一种基于排序代理锚损失的深度度量学习算法
2022-10-15陈海燕侯夏晔袁立罡刘振亚
张 兵,陈海燕,侯夏晔,袁立罡,刘振亚
1(南京航空航天大学 计算机科学与技术学院,南京211106)
2(南京航空航天大学 民航学院,南京211106)
3(软件新技术与产业化协同创新中心,南京210023)
E-mail:chenhaiyan@nuaa.edu.cn
1 引 言
度量学习的目的是根据数据自身特点,学习一种最优的度量方式来衡量样本之间的相似性.传统度量学习算法的提出,极大地改善了基于距离的机器学习算法的性能.近年来,随着深度学习在视觉识别领域取得巨大成功,神经网络的端到端训练和语义特征提取的优势被应用到度量学习中,形成了一种新的度量学习模式——深度度量学习[1].深度度量学习通过训练一个神经网络将数据映射到一个嵌入空间中,在这个空间中,样本越相似则其嵌入向量就越接近,越不相似则其嵌入向量就越远离.相比于传统的度量学习方法,深度度量学习最大的优势在于神经网络可以联合学习特征表示和语义嵌入,因此被广泛地应用到计算机视觉领域,例如图像检索[2]、人脸识别[3]、视觉跟踪[4]、行人再识别[5]等.
损失函数在深度度量学习中起着至关重要的作用,根据计算损失时使用策略的不同,现有的深度度量学习损失大致可以分为两类:基于对的损失(Pair-based Loss)和基于代理的损失(Proxy-based Loss).
基于对的损失函数旨在用一组成对的距离来表示两个样本之间的关系,如最早被提出的对比损失[6],目标是在嵌入空间中最小化同类样本间的距离,而异类样本则彼此推开.最近被提出的排序列表损失(Ranked List Loss,RLL)[7]也是一种基于成对约束建立的损失函数,给定一个查询点,对所有数据点进行相似度排序,获得一个排序列表.该损失旨在探索基于集合的相似结构,相比基于点的方法能够包含更丰富的信息.但是,它的这种相似结构是基于每个训练批次中所有的数据来建立的,当批数据量过大时,训练复杂度高,收敛速度慢.
基于代理的损失函数通过为每个类分配一个代理来解决训练复杂度高的问题.代理损失将每个数据点视为一个锚点,并约束锚点样本更靠近同类代理点而远离异类代理点.最近新提出的代理锚损失(Proxy Anchor Loss,PAL)[8]兼顾了代理损失和基于对的损失的优点,它将每个代理作为锚点,并将同一类的数据拉近代理而其他类的数据尽量远离代理.然而,代理锚损失在对正样本对进行挖掘时试图将同一类的正样本压缩到特征空间中的某个代理锚点,没有考虑类内数据的分布情况,这很容易造成同类样本的相似结构的丢失.
本文在RLL和PAL的启发下,结合两者的优势,提出了一种新的基于代理锚的排序列表损失函数.该损失函数根据数据到给定代理锚点的距离,对所有样本对进行排序得到一个排序列表,使所有的正样本都排在负样本之前,同时只强制正样本到其同类代理锚点的距离小于阈值.通过这种方式尽可能地保留每个类内部的相似结构,解决了代理锚损失中忽略类内数据分布的问题.此外,该损失也具有代理锚损失的优势,训练复杂度较低,收敛速度较快.最后在两个标准数据集上验证了该损失函数的有效性.
2 相关工作
2.1 排序列表损失
RLL是一种新的基于对的损失函数,该方法考虑了一批数据中的所有正样本和负样本来构建一个基于集合的相似结构.具体来说,给定一个查询点,RLL根据相似性对所有数据点进行排序来获得一个排名列表,将所有正样本都排在负样本之前,并且通过只强制正样本对的距离小于阈值,来为每个类学习一个超球体,阈值是每个类的超球体的直径,如图1所示.这样,RLL可以有效地保留每个类内部的相似结构.另外,RLL用间隔m来分隔正集和负集.给定一个样本xi,RLL的目标是把它的负样本推到边界α以外,把它的正样本拉到边界α-m以内,具体形式见式(1):
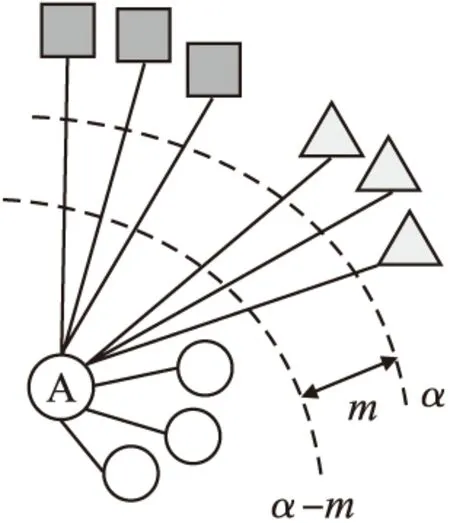
图1 排序列表损失;圆A表示一个锚点,它们不同的形状表示不同的类别Fig.1 Ranked list loss;the circle A indicates an anchor,their different shapes represent distinct classes
Lm(xi,xj;f)=(1-yij)[α-dij]++yij[dij-(α-m)]+
(1)
(2)
dij=‖f(xi)-f(xj)‖2
(3)
f表示嵌入函数,dij表示两个样本点之间的欧氏距离.
(4)
(5)
RLL通过公式(1)对具有非零损失的非平凡样本对进行挖掘,即违反损失约束的样本对,并通过公式(5)对非平凡的负样本对进行不同程度的加权,目的是利用所有的数据点学习一个基于集合的相似结构,使得正负样本分离,查询点与正样本的距离要比负样本更近,且两者之间保持一个m的间隔.RLL最大的问题是,计算复杂度高,收敛速度慢,无法较好地应对数据量大的应用场景.
2.2 代理锚损失
为了解决基于对的损失中训练复杂度高的问题,基于代理的度量学习损失被提出.这类方法的思想是为训练集中的每个类生成一个代理,来体现嵌入空间的全局结构,并在训练过程中将每个数据点与代理相关联.由于代理的数量远远小于训练数据的数量,有效降低了训练的复杂度.代理NCA损失(Proxy-NCA Loss,PNL)[9]是第一个基于代理的损失函数,它借鉴了近邻成分分析(Neighbourhood Components Analysis,NCA)[10]的思想,希望锚点样本与其同类代理点的距离更近而与其异类代理点的距离更远.但这种方法也存在一个固有的局限性:由于每个数据点只与代理相关联,因此损失了基于对的损失函数中大量用到的数据关系.
PAL借鉴基于对的损失的思想,利用了数据之间的关系,克服了PNL固有的局限性,具体如图2所示.PAL将每个代理作为一个锚点,并将其与批处理中的所有数据联系起来,PAL损失函数见式(6):
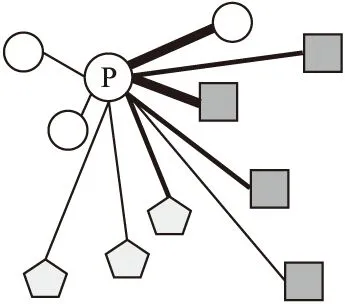
图2 代理锚损失;圆P表示代理,它们不同的形状表示不同的类别Fig.2 Proxy anchor loss;the circle P indicates a proxy,their different shapes represent distinct classes
(6)
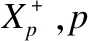
与PNL不同的是,PAL通过在损失中增加间隔而产生了类内紧致性和类间可分离性,从而构造了一个更有鉴别性的嵌入空间.但PAL也是将同一类正样本压缩到特征空间中的某个代理锚点附近,没有考虑类内数据的分布情况,这很容易造成同类样本相似结构信息的丢失.
3 基于排序代理锚损失的深度度量学习算法
3.1 排序代理锚损失
本文结合了PAL和RLL的优势,提出了一种基于代理锚的排序列表损失(Ranked Proxy Anchor Loss,RPAL),同时兼顾类内数据分布问题和训练复杂度问题.和PAL一样,RPAL从每个类中选择一个代理作为锚点样本,然后将整批数据与其关联起来,对于正样本对则约束其距离小于一定的阈值,以此来尽量保留类内数据的相似性结构,具体如图3所示.图中每个形状代表一个类别,中心的圆P表示该类的一个代理锚点,RPAL的目的是以代理锚点为中心,将批量中所有的正样本拉到边界α-m以内,并将所有的负样本尽可能地推到边界α以外,使正负集之间保持一定间隔m.

图3 RPAL说明Fig.3 Illustration of RPAL
RPAL按照代理NCA中的标准代理分配设置为每一个类分配一个代理,本文参照了RLL中损失函数的形式,并将其引入到PAL中,得到RPAL的总损失函数见式(7):
(7)
Lm(x,p)=(1-y)[α-d(x,p)]++y[d(x,p)-(α-m)]+
(8)
(9)
其中,仅当x和p类别相同时,y=1,否则y=0.wij和RLL中的设置一样,是负样本对的权重,参数T控制着加权的程度.当T=0时,它平等地对待所有非平凡的反例,如果T=+∞,它将成为最难挖掘的反例.d(x,p)表示嵌入向量x与代理锚点p的余弦距离.在该损失中,通过公式(8)来对非平凡样本对进行挖掘,即违反了式中的约束,具有非零损失的数据点.此外,通过公式(9)对每个批次中大量的非平凡负样本根据其违反约束的程度来进行加权.
3.2 算法描述
在每次批训练中,RPAL首先为每个类选择一个代理作为锚点;然后,通过根据距离对批处理数据中所有其他数据点进行排序来获得一个排名列表,优化的目标是将所有的正例都排在负例之前.并且,为了保留每个类内部的相似结构,在RPAL中将每个正样本约束到边界α-m以内,即为每个类以代理锚点为圆心,以α-m为半径,学习一个超球体;对于负样本,则将它们推到另一个边界α以外,使得正集与负集之间间隔m.算法1描述了基于RPAL的深度度量学习算法RPAL-DMLA.
算法1.RPAL-DMLA
输入:所有训练图像数据;预训练网络参数;损失函数的超参数:α,m,T;
输出:更新后的网络参数;
过程:
1.通过采样器构造小批量数据,并将其输入到网络,得到一批嵌入向量X
2.为批中的每个类分配一个代理p,构造代理集P,正代理集P+
3.计算所有嵌入向量x与代理p的距离d(x,p)
4.for eachx∈Xdo
5. 基于d(x,p)和公式(8)对正负样本对采样;
6. 根据公式(9)计算负样本权重wij;
7. 根据公式(7)计算损失L(X)
8.endfor
9.梯度计算并反向传播更新的网络参数
10.结束
3.3 算法复杂度分析
设M表示训练样本数,C表示样本的类别数,该损失的复杂度是O(MC),因为它在批处理中将每个代理与所有正样本和负样本联系起来进行比较.在公式(7)中,第1项求和公式约束的是代理锚与正样本的距离,使得它小于阈值α-m,复杂度是O(MC);第2项求和公式旨在将负样本与代理锚推开,使它们之间的距离大于阈值α,复杂度也是O(MC),因此RPAL总的计算复杂度是O(MC),与PAL相同,收敛速度得到了保证.
4 实验与分析
4.1 实验数据
本文在两个流行的标准图像检索数据集上对所提方法进行了实验评估:
1)CUB-200-2011[11]数据集,拥有200种鸟类的11788张图片,实验中将前100个类的5864张图片用于训练,其他100个类的5924张图片用于测试.
2)Cars-196[12]数据集,包含196个车型的16185张图片,实验中使用前98个类的8054张图片进行训练,其余98个类的8131张图片用于测试.
4.2 实施设置
为了与之前的工作进行公平的比较,本文采用了在ImageNet数据集上预训练且进行了批标准化的GoogleNet V2(BN-Inception)[13]作为嵌入网络.实验中根据嵌入向量的维度,对最后一层全连接层的大小进行了修改,并用L2标准化对最后的输出进行了归一化处理.
在训练过程中,对输入图像通过水平翻转和随机裁剪进行了数据增强,而在测试中只对输入图像进行中心裁剪,输入图像的默认大小设置为224×224.在所有实验中,使用AdamW优化器[14],权重衰减率设置为10-4,在Cars-196和CUB-200-2001数据集上进行了60代训练,初始学习率设置为10-4,且在训练时对于每一批次的输入图像进行随机抽样.
对于代理点的选择,实验中按照代理NCA[9]中的设置,为每个类指定一个代理,并使用正态分布初始化代理,以确保它们均匀分布在单位超球体上.通过超参数影响实验找到超参数取值α=1.4,m=0.4,T=20.
4.3 对比实验
在两个标准数据集上将本文所提出的RPAL与以下方法进行了比较:Lifted Struct[15],N-pair-mc[16],Clustering[17],Proxy-NCA[9],MS[18],SoftTriple[19],HTL[20],RLL-H[7],Proxy-Anchor[8].使用Recall@K作为损失函数图像检索性能的评价指标,它是由K个最近邻中至少存在一个正确的检索样本来确定的.两个数据集上的对比结果如表1和表2所示.
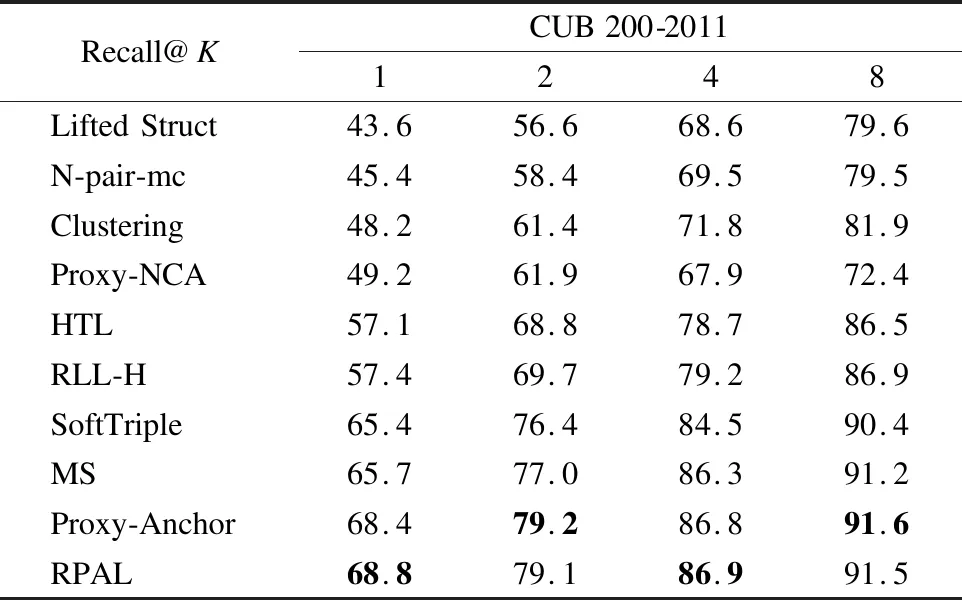
表1 在CUB-200-2011数据集上Recall@K(%)的比较Table 1 Comparison of Recall@K(%)on the CUB 200-2011 datasets
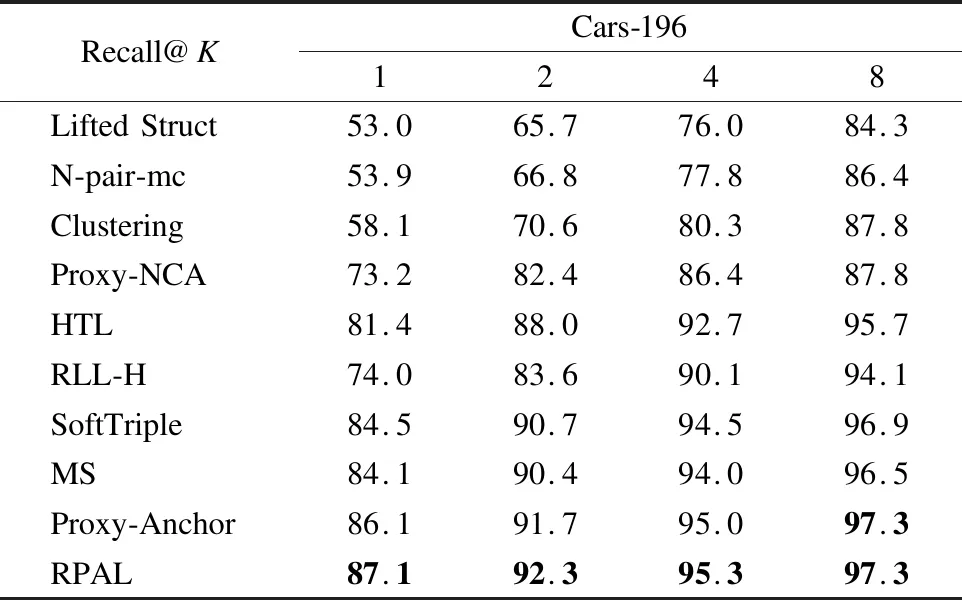
表2 在Cars-196数据集上Recall@K(%)的比较Table 2 Comparison of Recall@K(%)on the Cars-196 datasets
表1和表2展示了本文的方法和其他方法在小数据集(CUB-200-2011和Cars-196)的比较结果.从这两个数据集上的结果来看,本文的方法优于被比较的其他方法,并且在Cars-196数据集上,Recall@1指标提高了1%,这验证了本文所提出的损失函数的有效性.
为了进一步验证RPAL的泛化性能,除了上述使用的BN-Inception网络模型,在实验中还采用了现有深度度量学习方法中较为流行的其他网络架构(GoogleNet[21],ResNet-50[22],ResNet-101[22])作为嵌入网络在Cars-196数据集上进行了训练.实验结果如表3所示,在这3种不同类型的网络架构上RPAL的性能都要优于PAL.

表3 在Cars-196数据集上不同嵌入网络的比较Table 3 Comparison of different embedding networks on the Cars-196 datasets
4.4 超参数的影响实验
4.4.1 样本挖掘超参数的影响
为了研究超参数α的影响,实验中将负样本权重T和边界m设置为:T=20,m=0.4,观察α的不同取值对最终图像分类结果的影响,在Cars-196数据集上进行的实验结果如表4所示.
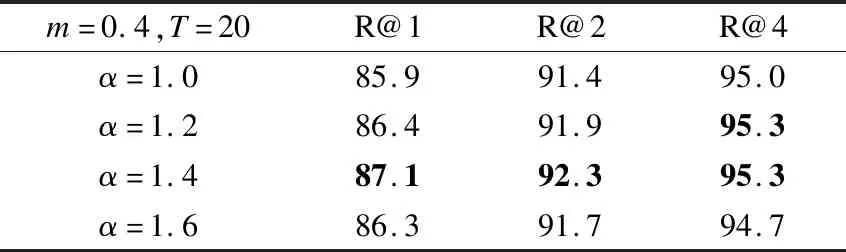
表4 α对图像分类结果的影响Table 4 Impact of α on image classification results
从实验结果可以看出,α对RPAL学习判别嵌入有较大的影响,因为α控制着负样本被推开的程度.
为了分析m的影响,实验中将设置:T=20,α=1.4,观察m的不同取值对最终图像分类结果的影响,在Cars-196数据集上进行的实验结果如表5所示.
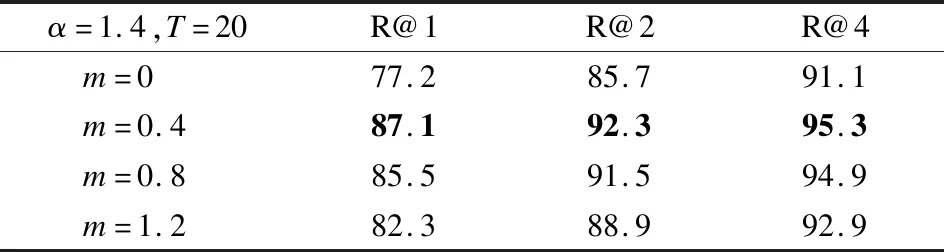
表5 间隔m对图像分类结果的影响Table 5 Impact of margin m on image classification results
从表5中可以观察到当m>0时,RPAL的性能表现要比m=0时提高了10%左右,这说明边界m对于增强RPAL的泛化能力具有重要意义.
4.4.2 负样本权重的影响
在3.1节提出的负样本权重公式(9)中,T是控制对负样本加权程度的参数.通过在Cars-196数据集上进行实验来评估不同的T值对图像分类结果的影响,实验中其他参数设置为:m=0.4,α=1.4,结果如表6所示.
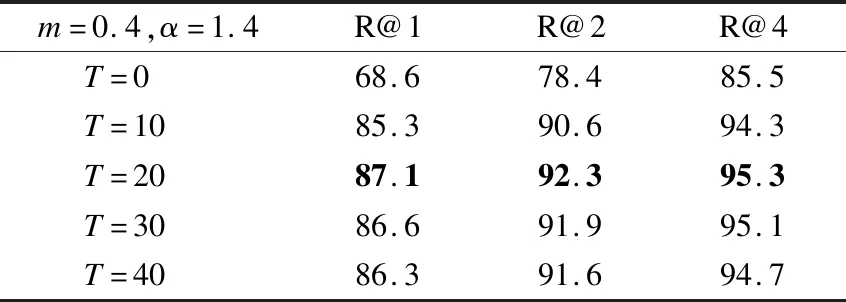
表6 负样本权重T对图像分类结果的影响Table 6 Impact of negative sample weight T on image classification results
从表6中可以观察到当T=0时,因为没有对负例进行加权,Recall@1的结果较差,但当T>0时,RPAL的性能相对稳定,并在T=20时达到最佳.
4.4.3 批量大小的影响
批量大小决定了在每次迭代训练时数据量的大小,这直接影响着挖掘非平凡例子的数量,因此批量大小在深度度量学习中是很重要的.为了研究批量大小对RPAL性能的影响,本节在3个标准数据集上观察不同批量大小时Recall@1指标的变化.结果如表7所示,其中可以观察到,随着批量大小的增加,RPAL的性能逐渐提高,因为更大的批量有利于挖掘出更多的非平凡例子.当批量大小为180时,RPAL达到了最好的性能.
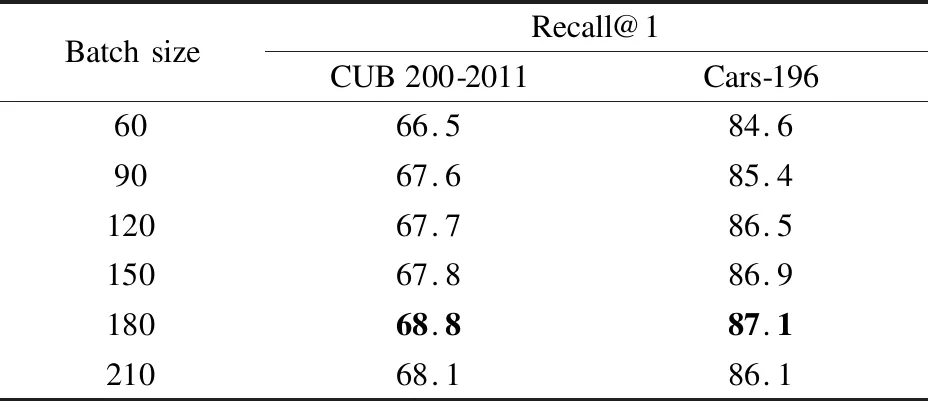
表7 批量大小对图像分类结果的影响Table 7 Impact of batch size on image classification results
5 总 结
本文将RLL和PAL有效地结合在一起,提出一种新的基于代理锚的排序列表损失RPAL.它体现了这两种损失方法的优势,既能够像基于代理的损失一样,实现快速可靠的收敛,且训练的复杂度低,也能够像基于对的排序列表损失一样,考虑类内数据分布,完整保留了类内数据的相似结构.在两个标准数据集的实验结果表明,本文所提出的基于代理锚的排序列表损失的深度度量学习算法具有更好的图像分类性能.
