抵御控制流分析的Python 程序混淆算法
2021-06-29刘建
刘建
(东莞理工学校,广东东莞 523000)
0 引言
控制流分析是一种特殊的分析技术,通常用于对程序的控制流结构进行静态结构分析。随着软件功能的增加,算法结构也变得越来越复杂,程序员们开始在程序语言中使用越来越多的分支语句[1]。为了能够提高程序执行的效率,通过控制流分析将这些程序编译为相对较为简单的语言,以便程序员们能够更好地利用和处理这些程序语言。但是这种能够将所有程序语言变得简单易懂的分析方法使得软件失去了程序语言对自身算法结构的保护能力,很多黑客利用控制流分析能够轻易地对软件程序的安全构成威胁,因此需要对程序的控制流分析进行防御机制的构建。
在以往的算法设计中,文献[2]通过蝙蝠优化算法对程序语言的流程结构进行了混淆计算,将其变为不易被控制流分析的语言结构。文献[3]通过计算混淆、聚合混淆的方式反推控制流分析的结构,降低了程序被控制流分析的概率,提高了算法结构的安全性[2-3]。本文结合以上文献设计了Python程序的混淆算法,用于低于控制流分析。
1 抵御控制流分析的Python程序混淆算法设计
1.1 加密Python程序混沌映射
混沌映射能够使Python程序具备更高的初值敏感性,并提高算法的运算速率,但是其结构较为简单,很容易成为控制流分析的解析缺口,因此在设计混淆算法时需要首先需要对其进行加密处理。通过混沌映射的定义式,能够得知混沌映射的随机性位置信息:

式(1)中,A1表示混沌系统随机过程中的初始位置参数,An表示混沌系统随机后的第n个节点的位置参数;δ表示初始混沌系数,其取值范围为[1,4],且均为常数。随着δ的系数值越来越接近最大值,其随机位置信息的计算越复杂,经过迭代计算后的实数序列就越来越收敛,直至完全变为一个实数项[4]。在实验过程中,可以将An取值为0.5,并将迭代次数固定在300,然后通过二项分布简化其计算过程,实现更优化的计算方法。通常而言,在迭代30次以后,混沌映射对于Python程序的加密能力就会越来越低,直至没有效果。
1.2 基于混沌映射设计混淆算法不透明谓词结构
不透明谓词是一种能够在到达应用程序某个节点之前就明确知道其结果的构造词。当所有不透明谓词均为T时,该不透明谓词就为永久的不透明谓词;反之,若有意向不透明谓词的结果为F时,该不透明谓词就为半永久性不透明谓词;若所有不透明谓词均为F时,该算法结构为陷门不透明谓词[5]。本文基于混沌映射构造不透明谓词的数据结构,并插入永远为真的不透明谓词,可以通过如下程序:
如图1所示,在插入不透明谓词时,需要假设所有程序语句全部为真,并使用if-else的语句作为条件表达式,假设程序确实为真,则进行到下一项,若程序其中一项为假,则跳过该项程序语句[6]。
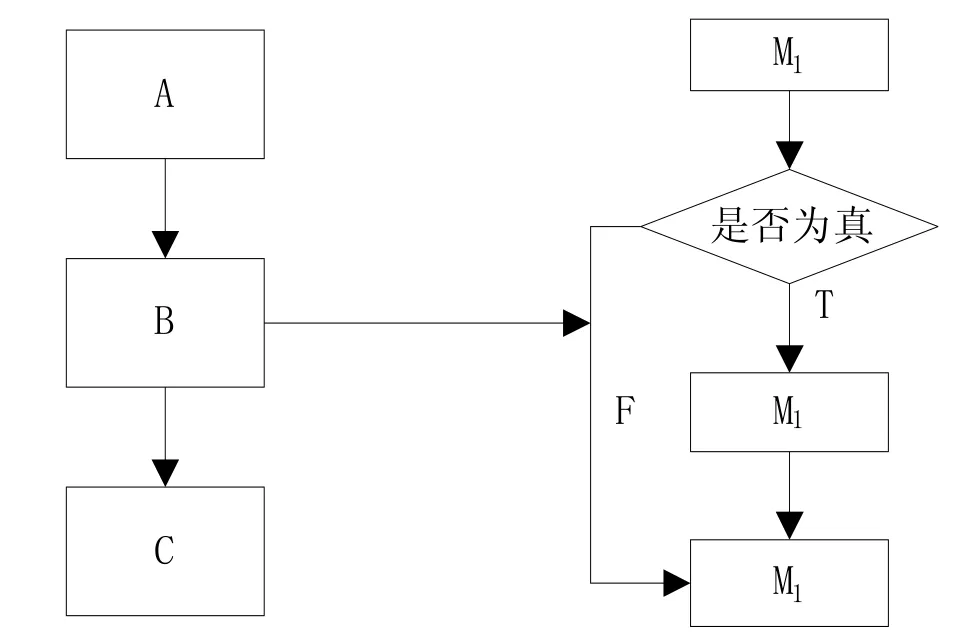
图1 不透明谓词插入程序Fig.1 Opaque predicate insertion program
1.3 抵御控制流分析算法实现
在使用混淆语句抵御控制流分析时,可以通过给定的混淆路径将所有文件夹中的Python全部遍历,若存在子文件夹,可以将子文件夹中的语句也搜索一遍。通过case条件语句封装所有变量赋值函数,解决变量赋值不受控制地暴露在外的问题[7]。通过上文中的布局混淆、控制混淆来插入不透明谓词,以此调整控制流分析的阅读和理解顺序,加深控制流分析解析算法的难度。将所有函数分为若干个大小不一的函数块,并结合上文中的不透明谓词插入算法,将每一个函数块中的不透明谓词全部插入到控制流阅读流程中,并将这些过程压缩在同一个文件夹中,放置在相应的位置。若最后阶段所有的Python都没有明显的bug程序错误,则可以表示针对该控制流分析的混淆算法设计成功,但是一旦目录是发生改变,则表示该混淆算法没有成功抵御控制流分析程序的解译。
2 实验设计
2.1 实验准备
本实验主要用于测试上文中设计的程序混淆算法是否能够抵御控制流的分析作用,并将其与传统的两种算法进行比较,通过抵御静态攻击安全性、抵御动态攻击安全性来判断其算法结构对于控制流分析的抵抗能力[8]。使用Python作为实验平台的编程语言,将Intel(R)CPU 2340@2.45Hz作为CPU处理器,其运行内存为4GB,储存空间大小为600G。首先编写一段流程较为复杂的算法语言,使用文中的混淆算法与现有的两种混淆算法分别对其进行改造优化,然后使用控制流分析分别在静态环境以及动态环境下攻击该算法程序。通过程序混淆前后的圈复杂度判断该算法的混淆力度。
2.2 实验结果分析
为了得到更具科学性的实验结果,将上述实验流程重复5 次,每一次都使用不同的算法程序,分别对其进行混淆与控制流分析。使用公式计算混淆前与混淆后的圈复杂度百分比:

式(2)中,α表示混淆前与混淆后的圈复杂度百分比;M表示混淆前的圈复杂度;N表示混淆后的圈复杂度。根据上述实验步骤与计算公式得到的实验结果如表1所示。
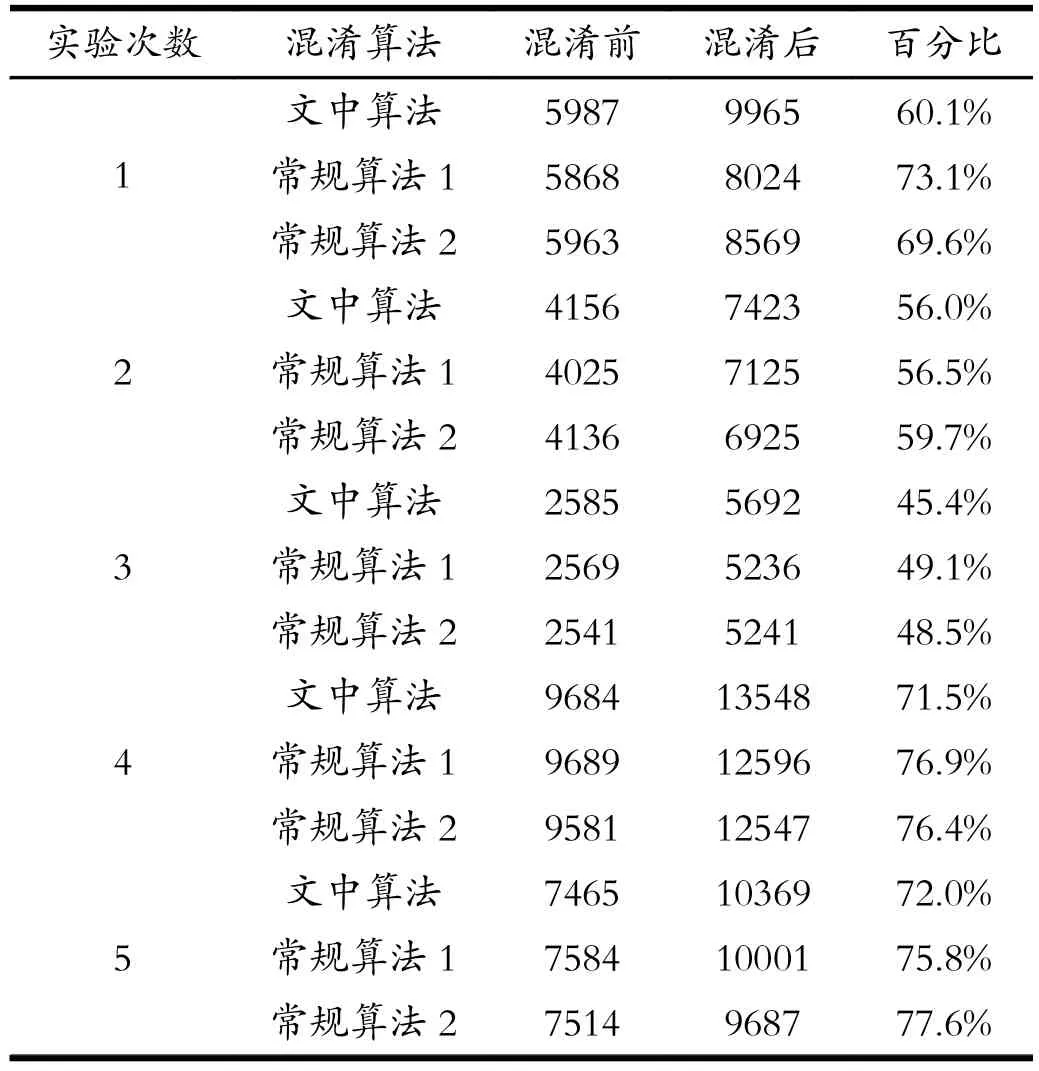
表1 程序混淆前后圈复杂度Tab.1 Cycle complexity before and after program confusion
如表1所示,在程序混淆前后的圈复杂度计算中,通过五次实验能够得到混淆前与混淆后的复杂度参数,混淆后的圈复杂度普遍高于混淆前的圈复杂度,且文中算法测得的百分比均低于常规的两种算法。由此可知,本文基于Python程序的混淆算法在抵御控制流分析的过程中拥有较常规算法更强的防御能力,能够更好地抵御控制流分析的解析。
3 结语
本文对混沌映射进行了优化处理,并构造插入了不透明谓词条件,极大地加强了Python程序中混淆算法对控制流分析的抵御能力。通过实验计算了Python程序混淆前后的圈复杂度,并通过百分比的计算明确了相较于传统的两种算法,文中算法具备更强的防御能力。
