg(弧度转换为角度).实验过程主要包括4个内容:程序特征提取、基本块脆弱性预测、脆弱基本块拆分和标签检测算法检测率开销对比.
1)首先将所选程序使用LLVM编译程中间代码形式(LLVM IR),使用LLVM Pass提取基本块静态特征并在每个基本块首插桩块号标签,再使用GDB调试工具运行程序获取程序的动态特征.
2)结合静态动态特征,使用训练好的级联森林对基本块的脆弱性进行预测.
3)选取一定比例脆弱性高的基本块进行重新拆分.
4)针对拆分前后的测试程序,使用CFCSS和RCFC两种标签检测算法进行控制流错误检测.对比其开销和检测率.
本章对故障注入实验做了以下假设[25]:1)仅考虑因PC寄存器发生故障导致的控制流错误;2)程序每次执行过程中有且只有一次故障.
从两个方面评估本文提出的方法:1)基本块脆弱性预测的准确性;2)针对高脆弱性基本块拆分的策略对传统基于标签的控制流错误检测方法在检测率上的提升.
5.1 基本块脆弱性预测实验
预测基本块的脆弱性是本文提出的方法的关键部分.本实验使用模型及参数设置如3.2节所述.我们将数据采集模块收集的61个不同程序,共2505个基本块的运行故障数据,并添加基本块脆弱性标签,基本块脆弱性计算公式为:公式(2).根据基本块脆弱性将其分为5类:一定发生控制流错误、极易发生控制流错误、比较容易发生控制流错误、很少发生控制流错误、不发生控制流错误,排除第1类和第5类的数据,其他3类样本数量按照基本块脆弱性由高到低3等分.
采用多粒度扫描对初始数据集进行处理,提取基本块间特征相关度,并生成新的特征集合作为级联森林的输入数据.将训练好的模型在MiBench测试套件中的6个程序上进行验证.我们对每个测试程序的基本块进行100次的故障注入实验,根据故障注入结果计算每个基本块的脆弱性,并根据脆弱性大小进行分类,从高到低一共分为五类.同时对比了不同分类模型的分类效果,不同模型的分类准确性如图4所示.

图4 分类准确性对比
由实验结果可见,多粒度级联森林在多分类任务中的效果相比于传统多分类机器学习模型有较好的准确性.
对于预测出“极易发生控制流错误”的基本块,需要进行进一步的拆分,不仅可以防止发生在该基本块内部的控制流错误漏检,也可以提高程序整体的错误检测率.
5.2 高脆弱性基本块拆分对传统基于标签的控制流错误检测算法的影响
本节评估针对高脆弱性基本块的拆分策略对传统的基于标签的控制流错误检测方法的检测率与开销的影响.故障检测率方面,我们对选取的每个测试程序进行2500次的随机故障注入实验,对比其在不同检测算法下拆分前后的故障检测率;开销方面,我们对选取的每次测试程序,分别对比其拆分前后原程序、插桩不同检测算法标签后的运行时间开销和空间开销.最终对比其检测率,以验证本文提出的方法的可行性.
采用MiBench测试套件中6个测试程序:Qsort、Dijkstra、FFT、Isqrt、Bit string和Rad2deg.分析6个测试程序的时空开销如图5、图6所示.
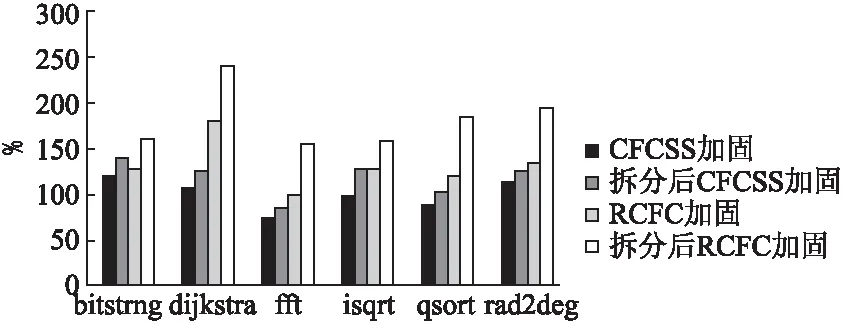
图5 检测方案额外空间开销对比
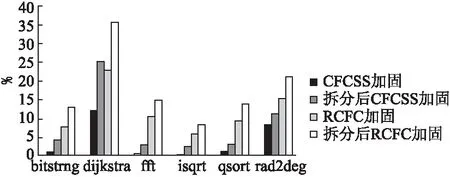
图6 检测方案额外时间开销对比
为了验证CFCSS和RCFC算法在基本块进行针对性的拆分后算法检测性能的提升情况,对6个测试程序进行了程序间跳转故障注入和随机跳转故障注入各2500次,实验结果如表4所示.其中程序内跳转代表程序发生错误跳转,跳转的目的地址依旧在程序内;随机跳转表示程序发生错误跳转,跳转目的地址为随机的计算机地址空间.CFCSS-S和RCFC-S分别代表经过基本块拆分后再加固的程序.
表4中程序的故障注入运行结果分为4类:“系统错误”表示程序发生系统故障被检测;“方法报错”表示程序发生故障被检测方法检测;“正确运行”表示程序发生故障但是输出结果正确;“错误漏检”表示程序发生故障没有被检测到.从实验结果可以看出,错误检测算法能检测出大多数程序内跳转错误,但是随机跳转错误主要是被系统直接检测出来.单标签检测算法CFCSS在各类程序不同错误类型下普遍低于双标签检测算法RCFC.两种方法不论是在程序内跳转还是随机跳转情况下,控制流错误检测率均有提升.

表4 检测算法故障注入结果统计表
经过对比发现,不论是CFCSS算法还是RCFC算法,在经过智能拆分后的程序上验证,控制流错误检测率都有较高的提升.其中,程序内跳转检测率提升尤为明显,是因为对程序进行基本块智能拆分后,提升了基本块内的控制流跳转错误检测率.随机跳转检测率提升较低,是因为随机跳转目的地址空间很大,有很大概率跳转到程序空间外,只有当程序地址发生低位翻转时,程序会发生内部跳转,进而被优化后的算法检测到.
6 总 结
本文提出了一种针对传统基于标签的控制流错误检测算法的通用优化方案.使用GDB开发了控制流错误故障注入工具,使用LLVM Pass实现基本块拆分的自动化工具,并在LLVM IR层级设计实现了程序基本块特征自动提取工具.利用多粒度级联森林实现了基本块脆弱性预测模型,并对高脆弱性基本块进行拆分.实验表明,拆分后的程序时空开销增加量很小.并且在单标签检测算法CFCSS和双标签检测算法RCFC上均可以实现高效费比的控制流错误检测.对传统的标签检测算法的优化有着重要的意义.
