基于多视图和注意力推荐网络的三维物体识别方法
2023-01-09张满囤权子洋师子奇
张满囤,权子洋,师子奇,刘 川,申 冲,吴 清,田 琪
(河北工业大学 人工智能与数据科学学院 天津 300130)
0 引言
三维物体识别是计算机视觉和图像学的基本问题,具有广阔的应用前景。近几年大数据和深度学习算法发展快速,越来越多的科学研究者开始采用深度卷积神经网络自动获取三维特征进行物体分类识别研究[1-3]。根据输入形式,上述方法可以分为基于多视图的方法、基于点云的方法[4]和基于体素的方法[5]。基于多视图的方法从三维物体的一组二维投影视图中学习特征描述符,通过二维神经网络进行分类识别。基于点云的方法采用三维空间坐标下的无序点作为输入,通过三维神经网络进行分类。基于体素的方法是对三维物体进行体素化处理,应用于更复杂的网络提取特征进行分类。本文针对物体在多角度的二维视图信息来进行分类识别研究,即基于多视图的物体识别方法。
基于多视图的三维物体识别过程的主要环节一般有三个:视图预处理、特征提取和分类识别,其中的特征提取是物体识别的关键,受到国内外学术界的广泛关注。Su等[6]首次提出并行的多视图卷积神经网络(multi-view convolutional neural networks,MVCNN),通过并行的CNN1来提取基于多个视图的特征,然后这些信息在视图池化层被汇集起来,并通过CNN2获得一个紧凑的物体特征描述符。Fu等[7]提出一个包含注意力推荐网络(attention-proposal-network,APN)的模型,对物体图像中关键区域定位再放大输入到下一层网络中,在三个细粒度识别分类任务中取得了最佳效果。
在本文中,提出一个基于MVCNN的改进算法模型,旨在提升算法的识别精度,减少识别运行时间。主要贡献如下:1) 在卷积层引入APN注意力模块,实现定位、聚焦关键特征区域;2) 在提取特征时的池化操作中使用最大池化和平均池化,避免只取最大值时忽略其他关键信息;3) 在某些情况下,物体图像会存在光强变化、遮挡等问题,使用SRC分类器代替softmax分类器,可有效提高物体识别的抗干扰性。
1 相关工作
近年来,卷积神经网络(convolutional neural networks,CNN)被广泛用于三维物体识别任务中。在基于点云结构的物体识别任务上,Charles等[8]针对三维点云数据提出网络名为PointNet的结构,该网络的输入数据为一系列无序的点云数据,通过对称性的函数实现网络最大池化操作,之后通过优化函数学习,进行相应识别操作,平均的识别精确度约为86.2%。但是,PointNet没有利用点云的局部结构来捕获全局特征。KC-Net[9]是一种克服PointNet局限性的网络,提出了用于提取相邻点之间局部特征的最近邻图和在图结构上的最大池化层。边缘条件卷积网络(ECC)[10]是为了图结构数据而设计的,使用图结构构建点云并应用卷积网络处理图形结构化数据。基于体素的算法和基于点云的算法具有相似的处理流程,其中非结构化和不确定的有序点云在初始阶段被转换成一系列规则的体素,3D ShapeNets[11]在ModelNet上的准确率约为84%。基于3DshapeNets,VoxNet[12]采用的是点云数据,但是将点云数据转换为体素格式,输入卷积神经网络中处理。Sedaghat等[13]通过使用面向对象的概念改进了VoxNet的架构,修改后的体系结构的名称是ORION,不仅预测对象的类标签,还对物体的方向进行了评估,该网络在训练期间也学习对象的方向信息,在测试时可以获得更好的分类结果。
基于多视图的物体识别任务中,除MVCNN[6]模型外,Feng等[14]设计了一个组视图卷积神经网络(group-view CNN,GVCNN)框架,用于分层关联建模,以实现对三维形状的区分描述。Gao等[15]设计了用于三维物体识别的成对多组视图的网络(pairwise multi-view CNN,PMV-CNN),将自动特征提取和目标识别结合在一个统一的CNN体系结构中。通过利用每个视图的元素最大化操作挖掘高响应值特征映射,提高两个对象的对比度,因此提取的特征非常适合三维物体识别,其性能远远优于手工特征。Jiang等[16]设计了一种分层多环视图神经网络框架(multi-loop-view CNN,MLVCNN),并对来自长短期记忆中所有隐藏层的输出应用最大池,以获得回路级描述符。虽然最大池操作可以轻松融合多视图特征,但它会导致视觉信息的丢失。Sun等[17]设计一种使用重排和仿射变换转换特征,自适应地选择特征的动态路由网络(dynamic routing CNN,DRCNN),经过重排、仿射变换、改进的动态路由算法和合并操作形成表示三维物体的新特征。
2 网络框架
本文以深度学习算法Att-MVCNN(attention multi-view CNN,Att-MVCNN)为物体特征提取的基本方法,提出的基于Att-MVCNN的三维物体识别流程图如图1所示。
整个三维物体识别的过程包括两部分,分别是神经网络学习和待测样本识别,使用前期训练好的卷积神经网络进行物体特征提取,然后利用基于I2范数的稀疏分类。主要步骤如下:1) 利用训练好的神经网络提取训练数据集x的物体视图特征,构建特征空间的训练集字典D;2) 使用卷积神经网络提取测试数据集y的深度学习特征Y;3) 使用SRC算法对Y用D稀疏表示,求解稀疏系数a;4) 计算最小残差,进行残差分类,最终输出分类结果。

图1 本文算法框图Figure 1 The proposed algorithm
2.1 注意力推荐网络(APN)
基于区域注意的APN[18-19],计算思想是给定一个输入图像A,首先通过将图像输入预先训练的卷积层来提取基于区域的深层特征,记为Wc*A,表示卷积、池化和激活的一组操作,Wc表示整体参数。将网络在每个尺度上建模为具有两个输出的多任务公式。第一个任务被设计为在细粒度类别上生成概率分布p,
p(A)=f(Wc*A),
其中:f(·)表示全连接层,将卷积特征映射到可以与类别项匹配的特征向量,并包含softmax层,将特征向量进一步转换为概率。第二个任务是为下一个更精细的尺度预测一个参与区域的一组框坐标。将参与区域近似为一个有三个参数的正方形,表示为
[tx,ty,tl]=g(Wc*A),
其中:tx、ty分别表示x轴和y轴下的正方形s中心坐标;tl表示正方形s边长的一半;g(·)的具体形式可以表示为两层堆叠的全连通层,有三种输出,即参与区域的参数。
为了保证该算法在训练中得到优化,采用一种二维boxcar函数的变体作为注意力掩膜来近似裁剪操作,该掩膜可以选择传播方向上最显著的区域,将受关注区域的左上角(tl)和右下角(br)的点参数化,
基于上述表示,裁剪操作可以通过粗尺度的原始图像和注意掩膜之间的元素相乘来实现。
Xatt=X*M(tx,ty,tl),
其中:*表示元素间乘法;M(·)表示注意力掩膜;Xatt表示剪裁区域。
2.2 卷积神经网络
本文的卷积神经网络框架主要包括特征提取部分、视图池化部分、特征融合部分和分类输出部分。在本网络模型中输入层的数据是经过归一化预处理大小为224×224的图像。本文卷积神经网络结构如图2所示,图2(a)为多视图输入的网络大框架,图2(b)为单一视图CNN卷积内部的具体网络图。算法的具体流程是:在卷积层中,所有神经元共享同一卷积核信息,第一个网络五层卷积后的输出作为APN模块的输入,APN模块的输出作为下一层的输入,两个相同卷积的输出经过特征融合层和全连接层处理后的特征图被赋予不同的权值,将具有不同权值的特征两两连接,将经过并行CNN网络提取的多个视图特征在视图池化层聚集成一个紧凑的特征描述符,经过最终的特征融合层、全连接层处理,用SRC分类器实现物体的识别。

图2 网络框图Figure 2 The network diagram
特征提取部分使用一组并行的卷积神经网络,考虑算法在保持较高识别准确率的前提下也要有尽可能快的执行速度,通过对不同规格的网络结构实验对比,使用VGG作为该部分的基网络,并进行改进。图3(a)为第一层卷积效果图,(b)为第五层卷积后效果图。

图3 基于VGG网络模型卷积过后的特征图Figure 3 Feature map after convolution based on VGG network model
视图池化部分均采用了最大池化和平均池化相结合的方式,通过池化操作可以降低特征图尺寸、减少网络运算复杂度和数据维度,加快网络学习速度。最大池化具有平移不变性,可以提取物体图像局部特征信息,之后再组合成全局信息,但是在某特征细节的处理上会丢失有用的特征信息。平均池化往往会对物体视图的每个特征赋予相同的权重,这样会使信息量少的视图覆盖信息量多的视图,因此将最大池化和平均池化结合,既可以保留物体轮廓特征的完整性,又可以更精确地处理特征细节,更加准确地提取物体特征信息。本文所采用的均值+最大池化的公式定义为
其中:Vm表示输入图像所对应特征图在池化窗口中的特征值;m为该特征点在池化窗口中的位置。池化就是把vm转变为相应的统计数值。
特征融合部分位于卷积池化层和全连接层之间,得到多张视图的全局和局部特征后,通过特征融合层更好地融合两部分信息。初步提取的物体特征经过处理形成特征向量,通过线性激活函数(ReLU)对其赋予不同的权重,再由一个全连接层整合,最终送入分类器。具体的计算公式为
f(x)=max(0,Relu(x))。
2.3 SRC分类器
分类识别部分采用SRC分类器[20-24]。SRC的工作过程是:设三维物体识别系统中有k类训练数据,每一类中有nk个数据样本,每个训练样本特征d都使用m维的列向量表示,则第k类的训练数据用矩阵形式表示为
Dk=[dk,1,dk,2,…,dk,nk]∈Rm×nk,
其中:dk,nk表示为第k类训练数据中的第nk个样本特征。属于同一类的测试数据特征用同类训练数据的特征线性组合,记为Y=[D1,D2,…,Dk]=[d1,1,d1,2,…,dk,1,…,dk,nk],即Y=Da,a为稀疏系数。求解最优的稀疏系数
对于第k类物体图像样本,定义相对应类别的稀疏系数δk(a),其中a只保留对应的第k类的系数,其余类别系数全置为0,计算测试样本与各类的训练数据样本线性加权差值ri(Y),找到使ri(Y)最小时对应的类i,从而得出测试样本的类别识别结果,
minri(Y)=‖Y-Dδk(a)‖2。
3 实验部分
3.1 实验平台
本文进行的实验采用Windows10的64位操作系统,使用Python3.6、MATLAB R2014a集成开发环境完成程序的开发与运行,并且配置Opencv2.4.13环境。实验所用主机的内存为8.0 GB,CPU处理器为i5-3230双核处理器,主频为3.2 GHz,另外为更高效地处理物体视图数据,使用显存为4 G的NVIDIA GTX1050的显卡。深度学习框架使用Pytorch。
3.2 实验数据集
本文实验使用的是三维物体识别领域的ETH数据集和ModelNet10数据集,其中ETH数据集包含8类80个物体共计3 280个数据样本,而ModelNet10数据集包含10类共计4 899个三维模型数据。实验在两个数据集内分别随机取70%的数据作为训练集,余下30%的数据作为测试集。
3.3 实验损失函数
本文中使用的是PyTorch中常用的CrossEntropyLoss损失函数,计算公式为
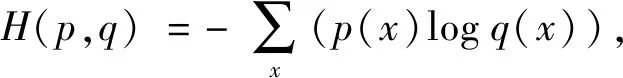
其中:p和q为两个概率分布。
3.4 评价准则
受试者工作特征曲线(receiver operating characteristic curve,ROC),是一种评价算法模型优劣的评价准则,ROC曲线图最靠近左上方的位置,识别分类效果最好。
在ROC曲线图中横坐标表示负正类率(false postive rate,FPR),纵坐标表示真正类率(true postive rate,TPR),计算为:
3.5 实验结果与分析
3.5.1注意力模块有效性对比实验 由混淆矩阵可知错误的分类主要是由于某些物体具有相似的空间特征结构,如在ETH数据集中的dog模型和horse模型在某些角度下的物体视图存在一定的相似性,还有在ModelNet10中的desk和table也存在一定的相似性,这些情况的出现与人眼视觉表现出的错误分类情况类似。
图4和图5分别展示了ETH图像集和ModelNet10数据集整体识别结果,可以看出MVCNN网络中加入注意力机制有效地增强了物体的关键特征信息,从而提高了物体识别的准确率。
3.5.2两个数据集的识别率实验 在两个数据集上,将本文算法与经典的基于体素的3D ShapeNets算法、基于点云的PointNet算法、基于单一视图的CNN算法和一系列基于多视图MVCNN结构的其他五种算法比较。将这五种算法提取的特征,使用SRC分类器对数据集图像识别分类,实验结果如表1所示。
由表2可知,由于3D ShapeNets和PointNet两种算法是在三维体素和点云形式上的算法,而本文训练使用的ETH数据集没有三维体素和点云格式文件,所以在表2中的准确率一栏中用横线代替。3D ShapeNets方法使用的三维网格形式特征在提取和表示时匹配准确率不高,而PointNet算法获取物体的三维点云特征在提取和表示时效果不错,但是三维数据占用内存大,网络运行效率次于在多视图形式下的运行效率。在ModelNet10数据集上的测试结果,基于多视图形式的深度卷积神经网络的识别分类准确率要优于基于体素和点云形式的深度卷积神经网络,其中加入注意力模块的Att-MVCNN方法最优。在ModelNet10数据集上识别率略低一些的原因可归纳为该数据集上存在两种形状较为相似的物体,如写字桌和台桌。

图4 ETH图像集的识别准确率Figure 4 ETH imageset of recognition rate
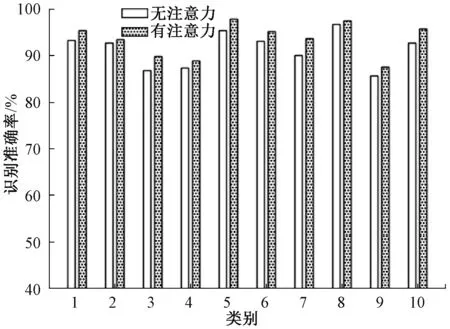
图5 ModelNet10数据集的识别准确率Figure 5 ModelNet10 dataset of recognition rate
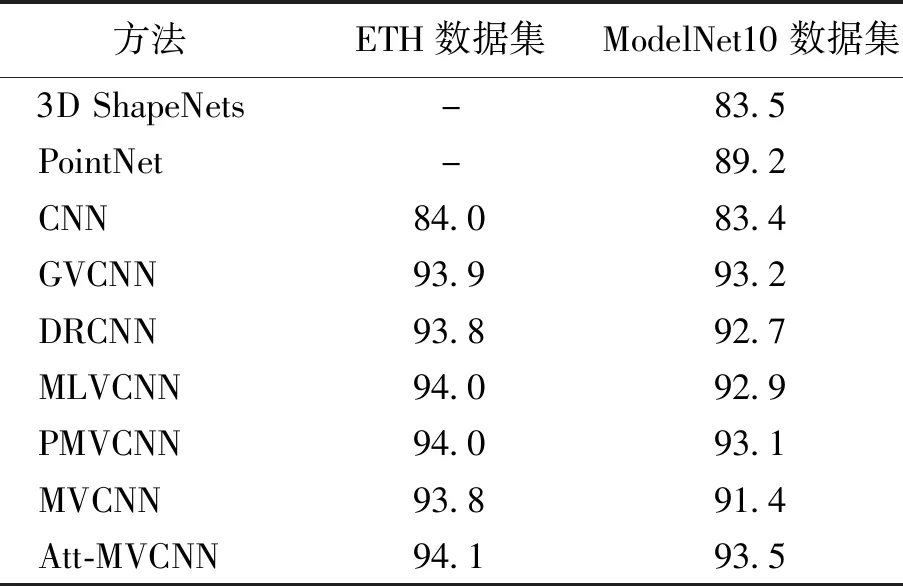
表1 基于不同特征提取网络的识别准确率比较Table 1 Comparison of recognition performance based on different feature extraction networks 单位:%
实验过程中把用于测试的样本集中的不同视角的图像组合成正样本对(同类样本)与负样本对(非同类样本)序列,采用上述不同算法计算样本对之间的距离,通过固定负样本对的FPR,选择对应的距离阈值后用同样的阈值检测出正样本对的接受率,拟合绘制ROC曲线图。
ROC曲线图中越靠近ROC空间的左上角的点,其分类效果越好。由图6可以看出,Att-MVCNN算法位于ROC曲线图中最靠近左上方的位置,表示在FPR一定的情况下,该算法中TPR最高。在TPR一定的情况下,FPR的值最小。表明该方法是优于其他方法的。

图6 9种不同物体识别算法的ROC图Figure 6 ROC diagram of 9 different object recognition algorithms
3.5.3性能指标 不同的学习率会影响权值调整,学习率过小会使算法收敛速度缓慢,学习率过大会使梯度在最小值周围震荡无法收敛,本实验使用梯度下降法对权重调整。通过设定消融实验,本阶段设置学习率为0.000 05。图7为本文算法在训练和测试阶段的损失函数趋势图。

图7 在本文算法中的损失值曲线图Figure 7 The loss value curve in this algorithm
图7表明算法在迭代计算30次过程中损失函数值呈下降趋势,符合预期设想。曲线值越接近0,算法在计算中产生的损失越少,相应阶段识别精度越高。
3.5.4不同分类器在三维物体图像上的分类性能 为了衡量不同分类器对网络提取特征的最终识别准确率的影响,使用KNN、SVM、softmax和SRC四种不同的分类器对最终得到的特征向量进行训练和分类识别,各分类器的准确率分别为80.86%、86.37%、93.95%和94.11%。因此,当SRC为分类器时识别准确率最高。
4 结论
本文提出的基于改进多视图卷积神经网络和稀疏表示分类器算法相结合的三维物体识别算法,利用深度学习训练三维物体视图的网络模型,并且提取物体图像特征信息,通过构建稀疏字典,最后使用稀疏表示分类算法计算的稀疏系数和残差结果进行物体识别。该方法避免了传统人工方法提取物体特征信息时的局限性,结合使用了深度卷积神经网络自动学习特征和SRC分类的优势,又在其中加入APN模块,使网络学习更关键区域的特征。在ETH和ModelNet10两个数据集上进行验证,结果表明本文所提出的算法具有较高的识别准确率。在今后的研究中,将进一步改进算法,以便应用于更多领域。
