一种多特征融合的中文微博评价对象提取方法
2016-06-30刘璟朱艳辉田海龙马进
刘璟++朱艳辉++田海龙++马进

摘要:针对目前中文微博评价对象抽取方法准确率较低的问题,本文提出一种基于条件随机场的多特征融合方法抽取评价对象,通过分析语义角色、词频、形容词位置特征与正确评价对象的关系,制定了融合基本特征、语义角色特征、词频特征和形容词位置特征的条件随机场多特征模板,实验结果表明,本文的方法提高了评价对象抽取的正确率。
关键词:评价对象提取;特征选择;中文微博;条件随机场
中图分类号:TP391 文献标识码:A 文章编号:1009-3044(2016)14-0188-03
1 概述
在信息爆炸的现代社会,中文微博评价对象抽取研究有非常大的的商业价值,中文评价对象抽取不仅可以服务于上层的情感分析任务,其结果还可以直接用于生活中数据统计分析。
目前对评价对象的抽取方法主要分为三个类别:基于无监督学习的抽取方法、基于监督学习的抽取方法和半监督学习的方法。Jakob N[1]提出了一种包含句法模式的情绪图走向方法提取评价对象候选集,然后采用自主学习策略抽取评价对象。文献[2]和[3]利用条件随机场模型的序列标注方法抽取评价对象。戴敏,王荣洋[4]引使用条件随机场抽取评价对象并引入了一些句法特征。宋晖,史南胜[5]对半监督学习方法提取评价对象进行了研究。Hu Minqing, Liu Bing[6]使用关联规则提取评价对象的候选集。Xu Liheng[7]利用句法分析信息和随机游走模型抽取评价对象。刘鸿宇。赵妍妍,秦兵等[8]使用句法路径自动识别情感评价单元。还有学者采用了话题模型抽取评价对象。本文的目标就是构建一个最优的条件随机场模型抽取中文微博的评价对象。
2 多特征融合的条件随机场评价对象抽取方法
条件随机场模型在自然语言处理任务中,相对于隐马尔科夫模型等其他模型,它能更好利用所提供的上下文信息,相对于其他模型性能更好。
2.1特征选择算法分析
1)语义角色特征
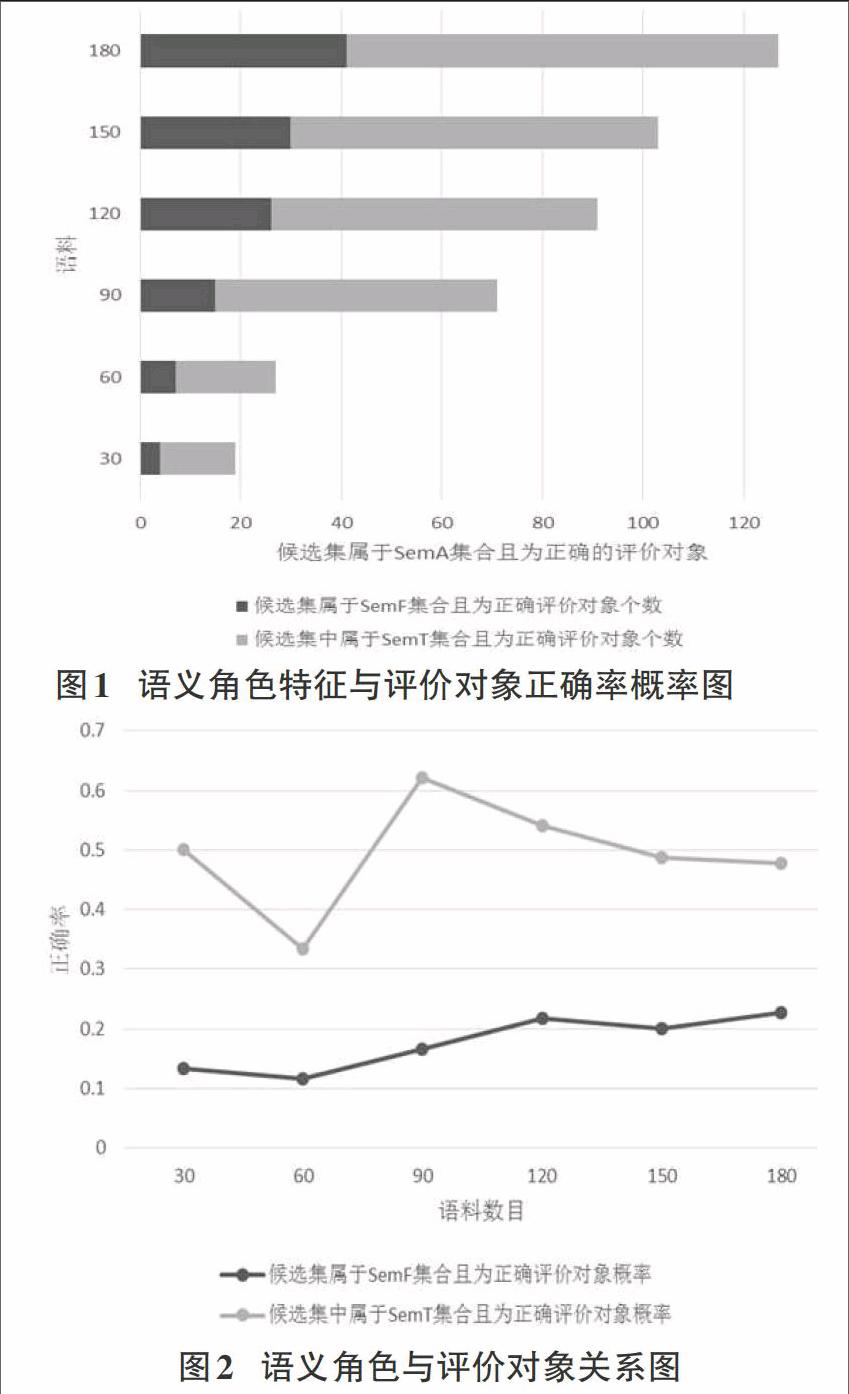
语义角色对评价对象抽取有重要的意义。定义集合SemT,对所有名词进行计算,满足以下两个条件中的任意一个则该名词属于集合SemT。切分词为动词且该评价对象候选集为受事者,切分词为形容词且该评价对象候选集为施事者。定义集合SemF,若名词属于实施着或者受事者,且不属于集合SemT,则该名词属于集合SemF。图1和图2给出了语义角色与评价对象的关系图。当切分词为动词时,受事者为极大可能为评价对象,当切分词为形容词时实施者极大可能为评价对象。
2)词频特征
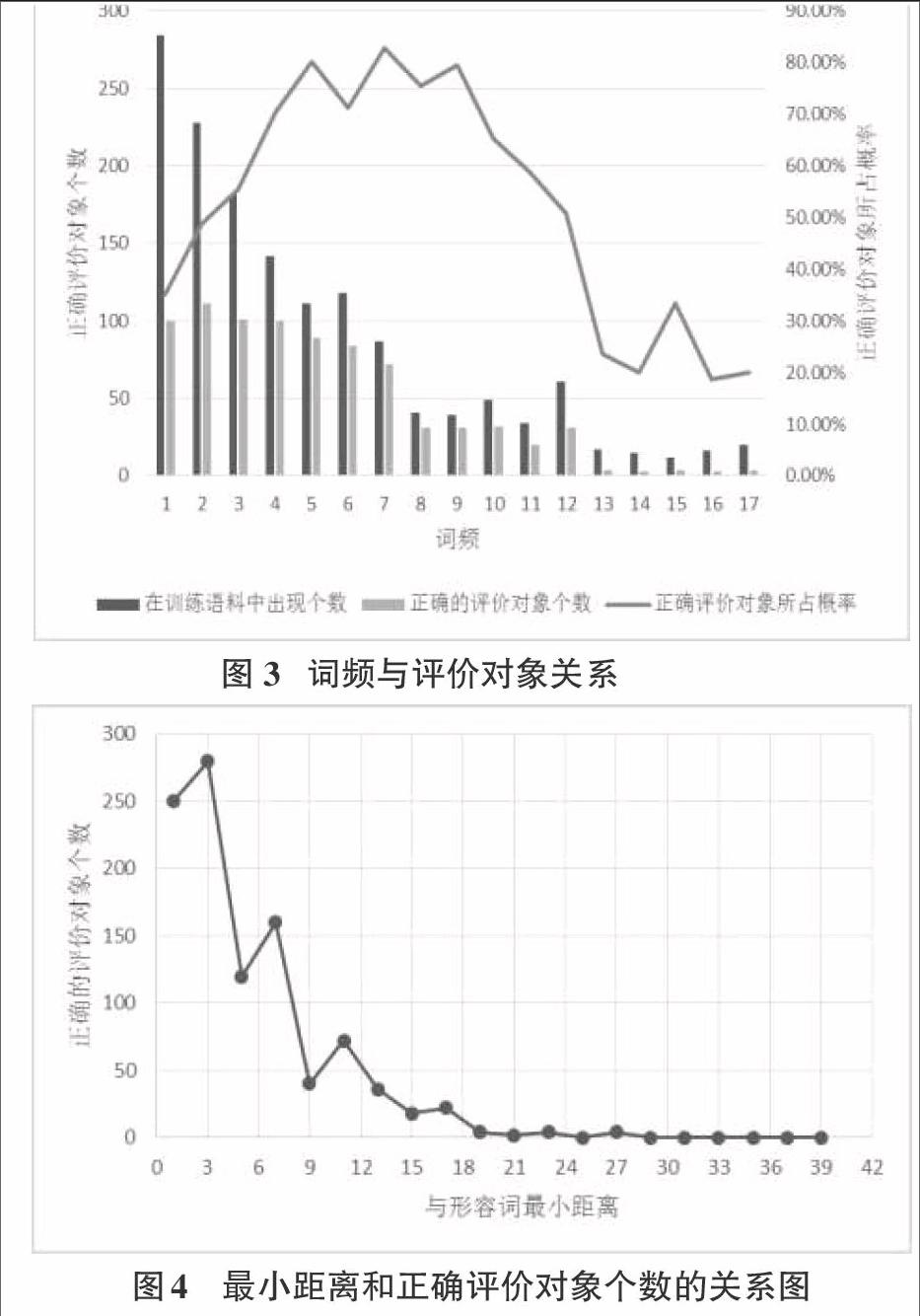
经统计分析发现,评价对象一般为名词或名词短语,对于微博观点句“我的手机从三星换到三星再换到三星,初体验总是很美好,到最后放弃的原因都是同一个:老死机。”其中名词“三星”出现了三次,也是本文要抽取的评价对象,通过分析微博观点句语料,我们发现在句子中频繁出现的名词极有可能为本文要抽取的评价对象。所以本文提出对微博观点句中所有名词提取出它在训练语料中的词频作为条件随机场的一个特征模板。通过统计训练语料中词频与评价对象的关系,其结果如图3所示,由图可知,当词频为1时,在训练语料中出现的次数最多,正确的评价对象个数也最多,但是正确评价对象所占的比率并不高,也就是当词频为1时,正确的评价对象多的同时,不正确的评价对象也非常的多。当词频大于等于3小于11时,正确评价对象所占比例达到了60%以上;当词频大于等于11的时候,正确评价对象所占比例有个大幅的下降,并进入较低的区域。
3)形容词位置特征
对训练语料中正确的评价对象和其与形容词的位置特征进行统计,其统计结果如图4所示。由图我们可以看出当该名词与形容词距离在大于等于1小于等于3的时候正确的评价对象个数都在200以上,有较高的正确率;当该名词与形容词最小距离在大于3小于等于7时,正确的评价个数在150左右,虽然有很多的正确评价对象,但是错误的评价对象也多;当该词与形容词最小距离大于7时,其正确的评价对象小于50并有趋向于0 的趋势,其主要原因是,微博短小精悍,一般都不会很长。
2.2设计条件随机场多特征融合模板
特征选择对条件随机场模型的评价对象抽取结果很大的影响,因此选择什么样的特征是本实验考虑的重点,通过上文的特征选择,本文使用到的特征模板如下面的表所示。
虽然条件机场模型可以容纳各种复杂的自定义特征,但是过多的特征也会导致条件随机场性能降低。我们在相关研究的基础上,通过分析,根据自己实验的特点,制定了基本词性特征模板和三个扩展特征模板。
3实验结果及分析
实验评价方法有很多种,本文采用正确率P、召回率R和F值来验证方法对评价对象抽取的有效性。本文使用第七届中文倾向分析测试预料中的5000句观点句作为测试集,得到实验结果如表5所示:
将本文的方法与文献[4]的方法对比得到对比实验结果如表6所示:
由实验结果可知,对于基本的词性模板,条件随机场很难判断评价对象,但是加入了语义角色的模板之后,实验结果有了很大的提高,语义角色的特征对评价对象抽取有很大的意义。在加入词频模板和形容词位置特征模板F值分别提高了1.5%和4.5%,将本文方法与文献[4]方法对比,F值提高了3.3%,实验结果表明,本文的方法有效提高了评价对象抽取的正确率。
参考文献:
[1] Jakob N, Gurevych I. Extracting Opinion Targets in a Single and Cross-Domain Setting with Conditional Random Fields[C]//Proceedings of EMNLP-2010. 2010: 1035-1045.
[2] Li Fangtao, Han Chao, Huang Minlie, et al. Structure-aware review mining and summarization[C]//Proc of the 23rd International Conference on Computational Linguistics. 2010: 653-661.
[3] Ma Tengfei.Wan Xiaojun. Opinion target extracton in Chinese news comments[C]//proc of the 23rd International Conference on Computational Liuguistcs, 2010: 23-27.
[4] 戴敏,王荣洋. 基于句法特征的评价对象抽取方法研究[J]. 中文信息学报,2014,28(4):93-97.
[5] 宋晖,史南胜. 基于模式匹配与半监督学习的评价对象抽取[J]. 计算机工程,2013,39(10):221-226.
[6] Hu Minqing,Liu Bing. Mining Opinion Features in Customer Reviews[C]//Proc. of the 19th National Conference on Artifical Intelligence. San Jose,USA: AAAI Press,2004.
[7] Xu Liheng,Liu Kang,Zhao Jun. Mining opinion words and opinion targets in a two-stage framework[C]Proc of the 51st Annual Meeting of the Association for Computational Linguistics. 2013.
[8] 赵妍妍,秦兵. 基于句法路径的情感评价单元识别[J].软件学报,2011,22(5):887-898.
