基于迁移模型集成的马铃薯叶片病害识别方法
2023-09-11章广传李彤何云高泉叶荣钱晔马自飞
章广传 李彤 何云 高泉 叶荣 钱晔 马自飞
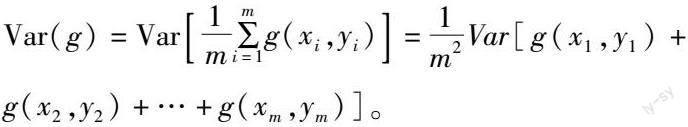

摘要:针对目前马铃薯叶片病害识别工作量大、准确率低且主观性强等热点问题,提出1种通过ResNet34模型结合不同迁移方式进行集成学习以快速识别马铃薯叶片病害图像的方法。首先,利用多种迁移方式(全部参数迁移、特征提取、微调及全新训练4种训练方法),通过调整超参数,使模型快速收敛达到全局最优点。其次,使用混淆矩阵对多种迁移方式的训练模型结果进行对比分析,微调模型识别准确率达到95.45%。最后,利用集成学习将3种训练较优的模型进行集成并与微调模型进行对比。通过试验建立了1个马铃薯叶片病害图像数据集,结果表明,相比现有热门神经网络模型,该数据集无论是识别准确率还是识别效率均有显著提升,通过对比发现,试验的总体准确率提升了3.68百分点,达到99.13%,迁移学习能够更快速地收敛,减少训练时间,并且集成学习能够大幅提升平均識别准确率。本研究提出的针对马铃薯叶片病害的识别方法成本低、精确率高,能更好地应用于日常病害识别中,为植物叶片病害的智能诊断提供借鉴和参考。
关键词:马铃薯;病害识别;迁移学习;ResNet;集成学习
中图分类号:TP183;TP391.41 文献标志码:A
文章编号:1002-1302(2023)15-0216-09
基金项目:国家自然科学基金(编号:32101611);云南省重大科技专项(编号:202002AE090010);云南省基础研究计划(编号:202101AU070096)。
作者简介:章广传(1998—),男,安徽铜陵人,硕士,主要从事智慧农业研究。E-mail:1535797658@qq.com。
通信作者:李 彤,教授,主要从事智慧农业研究。E-mail:tli@ynu.edu.cn。
利用计算机图像处理与模式识别技术对农作物的病害进行自动识别是当前研究的热点。马铃薯与小麦、稻谷、玉米、高粱并称为世界五大作物,中国是世界马铃薯总产量最多的国家。马铃薯病害发多于叶部,其中早疫病、晚疫病等等会对马铃薯的生长造成严重影响。目前,在作物病害识别研究中,计算机视觉技术已经发挥了举足轻重的作用,尤其是对叶部病害的识别。大多数农作物病害的识别是通过传统机器学习的方法进行的,包括支持向量机模型[1-3]等,但是这种方法的识别率较低、耗时长。卷积神经网络模型[4-6]由可学习的权重和偏置常量的神经元组成,每个神经元都接收一些输入,并做一些点积计算,输出的是每个分类的分数,以及局部连接、池化等具体操作指令,使模型具有一点自我识别能力,从而提升在病害识别中的准确率。目前,卷积神经网络已经在小麦、烟草及苹果等病害识别中取得良好效果[7-9]。在实际场景的应用中,病害识别需要考虑许多实际因素,如光照条件、病害种类、病害程度等。直接使用卷积神经网络训练,可能会因为数据集过小或不够多样化,导致模型的准确率不够理想[10]。
迁移学习是将已有的数据或模型应用在相关却不同领域的问题中,通过在其他领域中学习到的知识来解决现有领域中数据不足的问题,从而提升学习的效率[11-13]。相关研究结果表明,迁移学习通过提升模型的鲁棒性,能够大幅缩短模型训练时间。郑一力等研究发现,将迁移学习应用在Inception-V3等网络训练可以很好地识别植物叶片病害[14]。张旭等改进了ShuffleNetV2模型,其对苹果叶片病害的识别准确率达到98.95%[15]。随着计算机图像处理技术的发展,传统机器学习具有的模型的复杂度高、难以应用于实际等问题越发凸显,不适合移动设备的开发与应用。本研究基于以上研究,收集网络上的马铃薯叶片病害数据集,将ResNet34、迁移学习与集成学习相结合,改进网络的识别能力,以期为相关研究人员提供理论基础与技术支持。
集成学习使用多个学习机来解决同一问题,它通过调用一些简单的分类算法,以获得多个不同的基学习机,然后采用某种方式将这些学习机组合成一个集成学习机[16-17]。随着集成学习研究队伍的不断壮大,集成学习技术得到了快速发展,集成学习方法已将其范围扩大到各个领域,包括医疗保健、金融、保险、汽车、制造、生物信息学、航空航天等[16],使用集成学习的复合分类模型在很大程度上优于单个分类模型,而且通过集成多个分类器模型,可以减少广义误差,提高分类性能[18-19]。近年来,对集成学习的理论和集成学习的算法研究在机器学习领域内一直是一个热点,国际上机器学习界的权威学者Dietterich曾在AI Magazine上将集成学习列为机器学习领域四大研究方向的第1位。
1 材料与方法
1.1 总体框架
为了提高对马铃薯叶片病害识别的准确率,本研究提出基于迁移模型的集成学习方法,以期在目标数据集样本数量少的背景下,在不消耗其他资源的情况下提升模型的识别精度。首先,对训练样本数据集进行预处理并划分数据集,构建图像识别模型(ResNet34)以训练样本数据集。随后,利用ImageNet数据集训练ResNet34模型获取模型权重,将其迁移至本研究搭建的图像识别模型中,利用不同迁移方式进行训练,得到不同模型,在测试集上对不同模型进行集成学习(投票法)以提升识别准确率,详见图1。
1.2 ResNet34网络
随着计算机技术的发展,研究者对图像分类的要求越来越高,浅层的神经网络难以满足图像分类的需求,优秀的深层网络模型不断被人们创造出来。但是,伴随网络的加深,出现了梯度消失、梯度爆炸与网络退化等问题[20]。为了解决上述问题,He等提出,ResNet、ResNext可由一系列残差块堆叠而成,并且数量可以达到成百上千层[21]。本试验选择的模型为ResNet34,其结构如图2、表1所示。对于表1中conv_3x、conv_4x、conv_5x对应的一系列残差结构,第1层残差结构都是虚线残差结构,因为这一系列残差结构的第1层都有调整输入特征矩阵520的使命(将特征矩阵的高、宽缩减为原来的一半,将深度channel调整成下一层残差结构所需要的)[20]。
由图3可见,上述提到的残差结构主要有2个结构,图3-a的残差结构针对层数较少的网络,如ResNet18、ResNet34等,图3-b是针对网络层数较多的网络,如ResNet101、ResNet152等。
1.3 超参数
1.3.1 batch size batch_size指1次训练所抓取的数据样本数量,其大小影响训练速度、模型优化[22],其最大的好处在于使中央处理器(CPU)或图形处理器(GPU)满载运行,提高了训练的速度,其次是使得梯度下降的方向更加准确。梯度方差的公式如下:
式中:m为batch_size设置的大小,本研究后续一律使用m代替,增大m可以使得梯度方差减小,使梯度更加准确,而减小m会使梯度变化波动大,网络不容易收敛;g()为训练集上学得模型在x上的预测输出;x为测试样本;y为x的真实标记。
1.3.2 学习率 在卷积神经网络每次迭代时,更新参数都会存在一定的误差。学习率是深度学习中的重要超参数,合适的学习率可以使损失函数在较短时间内收敛到局部最小值[23]。当学习率设置过小时,损失函数的变化速度就会变慢,会大大增加网络的收敛复杂度,如果损失函数曲线离理论最优点较远,会增加网络达到极值的时间,并且很容易被困在局部最小值附近或者鞍点。当学习率设置远超阈值时,损失函数可能会直接跳过全局最优点,网络永远无法达到理想状态。
1.4 迁移学习
迁移学习的过程如图4所示。迁移学习可以加快网络模型的学习进度,减少模型的收敛进度。利用迁移学习可以将在ImageNet中训练好的模型的权重参数迁移到预训练模型中,实现对马铃薯叶片病害的有效识别。迁移方式有特征提取、全部参数迁移及部分迁移3种。
1.4.1 特征提取 特征提取指在原模型中,除了全连接层外的全部参数都不更新,将原全连接层更换为随机权重的新的全连接层,并且只更新全连接层的参数。
1.4.2 全部参数迁移 全部参数迁移又称模型迁移,源域模型和目标域模型共享模型参数,也就是将之前在源域中通过大量数据训练好的模型参数直接应用在目标域的模型上进行预测。基于模型的迁移学习方法比较直接,该方法的优点是可以充分利用模型之间存在的相似性,缺点是模型参数不易收敛。
1.4.3 微调 使用预训练网络初始化网络,用新数据训练部分卷积层。微调的大致过程如下:在预先训练过的网络上添加新的随机初始化层,预先训练的网络参数也会被更新,但会使用较小的学习率以防止预先训练好的参数发生较大变化。常用的方法是固定底层的参数、调整一些顶层或具体层的参数。微调的好处是能够减少训练参数的数量,有助于克服过拟合。
1.5 集成学习
集成学习是一种机器学习的方法,多个学习器被集中到一起来训练、解决同一个问题,与普通机器学习方法(试图从训练数据中学习一个模型)不同,集成学习可以从训练数据中的多个模型集成其优点,可使识别准确率得到提高。目前广泛使用的集成学习方法有Bagging法[19,24]、Boosting法[24-26]。集成学习中的投票法是选择若干模型作为基础学习器,用这些基础学习器分别识别样本,通过识别结果进行投票,根据少数服从多数的原则,通过多个模型的集成降低方差,从而提高模型的鲁棒性。
在理想情况下,投票法的预测效果应优于任何一个基模型的预测效果。但是,投票法也有其局限性,即它对于所有模型的处理都是一样的,也就是所有模型的权重对于最后结果的影响都一样大。如果某个模型在特定的表现情况下很好,而在其他情况下的表现很差,这是使用投票法时需要考虑的一个问题。集成学习的训练策略如图5所示。
图5中,投票机制是绝对多数投票法,以每次批量加载到网络中的样本为例,通过统计3个预测模型对病害图像xi的预测结果y1i、y2i、y3i并进行投票,投票法可表示为:
式中:H(x)为投票结果;i表示第i个样本;k表示第k个模型;Reject表示投票失败;yki表示第k个预测模型对第i个样本的预测结果。
2 结果与分析
2.1 试验环境
本试验采用Pytorch作为小麦病害识别中模型搭建、训练的平台,试验地点为云南省作物生产与智慧农业重点实验室,试验时间为2022年5—11月。试验模型在GPU环境下训练,试验的软件、硬件配置如表2所示。
2.2 数据来源
本试验以健康马铃薯叶片和4种病害马铃薯叶片(发生马铃薯早疫病的一般类别叶片、发生马铃薯早疫病较严重的叶片、发生马铃薯晚疫病的一般类别叶片和发生马铃薯晚疫病较嚴重的叶片)作为试验对象。试验数据来自AI Challenger 2018竞赛的数据集,选取其中的马铃薯类别作为本试验对象,共2 840幅,如图6所示。
2.3 数据增强与数据预处理
由于试验中马铃薯叶片的病害数据集图片有限且分布不均,因此选择数据增强的方法扩大数据集,以增强原数据集中存储的病害图像的多样性,从而增强模型的泛化能力。数据增强技术包含多种变换方法,包括颜色的数据增强(色彩饱和度、对比度与亮度)、镜像变换等。试验通过使用Python中的PTL模块对所有试验数据图像进行水平翻转,以增强模型的鲁棒性及适应性。同时,针对数据集中的某些病害进行垂直翻转,以达到各类数据样本相对平衡。数据增强后的所有样本共计5 158幅。
为了使模型训练更有效率,将5 158幅叶片病害图像统一调整为224像素×224像素大小,并用0、1、2、3、4作为数据集标签分别代表健康马铃薯叶片、发生早疫病的一般马铃薯叶片、严重发生早疫病的马铃薯叶片、发生马铃薯晚疫病的一般叶片与严重发生马铃薯晚疫病的叶片。依据数据增强后的图像划分数据集,按照8 ∶2的比例划分数据集,将数据集分为训练集和验证集,再将训练集按9 ∶1划分成训练集与测试集数据增强后的图像数量,如图7所示。
2.4 超参数的性能评估
2.4.1 m对模型性能的影响 本环节探讨不同m值(batch_size)对模型识别准确率的影响。将m设置为4的倍数,分别测试当m=16、32、64时对模型准确率的影响。从图8可以看出,当m=32时,训练效果最为平滑,效果最好。
2.4.2 学习率对模型性能的影响 本试验对3种不同的初始学习率进行测试训练,如图9所示,分别设置初始学习率为0.01、0.001、0.000 1、0.000 01,在同样的m值下测试试验结果。当初始学习率设置为0.01时,训练测试效果不是很理想;当初始学习率设置为0.001时,准确率继续提升;当初始学习率设置为0.000 1时,准确率仍在提升,达到85%;当初始学习率设置为0.000 01时,模型准确率变低,模型收敛慢。因此 选择初始学习率为0.000 1作为试验的默认准确率。
2.5 特征图的可视化
对ResNet34网络模型卷积块进行特征可视化,以方便观察该模型的卷积过程及理解模型识别病害的总过程。从卷积块的浅层到深层进行选择性的可视化。分别选取网络的conv1层卷积、layer1_conv3卷积、layer1_conv4卷积进行对比,从图10可以看出,特征图在第1次卷积时可以清楚地看到叶片的病害信息。随着卷积层数的增加,对叶片的信息也越来越模糊,可以解释为卷积神经网络浅层卷积层的特征提取更多的是对纹理和一些细节信息进行提取,而深层卷积层的特征提取更多的是对抽象特征信息进行提取。
2.6 迁移学习方法的性能评估
图11是ResNet34训练模型与不同迁移学习方式的混淆矩阵的对比结果,混淆矩阵横轴0、1、2、3、4分别代表真实类别的马铃薯健康叶片、发生早疫病的一般马铃薯叶片、严重发生马铃薯早疫病的叶片、发生马铃薯晚疫病的一般叶片与严重发生马铃薯晚疫病的叶片。纵轴0、1、2、3、4分别代表模型预测类别的马铃薯健康叶片、发生早疫病的一般马铃薯叶片、严重发生马铃薯早疫病的叶片、发生马铃薯晚疫病的一般叶片与严重发生马铃薯晚疫病的叶片。当模型预测类别与真实类别一一对应时,即混淆矩阵的蓝色程度越深时,意味着模型的预测效果越好。利用混淆矩阵比较容易判别模型的预测结果与真实结果之间的误差。根据混淆矩阵判断微调模型在识别严重发生马铃薯早疫病、发生马铃薯早疫病的一般情况和发生马铃薯晚疫病的一般情况时效果较好,全新训练模型在识别严重发生马铃薯晚疫病时的效果较好。分析可知,微调模型的总体识别效果较好。
本次微调试验将ResNet34网络的前6个层冻结,然后对后面的卷积层及全连接层进行重新训练。由于底层网络收集的都是图像的曲线、边缘等一系列普遍特征,一般的卷积神经网络的底层网络收集的信息都是相通的,因此保持这些权重不变,对后面部分网络进行重新训练,使其更为关注马铃薯病害数据集的一些特有特征,直到冻结所有卷积层,本试验的目的便是为了找到准确率最高的微调方法。
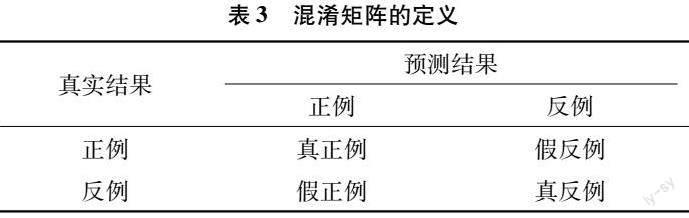
本试验主要研究3种迁移方式(全部迁移、特征提取和微调)与全新训练队模型准确率、模型的精确率、模型的召回率、模型的特异率及迭代1次的时间,将这5个参数进行对比,选择比较好的3个模型进行集成学习。其中,微调模型的识别效果最好,在整体准确率上,微调模型的准确率比全部迁移模型高1.51百分点,比特征提取模型高9.52百分点,比全新训练模型高3.68百分点,精确率、召回率与特异率也有明显的提升。每次迭代的时间也有大幅减少(除了与特征提取模型相比),特征提取冻结了除了全连接层之外的全部网络的权重,能够减少模型对预训练的卷积层的重新学习的过程,因此每次迭代的时间最短,而全部迁移模型、全新训练的模型都是每次更新卷积层的权重,所以每次迭代时间最长。微调模型只冻结前6个层,对后面的卷积层和全连接层的权重进行重新训练,因此每次迭代的时间相比较于全新训练、全部迁移会变短。采用准确率作为模型结果的主要评价指标,对模型进行进一步改进,采用精确率(P)、召回率(R)和特异度(S)作为模型进一步分析的评价指标,每个指标均由混淆矩阵计算得到,详见表3。
准确率(A):准确率指模型能够正确识别所有样本中正确样本的比例,公式如下:
A=真正例+真反例真正例+假反例+假正例+真反例×100%。
精确率(P):精确率指某类预测正确的样本中真实正确样本的比例,公式如下:
P=真正例真正例+假正例×100%。
召回率(R):召回率指某类正确样本中的被正确预测的样本所占比例,公式如下:
R=真正例真正例+假反例×100%。
特异度(S):特异度指某类反例的样本中被预测为反例样本所占比例,公式如下:
S=真反例真反例+假正例×100%。
2.7 集成学习对模型的提升
从表4中对4种不同模型的效果对比可以看出,全部迁移、微调与全新训练的模型训练效果较好,因此选择这3种模型进行下一步的集成学习。由于微调模型的识别准确率最高,因此将3种模型集成学习后的效果与微调模型进行对比。
本次集成学习主要通过全部迁移、全新训练、微调3种模型完成,首先将3种模型的预测结果分别导入3个不同的列表(list_a、list_b与list_c)中,再分别对列表中的类别进行投票,选择最终类别,得到投票预测准确的图片数量,绘制混淆矩阵,混淆矩阵如图12所示。在微调模型的基础上进一步提高预测准确率,对比结果如表5所示。
马铃薯健康叶片经过集成学习硬投票,没有将微调识别错误的样本投票为正确的样本,发生早疫病的一般马铃薯叶片经过集成学习硬投票,将微调识别错误的2个样本全部转化为正确样本,严重发生马铃薯早疫病的叶片经过集成学习硬投票,将微调识别错误的6个样本全部转化为正確样本,发生马铃薯晚疫病的一般叶片经过集成学习硬投票,没有将微调识别的错误样本投票为正确的样本,严重发生马铃薯晚疫病的叶片经过集成学习硬投票,将微调识别错误的11个样本中的9个转化为正确样本。集成学习的总体准确率较微调模型提高了3.68百分点,较全新训练模型提高了7.36百分点。
3 结论
针对马铃薯叶片样本量少且背景复杂的病害图像,本研究提出了一种在ImageNet上完成预训练的ResNet34网络,通过迁移学习、集成学习的方法对马铃薯叶片病害进行了分类试验,并就m、学习率、学习方法等因素对模型性能的影响进行了对比分析,得到如下结论:ResNet34网络可以自动从原始数据中提取马铃薯叶片的病害特征,平均识别准确率达到91.77%;对于全新训练而言,迁移学习可以充分利用在大型数据集上学习到的知识,可以大幅缩短模型训练时间,约减少3/5。在同一学习率下,集成学习的平均识别准确率相比全新训练提高了7.36百分点;集成学习将不同迁移方式得到的模型进行集成,最终结果优于任何一种迁移方式得到的模型,相比微调模型,平均识别准确率提高了3.68百分点。
参考文献:
[1]魏丽冉,岳 峻,李振波,等. 基于核函数支持向量机的植物叶部病害多分类检测方法[J]. 农业机械学报,2017,48(增刊1):166-171.
[2]张云龙,袁 浩,张晴晴,等. 基于颜色特征和差直方图的苹果叶部病害识别方法[J]. 江苏农业科学,2017,45(14):171-174.
[3]刘 媛,冯 全.葡萄病害的计算机识别方法[J]. 中国农机化学报,2017,38(4):99-104.
[4]郭小燕,于帅卿,沈航驰,等. 基于全局特征提取的农作物病害识别模型[J]. 农业机械学报,2022,53(12):301-307,379.
[5]孟 亮,郭小燕,杜佳举,等. 一种轻量级CNN农作物病害图像识别模型[J]. 江苏农业学报,2021,37(5):1143-1150.
[6]曾伟辉,李 淼,李 增,等. 基于高阶残差和参数共享反馈卷积神经网络的农作物病害识别[J]. 电子学报,2019,47(9):1979-1986.
[7]张红涛,朱 洋,谭 联,等. 基于FA-SVM技术的烟草早期病害识别[J]. 河南农业科学,2020,49(8):156-161.
[8]张 航,程 清,武英洁,等. 一种基于卷积神经网络的小麦病害识别方法[J]. 山东农业科学,2018,50(3):137-141.
[9]孙 俊,谭文军,毛罕平,等. 基于改进卷积神经网络的多种植物叶片病害识别[J]. 农业工程学报,2017,33(19):209-215.
[10]刘玉耀,彭琼尹. 基于卷积神经网络和迁移学习的瓯柑病虫害识别研究[J]. 热带农业科学,2022,42(9):64-70.
[11]杜甜甜,南新元,黄家興,等. 改进RegNet识别多种农作物病害受害程度[J]. 农业工程学报,2022,38(15):150-158.
[12]李 好,邱卫根,张立臣.改进ShuffleNet V2的轻量级农作物病害识别方法[J]. 计算机工程与应用,2022,58(12):260-268.
[13]孙 俊,朱伟栋,罗元秋,等. 基于改进MobileNet-V2的田间农作物叶片病害识别[J]. 农业工程学报,2021,37(22):161-169.
[14]郑一力,钟刚亮,王 强,等. 基于多特征降维的植物叶片识别方法[J]. 农业机械学报,2017,48(3):30-37.
[15]张 旭,周云成,刘忠颖,等. 基于改进ShuffleNetV2模型的苹果叶部病害识别及应用[J]. 沈阳农业大学学报,2022,53(1):110-118.
[16]张春霞,張讲社. 选择性集成学习算法综述[J]. 计算机学报,2011,34(8):1399-1410.
[17]杨融泽,柳 毅. 面向异常数据流的多分类器选择集成方法[J]. 计算机工程与应用,2018,54(2):107-113.
[18]Tian Y,Zhao C J,Lu S L,et al. SVM-based multiple classifier system for recognition of wheat leaf diseases[C]//2012 World Automation Congress.Puerto Vallarta Mexico,2012.
[19]车翔玖,于英杰,刘全乐. 增强Bagging集成学习及多目标检测算法[J]. 吉林大学学报(工学版),2022,52(12):2916-2923.
[20]郭玥秀,杨 伟,刘 琦,等. 残差网络研究综述[J]. 计算机应用研究,2020,37(5):1292-1297.
[21]He K M,Zhang X Y,Ren S Q,et al. Deep residual learning for image recognition[C]//Computer vision and pattern recognition.IEEE,2016.
[22]张忠林,余 炜,闫光辉,等. 基于ACNNC模型的中文分词方法[J]. 中文信息学报,2022,36(8):12-19,28.
[23]王东方,汪 军. 基于迁移学习和残差网络的农作物病害分类[J]. 农业工程学报,2021,37(4):199-207.
[24]Takemura A,Shimizu A,Hamamoto K. Discrimination of breast tumors in ultrasonic images by classifier ensemble trained with AdaBoost[J]. Electronics & Communications in Japan,2011,94(9):18-29.
[25]金松林,来纯晓,郑 颖,等. 基于特征选择和CNN+Bi-RNN模型的小麦抗寒性识别方法[J]. 江苏农业科学,2022,50(10):201-207.
[26]李 凯,崔丽娟. 集成学习算法的差异性及性能比较[J]. 计算机工程,2008(6):35-37.
