面向多GPU架构电流预测模型研究
2022-10-15赵德玉陈庆奎
赵德玉,陈庆奎,2
1(上海理工大学 管理学院,上海 200093)
2(上海理工大学 光电信息与计算机工程学院,上海 200093)
E-mail:chenqingkui@usst.edu.cn
1 引 言
随着计算机技术的飞速发展,图形处理器(Graphics Processing Unit(GPU))因其优越的并行计算能力在虚拟现实[1]、自动驾驶[2]、山洪监测[3]、大数据[4]、人工智能[5]、物联网[6]等领域得到广泛应用.目前,全球超算500强系统中有125套系统采用NVIDIA GPU作为并行加速器(1)https://www.top500.org/lists/top500/2020/11/.大规模数据的持续计算中会产生大量计算和冷却冗余能耗[7,8],因此GPU绿色节能计算成为当前研究热点.研究GPU通用计算的能耗复杂性是优化节能的基础工作,对探索程序的能耗瓶颈和优化系统设计都有重要意义.
获取GPU功耗数据是分析GPU能耗复杂性的前提.现有功耗预测方法将功耗数据作为研究对象,通过采集功耗数据建立功耗预测模型.现有方法存在以下问题:1)难以确定计算功耗变化中的相变规律;2)功耗预测模型针对特定GPU,通用性差.
针对已有预测模型存在的问题,本文提出以GPU通用计算程序的运行电流为研究对象,并采用Elman神经网络构建了一个面向多GPU架构的GPU运行电流预测模型.
图1为BlackScholes,Reduction,Bfs 3个应用程序在NVIDIA Geforce GTX 970上运行时利用实验室自行设计的电流实时监测系统提取到的GPU运行电流折线图.从图中可以看到,应用程序运行结束后,GPU电流不会立刻降到待机电流,而是经过一段时间后才降到待机状态.当一个应用程序执行结束,GPU执行队列中有新的计算任务,若该计算任务所需运行电流与刚执行结束的程序运行电流相近,则GPU就不会有运行电流幅值的剧烈变化,反之,则会有幅值的剧烈变化.因此,本文建立基于程序特征的电流预测模型,并利用预测模型实时评估程序的运行电流,为通过减小电流幅值的变化优化功耗和任务调度提供基础数据依据,协助开发者充分挖掘GPU计算的能耗瓶颈.
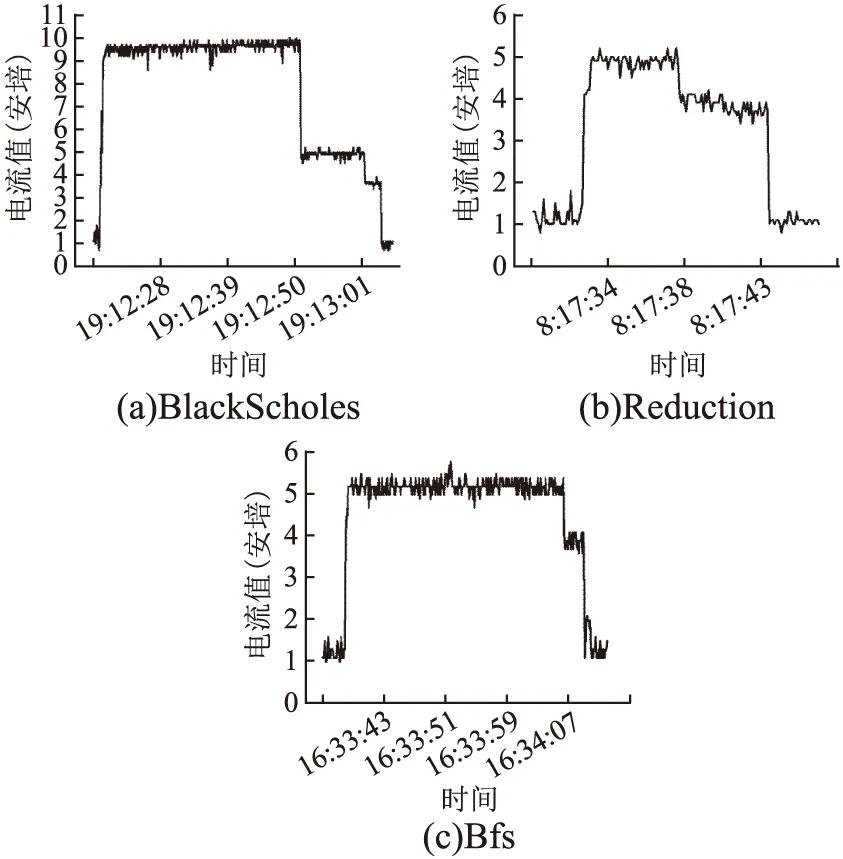
图1 NVIDIA GTX 970 GPU运行电流变化图Fig.1 GPU running current of NVIDA GTX 970
本文主要工作如下:
1)提出以GPU程序运行电流作为研究对象.电流属于细粒度研究对象,电流幅度的剧烈变化直接影响硬件的可用性和可靠性;电流受周围环境尤其是GPU温度的影响小,收集的电流数据可靠性更高.GPU芯片温度的提升,对功耗有比较明显的影响,而实验测试表明,GPU芯片温度提升对电流变化尤其是峰值电流的影响则较小,因此采集的电流数据更加准确.
2)建立了面向多GPU架构的GPU程序运行电流预测模型.为解决电流预测模型的通用性问题,本文引入了体系结构复杂度参数,结合从GPU源程序中提取的3个程序特征,采用Elman神经网络构建了程序特征、体系结构特征与运行电流的关系模型.实验结果表明,所建模型精确度较高,通用性较好.
2 相关工作
Hong等[9,10]面向NVIDIA Tesla GPU开发了一个功率和性能模型.通过分析PTX代码,得出指令和内存访问的数量,并根据这些信息建立模型.这种离线PTX分析方法对于预测GPU的功率和性能非常有用.该研究的缺陷是面向特定的GTX 280 GPU.
王卓薇等[11]在深入研究Fermi GPU架构的基础上,提出一种高精度的体系结构级功耗模型,该模型首先计算不同native指令及每次访问存储器消耗的功耗;然后根据应用在硬件上的执行指令和采样工具获得采样结果,分析预测其功耗;最后通过13个基准测试应用对实际测试与功耗模型测试结果进行对比分析.
王吉军等[12]提出了一种基于硬件性能计数事件的GPU功耗预测模型.通过分析在NVIDIA Tesla K20Xm GPU上运行GPU程序时的功率分布情况,选择了12个与程序运行功率有关的性能事件,使用反向传播人工神经网络分析硬件性能计数事件与实时功耗间的关系,建立了GPGPU功耗预测模型.
王海峰等[13]分别针对稀疏分支和密集分支程序提出了基于程序切片的GPU应用功耗模型.采用非线性回归和小波神经网络预测GPU功耗.以NVIDIA GeForce GTX260、GTX280和GTX480作为测试对象.结果表明,小波神经网络模型比非线性回归模型具有更好的通用性.
赵奇等[14]提出了一种面向程序设计的PTX指令级能耗预测模型,使程序员能够预测程序能耗.与以前需要硬件性能计数器或体系结构仿真的模型不同,该模型依赖于CUDA程序的PTX指令.在实证研究的基础上选取PTX指令,应用线性回归方法建立了GPU能量模型.结果表明,该模型具有较高的预测精度,平均预测误差在3.7%以下.
以上文献中提出的模型局限于单架构GPU,研究对象是功耗或能耗.本文提出的模型是面向多个GPU架构的,通用性更强.
Ade等[15]提出一种面向GPU系统功耗和性能预测的通用方法.该文首先描述了GPU工作电压和频率缩放对性能和功耗的影响,然后提出了功耗和性能预测的统计模型.实验结果显示该统计模型的预测误差在20%~30%之间.该研究存在问题主要有两个:1)采集的训练数据是整个系统的功耗,而不是GPU的功耗,因此数据准确性较差;2)随着技术发展,GPU体系结构越来越复杂,线性关系不足以用来描述程序特征与功耗或者性能之间的关系,因此基于统计的方法预测误差较大.
3 研究背景
3.1 GPU架构
现有GPU体系结构众多,如NVIDIA公司现存GPU就有Tesla、Fermi、Kepler、Maxwell、Pascal和Turing 6大类架构(2)https://www.nvidia.cn/page/products.html#Architectures.每类架构在处理器数量,组织模式、内存工作频率等方面有很大不同.为测试所提出模型的可靠性和通用性,本文选择了当下较为流行的NVIDIA公司的3种显卡(Geforce GTX 670、680和970)进行了实验数据的收集.其中GTX670和GTX680属于Kepler架构,GTX970属于Maxwell架构.Kepler架构和 Maxwell架构在流式多处理器(SM)设计上有很大不同.Kepler架构每个SM有192个单精度CUDA核,所有核共用指令缓存、寄存器,一级缓存与共享内存共用64KB;而Maxwell架构每个SM包含4个独立处理块,每个处理块包含32个CUDA核,并具有独立的指令缓冲区、warp调度器和寄存器,一级缓存则与纹理高速缓存功能相结合,共享内存是一个独立的单元,被4个块共享(3)https://developer.nvidia.com/cuda-zone.表1列出实验采用GPU的核心参数.
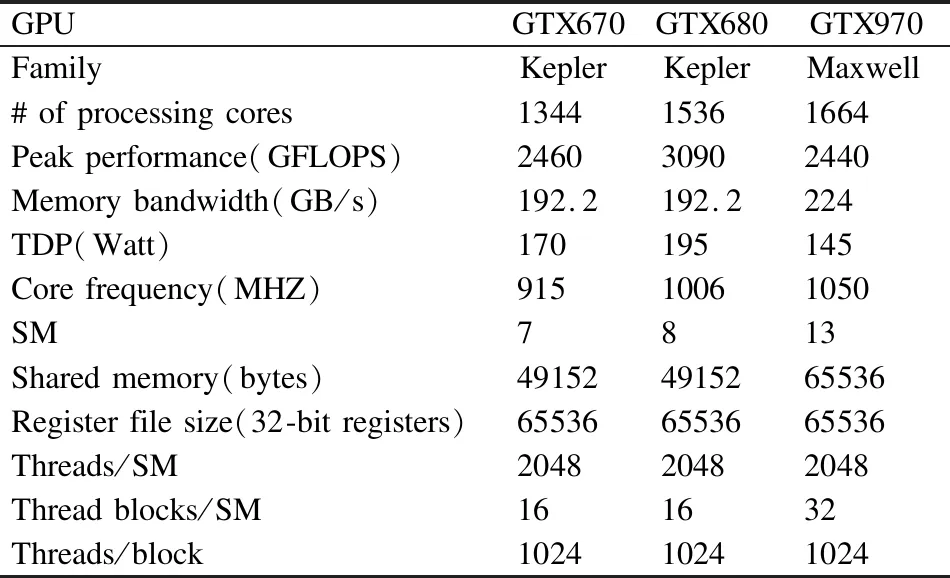
表1 GPU硬件配置参数Table 1 GPU parameters
3.2 应用程序集
所选应用程序应全面、真实地反映GPU资源的使用情况;应选择多种类型的应用程序;所选应用应具有实际应用价值.基于以上原则,从CUDA SDK(4)https://docs.nvidia.com/cuda/cuda-samples/index.html#new-features-in-cuda-toolkit-7-5和SHOC[16]两个应用程序集中选取了包括宽度优先搜索算法(Bfs)、单精度或双精度浮点数数组规约(Reduction)、并行前缀求和(Scan)等在内的31个应用程序.表2列出了所选取的应用程序.所有程序所用CUDA版本是CUDA7.5,在Windows 7操作系统下,利用Visual Studio 2010编译运行.

表2 应用程序Table 2 Application program
4 CUDA程序特征筛选与提取
4.1 CUDA程序形式化描述
从源代码层次分析一个CUDA程序,可知CUDA程序中最核心的函数是核函数,一个CUDA程序通常包含多个核函数,可描述为:P={K1,K2,…,kn}.每个核函数可看作多条语句的集合,既K={S1,S2,…,Sn},语句包含顺序语句、选择语句、循环语句、控制语句等类型,通过执行语句,完成相应的计算、存储访问等操作.
4.2 程序特征描述
在工作电压保持不变的前提下,GPU在静态待机状态时,运行电流基本是稳定的(如GTX970,静态电流在0.8A~1A之间);在运行状态下,工作电流随着计算负载的不同而发生不同的变化.对于CUDA程序,源代码是最主要的负载,而在程序源代码中最主要的操作语句包含计算语句、存储访问语句、分支语句等.可以认为,因为程序中包含的语句不同,对GPU资源的不同调用,导致程序的运行电流不一样.CUDA程序主要包含计算操作、存储访问操作及程序分支操作,因此本文从程序中提取计算操作、存储访问操作、程序分支3个特征来描述其对GPU运行电流的影响.
1)计算操作:NVIDIA显卡包含多个核处理器,计算操作主要通过调用多个核处理器并行完成;2)存储访问操作:GPU的内存可分为全局内存、共享内存、本地内存、常量内存、纹理内存和寄存器内存.每种内存的速度、大小和访问规则都不同,核函数可对不同的内存区域进行访问.王海峰等[17]通过设计特定程序,计算出全局内存和纹理内存访问指令功耗在71~75瓦特,常量内存访问指令功耗则在68瓦特左右,可以看到,各类内存访问指令功耗相差不是很大,因此,在本文中,对存储访问操作统计时不加以细分;3)程序分支:分支是影响程序性能的一个关键因素,分支越多,程序性能则会越低.在GPU中,由于分支的使用,warp中的线程执行可能会变为串行执行,从而导致GPU资源的极大浪费.
4.3 程序特征提取
用NVIDIA公司的Nsight(5)https://developer.nvidia.com/nsight-systems工具,对加载的CUDA应用程序进行源代码层级的分析,统计得到计算操作、程序分支及存储访问操作的数量,特征提取过程如图2所示.对表2所列的31个修改后的应用程序采用上述方法统计得到的各项特征数据值如表3所示.
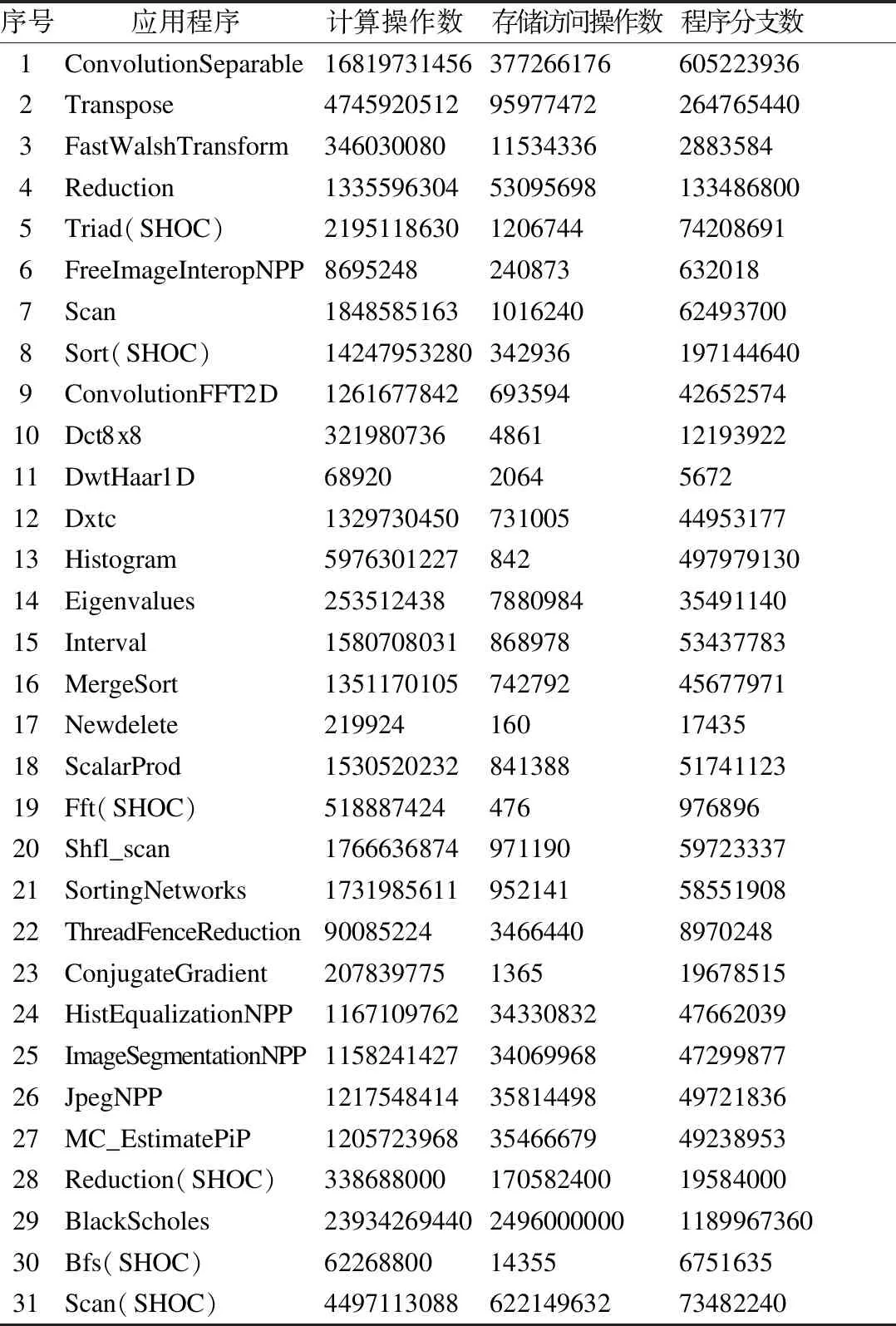
表3 程序特征Table 3 Program features

图2 特征提取过程图Fig.2 Feature extraction process
5 体系结构复杂度系数
不同的GPU有不同的计算核心数和存储频率.为提高模型的通用性,本文首次引入了GPU体系结构复杂度系数.该系数表示不同图形处理器的计算能力,以相同的核心频率和存储频率下的单元晶体管性能表示.公式(1)和公式(2)为系数计算公式:
(1)
(2)
Tnum代表GPU晶体管的数量;Cnum代表GPU计算核数量;NGPu代表GPU每个计算核的晶体管数量;NB代表指定基准GPU每个计算核的晶体管数量;Fcore和FB_c分别代表GPU和基准GPU的核心频率;Fmemory和FB_m分别代表GPU和基准GPU的存储频率;TDPGPU和TDPB分别代表GPU和基准GPU的热额定功耗;CoB代表基准GPU体系结构复杂度系数;CoGPU代表某GPU计算得到的体系结构复杂度系数;PerGPU代表每核性能,当选用GPU与基准GPU属于同一架构,PerGPU的值是1;当选用GPU比基准GPU架构先进,PerGPU的值是1.35.本文选用Geforce GTX 670为基准 GPU,CoB是一个经验值,本文设置为 0.25.表4列出了实验选用GPU的体系结构复杂度系数.

表4 体系结构复杂度系数Table 4 Architecture complexity coefficient
6 基于Elman神经网络的GPU电流预测模型的设计与实现
GPU运行电流可用程序特征函数表示:
(3)
其中,m代表与电流相关的特征数量;hi(Ci)代表第i个程序特征Ci对电流的贡献.当hi(Ci)=αiCi时,电流是关于程序特征的多元线性函数;当hi(Ci)≠αiCi时,电流是关于程序特征的非线性函数.
随着GPU计算负载的变化,GPU的运行电流具有明显的非线性、时变和短时特性.人工神经网络具备自学习、自组织和容错强等优点,对非线性函数关系具有良好的逼近能力,用于描述非线性、时变特性的GPU运行电流比较合适.静态神经网络,如BP算法,可以用来预测GPU的运行电流,但其学习收敛速度慢,学习记忆不稳定.Elman神经网络(ENN)[18]作为一种典型的反馈神经网络,具有收敛速度快、学习记忆稳定、动态特性好等特点.因此,针对具有非线性时间序列特征的GPU运行电流,本文提出了一种基于ENN的GPU运行电流预测模型.
Elman神经网络由输入层、隐藏层和输出层组成.每层所有神经元与下一层的所有神经元相连.此外,它还有反馈神经网络,每个隐藏层通过一组额外的上下文节点进行反馈.它存储隐藏层的输出,稍后将其反馈给隐藏层.
图3为GPU运行电流预测的Elman神经网络结构.Elman神经网络的输入层包含了应用程序的计算操作数、存储访问操作数、程序分支数和体系结构复杂度系数共4类,输出层为预测电流.因此,Elman神经网络的输入层节点数为4,输出层节点数为1.利用MATLAB-Elman神经网络工具实现了电流预测模型,训练算法采用Traingdx算法.通过多次测试,将隐藏层神经元数设为11个,训练后的神经网络均方误差小,相关系数R接近1.

图3 Elman神经网络结构图Fig.3 Elman neural network architecture
7 实验和结果分析
7.1 GPU温度对GPU运行电流的影响
本文首先通过实验观察GPU温度变化对电流数据的影响.图4为NVIDIA Geforce GTX970在GPU初始温度分别为34度和41度时运行Scan和Dct8×8两个应用程序时的电流变化.从图中可以看出,在不同的温度下,同一程序运行时,电流在0A-0.3A之间变化,特别是峰值变化很小.据此可认为GPU温度对GPU运行电流的影响很小.
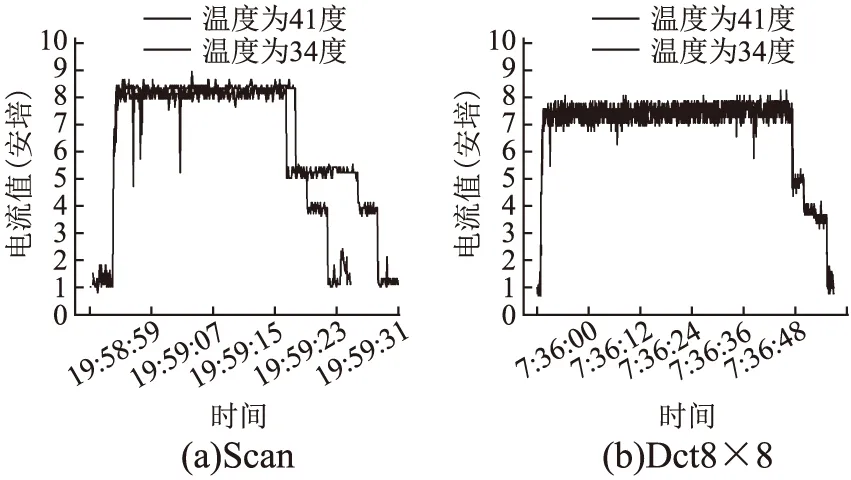
图4 不同温度下的显卡电流变化图Fig.4 Running current change of NVIDIA GTX970 on different temperatures
7.2 实验方法
本文首先对选择的每个应用程序源代码进行修改,一方面修改应用程序核函数block和thread的配置,最大可能提高SM资源占用率;一方面通过增加循环次数,使每个CUDA程序核函数运行时间不少于1分钟,以保证能够采集到足够多的数据,从而保证采集数据的可靠性.同时,为最大限度消除显卡温度对程序运行电流的影响,利用GPU-Z工具(6)https://www.techpowerup.com/gpuz/监视显卡的工作温度,一个程序执行完毕,当显卡温度回落到特定温度(本文为34度)后,再运行下一个程序.针对选定的CUDA应用程序,采用实验室自行设计的GPU实时电流监测采集系统,采集了同一程序在不同显卡(GTX670,GTX680,GTX970)运行时GPU的运行电流值.
7.3 数据预处理
对于每个CUDA应用程序得到一组数据(I,Cinstruction,Cmemory,Cdivergence,Co).其中,I代表程序运行时GPU工作电流,该值是对采集到的电流取平均值,Cinstruction代表程序包含的计算操作指令数;Cmemory代表存储访问操作数,GPU中有多个层级的内存,在本文没有细分;Cdivergence代表程序分支数;Co代表GPU体系结构复杂度系数,该数值不做预处理.从表3可以看到,不同的程序,提取的特征处于不同的数量级,为消除特征数据之间的数据量级影响,需要对数据进行预处理.我们利用对数函数对数据进行变换处理,做如下定义:
yi=ln(Ii)/ln(max(I))
(4)
x1i=ln(C1i)/ln(max(C1))
(5)
x2i=ln(C2i)/ln(max(C2))
(6)
x3i=ln(C3i)/ln(max(C3))
(7)
其中,yi为第i个程序电流预处理后数值,Ii代表第i个程序的测量电流,max(I)代表所有样本的最大测量电流,x1i、x2i、x3i代表第i个程序的计算操作数、存储访问操作数和程序分支数预处理后的数值,C1i、C2i、C3i代表第i个程序计算操作数、存储访问操作数和程序分支数特征值,max(C1)、max(C2)、max(C3)代表所有样本的程序计算操作数、存储访问操作数和程序分支数的最大值,原始数据经过预处理后变为(yi,x1i,x2i,x3i,Co).
7.4 实验结果分析
本文选取表2中的31个应该程序作为样本,每个应用程序分别在NVIDIA Geforce GTX970、NVIDIA Geforce GTX680和NVIDIA Geforce GTX670显卡上运行,共有93组电流数据,选取前81组数据作为训练样本,最后12组(见表5)数据为测试样本,对网络进行训练和验证.
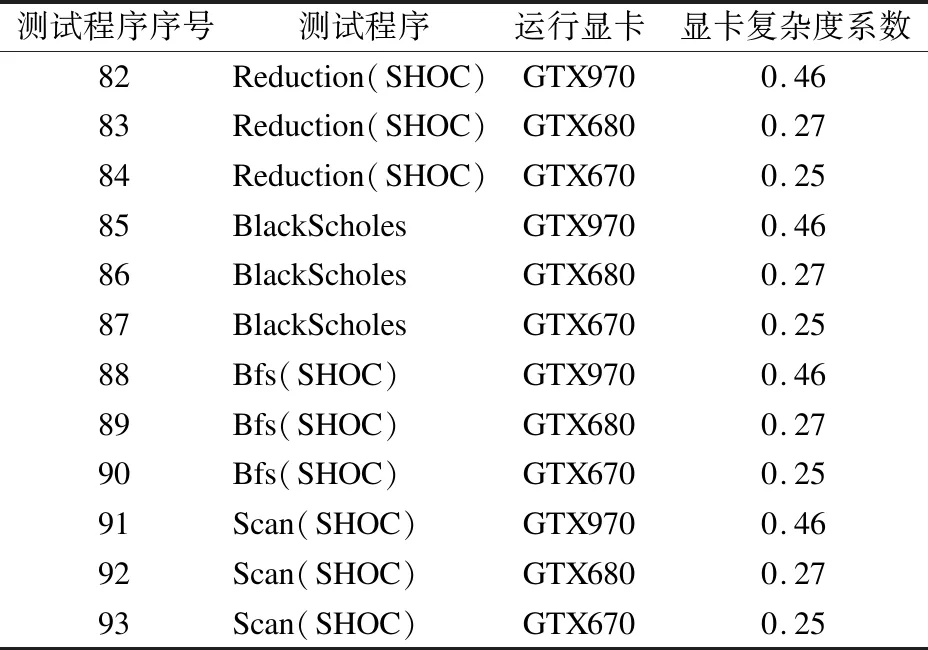
表5 测试程序Table 5 Testing program
用预测误差代表单个程序的预测精度,用测试程序的平均预测误差代表模型的预测精度.式(8)和式(9)为预测误差和平均预测误差的计算公式.
EsErrori=(Iesi-Imea)/Imea
(8)
(9)
其中,EsErrori为第i个程序的预测误差,Iesi为第i个程序的电流预测值,Imea第i个程序的电流测量值,n代表测试程序的个数,AvgEsError代表所有测试程序的平均预测误差.
图5显示了12个测试应用程序的预测结果.采用ENN预测模型得到的运行电流预测值和预测误差分别见表6和表7.

图5 GPU电流预测结果图Fig.5 GPU current prediction result
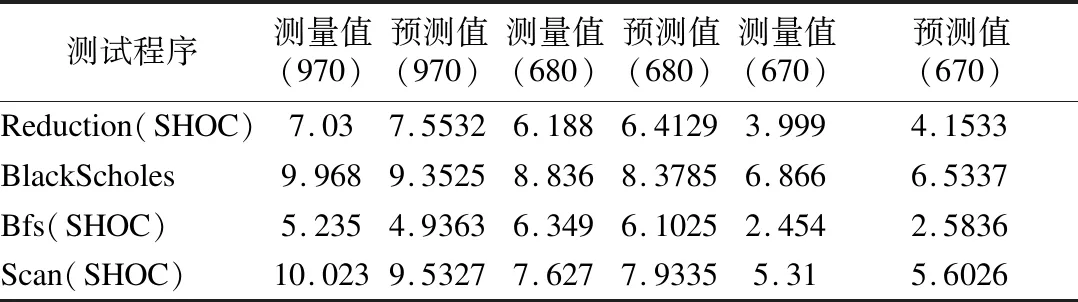
表6 测试程序运行电流预测值和测量值(单位:安培)Table 6 Predicted value and measured value of testing program(UNIT:Ampere)
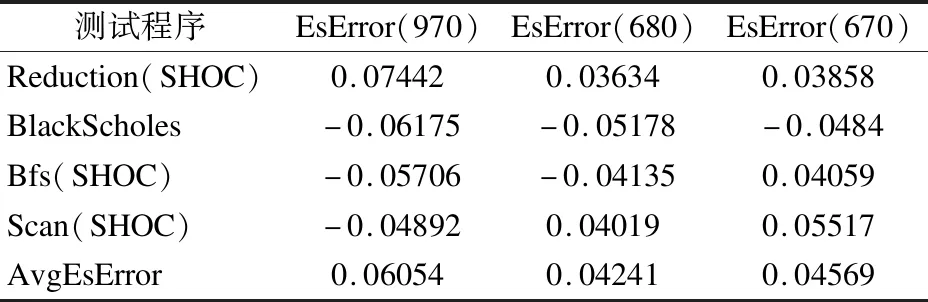
表7 预测误差Table 7 Predicted error of testing programs
从图5、表6和表7可以看到,测试程序的预测值与测量值相近,单程序预测误差不超过8%,不同类型显卡的平均预测误差低于7%.因此,本文所提出的模型具有良好的准确性和通用性.
8 结 语
本文提出以GPU的运行电流为研究对象分析GPU能耗的复杂性.通过分析程序源代码,提取了3个程序特征;同时结合本文引入的GPU体系结构复杂度系数,利用Elman神经网络建立了GPU运行电流预测模型.实验结果表明,单个程序的预测误差不超过8%,不同体系结构间的平均预测误差不超过7%.因此,本文提出的模型具备预测精度高、通用性好等优点.在今后的工作中,GPU不同类型的存储访问操作将进行细分,以提高模型的预测精度.同时,为了更好地描述GPU运行电流和程序特征之间的关系,我们考虑设计和实现一个基于程序切片的电流预测模型.此外,将结合本文模型,进一步研究多程序并行执行GPU能耗控制优化.
