融合三支决策与交互特征选择的点击率预估模型研究
2022-10-15赵旭栋续欣莹
赵旭栋,谢 珺,续欣莹
1(太原理工大学 信息与计算机学院,山西 晋中 030600)
2(太原理工大学 电气与动力工程学院,太原 030000)
E-mail:xiejun@tyut.edu.cn
1 引 言
在推荐系统和在线广告中,确定某一用户对指定商品或者广告的点击概率是一项重要的任务,它决定了推荐系统的准确性和在线广告的收入.在推荐系统的Top-N推荐中,用户对某个商品的点击率是一个重要的排序依据,这个点击概率决定了商品在推荐列表中的位置,系统偏向把点击率较大的商品放置在推荐列表中的前列,以提升个性化推荐的准确性.在线广告中,广告曝光千次的点击率是广告提供者衡量某个广告位的一项重要指标,广告商往往会根据千次点击率对平台的广告位置进行估值,拥有较高的曝光千次点击率的广告位能够获得更多的利润.因此,点击率(Click-Through Rate,CTR)预估任务在推荐系统和在线广告中扮演着至关重要的角色.
CTR预估利用用户信息、广告或商品信息以及上下文信息来训练模型.在现有的深度学习CTR预估模型中,为了提升模型的准确性,会利用原始特征之间的向量积来学习异构信息,这些异构信息又叫交互特征或者组合特征.例如,二阶组合特征“女性化妆品品牌”蕴含着女性和某一化妆品牌的关系,这种交互特征可以反映用户兴趣,对模型表现至关重要.另外,特征交互可以给模型带来非线性的特征信息,这些非线性的特征信息与原始特征相融合可以极大的提升经典的线性回归算法如逻辑斯蒂回归[1](Logistic Regression, LR)等模型的预估效果.
在现有的CTR预估模型与算法中,为了提升模型特征交互的能力,降低人力成本,往往会利用模型结构自动进行特征交互[2].因子分解机(Factorization Machine, FM)[3,4]将高维的稀疏特征映射到低维,并且通过低维特征向量之间的内积来进行特征交互;域因子分解机(Field-aware Factorization Machines, FFM)[5],在FM特征交互的基础上加入的特征域交互概念,进一步提升了特征交互的深度;梯度下降树(Gradient Boost Decision Tree, GBDT)[6,7]利用树结构来筛选交互特征,并通过LR来产生最后的预估结果;这些都是经典的机器学习点击率预估算法.深度学习进一步提升了点击率预估模型的交互能力.深度学习点击率预估算法将深度神经网络(Deep Neural Network, DNN)发掘隐式交互特征的能力和传统机器学习方法学习显式交互特征的能力相结合[8,9],进一步提升了模型的预估效果.一些基于FM产生的深度学习算法如DeepFM(Deep Factorization Machines)[10]以及xDeepFM (eXtreme Deep Factorization Machine)[11]等都是结合了深度学习的优势,通过神经网络隐式的特征交互提升了模型的表现.另外, PNN(Product-based Neural Network)[12]、DCN(Deep & Cross Neural Network)和DSPN(Deep & Product supported stacking Network)[13]等都是在深度学习的基础上利用不同的向量积形式引入交互特征,得到了更好的预估效果.
然而,并非所有的特征交互都是有益的,学习所有的交互特征可能会引入冗余信息,冗余信息会给模型带来噪声并且增加了模型训练的难度.如果能够在现有的因子分解机及其衍生的点击率预估模型的基础上加入交互特征选择机制,那么原有模型就可以移除冗余的噪声信息,进一步提升特征交互的质量,从而提升模型的预估效果.本文受到三支决策思想的启发,针对因子分解机及其衍生的点击率预估模型产生的冗余交互特征,提出了一种融合三支决策与交互特征选择的点击率预估模型TIFS(Three-way Decision & Interactive Feature Selection models).TIFS提出了一种融合Logistic判别分析与三支决策的交互特征选择函数来筛选交互特征.不同于Logistic的二支决策,融合三支决策的交互特征选择函数不仅能够去除冗余的交互特征,而且能够利用延迟决策机制决策保留一般重要的交互特征,强化重要的交互特征.通过融合TIFS模型之后,FM,FFM,DeepFM以及xDeepFM等模型就可以去除冗余的交互特征,原有模型可以在更低的计算成本下获得更好的表现.在3个公开的数据集上进行大量的实验验证表明TIFS可以提升原有模型的表现.
本文主要的贡献为:
1)通过实验证明在现有的点击率预估模型中,产生的冗余交互特征会影响模型的预估效果.
2)受到三支决策思想的启发,提出了TIFS模型.TIFS融合了基于三支决策构建的交互特征选择函数,可以去除冗余交互特征,提升模型训练效率,提升模型预估效果.结合因子分解机及其衍生模型,TIFS可以进一步提升原有模型的性能.
3)在3个公开数据集上进行了大量的实验验证,融合TIFS的因子分解机及其衍生模型有更优秀的预估效果.
2 相关工作
2.1 粗糙集和三支决策介绍
经典的Pawlak粗糙集[14]是一种处理不确定性和不精确性问题的数学工具,它使用上下近似集来描述一个概念.假设U是一个有限的非空子集,R∈U×U是定义在U上的等价关系,记apr=(U,R)为近似空间,那么U在等价关系R下的划分就可以记为U/R={[x]r|x∈U},[x]R是包含x的等价类.∀X⊆U,上下近似集定义如公式(1)、公式(2)所示:
aprR(X)={x∈U|[x]R⊆X}
(1)
aprR(X)={x∈U|[x]R⊆X≠∅}
(2)
根据上述定义,整个论域U可以被分为互不相交的正域POS(X)、负域NEG(X)和边界域BND(X)3部分,如公式(3)~公式(5)所示:
POS(X)=aprR(X)
(3)
NEG(X)=U-aprR(X)
(4)
BND(X)=aprR(X)-aprR(X)
(5)
正域中的元素x在等价关系R下确定属于X,负域中的元素x在等价关系R下确定不属于X,边界域导出的规则可能属于X.公式(6)给出分类的边界概率:
(6)
其中|·|表示集合中元素的基数,Pr(X|[x]R)表示分类的条件概率.通过这个条件概率,就有了判别某一类是否属于某个域的分类依据.在引入阈值α,β后,∀X⊆U,0≤β<α≤1,则(α,β)-正域、(α,β)-边界域及(α,β)-负域如公式(7)~公式(9)所示:
POS(α,β)(X)={x∈U|Pr(X)|[x]R≥a}
(7)
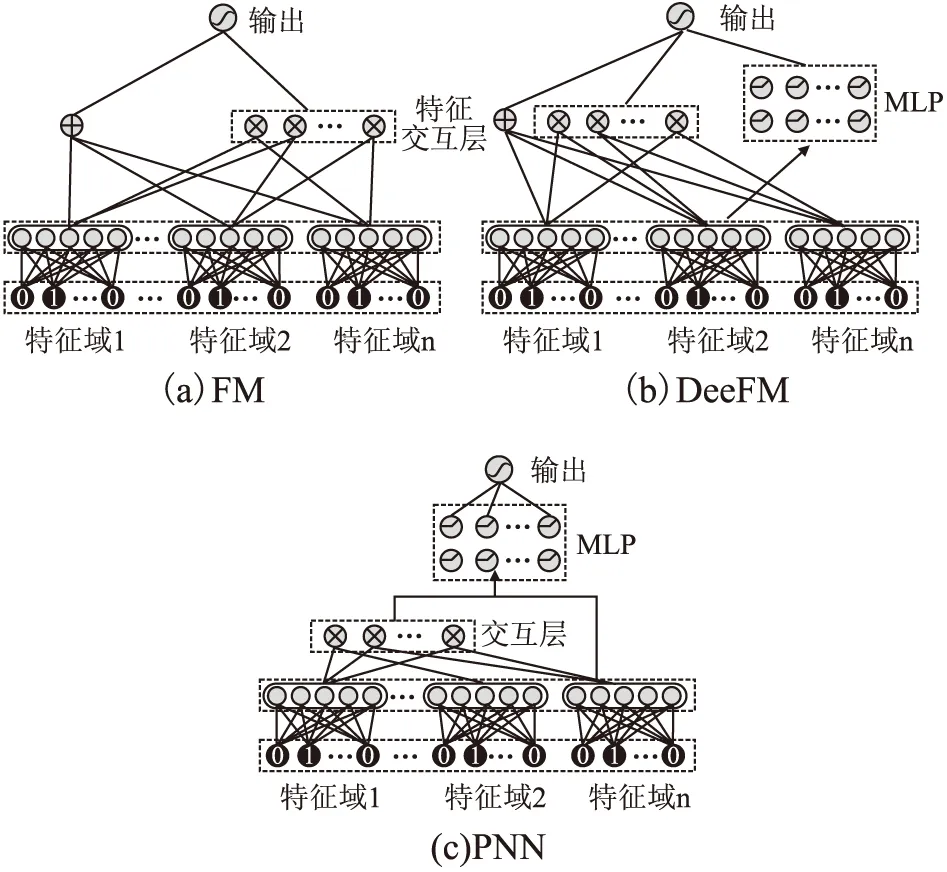
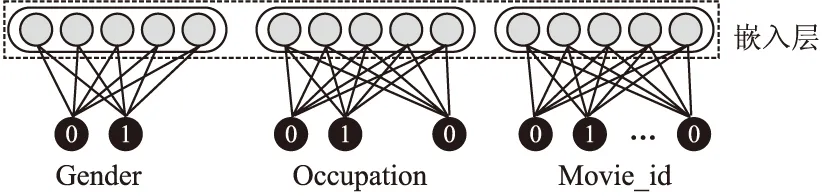
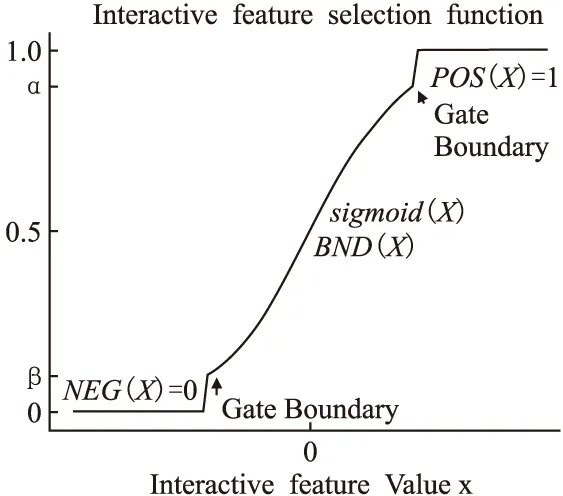
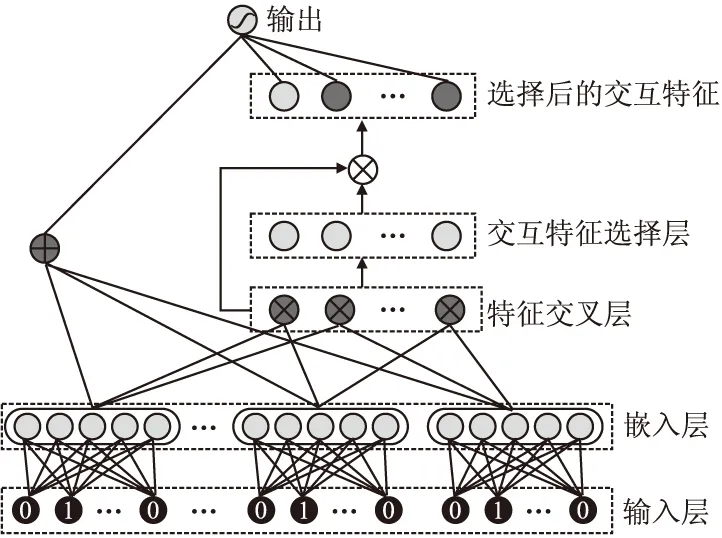
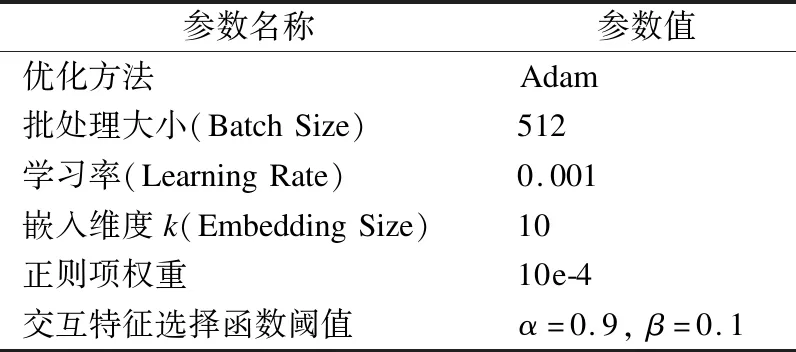
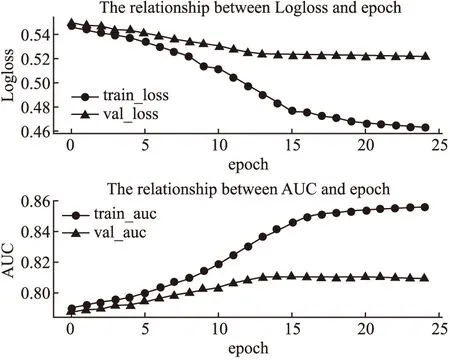
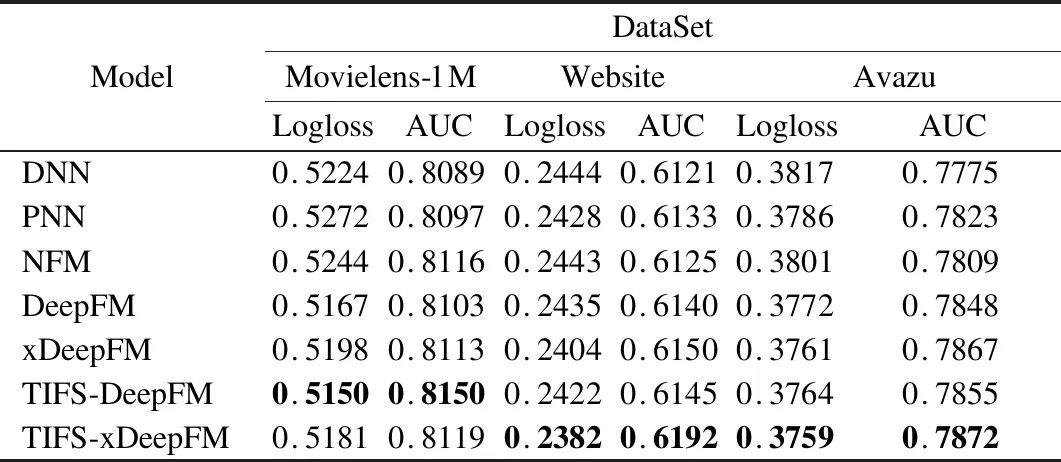
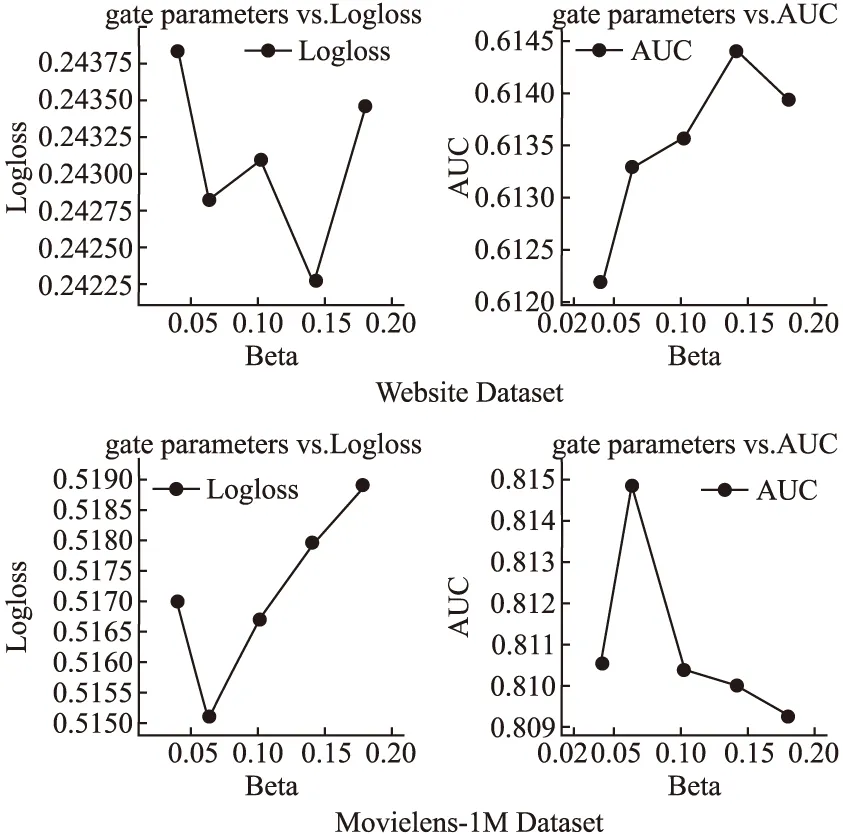
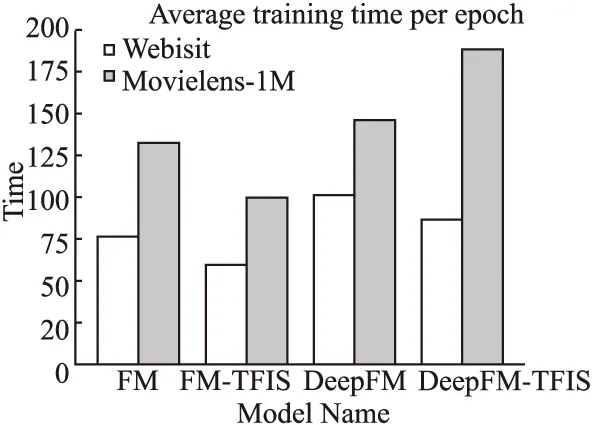
BND(α,β)(X)={x∈U|β (8) NEG(α,β)(X)={x∈U|Pr(X|[x]R)≤β} (9) 当α=1,β=0时,模型就是Pawlak经典粗糙集模型.(α,β)阈值将论域分为了3个可通过条件概率量化的区间[15],即接受域(正域),拒绝域(负域)和延迟决策域(边界域). 在传统的Bayes决策中,决策的行为只有正域和负域两种,即必须对论域中的对象进行划分,这是二分类的基本思路.但在三支决策的理论中,决策的行为不仅包含正域和负域,还可分出一种边界域,给出了一种待定决策的行为.相比于Bayes决策的过于严格和理想化的分类,三支决策更加有现实意义.例如,在确诊一个病人是否感染冠状病毒引起的肺炎过程中,医生若只有核酸检测阴性的证明,往往不会立即确诊,而是继续观察病情进一步观察患者的情况之后再公布病人的确诊信息.这种中间决策的行为在数据信息稀疏条件下比传统的Bayes二分类决策风险更低.因此在推荐系统和在线广告这种稀疏特征的场景下,三支决策相比传统的二支决策更有优势. 特征交互可以提升模型的预估效果,已有的CTR预估模型十分注重对模型特征交互的研究.Rendle提出的FM解决了稀疏数据环境下的特征交互问题.FM将高维稀疏交互特征的权重映射为一个固定的低维向量,极大的减少了学习交互特征的复杂度.基于FM衍生了许多模型[16],例如FFM在FM的基础上加入了特征域交互;DeepFM将DNN与FM算法并行结合,将深度学习学习隐式交互特征的能力与FM学习显式交互特征的能力相结合,进一步提升了模型的表现;注意力因子分解机(Attention Factorization machine,AFM)[17]引入注意力机制,为不同的交互特征分配了注意力权重,注意力权重能够区分交互特征重要度,提升特征交互的质量.神经因子分解机 (Neural Factorization machine,NFM)[18]将FM与DNN串联,使用深度神经网络代替了FM中的二阶特征交互部分,解决了FM中高阶特征组合爆炸的问题;xDeepFM(eXtreme Deep Factorization Machine)将特征交互从比特级提升至向量级,提出了压缩交互网络 (Compressed Interaction Network,CIN)网络来实现显式的特征交互.除因子分解机及其衍生模型之外,还有一些其他学习交互特征的方法,例如PNN[19]在DNN前选择了内积、外积两种方式来得到交互特征;DCN(Deep & Cross Network)则是将DeepFM中的FM侧进一步替换为交叉网络 (Cross Network,CN)来学习交互特征,这是一种比特级的特征交互;DSPN(Deep & Product supported Stacking Network)则保留了PNN学习交互特征的方法,在另一侧并行加入DNN进一步提升了模型的表现.一些融合多模态特征信息进行特征交互的工作也取得了不错的预估效果.利用知识图谱融合模型结构进行特征组合的方法也取得了巨大进步,进一步提升了模型的表达能力. 图1给出了FM、DeepFM和PNN的结构,这3种模型结构同时拥有输入层、特征交互层和输出层.可以发现已有模型都缺少对交互特征选择的研究,忽视了交互特征的质量.华为在最近的研究AutoFIS(Automatic Feature Interaction Selection)[20]中注意到了这一点,利用特殊的目标函数实现交互特征选择;腾讯在模型GateNet(Gating-Enhanced Deep Network)[21]的嵌入层中加入门机制来筛选特征,但对于交互特征的选择仍缺乏研究.以上研究都给TIFS模型的产生提供了重要的理论依据. 图1 FM、DeepFM和PNN结构图Fig.1 Architectures of FM, DeepFM and PNN 本节主要介绍了因子分解机进行特征交互的基础模型和融合三支决策思想产生的交互特征选择函数,最后介绍了融合交互特征选择函数的TIFS模型. 在研究交互特征选择之前,首先要对目前的基于FM产生交互特征的模型进行介绍,本小节介绍了CTR预估模型产生特征向量的一般方法,并且介绍因子分解机及其构造特征交互的形式. 3.1.1 特征嵌入层 在机器学习中,对于分类特征一般会采用One-Hot编码来产生特征向量.由于数据的稀疏性以及深度学习复杂庞大的参数,深度学习CTR预估模型一般采用Embedding思想将高维的稀疏特征映射为一个固定维度的低维稠密向量[22].例如,某数据集中有着这样一个输入例子[Gender=男,Occupation=律师,Movie_id=4],这代表着观看某一电影观众的用户信息,那么经过One-Hot编码可以得到稀疏向量: 由于类别过多,对于movie_id特征使用One-Hot编码会导致特征向量中0值过多,造成较大的稀疏性.在CTR预估任务中,一般用一个可以训练的矩阵来将稀疏特征映射为低维稠密向量.图2给出了针对上述例子的嵌入示例.嵌入层的输出为E=[e1,e2,…,ei,ef],其中f指的是特征域的数量,ei∈k代表特征域中某一类特征,k代表着嵌入特征的维度. 图2 嵌入层示例图Fig.2 Architecture of embedding layer 3.1.2 特征交互层 在现有CTR预估模型中,进行特征交互是提升模型表现的常用的方式.通过嵌入得到稠密的特征向量ei,一般采用内积的方式来表示交互特征.在图1所示的PNN交互层中,采用特征域内两两内积的方式来产生交互特征,如公式(10)所示: [ (10) 其中<·,·>指两个向量的内积, (11) 3.1.3 多层感知器 多层感知器(Muti-Layer Perceptron,MLP)是学习特征之间隐式关系和联系的一种重要的方法.MLP在点击率预估任务中也扮演着重要的角色,图1中PNN和DeepFM都用到了MLP.特征间的显式交互方法和MLP方法通过不同的形式来提升模型的整体表现.MLP是一种前馈神经网络,主要通过公式(12)迭代传播: a(l)=relu(W(l)a(l-1)+b(l)) (12) 其中a(l)是第l层神经网络的输出,W(l),a(l-1)和b(l)分别为第l层神经网络的权重参数矩阵,输入和偏置.激活函数为通常为Relu函数.在CTR预估任务中,输入为嵌入层的输出向量即a(0)=[e1,e2,…,ef],经过MLP之后得到的输出为ah,ah∈Mh,Mh为神经网络输出层h层的神经元数量. 本小节基于二元Logistic回归和三支决策思想提出了交互特征选择函数,简要介绍了交互特征选择函数选择交互特征的过程.交互特征选择函数可以在CTR预估模型训练中筛选交互特征. 假设任意一个交互特征为x= (13) 即: (14) 通过公式(14),可以生成下面的判别准则,即: (15) 公式(15)是基于Logistic的一般判别结果,Pr(d=1|x)即为Logistic回归中的Sigmoid函数.在三支决策的语义中,利用2个状态集和3个行动集来描述过程,不同于上述判别准则,粗糙集将3个行动状态表示为接受域POS(X),拒绝域NEG(X)和延迟决策域BND(X),对应于保留交互特征(d=1),去除交互特征(d=0)和决定特征是否去除3个部分.基于上述描述的三支决策判别规则可表示为公式(16): (16) 其中α,β为相应的阈值,且α+β=1. 通过公式(16),可以将交互特征选择分为3部分,再将阈值0≤β<α≤1确定为超参数之后,可以依据得三支决策判别规则得到交互特征选择函数,如公式(17)所示: (17) 公式(17)给出经过三支决策之后的分段函数.在确定阈值后,当x∈POS(X)时,保留特征交互x;x∈BND(X)时,由Sigmoid函数来决定特征交互x的权重;当x∈NEG(X)时,去除交互特征x.由此,成功利用三支决策和Logistic判别分析完成了交互特征的选择过程.图3给出了交互特征选择函数的结构. 图3 交互特征选择函数Fig.3 Interactive feature selection function 通过图3结合公式(17),可以观察到交互特征选择函数为分段函数,加入了两个阈值参数α,β,利用三支决策将Sigmoid函数分为3个区间,函数为线性复杂度,计算代价较低. 3.3.1 模型介绍 基于公式(11)和交互特征选择函数,可以给出融合FM和交互特征选择函数一般形式,如图4所示.在特征交叉层产生的交互特征x通过交互特征选择函数之后便可以得到选择之后的特征,即: (18) 图4 TIFS-FM模型图Fig.4 Model diagram of TIFS-FM 对比图1可以发现,相较于原有的FM,TIFS-FM模型增加了交互特征选择层.交互特征选择层利用交互特征选择函数将交互特征的权重分为3个部分.对应不同的3种权重,TIFS-FM可以保留重要交互特征,决策保留一般交互特征,去除冗余交互特征.TIFS-FM的交互特征选择层提升了交互特征的质量,输出层利用经过选择的交互特征和原始特征进行预测,减少了冗余特征给模型带来的负面影响.经过选择之后的交互特征表达能力更强,进一步提升了模型的表达能力. 在选择交互特征之后,TIFS-FM预估模型的最终输出结果为: (19) 其中LLinear= CTR预估任务是一个二分类问题,对于二分类问题通常使用交叉熵损失函数来训练模型,如公式(20)所示: (20) 3.3.2 算法复杂度分析 本节首先介绍了实验使用的3个公开数据集,然后介绍了实验的参数设置和评价指标,最后本节从TIFS选择交互特征的有效性、融合TIFS的因子分解机及其衍生模型的整体表现、TIFS-FM超参数实验以及模型训练时间对比等4个维度进行了实验验证与结果分析. 为了评估TIFS的有效性,本节通过3个公开数据集对模型进行训练和验证,这3个数据集都可以通过公共渠道获取,数据集的基本信息为: ·MovieLens-1M(1)https://grouplens.org/datasets/movielens/:MovieLens-1M数据集是推荐系统中常用的数据集,其中共有100万条用户和电影信息的评分数据.为了使用Movielens-1M完成 CTR预估的任务,将评分少于4分的样本转换为负样本,将其余部分作为正样本.最后将它随机分为两部分:80%用于训练,20%用于测试. ·Aavazu(2)https://www.kaggle.com/c/avazu-ctr-prediction: Avazu是Kaggle平台上的一个点击率预测竞赛数据集,包含了4000万个数据实例的点击日志.它来源于实际的在线广告平台.将Avazu的4000万条数据随机排列:80%为训练集,20%为测试集. ·Website(3)https://www.kaggle.com/arashnic/ctr-in-advertisement/:Website是Kaggle平台上一个网站收集的真实数据集,它收集了不同用户在某软件平台的点击行为,包含了46万条实例.在本次实验中,将Website的46万条数据随机排列:90%为训练集,10%为测试集. 3种数据集统计信息如表1所示. 表1 3种数据集统计信息Table 1 Basic statistics of the three datasets 本次实验采用AUC(ROC曲线下的面积)和Logloss作为模型评价指标.AUC对与正例样本的比例不敏感,最大值为1,越高越好.Logloss又称为交叉熵损失函数,它衡量模型预测值和实际值之间差距,Logloss的值越小代表模型的精度越高. AUC提高1‰或者Logloss降低1‰对于CTR预估任务来说十分重要,这在已有研究中也有指出.本节实验选择以下模型作为对比的基线模型: FM:因子分解机模型是CTR预估任务中应用最广最经典的模型,它将稀疏特征映射为低维稠密向量,利用内积的方式产生二阶交互特征,是理想的基线对比模型. FFM:是因子分解机的一个衍生模型,它在FM交互特征的基础上加入了特征域之间的交互. NFM:利用神经网络强大的拟合性来拟合FM中的特征交互,有效的避免了特征的组合爆炸问题. PNN:在输入DNN网络之前利用内积或者外积的方法学习交互特征. DeepFM:将深度神经网络隐式的特征交互与FM显式的特征交互相结合,是深度学习CTR预估模型中的经典的基准模型. xDeepFM:通过CIN网络将比特级的特征交互在向量级实现,进一步提升了模型表现. 考虑实验的公平性,所有基线模型均设置了相同的参数,如表2所示. 表2 参数设置Table 2 Parameter settings 本小节通过大量的实验来验证TIFS的有效性.实验主要分为4个部分,第1部分验证了TIFS是否能有效的选择交互特征以及经过选择之后模型是否有更好的表现;第2部分主要将TIFS-DeepFM,TIFS-xDeepFM与DNN,PNN以及DeepFM,xDeepFM模型进行对比;第3部分对TIFS中的阈值超参数进行了分析;第4部分实验是针对TIFS选择特征交互后模型的效率进行对比与分析. 4.3.1 TIFS交互特征选择有效性验证 本小节基于Movielens-1M和Website数据集进行实验,选择了机器学习模型FM和FFM.表3给出了实验数据,其中Ratio代表交互特征占原有模型两两交互特征的比例,|Δ|代表绝对值之差,FM和FFM未经过任何交互特征选择过程,所以它们的交互特征比例均为100%,TIFS-FM和TIFS-FFM经过了交互特征选择.通过实验可以发现. 表3 TIFS交互特征选择验证Table 3 TIFS interactive feature selection verification 1)如图5所示,TIFS-FM在Movielens-1M数据集上有着良好的收敛性,随着训练轮次的上升,LogLoss逐渐降低,AUC值逐渐升高,并且趋于稳定. 图5 TIFS-FM在Movielens-1M上的训练过程Fig.5 Training process of TIFS-FM on Movielens-1M dataset 2)TIFS-FM和TIFS-FFM在经过特征选择函数之后,能够去除冗余交互特征.在Movielens-1M数据集上,TIFS-FM和TIFS-FFM分别可剔除58%和34%的无用交互特征,在Website数据集上,TIFS-FM和TIFS-FFM分别可以剔除49%和43%的交互特征,冗余特征去除的比例相当可观,并且提升了模型的预估效果.由此,验证了TIFS选择交互特征的有效性. 3)在Movilens-1M和Website数据集上,经过TIFS选择交互特征之后,TIFS-FM和TIFS-FFM在Logloss和AUC指标上均有提升.这表明过多的交互特征给模型带来了负担和噪声,进行一定的交互特征选择是十分必要的. 4.3.2 模型表现对比 本节将TIFS应用于深度学习模型,进一步提升了模型的预估效果.融合了交互特征选择函数的TIFS-DeepFM和TIFS-xDeepFM的表现超越了原有模型和基线模型.模型对比实验在Movilens-1M,Website以及Avazu 3个数据集上进行.为了进一步验证模型的有效性,除去原有的DeepFM和xDeepFM,进一步增加了PNN,NFM作为基线对比模型.表4给出不同模型之间的对比结果.通过实验,进一步验证了,融入交互特征选择层的因子分解机深度学习模型表现更优,交互特征选择函数能够进一步提升模型的表现.通过实验结果可以发现以下几点: 表4 不同模型对比结果Table 4 Comparison results of different models 1)由于CTR预估任务中数据的稀疏性(即在数据集中正样本率较低),产生点击行为的样本数较少,导致模型学习参数的有效样本较少,通过实验结果可以发现各个模型在AUC和Logloss两个指标的差距较小.但在实际的在线广告领域,1‰的差距也意味着巨大的进步. 2)在3个数据集上,进行特征交互的模型表现更优于未进行特征交互的DNN模型.这表明特征交互能够提升模型的表现,在原有特征的基础上加入一定的异构交互特征是十分必要的. 3)在3个数据集上,TIFS-DeepFM和TIFS-xDeepFM表现最优,相较于DeepFM,xDeepFM在Logloss和AUC指标上均有提升.在Movielens-1M数据集上,TIFS-DeepFM的表现最优,在两个评价指标上均优于对比模型;在Avazu和Website数据集上TIFS-xDeepFM表现最优.这表明,经过TIFS选择交互特征之后,原有模型的预估效果可以进一步提升. 4.3.3 阈值超参数实验 本小节主要研究了TIFS中的阈值超参数对模型的影响.本实验在Movielens-1M和Website数据集上进行验证,采用TIFS-DeepFM模型作为基线模型,负域阈值β作为超参数,选择0.02,0.05,0.1,0.15,0.2几个参数值进行实验.通过图6可以观察到: 图6 阈值超参数验证结果Fig.6 Threshold hyperparameter verification results 1)Movielens-1M数据集上β=0.05时,模型达到最优值,Website数据集上β=0.15左右时模型达到最优值.这表明阈值是影响模型表现的一个重要的超参数,在实际的实验中要针对不同规模的数据和异构信息来选择合适的阈值. 2)负域阈值β本质上代表保留重要交互特征和去除冗余交互特征的比率.实验结果表明,经过一定的阈值之后,模型的表现不升反降,这从侧面印证了过多的去除交互特征会影响模型的表达力,找到适合的临界阈值十分重要,这也符合三支决策理论的基本原则. 4.3.4 模型效率对照 本小节主要在Movielens-1M和Website数据集上对FM,TIFS-FM, DeepFM, TIFS-DeepFM的拟合训练时间进行对比,如图7所示.通过实验可以发现: 图7 模型训练时间对比结果Fig.7 Model training time comparison results 1)在Movielens-1M和Website数据集上TIFS-FM及TIFS-DeepFM的训练时间均有着明显的下降.这表明交互特征选择函数能够有针对性的对冗余的交互特征进行选择,通过函数本身的机制抑制了交互特征权重的梯度传递,去除的冗余特征数F较多,降低了模型的训练时间. 2)在CTR预估任务中,数据量和特征数量都十分庞大.实验结果表明,TIFS-FM和TIFS-DeepFM融合交互特征选择函数牺牲线性的计算代价释放了大量的计算资源,模型的训练时间大幅优于原有模型,进一步验证了融合三支决策和交互特征选择点击率模型的优越性能. 本文提出了融合三支决策和交互特征选择的点击率预估模型.通过实验验证,融合三支决策和交互特征选择之后的点击率预估模型有着更优秀的表现.论文针对点击率预估中冗余的交互特征带来的负面影响,主要贡献包括:1)通过实验证明过多的交互特征给模型带来了负担;2)提出了融合三支决策的交互特征选择函数对冗余交互特征进行筛选,提升了模型的表现.通过实验验证,本文提出的融合三支决策和交互特征选择的点击率预估模型可以有效的筛选交互特征,并且在效率和预估效果上均有提升.今后的工作将考虑融合知识图谱和图神经网络来提升特征交互的质量,进一步提升点击率预估的效果.2.2 基于特征交互的点击率预估模型介绍
3 融合三支决策与交互特征选择的点击率模型
3.1 基础模型

3.2 交互特征选择函数
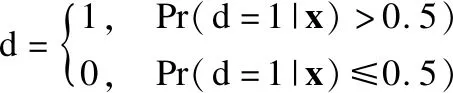
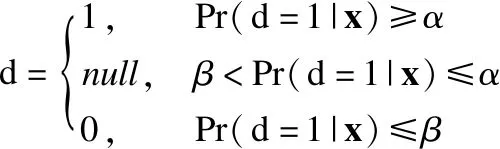
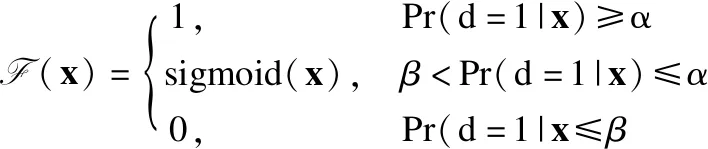
3.3 融合TIFS的TIFS-FM模型
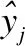
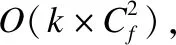
4 实验过程和结果分析
4.1 数据集介绍

4.2 实验评价指标和基线模型
4.3 实验过程和结果分析

5 结束语
