关于短文本匹配的泛化性和迁移性的研究分析
2022-01-19马新宇范意兴郭嘉丰张儒清苏立新程学旗
马新宇 范意兴 郭嘉丰 张儒清 苏立新 程学旗
(中国科学院网络数据科学与技术重点实验室(中国科学院计算技术研究所) 北京 100190)(中国科学院大学 北京 100049)
短文本匹配任务是指输入2段短文本,通常是句子级或者短语级,算法或者模型需要预测它们之间的匹配程度.自然语言理解中的许多任务,包括自然语言推断[1]、复述问题[2]、答案选择[3]、问答任务[4]都可以抽象成短文本匹配问题,例如自然语言推断需要判断2个句子间是否存在蕴含关系,复述问题需要判断2个句子是否语义相等,答案选择和问答任务都需要判断句子是否包含问题的答案.短文本匹配任务在现实中有着广泛的应用,例如在线聊天机器人中对话的匹配[5]、社区问答系统中相似问题的匹配[6],以及机器阅读理解系统[7]中问题和答案的匹配等.
近年来,短文本匹配取得了显著进步,一方面得益于深度学习的发展,深度学习模型在计算机视觉和自然语言处理领域已经几乎显著超越或者碾压所有传统基于规则的方法和机器学习技术,尤其是近年来以BERT(bidirectional encoder representations from transformers)[8]为代表的首先在大规模无监督语料上学习通用表达的预训练模型,使得自然语言处理(natural language processing, NLP)中的很多任务得到了全面的性能提升.然而,深度学习模型通常需要大量的标注数据来进行训练,现实中往往没有很多标注数据,并且标注数据的成本很高;同时预训练模型一直被认为有较好的泛化能力,但是通过我们的实验发现,在大多数情况下,BERT的泛化能力是比较差的.另一方面大量公开的数据集也对短文本匹配任务的发展起到了非常重要的促进作用.比如被广泛使用的GLUE benchmark[9]是很多自然语言理解模型评价的标准数据集集合,10个任务中的9个都可以抽象成短文本匹配问题.问答领域也发布了很多通用的数据集,比如SQuAD[10],Ms marco[11],尤其是Ms marco,它的标注数据量达到了百万级.然而,对于这些现有的有标注数据集,很少有研究去分析它们是否能泛化到一个新的数据集,以及如何利用这些现有的大量有标注数据到新的领域中去,达到减少新领域的数据标注量和提升性能的目标.
本文的主要目标为分析短文本匹配数据集之间的泛化性和迁移性,为未来利用迁移学习的方式在新领域提升短文本匹配模型的性能提供有价值的指导.具体来说,我们将分析目标分解为3个具体的研究问题.
问题1. 不同短文本匹配数据集之间的泛化关系是怎么样的,与哪些因素有关?
问题2. 是否能利用其他领域的数据集提升目标领域数据集的性能?
问题3. 基于以上分析,如何有效利用其他领域的标注数据来提升新领域的性能?
对于问题1,我们首先在源数据集上进行训练,然后在目标数据集上直接测试性能(泛化),为了规避模型对泛化能力的影响,我们在所有实验中都使用了2个深度学习模型进行对照,一个是传统的深度学习模型ESIM[12],另外一个是预训练语言模型BERT[8].然后通过力导向图算法可视化数据集之间的关系.对于问题2,我们首先在源数据集上进行预训练,然后在目标数据集上微调再测试性能(迁移),同时对数据集之间的迁移关系进行了定量的分析,即给定不同的源数据集的数据量,观察迁移带来的性能提升效果.对于问题3,基于对数据集之间泛化性和迁移性的分析,我们提出了一种简单可行的办法,可以提升模型的泛化能力和迁移能力,并在新领域并且只有很少标注样本的情况下,取得了很好的效果.
本文的主要贡献有3个方面:
1) 分析研究了不同数据集上的模型泛化能力.发现模型的泛化能力主要与数据集的类型和来源有关,并且类型的影响要大于数据集的来源.
2) 分析研究了不同数据集上的模型迁移能力.发现数据集的迁移能力和泛化能力的趋势往往是不一致的;并且即使是预训练模型BERT,在目标数据集很大的情况下(几十万标注样本),合适的迁移仍能带来性能的提升.
3) 基于对泛化性和迁移性的分析,提出通过将数据集进行平均混合的方式,可以提高模型的泛化能力和迁移能力.实验表明BERT在此混合数据集预训练之后,在新的领域并且只有100个标注样本的情况下,达到了堪比原始千级和万级标注数据量的效果.
1 任务描述

r=F(T1,T2),
其中F代表不同的匹配模型.
我们选择了10个常用的短文本匹配数据集来进行此次分析实验,这些数据集除了SNLI[13]和MNLI[14]为三分类,其余全部为二分类.我们按照数据集规模,以10万数据量为分界线,将数据集分为大数据集和小数据集.在接下来的实验中,为了消除数据规模的影响,我们固定大数据集的数据量,每个大数据集只随机选取10万的数据进行实验.表1是关于这些数据集的一些特征描述,包括数据集的数据量、数据集来源和类型.
我们首先介绍大数据集:
SNLI[13]是斯坦福自然语言推断数据集,它是根据图像数据集人工标注的,需要判断2个句子是蕴含、矛盾或者中立关系.
MNLI[14]是多类型自然语言推断数据集,数据集中的数据来自多种领域,例如演讲、小说和政府报告等.它需要判断2个句子是蕴含、矛盾或者中立关系.
QNLI是由问答数据集SQuAD[10]转换成的自然语言推断数据集,数据主要来自于英文维基百科.该数据集需要判断问题的答案是否被另外一个句子所包含.
Ms marco[11]是一个大规模的微软阅读理解数据集,我们从原始的数据集中抽取了12万数据并转换为问题和答案所在句的匹配问题,该数据集的数据来自网页文档.
QQP[15]是复述问题数据集,该数据集主要来自问答网站Quora,它需要判断1个句子对是否是重复问题,是二分类任务.
小数据集主要有:
WNLI[16]是一个自然语言推断数据集,数据主要来自于小说,训练集数据量约为1 000.
RTE[17]是二分类自然语言推断数据集,数据主要来自于网上新闻,训练集数据量约为3 000.
SciTail[18]是自然语言推断数据集,数据主要来自于科学考试中的多项选择题,训练集数据量约为3万.
MRPC[2]是一个复述问题数据集,数据主要来自在线新闻,训练集数据量约为4 000.
WikiQA[19]是一个问答数据集,数据主要来自必应的搜索问题和维基百科的文档,训练集数据量约为3万.

Table 1 Statistics of Different Matching Datasets
2 模 型
我们使用了2种常用的深度学习模型进行分析实验:一种是传统的深度学习模型ESIM[12],另外一种是预训练语言模型BERT[8],2个模型主要用来进行对照.
2.1 ESIM模型
ESIM[7]是短文本匹配中效果较好的模型之一,它模型结构简单,但是高效,且在短文本匹配中比较通用,它主要由3个模块组成.
1) 表达层.使用双向长短记忆网络LSTM[20]编码2个句子的词向量,提取词表达.
2) 特征提取层.由局部注意力机制[21]对2个句子进行对齐操作.
3) 匹配层.使用池化层和全连接计算匹配得分.我们使用了Spacy分词工具对文本进行分词和Glove300d[22]初始化词向量.
2.2 BERT模型
BERT[8]是预训练语言模型,它首先在大量的无标注文档上进行预训练,然后在下游任务上进行微调,它在多种自然语言理解任务上达到了目前最好的效果.模型的结构使用了Transformer[21]的编码器部分,主要的组成部分包括了自注意力、Layer-Norm[23]等.输入由2个句子s1和s2拼接而成,[CLS]+s1+[SEP]+s2+[SEP],输出为线性全连接层,即分类层.实验中句子最大长度设置为128,BERT的分词使用自带的WordPiece[24]分词方法,一个单词有可能会被分成多个子词,我们使用谷歌开源的BERT-base-uncased版本的模型进行实验.
3 实验及分析
为了对比公正,我们严格控制了实验流程,确保所有数据集的训练和测试流程一致,尽量不引入其他变量,只微调部分超参.我们将发布代码,供研究社区使用.ESIM模型在训练过程中采用了early-stop技术,使用Adam[25]优化器进行优化,使用Glove300d初始化词向量;BERT模型对大数据集学习率设置为2E-5,小数据集学习率选取1E-5,2E-5,3E-5,4E-5,5E-5中效果最好的,训练5次取平均值.
3.1 模型是否可以泛化到新的数据集
深度学习模型目前在单个数据集上已经取得了很好的性能,我们很自然地想到是否能从一个数据集直接泛化到一个新的数据集,不做任何训练就能达到很好的性能.我们首先在5个大的数据集上进行训练,由于这些数据集规模不一,为了消除数据量的影响,我们对每个大数据集只取10万的样本进行训练.另外我们也随机从这5个大数据集中随机取2万的样本,组成一个新的数据集Multi-100K(MT100K).在源数据集上训练完模型之后,我们在其他所有数据集上直接进行测试,不在目标数据集上再进行训练.由于SNLI和MNLI是三分类自然语言推断数据集,我们将其标签从(蕴含、中立和矛盾)合并成2类(蕴含和不蕴含)以进行泛化实验.
实验结果如表2所示,表2中值为准确率,其中上表是ESIM模型结果,下表是BERT模型结果,虚线右侧是大数据集,虚线左侧是小数据集,行代表源数据集,列代表目标数据集,SELF行表示在目标数据集上训练和测试,MT100K行表示在MT100K数据集上训练,然后在目标数据集上测试,由于MT100K是从大数据集中取了部分数据,所以它对大数据集不做泛化实验.我们发现模型在不同数据集上的泛化能力非常差.对于ESIM模型,在源数据集上训练,在目标数据集上测试,比在目标数据集上训练和测试(SELF行)的性能平均下降14.1个百分点,即使我们取每个数据集上泛化性能最好的结果,性能也平均下降了6.1个百分点;对于BERT模型,在源数据上训练,在目标数据集上测试与SELF行相比,性能下降了18.7个百分点,即使取每个数据集上泛化能力最好的,性能也下降了7.5个百分点.因此,模型在训练过的数据集上发生了过拟合现象.虽然BERT相比于ESIM模型下降的稍多,但是整体泛化性能还是要比ESIM高2.5个百分点,这得益于BERT在大规模语料上预训练以及模型本身的能力.

Table 2 Generalization Experimental Results
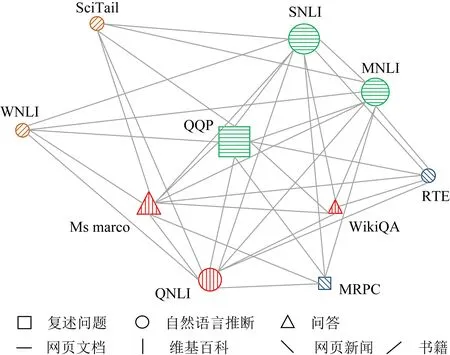
Fig. 1 Visualization of similarity between datasets
3.2 数据集之间的泛化关系与什么因素有关

结果如图1所示,我们发现这些数据集很自然地按照任务类型(形状内的纹理)和数据集来源(形状)聚集.泛化性最好的2个数据集一定是类型相同,来源相同,例如图1中右上角区域的SNLI和MNLI,左下角区域Ms marco和QNLI,因为QNLI是从问答数据集中转变过来的,训练数据更像是问答类型,所以它和问答数据集的泛化性能较好,尤其是和Ms marco数据集.因此,数据集之间的泛化能力主要与数据集的类型和来源有关.
3.3 源数据集规模越大,其泛化能力是否越强
从实验中,我们发现MT100K的泛化性能已经接近在目标数据集泛化最好的性能,平均性能仅下降3%.为此,我们基于混合数据集进一步分析源数据集规模大小对其泛化能力的影响.具体地,我们从5个大数据集中等量抽取4万、6万、8万和10万数据进行训练,然后将其泛化到小的数据集.
实验结果如表3所示,我们可以看到增大源数据集规模之后,除了WNLI数据集,其他4个数据集的性能都有所提升,平均性能提高了6个百分点.尤其是MT500K,在SciTail数据集上比MT400K提升了约2个百分点.增大源数据集规模之后,WNLI数据集性能下降的一个可能原因是WNLI的训练和测试集过于小,其中测试集只有几百个测试样本,与预训练数据集的规模差异过大,导致模型在源数据集上出现了过拟合现象.因此一般情况下,源数据集规模越大,泛化性能越强.

Table 3 Generalization Results of Different Sizes of Mixed Datasets on Small Datasets
3.4 不同数据集之间的泛化和迁移趋势是否一致
在这个实验中,我们分析不同数据集之间的迁移是否和泛化具有相同的趋势.如果趋势一致,我们就可以直接选择泛化能力强的数据集,用来提升目标领域数据集的性能.具体地,我们在5个大数据集上进行预训练,然后在其他所有数据集上进行迁移测试,并分析迁移后的性能与之前分析的泛化性能的一致性.同泛化实验一样,我们保证训练流程一致,只微调部分参数,尤其BERT这种对小数据集敏感的模型,我们实验多次取平均值.
实验结果如表4所示,我们发现了数据集之间泛化和迁移的趋势往往是不一致的.从源数据到目标数据的组合共有45种,而ESIM和BERT模型泛化和迁移趋势一致的分别只有3个和2个.虽然泛化实验计算量很小,但是我们不能直接从泛化实验的趋势推广到迁移实验.另外,从实验结果看,BERT模型比ESIM模型的迁移效果要高很多.因此,预训练模型的泛化能力要比传统的深度学习模型强,并且迁移能够带来比泛化更大的性能提升.

Table 4 Results of Transfer Experiment
3.5 迁移能够带来多少性能的提升
我们在此实验中,进一步分析经过在源数据集预训练之后的模型,迁移到目标数据集上能够带来多少性能提升,尤其是预训练语言模型BERT,是否能在目标数据集很大的情况下,还能有性能上的提升.
从实验结果表4中,我们可以看到ESIM模型在5个大数据集上迁移的平均性能比在源数据集本身进行训练和测试(SELF行)提升2.2个百分点,如果选取每个数据集上泛化最好的性能,则提升3.5个百分点;对于BERT模型,在5个小数据集上如果选取泛化最好的性能,则提升3个百分点,在5个大数据集上如果选取每个数据集上泛化最好的性能,仍能提升0.3个百分点.所以,即使是BERT这种预训练模型,合适的迁移仍然能带来性能的提升.
3.6 目标领域数据量的大小对性能的影响
我们在此实验中分析,在目标领域中不同数据量的情况下对应的迁移性能的变化,观察模型能否在少样本的情况下取得不错的效果.具体来说,我们首先使用在5个大的目标数据集上迁移能力最好的大的源数据集上进行预训练,然后不断增加目标数据集的数据量,比如对于ESIM模型和SNLI数据集,我们先在QNLI上预训练,然后不断增加SNLI的数据量,测试其性能.由于MT100K良好的泛化能力和迁移能力,我们也将其加入到了BERT模型下的实验.实验结果如图2所示,图2(a)为ESIM模型下的实验结果,图2(b)为BERT模型下的实验结果.图2中正方形标记的曲线代表只在目标数据集上的训练和测试;三角形标记曲线代表首先在迁移效果最好的数据集上预训练,然后在目标数据集上训练;圆形标记曲线代表先在MT100K上训练,然后在目标数据集上训练和测试.实验结果表明,在迁移效果最好的数据集上进行预训练,不管对于ESIM模型还是BERT模型,在几乎所有实验中都要比只在数据集本身训练和测试要高,证明了合适的迁移会给数据集带来性能上的提升.根据统计,我们发现在源数据集上进行预训练之后,仅需37%的目标数据集量,就能达到目标数据集95%的性能.此外,由图2(b)所示,在MT100K上进行预训练的结果曲线比在迁移效果最好的源数据集训练的曲线更加平滑,性能也有所提升,进一步验证了多个数据集的融合能提高模型的迁移能力.

Fig. 2 Learning curves of five large datasets
3.7 混合后的数据集在新领域和小样本情况下的性能
基于对不同领域数据集之间泛化性和迁移性的分析,我们发现预训练模型BERT在平均混合的数据集上预训练之后,有着更好的泛化能力和迁移能力.为此,我们探索在少量样本的情况下,将MT100K应用到新领域的表现.我们选择4个小数据集SciTail,WNLI,RTE,MRPC进行实验,在这4个小数据中随机取100个样例.我们先使用BERT模型在MT100K上进行预训练,然后再在这4个小数据集上100个样例进行微调和评价.
实验结果如表5所示,其中MT100K行是在MT100K数据上预训练之后,再在4个小数据集上100个样本进行微调,最后进行测试;SELF行代表在小数据集上的全量数据进行训练和测试.我们发现在少量样本(只有100个)情况下,MT100K的平均性能只比全量的小数据集低4.1个百分点.因此在短文本匹配领域,对于新领域的数据集,我们可以首先将其他领域的数据集等量混合,然后使用BERT模型在混合的数据集预训练之后,再进行少量的目标样本标注和训练,就可以达到不错的效果.

Table 5 Experimental Results of MT100K on 100 Samples
4 相关工作
深度学习方法尤其是预训练方法在短文本匹配问题取得了目前最好的效果,但是这些模型在某个数据集训练之后很难泛化到其他的数据集,尤其因为短文本匹配包含多种匹配任务[1-4],这种任务之间的差距使得泛化更加困难.Liu等人[27]结合了多任务学习和预训练方法,训练之后可以在多个数据集上取得较好的效果,并且证明了经过多任务学习,模型的领域迁移能力有很大的提升.Raffel等人[28]将文本匹配问题和阅读理解等其他问题全部抽象成“text-to-text”问题,通过超大规模的无标注数据的预训练,提升模型的泛化能力.Yogatama等人[29]尝试通过在多个数据集上预训练得到更加通用的表达.本文主要受Talmor[30]的工作启发,它们从机器阅读的领域出发,研究了不同的机器阅读理解数据集的泛化性和迁移性,我们尝试将其推广到短文本匹配领域.
5 总 结
本文在10个数据集上,使用2种深度学习模型对短文本匹配的泛化性和迁移性进行了详尽的分析实验.实验结果表明:1)深度学习模型的泛化能力很差,会在训练过的数据集发生过拟合,即使是BERT这种预训练模型;2)影响泛化能力的因素主要有匹配的类型和匹配数据集的来源;3)实验结果显示不同数据集之间泛化性和迁移性趋势通常情况下并不保持一致;4)通过迁移,模型能在小数据集上有较大的提升,即使是BERT这种预训练模型,合适的迁移也能在目标数据集带来提升;5)将数据集进行简单的混合能带来更好的泛化能力和迁移能力,在将其应用到新的领域和少量样本的情况下,模型取得的效果非常好.总结来看,本文的分析工作对未来利用现有数据集迁移到新的领域,并且在减少目标数据标注量和提升性能上提供了有价值的指导.
作者贡献声明:马新宇负责所有的实验及分析,以及文章的撰写;范意兴参与了论文想法的讨论、论文逻辑的梳理,还设计各个实验和修改论文等;郭嘉丰参与了论文想法的讨论、论文摘要和前言的修改,以及部分实验的分析;张儒清参与了论文想法的讨论、论文逻辑的梳理和实验的设计,修改了论文的实验部分;苏立新是论文想法的提出者,并在实验过程中给予了大量的指导;程学旗参与了论文想法的讨论,确定了论文的分析思路,提供了服务器进行大量的实验.
