基于时空特征融合的动态手势识别*
2022-08-04侯莹莹李建军
侯莹莹,李建军
(内蒙古科技大学 信息工程学院,内蒙古 包头 014010)
随着机器视觉、人工智能及虚拟现实技术的日渐成熟,手势识别成为人机交互领域的一个前沿课题和研究热点.由于动态手势识别能够更多、更完整地表达人类所需的语义信息,所以在许多领域有着广泛的应用前景,如手语字母翻译[1],智能家居,游戏手势等.
动态手势的识别和分类仍面临许多困难和挑战,如动态手势可变的时间序列,复杂的空间关系,特征缺失等问题.目前手势识别研究主要基于传统机器学习和深度学习.刘江华等[2]将计算得到的光流场映射在特征空间上,通过映射系数建立手势模板.然而单一的光流特征无法完整描述手部的变化.王贺贺等[3]采集边缘特征点,建立边缘轨迹,之后采用线性SVM进行分类和预测.但这种方法具有算法计算时间长的缺点.谷学静等[4]运用CNN和LSTM的融合网络对采集到的动态手势数据进行分类,该方法易受模型参数影响,需要大量时间匹配合适的模型参数,并且容易丢失手势特征的细节信息.陈国良等[5]在动态手势识别中使用隐马尔可夫模型(HMM)融合,通过体感控制器(Leap Motion)获得手势数据,提取4类手势特征,建立并融合4类特征HMM中的发生概率,最终识别结果为最大概率的手势,该方法对设备要求较高.
针对动态手势的空间可变性和时序复杂性,提出了融合时空特征的动态手势识别方法.对动态手势视频提取关键帧和手势关节点信息.之后基于手势关键帧序列和手势关节点信息,计算表征手势空间关系的角度特征和距离特征,以及反映手势在时序上的变化趋势的轨迹特征.最后对3类特征编码融合,并利用支持向量机(Support Vector Machine, SVM)实现动态手势识别.改进后算法更加完整地描述了动态手势的空间信息和时间信息,在有效提高手势识别效率的同时大大降低了算法运行时间.
1 动态手势视频预处理
基于融合时空特征的动态手势识别方法的整体流程如图1所示.主要包括手势视频预处理、手势特征提取、特征融合及手势识别这3个模块.首先提取视频关键帧并利用OpenPose获取手势关节点信息.之后基于动态手势关键帧和手势关节点信息,计算手势的角度特征,距离特征及轨迹特征.最后融合3类特征并使用Linear SVM实现动态手势识别.
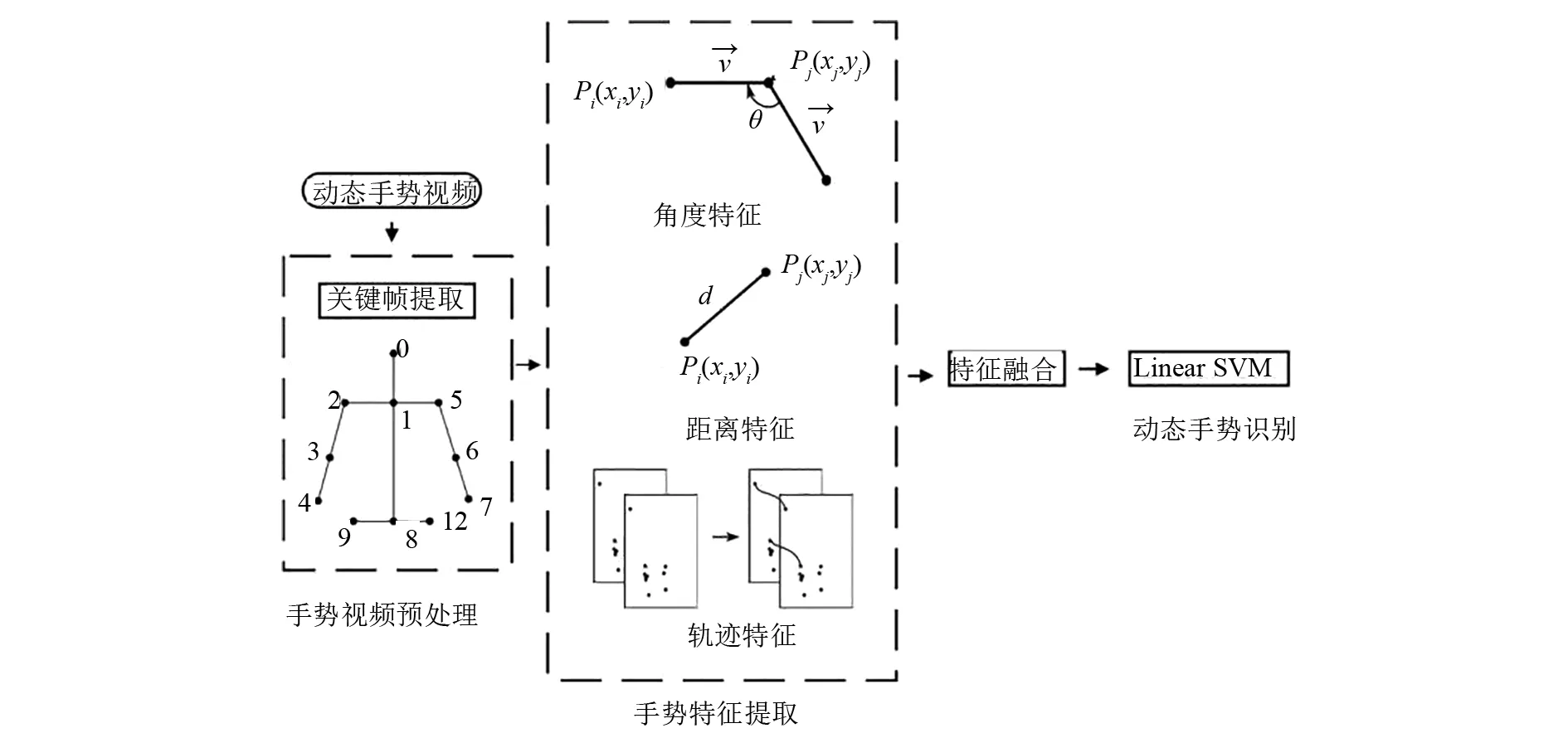
图1 动态手势识别框图
1.1 关键帧提取
整个动态手势序列中许多连续帧是重复或相似的,造成了信息冗余,增加后续模型计算量.针对这一问题采用帧差法提取手势关键帧,以关键帧序列替换原始视频序列[6],有效去除视频序列冗余信息,极大提高了时间效率.算法流程如图2所示.经过关键帧提取后的动态手势序列如图3所示.
1.2 手势关节点提取
通过OpenPose提取动态手势的关节点信息,有效避免了视频中背景,光照,手臂和手掌被衣物遮挡等的干扰,进一步减少了模型计算量.
OpenPose[7]模型基本思想是运用VGG19网络提取图像特征,基于图像特征预测人体关节点位置和关节点之间的空间关系,最后生成骨骼图像.
基于动态手势关键帧序列,运用OpenPose模型提取了与手势动作有关的11个关节点.实验所要提取的11个关节点如图4所示.OpenPose生成的手势骨骼如图5所示.

图2 关键帧提取算法流程

图3 动态手势关键帧序列
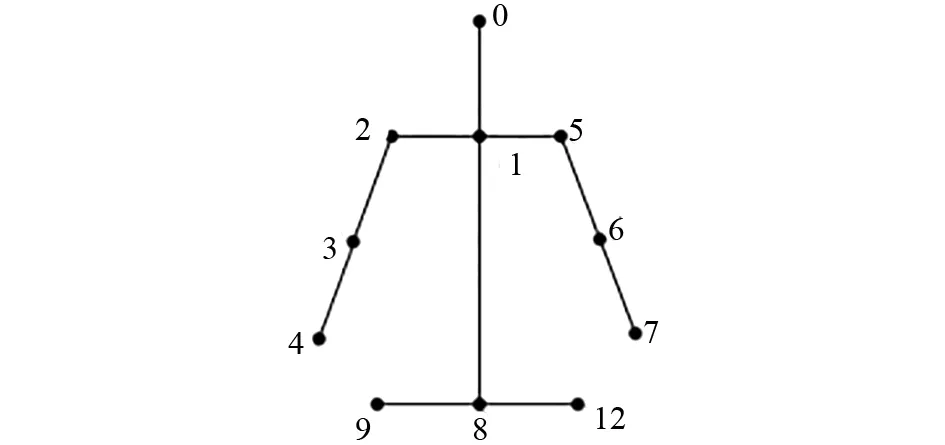
图4 11个手势关节点

图5 手势骨骼
2 手势特征提取及融合
动态手势包含空间信息和时间信息.从空间来看,不同手势导致相邻骨骼之间的夹角及关节点之间的距离有所差别,所以运用角度特征及距离特征描述动态手势的空间关系.从时间来看,不同手势序列导致手势关节点在时序上的变化不同,因此通过轨迹特征来反映手势序列在时间上的变化趋势.空间特征与时间特征相配合,实现动态手势更完整且准确的描述.
2.1 角度特征
基于OpenPose提取到的11个关节点以及相邻骨骼之间所形成的10个角度计算得到手势的角度特征.角度计算示意图如图6所示.

图6 角度特征示意图
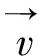
(1)
相邻骨骼之间的夹角θ计算公式为:
(2)
所以,每一帧手势关键帧中计算得到的角度特征描述符为:
Angles=(θ1,θ2,θ3,…,θ10).
(3)
式中:Angles为角度特征;θ1,…,10是由10段骨骼组成的夹角.
2.2 距离特征
随着手势动作的变化,一些关节点间的距离也会发生显著的变化.所以将距离特征与角度特征相配合,以更全面地表述动态手势的空间关系.计算了表征手势动作的7组距离,用作描述符的7组距离如表1所示.
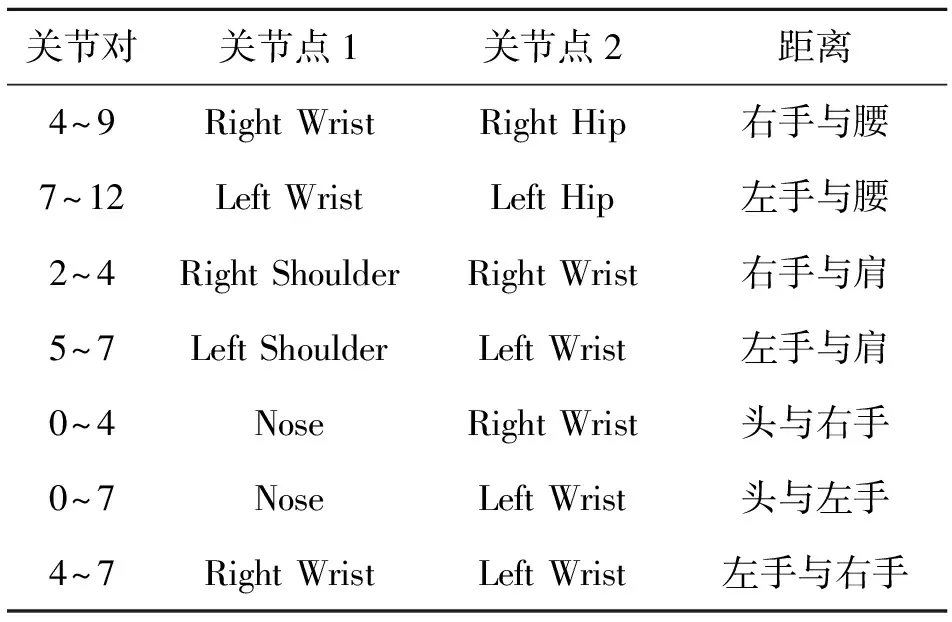
表1 计算的距离特征
距离特征即为计算两关节点之间的欧氏距离,如式(4)所示.
(4)
式中:d为两关节点之间的距离;(xi,yi)和(xj,yj)为关节点坐标.
所以,每一帧手势关键帧计算得到的距离特征描述符为:
Distance=(d1,d2,…,du).
(5)
式中:Distance为距离特征;d1,…,7为7对关节点之间的距离.
2.3轨迹特征
在计算轨迹特征前,首先将10段骨骼参数化为参数空间中的一点(θ,ρ),骨骼运动过程也就转变为参数空间中每一点的运动过程,计算所得的轨迹描述符可以表示更多手势随时间的变化信息[8].参数空间的表达式为:
ρ=xcosθ+ysinθ.
(6)
由式(6)和关节点坐标,可以计算得到θ值:
(7)
式(6)和(7)中:(x,y)为关节点坐标;ρ为骨骼段到坐标原点的距离;θ为x坐标轴与垂直于骨骼的直线之间所形成的夹角.
根据式(6)和θ值计算出ρ值.对10段骨骼依次进行上述计算,就可以实现骨骼到参数空间的映射.骨骼到参数空间的映射如图7所示.

图7 参数空间转换
将骨骼映射到参数空间后,根据参数空间中代表骨骼的点P(θ,ρ)计算轨迹特征描述符.每一点的轨迹可编码为:
T=(ΔPt,……,ΔPt+s-1).
(8)
式中:T为参数空间中每1点运动轨迹序列;S为轨迹长度,实验过程中将S设置为1;ΔPt为参数空间两点之间位置的变化关系,计算公式如式(9)所示.
ΔPt=(Pt+1-Pt)=(ρt+1-ρt,θt+1-θt).
(9)
运用式(10)标准化处理轨迹序列.
(10)
式(9)和(10)中:T′为经过标准化处理的轨迹序列;Pt和Pt+1分别为t时刻、t+1时刻参数空间中代表人体骨骼的点坐标.
对每一帧关键帧的参数空间中的10个点重复上述计算,最终得到轨迹描述符为:
(11)

2.4 手势特征融合及识别
采用特征编码的方式将提取到的角度特征、距离特征和轨迹特征进行融合.常用的特征编码融合方法有特征词袋模型BOF, Fisher向量等方法[9].Fisher向量和词袋模型BOF都是运用聚类算法将特征转换为码本,对视频进行向量表示.但Fisher Vector(FV)算法的核心思想是运用混合高斯模型(Gaussian Mixture Model, GMM)训练码本,提取到的特征用GMM梯度向量表征.相较于BOF模型,Fisher向量不仅反映了每个码本的出现频率,还保留了每个特征在码本上各自的占用概率.因此Fisher向量在视频分类问题上可以表征更加充分的视频特征.选择FV算法对提取到的角度特征,距离特征及轨迹特征进行编码融合,算法流程图如图8所示.具体步骤如下:
(1)提取手势视频的角度特征,距离特征及轨迹特征;
(2)让3类特征描述符符合混合高斯分布,训练出GMM的参数(权重,均值以及方差);
(3)计算特征的占用概率;
(4)计算似然概率的梯度向量,并利用L2进行特征向量归一化;
(5)最终得到角度特征,距离特征和轨迹特征的Fisher向量.

图8 特征融合算法流程图
由于SVM相较于其他机器学习分类算法而言,可以有效避免维数灾难,拥有更好的整体性能和准确率.因此使用线性支持向量机(Linear SVM)对动态手势进行识别分类.
2.5 算法结构
改进的动态手势识别的整体算法流程图如图9所示.
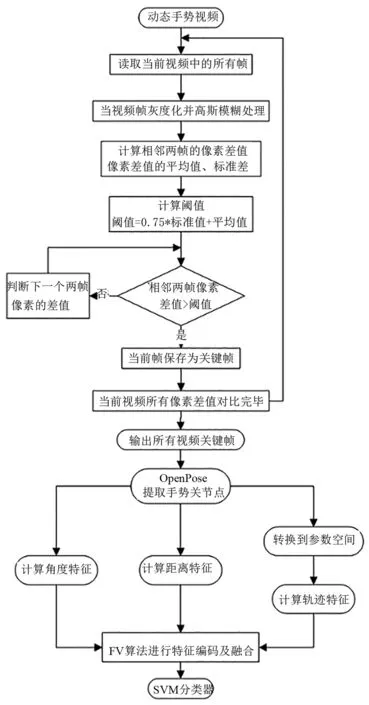
图9 动态手势识别算法流程
3 实验结果及分析
3.1 实验数据集
分别在UTD-MHAD数据集和中国交通警察指挥手势数据集上对算法进行了评估和验证.
动态数据集UTD-MHAD[10]:数据集中包含8位不同的受试者执行的27个不同的动作,每个动作重复4次,共861个RGB视频序列.从中选择了16个手势动作,分别为Wave, Clap, Throw, Arm cross, Draw X, Draw circle (counter clockwise), Boxing, Baseball swing, Tennis swing, Arm curl, Push, Catch, Knock, Draw triangle, Swipe left, Tennis serve,共510个视频序列.
中国交通警察指挥手势数据集[11]:数据集中的视频选取了不同的复杂背景,比如黑板,座椅,树林,来往车辆及行人,附近建筑等.选择多名不同身高及体型的被试者进行录制,且被试者的头部,手臂及手掌均被警帽,警服和白色手套遮挡.包含8个手势动作,分别是Change lane, Go straight, Pull over, Slow down, Stop, Turn left, Turn left to stay, Turn right,共448个视频序列.
3.2 实验结果与分析
实验采用的验证方式为留一交叉验证[12],每一次训练只使用1个样本作验证集,在数据集中按顺序选取,其余样本全部进行训练.所有样本都验证完成后取验证准确率的平均值.对于小规模数据集的试验,留一交叉验证能够实现数据集中样本的充分使用.
在FV算法中,为了建立高斯混合模型,需要提前设置聚类参数K.经过多次试验,匹配到对于动态数据集UTD-MHAD最佳的高斯参数K值为25,对于中国交通警察指挥手势数据集最佳高斯参数K值为20.
UTD-MHAD数据集最终的识别结果采用归一化混淆矩阵表示,如图10所示.

图10 UTD-MHAD数据集的混淆矩阵
由混淆矩阵可以表明,改进后的算法在UTD-MHAD数据集上识别率达96.47%.其中,Draw X和Draw triangle这两个动态手势极易发生混淆.在该数据集上同已有算法进行对比实验,结果如表2所示.

表2 基于UTD-MHAD数据集不同方法的识别率对比
运用文献[8]提出的方法选取15个关节点信息,通过计算角度和轨迹特征对手势进行识别,识别率为89.96%.改进后的算法只使用了和手势动作有关的11个骨骼关节点,并且运用距离特征与角度特征相配合更加完整地描述了动态手势在空间中的变化关系,达到了较理想的识别效果,充分证明该算法的可行性.
中国交通警察指挥手势数据集最终的识别结果采用归一化混淆矩阵表示,如图11所示.
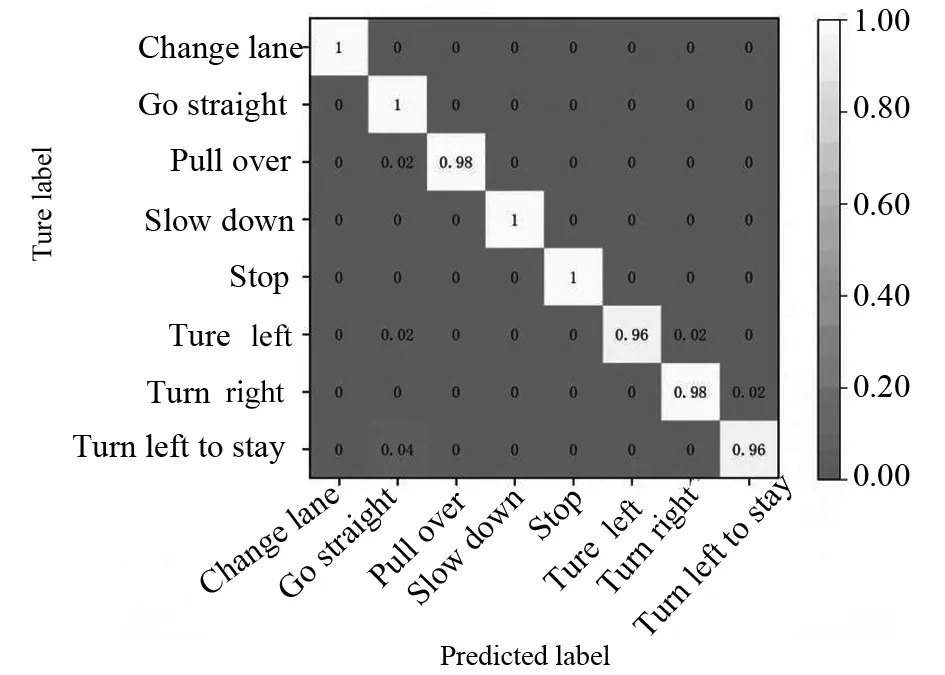
图11 中国交通警察指挥手势数据集的混淆矩阵
由混淆矩阵可以表明,改进后的算法在中国交通警察指挥手势数据集上识别率达98.66%.其中,个别Turn left和Turn right手势发生了混淆.在该数据集上同已有算法进行对比实验,结果如表3所示.

表3 基于中国交通警察指挥手势数据集
从对比实验结果可以看出,改进后的算法取得了较好的实验结果,均高于参考文献其它的算法,并且此算法可以很好地应对数据集中各类复杂视频背景,在手势特征提取过程中很好地避免了手臂及手掌被衣物、手套等遮挡的干扰问题,具有一定的鲁棒性和可行性.
改进后的算法与文献[8]所提算法在运行时间上的对比如表4所示.由对比结果可以表明,改进算法在识别率有较大提升的基础上缩短了2倍的算法运行时间,具有一定的可行性.

表4 改进算法与文献[9]算法在运行时间上的对比
4 结论
文章运用帧差法对动态手势视频进行关键帧提取,之后利用OpenPose获取手势的关节点信息.然后基于动态手势关键帧和手势关节点信息,通过计算角度特征和距离特征以表征手部在空间中的变化,并通过将2D手势编码到参数空间计算其轨迹特征来反映手势在时序上的变化.最后融合3类特征并利用支持向量机实现动态手势识别.改进后的算法在不破坏完整动态手势语义的前提下,极大减少了视频冗余帧、视频复杂背景、光照、被试者手臂及手掌被遮挡等信息的干扰,大大降低了算法运行时间.并且通过空间特征和时间特征的相配合,更加完整且准确的对动态手势进行了描述.因为不同特征对手势识别的鉴别度和描述能力不同,所以目前直接将Fisher向量串联的特征融合算法不能很好地体现各个特征的重要程度.所以在未来的研究工作中,将进一步对空间特征和时间特征的融合算法进行优化,以到达更高识别效果.
