一种基于迁移极速学习机的人体行为识别模型
2015-09-22支周屈肃
支周+屈肃

摘 要:为了解决由于每个用户的行为都有自身的特点和习惯,加之手机放置位置和方向的不确定性及多样性所导致的通用模型识别率低的问题,文章提出了利用TrELM(Transfer Extreme Learning Machine)算法实现迁移学习,并基于智能手机中内置的加速度传感器进行信息采集并通过机器学习方法构建人体行为识别模型。该方法是一种基于参数迁移的方法,通过对ELM的目标函数进行修改,引入一个可以表示两域差异的迁移学习量,从而实现ELM模型的迁移学习。实验结果表明,该模型可以有效的提高新用户的行为识别正确率。
关键词:迁移学习;人体行为识别;极速学习机;机器学习
中图分类号:TP391 文献标识码:A 文章编号:2095-1302(2015)09-00-03
0 引 言
基于智能手机进行人体行为识别是移动情景识别的一个重要研究方向,在健康监控、行为检测、老年人监管等方面有广泛应用[1]。在构建行为识别模型时,利用智能手机中内置的三轴加速度传感器,对人们多种日常行为的加速度数据进行采集,并通过机器学习的方法,构建用户行为识别模型[2]。
由于每个用户的行为都有自身的特点和习惯,加之手机放置位置和方向的不确定性及多样性,导致不同用户的行为加速度数据特征的数据分布差异较大,以至于识别模型的不适用性大大增加。为了解决识别模型的自适应性问题,并且以最小的代价获得较大收获,这就需要利用迁移学习对通用模型进行修改。
为了解决通用行为模型在面对新用户时的不适用问题,本文提出了TrELM算法实现迁移学习。该方法是一种基于参数迁移的方法,通过对ELM的目标函数进行修改,引入一个可以表示两域差异的迁移学习量,实现ELM模型的迁移学习。利用TrELM算法实现通用模型的迁移,首先利用ELM分类器构建通用行为识别模型,可以得到源域中识别模型的输出权值向量βS;之后通过对新用户的少量行为样本进行学习,修改通用模型的输出向量为βt,实现对通用模型的修改,完成具有迁移学习功能的行为识别模型。
1 已有研究
Dai提出了一种TrAdaBoost方法[3],该方法的假设前提为源域和目标域实例数据的特征和标记相同,但数据分布不同。该方法利用AdaBoost方法构建了一个数据样本权值自动调整的机制,在迭代过程中对源域和目标域的数据采取不同的权重调整机制,进而可以实现减少有害数据对目标域学习的影响。该方法虽然可以借助源域的部分数据样本作为辅助数据来在目标域进行学习,但是当源域和目标域的数据样本相似性较差时,负迁移效果会增加。Jiang等在文献[4]中的处理办法是对源域数据样本进行领域适应性的转变,将产生负迁移效应的源域样本删除后再进行赋值,增加其在目标域中的权值大小,最终可以利用具有预测标签的目标域样本对源域样本的质量进行提升。
Dai等人在文献[5]中提出翻译特征迁移学习方法,该方法是一种较为基础的特征迁移学习方法,主要通过对跨领域的特征进行学习,用以解决训练数据和测试数据所属特征空间不同的问题,利用不相关的数据帮助目标分类和聚类学习。
Lawrence在文献[6]中提出了一种高效算法MT-IVM,该方法构建了多任务的高斯过程,在其特性上获取知识,以实现知识共享。Bonilla在文献[7]中也研究了高斯过程下的多任务学习,提出了基于任务间自由形式的协方差矩阵,进而模拟交互任务的依赖性,最终利用高斯过程中知识对任务间的相互关系进行学习。Schwaighofer等人构建了基于高斯过程和贝叶斯算法的统一模型,以解决多任务学习问题[8]。在文献[9]中,Evgeniou提出了一种以分层贝叶斯模型为前提的规则化框架,并实现了在迁移学习中的应用,解决了多任务学习的问题。该方法的实现基于如下假设,即在面临每个任务时,将SVMs中的特征分为两部分,一部分是所有任务都具有的共同体,另一部分是针对某个任务的专有部分,这种方法适用于具有较多样本,且源域和目标域样本较为单一的情况。
Mihalkova在文献[10]中提出了TAMAR算法,通过马尔科夫逻辑网络在相关联领域间迁移相关知识。在马尔科夫模型中,关联领域的实体通过预测表现出来,他们的关联性可由一阶逻辑表示。该方法基于这样一个事实,若两个域是相关的,则存在一种从源域到目标域的实体之间及关系的映射。TAMAR算法分为两个阶段,首先构造一个基于加权的对数似然度的从源域到目标域的映射;之后利用FORTE算法修正目标域的映射结构,修改后的马尔科夫逻辑网络可以用作目标域的关联模型来使用。此外,Davis等人构建了二阶马氏逻辑,实现相关知识的迁移学习,该方法根据反相马尔科夫链的形式实现源域中某一样本的架构构造,进而可以在目标域中获取该样本的公式。
本文所提出的TrELM算法结合了参数迁移方法,实现了ELM在模型层面上的迁移学习功能。
2 基于迁移极速学习机的行为识别模型
目前,针对ELM迁移学习方法的研究主要是基于实例迁移学习方法,基于参数的迁移学习大多是在SVM结构中实现的。迁移学习算法TL-SVM通过对SVM分类器进行深入研究,从判别函数f(x)=wTx+b中发现不同域间的差异体现在其w值上。通过构造可以体现两域间差异的项μ‖wt-wS‖2,将其添加至SVM目标式中,根据一系列运算规则,即可实现不同域间的迁移学习。
用ELM构建模型,会得到输出权值向量β,针对数据分布不同的领域,在其上训练的ELM模型中的β向量必然不同,虽然模型构建时输入节点加权值向量以及偏差向量均是随机赋值的,但其模型构建理论可以说明,以不同域数据样本构建的多个ELM分类模型间的差异,可以用输出权值向量β表示。
鉴于SVM及ELM的相关性以及基于SVM的迁移学习研究,构造TrELM(Transfer Extreme Learning Machine)算法模型。通过在ELM的目标式中增加μ‖βt-βS‖2项,可以表示两个域间的差异,通过严密的数学公式推导求解后,可以得到目标域内的ELM目标式,进而实现两域间的迁移学习。其中,‖βt-βS‖2表示两域分类器之间的差异程度,该值越大则分类器间的差异越大,反之越小;参数μ控制惩罚程度。TrELM算法原理如图1所示。
图1 TrELM算法原理
3 实验结果
项目组是以智能手机为背景的行为识别模型的迁移学习,将九名测试者p1至p9按其年龄分布分为A、B、C三组,其中,A组成员为p1-p3,年龄分布为20-30岁,相应样本集记DA;B组成员为p4-p6,年龄分布在31-40岁,相应样本集记DB;C组成员为p7-p9,年龄分布在41-50岁,相应样本集记DC。上述每个样本集均按比例(1:3)分为两部分,即DA1、DA2,DB1、DB2和DC1、DC2。
为了论证方法的有效性,实验将分为迁移学习前和迁移学习后模型的适应性统计两部分。第一部分分别以DA、DB和DC作为训练集,构建ELM通用行为识别模型,之后对其余两个样本集进行测试,统计测试集正确率,以衡量未迁移学习时的模型适应性;第二部分是在第一部分的基础上,以其余样本集中较少部分作为迁移学习训练样本集,对模型进行TrELM算法的自适应性修改,以测试集正确率作为迁移学习后的模型适应性能力进行统计。每组实验均进行20次,统计正确率的平均值。
在构建通用行为识别模型时,由于ELM算法的输入权值向量是随机赋值的,故只需要确定隐藏层节点数即可。目前统一规范确定隐藏层数量,只能靠经验值确定。选取隐藏层参数为100,以达到构建最优网络的目的。
另外,在ELM的输出函数中,C的取值范围[2^(-10), 2^(25)],选取分类器性能最优时的C值为2^(18)。
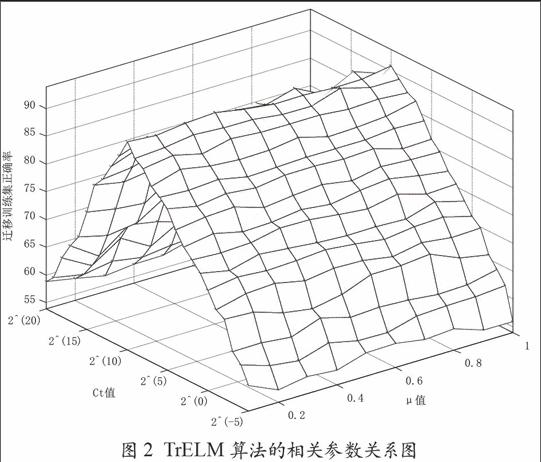
在迁移学习过程中,假设TrELM算法的性能是由其相关参数μ和Ct确定的。令μ的取值范围为[0,1],Ct的取值范围为[2^(-5), 2^(20)] 。统计迁移训练集20次实验的平均正确率如图2所示。图2中所示为三轴坐标,坐标系中每个点表示取该点所在的Ct和μ值时,模型在迁移训练集上所得到的正确率。由图2可知,在保证TrELM算法性能最优的前提下,取μ为0.4,Ct为2^(10)。
图2 TrELM算法的相关参数关系图
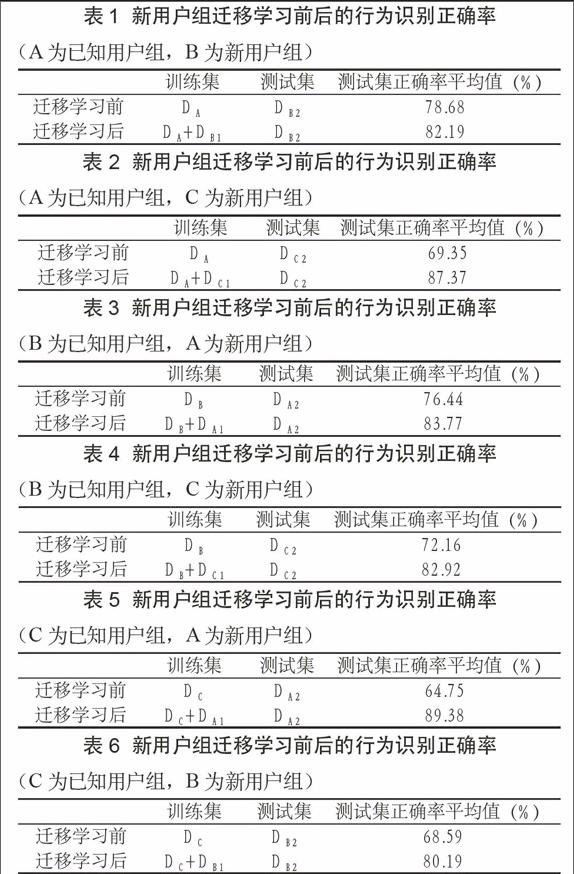
表1至表6为各交叉用户组在模型迁移学习前后的行为识别准确率平均值的统计,上述两部分实验的相关样本集及正确率统计结果分别列于各表中的第一行和第二行。
表1 新用户组迁移学习前后的行为识别正确率
(A为已知用户组,B为新用户组)
训练集 测试集 测试集正确率平均值(%)
迁移学习前 DA DB2 78.68
迁移学习后 DA+DB1 DB2 82.19
表2 新用户组迁移学习前后的行为识别正确率
(A为已知用户组,C为新用户组)
训练集 测试集 测试集正确率平均值(%)
迁移学习前 DA DC2 69.35
迁移学习后 DA+DC1 DC2 87.37
表3 新用户组迁移学习前后的行为识别正确率
(B为已知用户组,A为新用户组)
训练集 测试集 测试集正确率平均值(%)
迁移学习前 DB DA2 76.44
迁移学习后 DB+DA1 DA2 83.77
表4 新用户组迁移学习前后的行为识别正确率
(B为已知用户组,C为新用户组)
训练集 测试集 测试集正确率平均值(%)
迁移学习前 DB DC2 72.16
迁移学习后 DB+DC1 DC2 82.92
表5 新用户组迁移学习前后的行为识别正确率
(C为已知用户组,A为新用户组)
训练集 测试集 测试集正确率平均值(%)
迁移学习前 DC DA2 64.75
迁移学习后 DC+DA1 DA2 89.38
表6 新用户组迁移学习前后的行为识别正确率
(C为已知用户组,B为新用户组)
训练集 测试集 测试集正确率平均值(%)
迁移学习前 DC DB2 68.59
迁移学习后 DC+DB1 DB2 80.19
通过上述表格的第一行可以看出,对于所构建的通用行为模型,在面临新用户时,行为识别正确率较低,平均值最低为64.75%,说明了对新用户进行行为识别时,通用模型的不适应性以及迁移学习的必要性。通过对比各表格中第一二行的测试集正确率,可以看出,利用新用户的行为数据进行了基于TrELM算法的模型迁移学习后,行为识别正确率有了明显提高,表5中正确率的增加幅度最大,为24.63%,说明了TrELM算法可以有效达到迁移学习的目的。
另外,表2和表5中测试集正确率增加值要大于其余四个表,这是由于当所迁移到的目标域用户组年龄组成与源域训练组差异较大时,两组行为特征值的数据分布也会有较大不同,通用模型的不适应性增大,在这种情况下进行迁移学习,可以得到更好的效果,识别正确率也会有较大提高。
4 结 语
为了解决通用行为模型在面对新用户时的不适用问题,本节提出了TrELM算法实现迁移学习。该方法是一种基于参数迁移的方法,是通过对ELM的目标函数进行修改,引入一个可以表示两域差异的迁移学习量,实现ELM模型的迁移学习。利用TrELM算法实现通用模型的迁移,首先利用ELM分类器构建通用行为识别模型,可以得到源域中识别模型的输出权值向量βS;之后通过对新用户的少量行为样本进行学习,修改通用模型的输出向量为βt,实现对通用模型的修改,完成具有迁移学习功能的行为识别模型。实验在真实数据集上进行,结果表明,该模型可以有效提高新用户的行为识别正确率。
参考文献
[1]张烁,段富.基于智能移动平台的情景感知技术研究[J].计算机应用与软件,2013,30(8): 166-169.
[2]徐川龙,顾勤龙,姚明海.一种基于三维加速度传感器的人体行为识别方法[J].计算机系统应用,2013,22(6):132-135.
[3] Dai Wenyuan,Yang Qiang,Xue Guirong,et al.Boosting for transfer learning[Z]. Proceedings of the 24th international conference on Machine learning ACM International Conference Proceeding Series, 2007:193-200.
[4] Dai W,Chen Y,Xue G,et al.Translated Learning:Transfer Learning across Different Feature Spaces[Z].In Advances in Neural Information Processing Systems,2008.
[5] Lawrence N D,Platt J C.Learning to Learn with the Informative Vector Machine[Z].In Proceedings of the International Conference in Machine Learning,2004.
[6] Bonilla E V, Chai K M A, Williams C K I. [Z].Nips,2008.
[7] Schwaighofer A,Tresp V,Yu K.Learning Gaussian Process Kernels via Hierarchical Bayes[J].In Advances in Neural Information Processing Systems, 2004: 1209-1216.
[8] Evgeniou T,Pontil M.Regularized multi-task learning[J].In Proceedings of 17th SIGKDD Conf[J]. on Knowledge Discovery and Data Mining,2004,28(1):109-117.
[9] Mihalkova L,Huynh T,Mooney R J. Mapping and revising Markov logic networks for transfer learning[C].National Conference on Artificial Intelligence-volume:AAAI Press,2007,608--614.
[10] Davis J, Domingos P. Deep Transfer via Second-Order Markov Logic[J]. Proceedings of the Aaai Workshop on Transfer Learning for Complex Tasks, 2009.
