基于改进的LogitBoost算法的垃圾网页检测研究
2015-10-08周爽等
周爽等

【摘 要】实现垃圾网页的有效检测可以有效提高搜索引擎检索质量,促使网页的设计向着面向用户的方向发展。由于垃圾网页是面向搜索引擎设计的,正常网页是面向用户设计的,因而两者在特征方面存在众多区别,通过机器学习方法可以根据垃圾网页与正常网页在特征方面的不同对垃圾网页进行有效识别。通过对常见单分类器和集成学习分类器处理垃圾网页数据集的对比实验,发现集成学习方法logitboost较为突出,所得结果明显优于单一分类器和常用集成学习算法,所得结果也更接近真实值,并通过对logitboost所用的预处理方法和基分类器进行改进,发现用resample对垃圾网页进行预处理,以REPTree算法为基分类器的logitboost算法对垃圾网页数据集的分类有较高的精确度。
【关键词】垃圾网页识别;集成学习;Weka logitboost
0 引言
大数据时代,信息的指数式增长使得信息在人们的生活中发挥着越来越重要的作用,而信息技术的发展使搜索引擎成为互联网用户查询资料、搜索有效信息的有效工具。同时,电子商务的飞速发展让商家看到了互联网上存在的巨大的利润,据中国电子商务发布的数据显示,2014年中国电子商务交易规模已达13.4万亿元,上涨31.4%,其中B2B电子商务市场规模已达10万亿。对商业网站而言,网页的排名越靠前,该网页浏览量也会相应增加,网站流量的增加就意味着利润的增加。
然而,多数的互联网用户习惯关注搜索引擎排序靠前的少数网站,据统计95%的用户只对前五页的搜索结果有兴趣,大量排序靠后的网站被用户选择性忽视[1]。因此,在利益因素的驱动下,有些网站的制作者和管理者采用不道德的方式迷惑搜索引擎排序算法,使网页获得高于其实际的虚假排名,这种网页被称为垃圾网页。
垃圾网页严重恶化了搜索引擎搜索结果的质量,使用户在信息获取过程中遇到阻碍,降低了用户对搜索引擎的信任度,同时还会助长更多的互联网作弊行为,严重影响了互联网检索环境。因此,垃圾网页的识别成为搜索引擎的重要挑战之一,实现对垃圾网页的有效检测成为现今互联网产业发展一个亟待解决的问题。
1 垃圾网页识别
1.1 垃圾网页
垃圾网页是指专为搜索引擎设计,而非用户设计,其通过不道德的手段欺骗搜索引擎,获得高于实际的排序结果以增加访问量的网页,其主要的作弊方式有内容作弊、链接作弊和隐藏作弊[2]三种形式,达到欺骗搜索排序算法的效果。
内容作弊通过改变文本内容的相关性来提升网页的排序值,内容作弊的实现方式主要有两种:一种是在一个小关键词集合中设法提高关键词之间的相关性;另一种增加搜索引擎查询关键词的数目。链接作弊是通过创建大量出链到另一网页或聚集大量入链指向单一目标网页或组页面等创建链接结构来增加页面的重要性,从而实现搜索排名的提高。隐藏作弊就是通过某种方式隐藏垃圾网页的一些内容和链接,实现对用户和搜索引擎不可见。
垃圾网页具有多样性、隐藏性、融合性和进化型的特点,这些特点让垃圾网页对于用户和搜索引擎都有严重的危害。对于用户,大大增加了查找信息的难度,产生较差的用户体验,使降低了用户对搜索引擎的信任度;对于搜索引擎,垃圾网页会导致搜索引擎的链接中堆砌大量无用的垃圾信息,消耗大量索引时间和存储空间,令搜索引擎的检索速度大大减慢;同时垃圾网页还会助长更多的互联网作弊行为,偏离面向用户设计的基本目的。
1.2 垃圾网页检测识别技术及现状
垃圾网页的检测技术可分为基于内容分析法、基于链接分析法和基于阻止隐藏技术分析法,由于正常网页和垃圾网页所面向的对象不同,因而正常网页和垃圾网页在特征上也存在差别,采用机器学习的方法通过增加、删减相应特征以保持系统作弊检测的有效性,因此可以更有效的实现垃圾网页的检测。
基于内容分析法是通过对网页的文本、URL属性、锚文本及超链接分布等内容特征分析统计,通过抓取网页的一些特征向量构建决策树过滤器,从而实现对正常网页和垃圾网页的区分。
基于链接分析法对垃圾网页的检测主要依靠一种信用机制,即指向正常网页的网页是垃圾网页的概率较低,通过这种信用机制,可以实现对网页的链接分析:正常网页经过K个链接所指向的网页都是正常网页或距离正常网页较远的网页是垃圾网页的概率较大。Trust Rank算法是其中最具影响力的算法,其通过建立一个高信任度的种子集合,对集合中的站点的出链进行分析,对网页是否是垃圾网页做出判断。
1.3 垃圾网页数据集及其评价指标
1.3.1 垃圾网页数据集
本文采用web spam UK2007数据集[3]进行相关对比实验,其垃圾网页训练数据集和测试集的具体情况如下图所示,从下图可以看出垃圾网页与非垃圾网页样本数的比率约为1:18,垃圾网页数据集存在不平衡问题,较大的数量差异会导致标准分类器分类性能的下降。
1.3.2 评价标准
本文采用一套结合垃圾网页特点的评价标准,包括查准率、查全率、F1测度及AUC,其中AUC是指ROC曲线下方的面积,是反映敏感性和特异性连续变量的综合指标,可以更好地处理垃圾网页数据集的不平衡问题,能更加公平的对待稀有类和大类,因此这套评价标准对于评价垃圾网页十分适合。
2 集成学习算法
集成学习方法[4]又称多重学习或分类器组合学习,是从弱分类器产生强分类器的机器学习方法,其使用一系列的学习器对训练集进行学习,通过某种规则整合各种学习器的学习结果,从而获得比单个学习器更好的学习效果。一定条件下,集成学习的性能明显好于单一分分类器的分类性能。根据学习器之间的关系集成学习可以分成并态集成学习和同态集成学习两种,其中并态集成学习使用不同学习器进行集成,同态集成学习使用同一种学习器进行集成,但是基分类器之间的参数有所不同。
集成学习通过把不同起始点得到的分类器的结果进行集成,其所得结果更好的接近全局最优解,并且所得的近似假设函数较单一分类器获得的近似函数效果更好;集成学习使用加权和扩展假设空间的方法扩大假设空间的规模,其所得的假设函数更接近真实函数;并且采用集成学习的方法可以有效减小选错分类器的风险,从而是集成的结果在一般情况下好于单一分类器的结果。
2.1 Adaboost算法
Adaboost算法[5]是一种基于基分类器的迭代算法,它将多个弱分类器联合起来对同一个训练集进行分类,来提高准确率。该类算法中,每个预测参量都是有权重的,它反映了弱分类器一次分类的错误分类的频繁,AdaBoost算法根据每次对训练集样本分类是否准确以及它的正确率来确定该次训练集的权重,在该权重基础上加减某个数值,来确定下个训练集的权值。
2.2 Logitboost算法
Logitboost算法[6]是基于机器学习的判别分类算法,它根据样本数据集构建弱分类器,通过负对数似然函数计算样本权重,调用分类器检测样本的分类,并在下一轮的迭代过程中增加判错样本的权重,经过反复调用该弱分类器,赋予判错样本较大的权重,增加其关注度,最终使得弱分类器在迭代过程中变为强分类器。Logitboost算法对于多因素、二分类及多分类数据的分析效果尤为明显,还可以发掘数据间潜在的规律。
2.3 重采样算法
重采样算法[7]可以实现对不平衡数据集分布的改变,减少各类别样本数据间的不平衡程度。数据的重采样方法从原理上可以分为:简单随机抽样法、系统抽样法、整群抽样法及分层抽样法。本文采用简单随机抽样方法resample,即利用放回或不放回方法抽取特定数目的随机样本,每个参与抽样的单元被选进样本的概率均等,采用抽签算法或随机数字表进行随机数据的抽样构建新样本。
2.4 集成学习有效性的条件
集成学习的分类效果[8]并不是绝对有效的,要想取得更好的分类效果需要满足一定的条件,即分类器保证一定的准确率且具有一定的差异性。根据PAC学习模型,集成学习是用弱分类器来产生强分类器的机器学习方法,分类器的准确率就是指分类器的分类结果要比随机猜测效果好,对于二分类问题,单个分类器的准确率要高于50%,否则集成后分类的错误率会上升。分类器的差异性是因为集成完全相同的分类器的分类效果同单一分类器的分类效果差别不大,因此为提高集成学习的效果应选用不同的分类器作为基分类器或选用参数不同的同一分类器作为基分类器。
3 垃圾网页数据集分类实验
Weka(怀卡托智能分析环境)是基于Java的开源数据挖掘软件,集合了大量承担数据挖掘的机器学习算法,可以明显提高算法对数据集的处理效果。
3.1 Weka简介
Weka是怀卡托大学的weka小组完成的开放的数据挖掘平台,被誉为“数据挖掘和机器学习历史上的里程碑”,是现今最完备对的数据挖掘工具之一。Weka提供的多种机器学习方法可方便用户发现数据集中隐藏的数据之间的关系;该工具还有多种适用于任意数据集的数据预处理功能;并且,用户还可以实现对算法的性能进行评估。
本文基于weka平台对垃圾网页数据集进行分析,可以充分利用该工具在数据集处理方面的优势,直接使用其集成学习算法,实现对垃圾网页数据集分类任务的有效改进。
3.2 基于weka平台的集成算法对垃圾网页数据集的分类
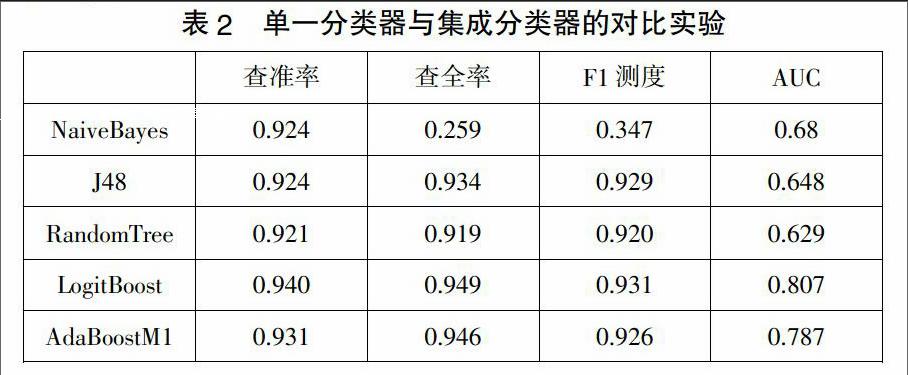
本实验采用单一分类器和集成学习分类器的对比试验,单一分类器选用朴素贝叶斯、J48和随机树,集成学习算法采用logitboost和Adaboost,实验证明集成学习算法较单一分类器有更好的分类效果,其中logitboost效果最好。
3.3 不同预处理的logitboost算法实验(以DecisionStump算法为基分类器)
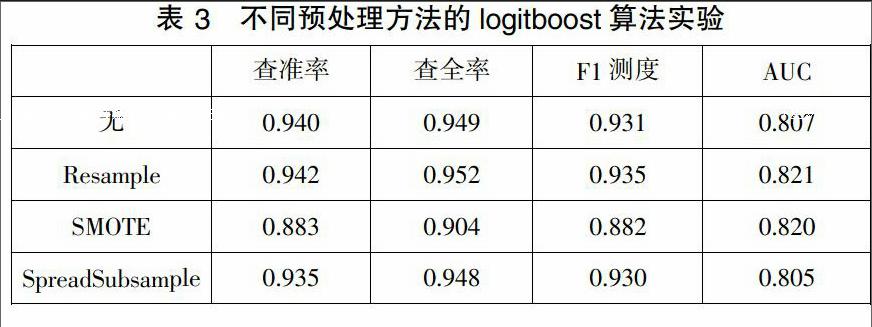
本实验通过对垃圾网页数据集选用不同的过滤器进行预处理,发现resample过滤器进行预处理后的数据集有更好的分类效果,其查准率、查全率、F1测度及AUC的结果都明显高于其他过滤器,因此采用resample作为数据集的预处理方法。
3.4 不同基分类器的logitboost算法实验(采用重取样的预处理方法)
本实验采用resample过滤器对垃圾网页数据集进行处理,在迭代次数为10的条件下,改变基分类器的种类,发现以REPTree为基分类器时logitboost分类器的查准率、查全率、F1测度及AUC的值都高于其他基分类器的值。
3.5 实验结论
本文通过实验发现在用resample过滤器对垃圾网页进行预处理的前提下,用REPTree作为基分类器的logitboost算法对于垃圾网页数据集的分类方面,查准率、查全率、F1测度及AUC均有得到了较为明显的提高,因而基于改进的logitboost算法对于垃圾网页数据集的检测有较好的精确度。
4 结束语
本文通过将集成学习logitboost进行改进,并将其应用于垃圾网页分类检测,说明了在使用有一定准确率和差异性的分类器作为基分类器的条件下,集成学习方法可以明显提高分类效果,下一步的工作是调整分类器的相关参数参数,观察参数的变化对分类效果的影响,找出分类效果更好的分类方法。由于集成学习算法的分类效果同基分类器的迭代次数有关,迭代次数不够时将会使数据不能得到充分的挖掘,造成分类效果较差,迭代次数太多会造成过度拟合现象,因而需要对logitboost的迭代次数进行分析,找出合适的迭代次数,提高分类器的分类效果。
【参考文献】
[1]邱齐辉.基于决策树和贝叶斯算法的垃圾网页检测的研究与实现[D].北京:北京工业大学,2012.
[2]贾志洋,李伟伟,高炜,夏幼明.基于支持向量机的搜索引擎垃圾网页研究[J].计算机应用与软件,2006,26(11):165-167.
[3]房晓南,张化祥,高爽.基于SMOTE和随机森林的web spam检测[J].山东大学学报:工学版,2012,43(1):24-27.
[4]周济,文志强,林海龙.集成学习有效性的研究[J].软件导刊,2014,13(6).
[5]张松,周亚建,刘念.数据挖掘基本算法比较[C]//.2010全国通信安全学术会议论文集.2010:326-332.
[6]Takafumi Kanamoria、 Takashi Takenouchi,Improving Logitboost with prior knowledge[J].Information Fusion 14 (2013):208-219.
[7]谢娜娜.基于不平衡数据集的文本分类算法研究[D].重庆:重庆大学,2013.
[8]周济,文志强,林海龙.集成学习有效性的研究[J].软件导刊,2014,13(6).
[责任编辑:刘展]
