基于多源数据的中文产科知识图谱构建
2023-01-09张坤丽胡晨馨昝红英赵悦淑储文艳
张坤丽,胡晨馨,2,宋 玉,昝红英,赵悦淑,3,储文艳
(1.郑州大学 信息工程学院 河南 郑州 450001;2.郑州中业科技股份有限公司 河南 郑州 450001;3.郑州大学第三附属医院 河南 郑州 450052;4.郑州大学 外国语与国际关系学院 河南 郑州 450001)
0 引言
随着万维网以及开放链接数据的发展,Google于2012年5月正式提出知识图谱的概念,为下一代智能搜索提供引擎服务[1]。知识图谱技术提供了一种从海量文本中抽取结构化知识的手段,并与大数据、深度学习技术相结合,成为推动人工智能发展的核心驱动力。随着医疗大数据时代的到来,医学知识互联也逐渐走入人们的视野,医学知识图谱是实现智慧医疗的基石,受到了越来越广泛的关注。
目前,国外的知识图谱如SNOMED CT[2-3]、IBM Watson Health[4]等均致力于构建一套全面统一的医学术语系统。国内也有不少学者对医学知识图谱的构建进行了探讨,有学者参照 UMLS 体系构建中文医学语言系统,如李丹亚等[5]所构建的中文一体化医学语言系统,主要应用于医学文本自动处理及医学文献信息检索;曾召等[6]所构建的中医药一体化语言系统,确立了中医药语言系统的语义网络体系和语义关系。此外,中文医学知识图谱CMeKG2.0版(http:∥cmekg.pcl.ac.cn)于2019年正式上线发布,该图谱建立了大规模、高质量的医学知识基础集,实现了疾病、症状、药物、诊疗技术之间广泛的知识关联,扩大了医学知识的覆盖面,提高了描述信息的丰富程度,并且提升了医学知识的标准化、规范化和国际化水平。
中国是世界人口第一大国,医疗卫生直接涉及人民群众的幸福安康,是重大的民生问题。随着多胎政策的落地,高龄产妇易发生妊娠并发症,不良妊娠的发生率也有所提高,给产科医疗机构带来了更大的挑战。此外,随着对产科医学的不断探索,临床积累了大量的与产科相关的医疗数据和信息资源,虽然现有的知识图谱也包含了一些产科知识,但是所涉及的产科疾病只占了一部分,不够全面和深入,并且资料来源广泛、结构迥异,很难被有效利用,需要采取有效的方法对这些知识进行组织和融合。针对上述问题,本文首先对多源语料进行分析,在专家的指导下提出了产科医学知识图谱描述体系,根据《妇产科学》、MeSH和ICD10中的产科疾病名称,抽取教材、指南及目录、网络资源等多来源文本中产科疾病的相关内容,采用半自动或自动的方式进行标注,然后进行人工检查,最后对多来源的异构数据进行整合、加工、更新等知识融合操作,构建了中文产科知识图谱(Chinese obstetric knowledge graph,COKG),网址为http:∥www5.zzu.edu.cn/nlp/info/1015/2147.htm。
1 COKG的构建流程
知识图谱的构建有自顶向下和自底向上两种模式[7]。COKG的构建借鉴了国内外丰富的疾病分类体系及其相关术语,采用先确立模式层再构建数据层的自顶向下的构建模式。
COKG的构建流程如图1所示。首先设计模式层,即制定相应的知识描述体系。根据国际标准医学术语集初步设计概念分类体系,通过案例的人工标注与分析来设计关系分类体系,随后经过医学专家的评估,形成知识图谱描述体系。以模式层为基础,获取多来源的产科相关知识,包括非结构化和半结构化文本,采用半自动或自动的方式对得到的实体关系进行标注。COKG以产科疾病为核心,用三元组形式对其所涉及的症状、治疗、检查、流行病学以及社会学等因素进行描述。同时,为了全面准确地描述知识,在三元组的基础上加入对每一元的约束或属性,将原本的三元组扩展为六元组。其中,e1为实体1,e1_pro为实体1的属性,rel为关系,rel_pro为关系的属性,e2为实体2,e2_pro为实体2的属性,形式为〈e1,r,e2〉三元组或〈e1,e1_pro,rel,rel_pro,e2,e2_pro〉六元组,以此构建出COKG的知识本体,并完成多源数据的知识融合。
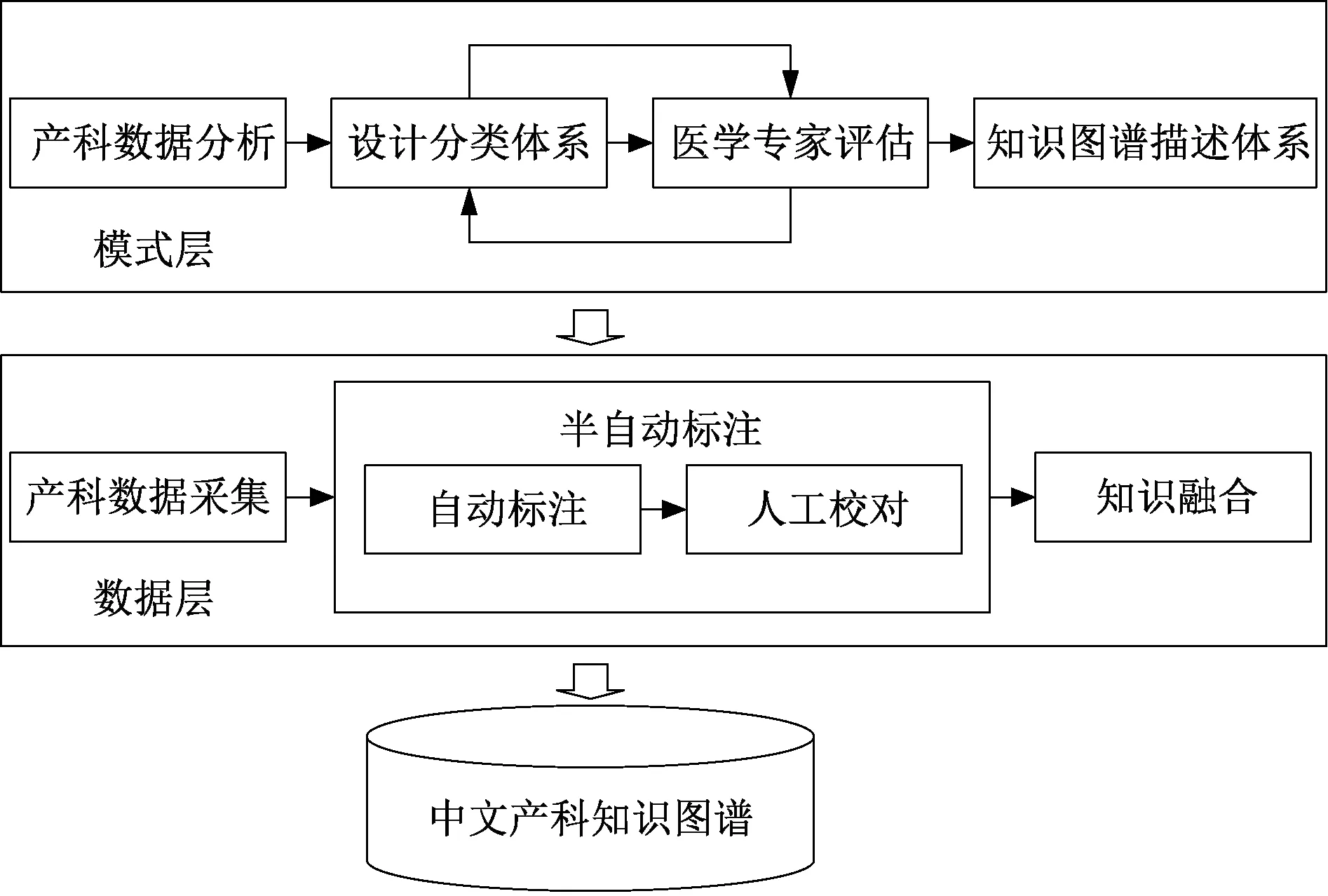
图1 COKG的构建流程Figure 1 The construction process of COKG
2 COKG模式层构建
本文构建的COKG以疾病作为描述主体,建立实体之间的层级关系及关联关系,形成包含概念分类体系和关系分类体系的知识描述体系。COKG中定义了疾病、部位、症状、药物、检查、手术治疗、其他治疗、流行病学、预后、社会学、同义词和其他共12类医学实体,对《妇产科学》以及临床路径中的产科疾病描述进行考察,将产科疾病类概念作为核心及入口,将自然语言处理属性(同义和编码)也考虑在内,与其他概念(包括疾病)之间可以形成11大类关系,按其所涉及的具体内容及关系,再细分为44 个子类。由于篇幅所限,表1仅展示了COKG中部分标注关系定义,其余子关系不再一一详述。其中关系“同义词”包含了疾病的英文名称、别称、简称、缩略语、俗语等,是对多源数据进行知识融合的重要依据;关系“疾病-检查”可细分为影像学检查、实验室检查、组织学检查、辅助检查及筛查等子关系。

表1 COKG部分标注关系定义Table 1 The partial label relationship definition of COKG
3 COKG数据层构建
COKG数据层构建主要包括产科知识采集、半自动标注及知识融合三部分。
3.1 产科知识采集
COKG以产科疾病为核心,抽取多来源文本中产科疾病的相关内容。产科数据来源如表2所示,其中“半”表示半结构化数据,“非”表示非结构化数据。对《妇产科学》、临床路径和临床实践文本中的实体及实体关系进行半自动标注,对丁香园用药助手和百度百科医学中的实体及实体关系进行自动抽取。
3.2 半自动标注
为了提升标注效率和保证标注的一致性,借助已开发的面向医疗文本的实体及关系标注平台[8],对语料中的实体及实体关系进行预标注,从而完成多来源医学知识文本的半自动标注任务,具体的人工标注流程如图2所示。
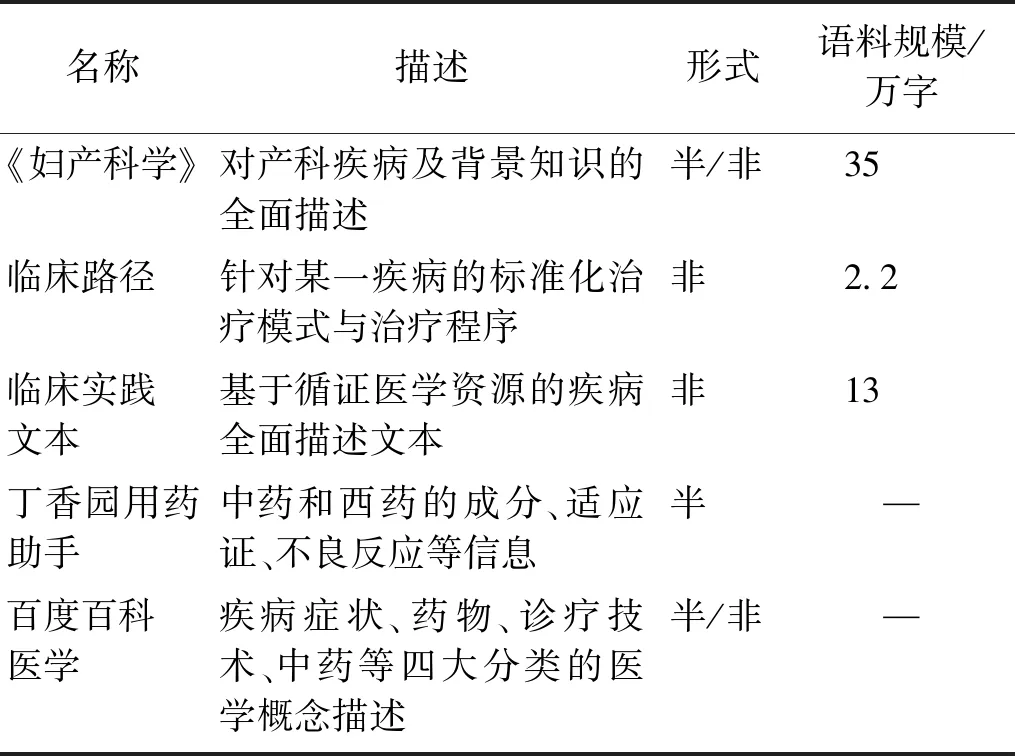
表2 产科数据来源Table 2 The source of obstetric data
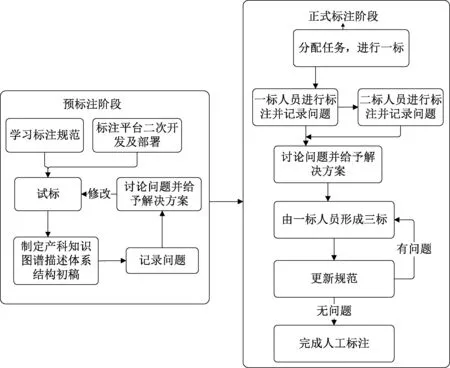
图2 人工标注流程Figure 2 The manual annotation flow chart
采用基于规则和机器学习的方法对丁香园用药助手及百度百科医学中半结构化和非结构化数据进行了实体识别及关系抽取,然后再次进行人工校对,将数据整合和去重处理之后得到的结构化三元组作为COKG数据层的补充。
3.2.1规则方法 首先,对半自动标注的语料进行归纳和总结,将常出现在同一关系之间的词语或者短语作为关系标记模式抽取出来,使其作为规则描述的一部分进行自动抽取。其次,在抽取时,对不同来源的文本进行分析,根据类别设计不同规则,从半结构化和结构化文本中进行实体抽取和关系抽取,所抽取的关系按知识描述体系进行相关关系的匹配。
丁香园用药助手按药品的成分、适应证、用药禁忌等属性进行描述,根据MeSH词表及已扩展的相关疾病概念,对适应证中包含产科疾病的药品,按规则可抽取出〈疾病,药物,药物治疗〉关系。例如,“烯丙雌醇片”的适应证为“先兆流产,习惯性流产,先兆早产”,则可抽取出〈先兆流产,烯丙雌醇片,药物治疗〉、〈习惯性流产,烯丙雌醇片,药物治疗〉和〈先兆早产,烯丙雌醇片,药物治疗〉的关系。
百度百科医学中对某一疾病的抽取可直接按内容抽取相应的实体,“又称,别称,英文别称,英文名称”这一类则统一归入“同义词”关系中。例如,可抽取出〈妊娠期肝内胆汁淤积,妊娠期胆汁淤积症,同义〉以及〈妊娠期肝内胆汁淤积,瘙痒,临床症状及体征〉等关系。
3.2.2机器学习方法 在机器学习方法中直接采用标注平台[8]所使用的 Bi-LSTM-CRF模型[9]进行实体识别,PCNN 模型[10]进行关系抽取,然后再进行人工校对。实验采用实体及子关系分类与COKG较为相似的基于常见病的人工标注临床实践文本为训练集,以半自动标注的教材及产科疾病相关临床实践文本为测试集,以五类频次较高的实体以及它们之间的关系为实验对象,实体识别实验数据集如表3所示。对应的实体关系实验数据集如表4所示,这五类关系的头实体都是疾病。这五类关系共包括 14 种子关系,后续的关系抽取将按14种子关系进行分类。

表3 实体识别实验数据集Table 3 The experimental data sets of entity recognition

表4 实体关系实验数据集Table 4 The experimental data sets of entity relationship
1) Bi-LSTM-CRF模型
Bi-LSTM-CRF模型是目前医学领域实体识别比较主流的深度学习模型,能有效提高模型的准确率,本文选择此模型进行实体识别。Bi-LSTM-CRF 实体识别模型如图3所示。该模型进行实体识别的参数中Dropout设置为 0.5;字向量及隐藏层维度为300;窗口大小为 7;学习速率为 0.001;Epoch为32。

图3 Bi-LSTM-CRF实体识别模型Figure 3 The entity recognition model of Bi-LSTM-CRF
对实体识别常采用严格和松弛这两类指标对结果进行评价,将自动识别的结果记为S={s1,s2,…,sm},金标准结果记为G={g1,g2,…,gn}。Bi-LSTM-CRF实体识别结果见表5,其中松弛指标值(F1r)为79.05%,严格指标值(F1s)为69.48%。由于医疗命名实体的形式呈现多样化,症状类实体较难识别,包括单独症状(如发烧)以及与身体部位联合的症状(如头痛),因此在五类实体中F1值最低。针对松弛指标的结果,虽然没有准确定位实体,但实体类别正确,且对实体的大致位置进行了标记,可经过实体规范处理等明确标记位置。
2) PCNN模型
PCNN 模型能够对实体前、实体间以及实体后的特征分布进行编码,有效地提高关系抽取的准确率。因此,COKG 构建中采用 PCNN 模型进行关系抽取。PCNN实体关系抽取模型如图4所示。在实体已确定的情况下,实体之间的关系抽取可认为是分类问题,PCNN 将传统 CNN 的最大池化方式修改为分段池化,输入由词向量和位置向量拼接而成。在池化层,将卷积层的输出分为实体e1之前的信息ci1,实体之间的信息ci2和实体e2之后的信息ci3,然后分别对这三部分进行最大池化操作,即pij=max(cij),其中1≤i≤n,i≤j≤3。将n个卷积滤波器的结果拼接,通过tanh函数得到 PCNN 层输出,并传输到Softmax层进行关系分类。

表5 Bi-LSTM-CRF实体识别结果Table 5 The entity recognition results of Bi-LSTM-CRF 单位:%

图4 PCNN实体关系抽取模型Figure 4 The entity relationship extraction model of PCNN
采用PCNN模型进行实体关系抽取实验,设置词向量维度为50,位置向量维度为5,Dropout 为0.33,PCNN实体关系抽取结果见表6。可以看出,F1值超过80%,无论是作为半自动标注的预标注以及从大规模的产科相关文本中进行关系抽取,都能够获取较为准确的三元组。在已抽取的实体及关系基础上辅以规则进行数据清洗及规范,可提高知识图谱构建效率。
3.3 知识融合
由于不同来源中同一实体往往存在多种表达方法,因此需要对异构或冗余数据进行整合、消歧、加工、更新等知识融合工作。经过上述的实体识别和关系抽取之后,数据中仍然存在着一些噪音。实体前后无意义标点示例如表7所示。同时规则抽取具有一定的局限性,抽取的三元组关系会包含一些冗余及冲突信息。实体同义关系示例如表8所示,会出现不受控领域实体的字符串表述多样但含义相似,如“False preterm labor”和“假早产”等。因此,对自动抽取的三元组,按类别比例10%抽样进行人工校对,将发现的问题分为不同类别,对这些抽取得到的产科描述标注元组进行异构数据的整合、消歧、加工、更新等知识融合工作,融合前后对比如表9所示。本研究对人工标注元组(5 790条)、自动标注元组(9 459条)进行分析,规范化处理了359条实体;利用受控实体中同义关系元组聚类同义实体辅以人工校对,构建标准名别称元组列表841条;对外部资源如症状库[11]、药品库[12],人工发现本体映射关系,转换其表达格式扩充标注元组得到约20 000条,规范药品名后元组去重得到7 505条。经知识融合后,COKG的产科描述标注元组知识质量得到了明显的提高。
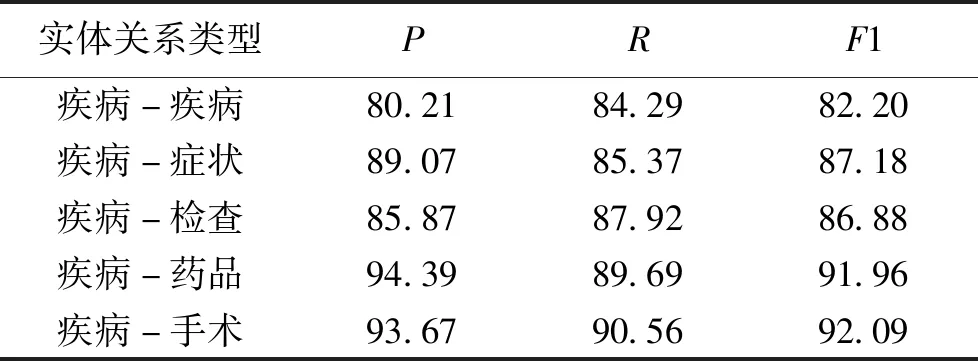
表6 PCNN实体关系抽取结果Table 6 The entity relation extraction results of PCNN 单位:%

表7 实体前后无意义标点示例Table 7 The example of meaningless punctuation before and after entity

表8 实体同义关系示例Table 8 The entity synonymy relations list
4 构建结果及展示
标注一致性用来描述两份标注结果的一致程度,一般用Kappa值[13]和F值[14]来表示(具体数据略)。有2名医学专家和近20名标注人员参与标注工作,共计完成标注200余万字。标注实体数量如图5所示,其中人工抽取4 888种,自动抽取5 786种,总共10 674种实体概念。标注实体关系数量如图6所示,包含15 249个实体关系三元组,其中半自动抽取5 790种,自动抽取9 459种。
为了直观地反映COKG中概念之间的关系,设计了知识图谱可视化展示平台(http:∥121.196.167.126:8088/)。COKG展示界面如图7所示。展示平台按疾病首字母进行排序,同时设置了搜索框方便用户查询,并以疾病为中心放射性链接与其相关的各类实体。

表9 知识融合前后对比Table 9 The comparison before and after knowledge fusion
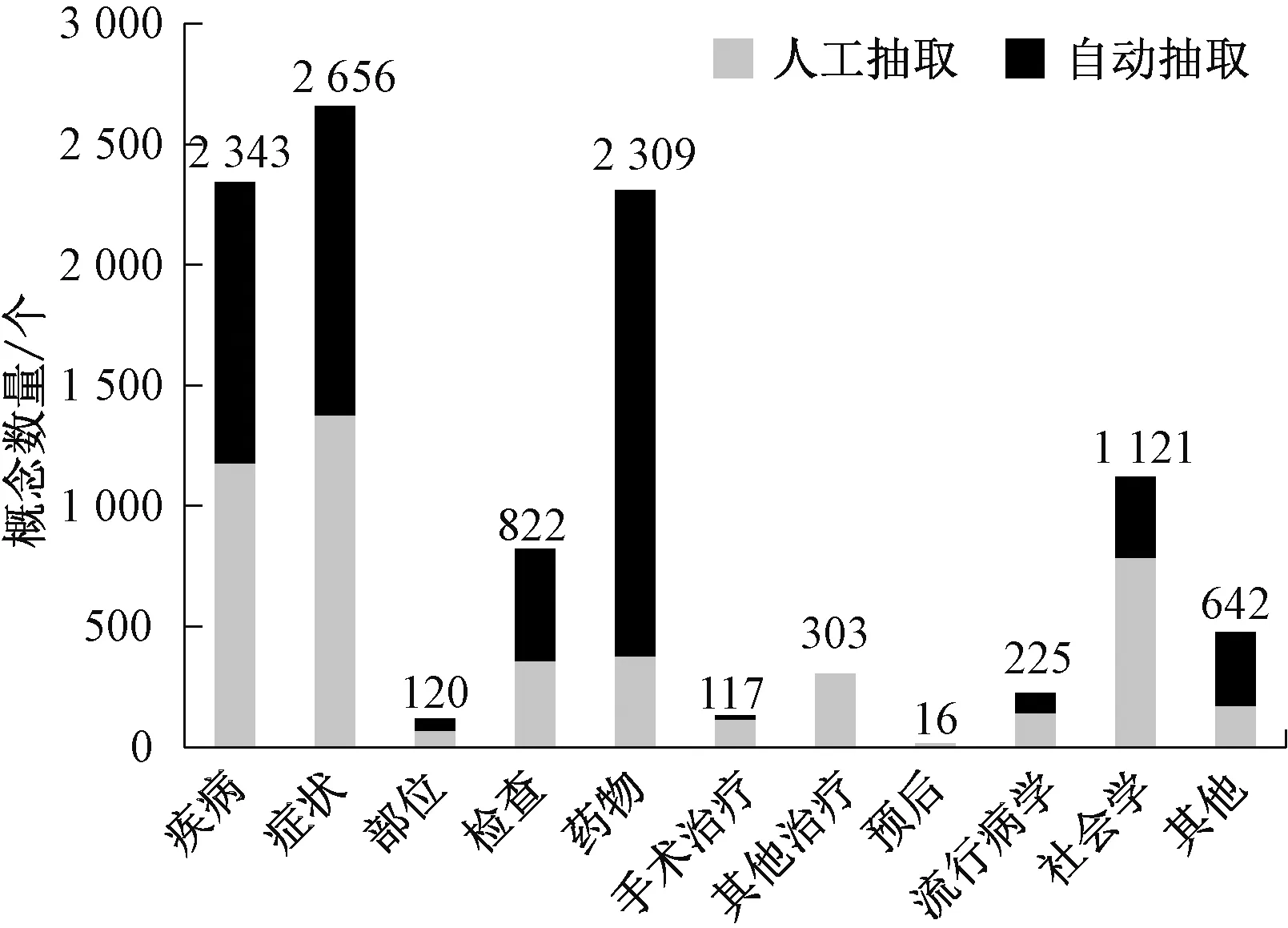
图5 标注实体数量Figure 5 The number of the annotated entity

图6 标注实体关系数量Figure 6 The number of the annotated entity relation
5 小结
本文在COKG模式层的构建中首先整合了多来源的医疗文本,然后在专业人员的指导下设计了知识图谱描述体系;在数据层使用基于规则和机器学习的方法抽取了实体及其关系,构建了医学知识图谱的知识本体;在知识融合部分,对这些人工和自动标注的三元组进行分析,然后人工检查并归纳数据异常的情况,最后完成多源数据的知识融合。未来的研究工作将在完善COKG和扩展数据来源的同时,借鉴与利用已有经验知识,继续研发基于产科知识图谱的辅助诊断、临床决策支持系统等医学领域的应用。目前构建的COKG在处理大规模数据时还存在一定的局限性,下一步将尝试利用半监督的知识融合方法对大规模知识进行筛选,进一步扩大COKG所涵盖产科疾病的广度和深度。
