U3+GAN: 基于U-Net3+融合GAN方法对眼底视网膜血管分割的研究
2022-07-07孙顺旺
孙顺旺




摘要:在眼部疾病的自动检测中,视网膜眼底血管分割是不可缺少的一环。视网膜血管结构复杂,粗细血管交织纵横,特别是在沉积物和病变区域,能否高精度地分割视网膜血管的宏观和微观结构对疾病的判定和治疗起着关键的作用。本文提出了一种多尺度对抗生成分割网络模型,用于更加准确的分割视网膜眼底血管。网络的生成器为U-Net3+网络结构,在进行低级语义和高级语义提取后,分别输入两个自编码鉴别器以更好地捕获细粒度的细节和粗粒度的语义,并更加精准的进行微小的毛细血管分割。作为生成性对抗网络,生成器和鉴别器在不断的迭代过程中,可以更好的保存像素级别的宏、微观血管分割结果。在公共数据集 DRIVE上,我们对网络进行了定量评估,并与最新的研究成果进行了比较。该网络能有效地实现难以捉摸的血管分割,在特异性、准确率和精确率方面都在比较高的水平。U3+GAN架构的性能和计算效率在临床视网膜血管分割应用存在巨大的潜力。
关键词:眼底视网膜血管分割、深度学习、多尺度对抗网络、U-Net3+、医学影像分析
引言
近年来,随着电子设备的普及,伴随而来的也有越来越多的眼部疾病,视网膜血管提供了丰富的几何特征,如血管直径、分支和分布关系等。这些特征反映临床病理,可以用于诊断高血压、糖尿病视网膜病变、黄斑水肿和巨细胞病毒性视网膜炎(Cytomegalovirus Retinitis[1]) [2,3]。但是,通过手工分割血管耗时耗力,血管自动分割在医学诊断过程中起着越来越重要的作用。在深度图像处理浪潮中,相比传统自动分割算法,深度学习有很大优势,在改善血管分割性能方面也有了新的提升,基于深度图像的眼底血管分割的应用,在临床方面有很好的应用场景,吸引着许多科研人员的关注。
迄今,已經出现了许多机器学习在眼底视网膜血管分割方面的应用,主流的方法包括K近邻分类器(KNN)与支持向量机(SVM),其大多数都是基于手工分类的方。像这样的经典机械学习分类方法只能针对特定场景进行设定分类模型,不能学习新的特征,在适应新的眼底图片的性能上,泛化能力较差。近些年来,基于U-Net的网络架构的视网膜血管分割应用比较广泛。U-Net 由捕获上下文信息的编码器和实现精确定位的解码器组成,因此也衍生出许多作品,如Deformable-UNet, IterNet和最近的SA-UNet等等。这些架构在宏观分割上可以取得更好的效果,然而,在提升更高精度和细小分割时,他们的效果不太理想。最近,李兰兰等人的相关研究表明GAN系列架构用于视网膜血管分割是很好的选择。
GAN网络是由生成器(G网络)与鉴别器(D网络)组成,G和D构成了一个动态的“博弈过程”。在图像分割领域,GAN网络模型的G网络用来分割,而D网络用来进行对G网络生成出的分割图片进行鉴别校正。本文提出一种新的GAN网络模型来进行眼底血管的分割,网络的主要基于图1的RV-GAN[2]架构。在此基础上,我们改变了生成器(G网络)的整体架构,并采用最新的分割网络U-Net3+[15]作为基础的G网络,同时,我们保留了RV-GAN的多尺度鉴别器(D网络)以及Loss损失函数,我们把此网络命名为“U3+GAN”(如图2 RV-GAN网络结构)。此网络结构既保证了U网络宏观上血管分割的精度,也可以让GAN架构实现更细致、更高精度的微小血管分割。
本文章的主要工作总结如下:首先,我们提出了一种深度对抗网络模型,利用对抗原则通过D网络进行监督筛选,以此增强G网络(即U-Net3+[15])的分割能力,并且D网络是基于多尺度输入融合的两个U型网络组成,它与G网络同为U形结构,形成了一个对称结构,使G网络和D网络拥有同等对抗的能力,从而使G网络可以更加细致地分割血管细节,提高对细小血管的分割精度。其次,U3+GAN利用U-Net3+的网络全尺度融合架构,其G网络可以提取出大量细粒度的细节和粗粒度的语义,随后传入到D网络之中进行细致的多尺度鉴别,通过匹配相应的加权损失函数,进行梯度下降,降低损失并提高精度。最后,我们通过大量的实验,验证了网络的有效性。
1方法
本文从最近的眼底视网膜血管分割研究中,受到V-GAN、RV-GAN和U-Net3+的启发,我们通过融合了U-Net3+与RV-GAN的网络模型,提出了一种新的U3+GAN架构。在本小结中,我们将重点介绍此方案的一些实现细节,如图2,我们的GAN网络模型有两个主干网络,分别为生成分割图像的G网络(Generator)和拥有鉴别监督功能的D网络(Discriminator)。G网络基于U-Net3+框架实现,D网络基于RV-GAN的多尺度编解码U形D网络来实现,我们将他们组合并加以改进,获得了很好的分割结果。
1.1生成器(G网络)
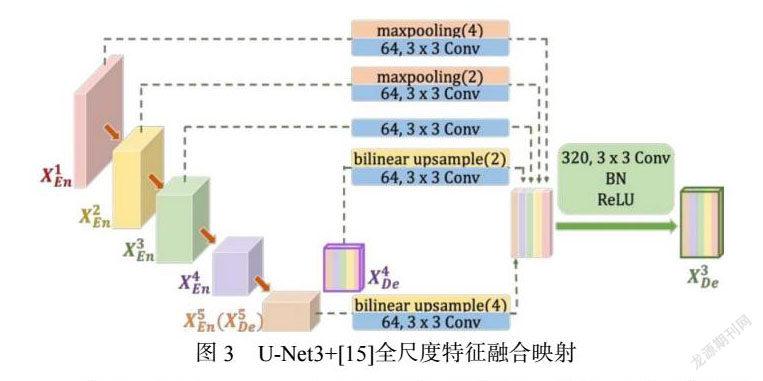
U-Net3+提出了全尺度跳跃连接,使每一个解码器都融合了来自编码器中的小尺度,同尺度以及大尺度的特征图,从而获得全尺度下的细粒度语义和粗粒度语义。
如图3(来自U-Net3+)所示,第三层解码器![]() 是由底层解码器(Decoder)的特征图和所有的编码器(Encoder)特征图融合而成,在中间部分,此网络做了最大池化缩小编码器
是由底层解码器(Decoder)的特征图和所有的编码器(Encoder)特征图融合而成,在中间部分,此网络做了最大池化缩小编码器![]() 和
和![]() 的特征图分辨率,编码器最下两层
的特征图分辨率,编码器最下两层![]() 和
和![]() 的特征图通过双线性插值上采用,从而扩大分辨率。在统一了特征图分辨率之后,它又进行了U-Net式的通道维度拼接融合,得到了320个通道的特征图,最后通过3
的特征图通过双线性插值上采用,从而扩大分辨率。在统一了特征图分辨率之后,它又进行了U-Net式的通道维度拼接融合,得到了320个通道的特征图,最后通过3![]() 3卷积、BN和ReLU操作的得到了
3卷积、BN和ReLU操作的得到了![]() 的图像。
的图像。
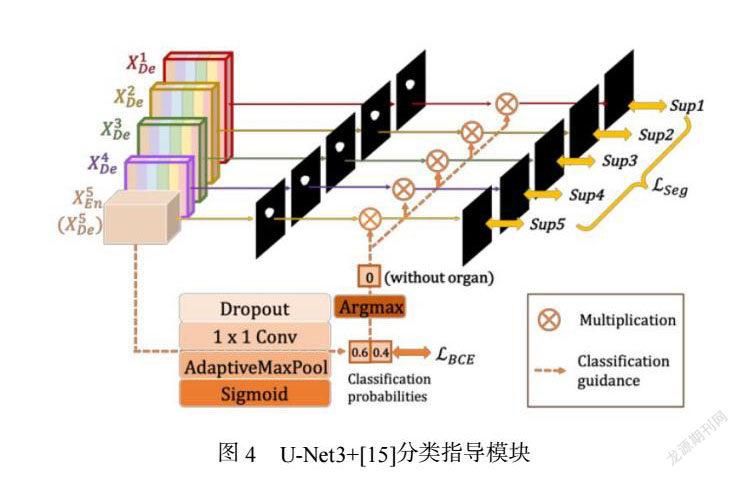
在研究医学影像分割方面,U-Net3+引入了深度监督(Deep supervision)和特定的损失函数,精细的捕获大尺度和精细结构的界限;并结合如图4的分类指导模块(CGM)限制了过度分割,很大程度提升了分割的性能。在训练时候U-Net3+比U-Net++拥有更少的参数,在此诸多优点的基础上,我们参考V-GAN中以U-Net架构实现G网络,使用U-Net3+网络作为我们GAN网络模型的生成器(G网络),因此它拥有全尺度融合的特点,不但可以通过编码器提取一些局部微小的血管特征,例如:微小分支,微型毛细血管和堵塞信息等,也可以通过解码器学习到全局的粗粒度语,例如:动脉血管,静脉血管大体位置与结构。
1.2鉴别器(D网络)
对于D网络,为了使生成器具有更精准的提取信息能力,我们结合RV-GAN提出的多尺度U型的鉴别器,这样使U3+GAN既具有了多尺度融合信息的特点,也具备了和G网络有同等对抗能力的U型网络。在D网络输入的图像中,我们分别将G网络生成的高层语义信息及较低层的特征信息传入D网络的两个鉴别器当中。对于传入的底层信息我们通过MaxPooling2D模块进行下采样缩小图像分辨率,更好的提取底层信息,然后通过3X3卷积滤波模块,最后通过Activation模块进行tanh处理得到底层D网络的输入图片,用于帮助对抗网络的学习训练。我们将这两个鉴别器分别定义为![]() 和
和![]() ,如图2中的Discriminator架构部分所示。
,如图2中的Discriminator架构部分所示。
1.3整体和局部损失函数
在鉴别器网络中,我们发现RV-GAN基于Patch-GAN[16]提出的多尺度编解码鉴别器的损失有很多优点,为此我们根据他们的不同编解码损失构建了自己的D网络损失函数,每一个编码器和解码器提取出来的特征,都有一定的权重,介于[0:1]之间,并且总和为1,通过公式(1)和公式(2)进行计算。
2实验(Experiments)
2.1 数据集
我们的模型是基于TensorFlow2.0来实现的,数据集为DRIVE[19],图像尺寸为TIF(565,584)。依据RV-GAN对数据集的处理方法,我们使用数据集中的每 5 倍交叉验证来训练U3+GAN 网络。并使用重叠的图像补丁,步幅为 32,图像大小为(128,128),用于训练学习和验证。最后,我们得到了来自DRIVE 数据集16 张图片尺寸为(20,20)的 4200张图片,DRIVE 数据集带有用于测试图像的官方 FoV 掩码,使得实验效率更高。
2.2 超参数设置
对于U3+GAN训练,我们使用Hinge loss[17,18]。我们选择了![]() =0.5和
=0.5和![]() =0.5(公式(1),公式(2))、
=0.5(公式(1),公式(2))、 ![]() =10(公式(5)),
=10(公式(5)),![]() =10(公式(6)),
=10(公式(6)),![]() =10(公式(7)),并使用学习速率
=10(公式(7)),并使用学习速率 ![]() = 0.0002,
= 0.0002,![]() = 0.5 和,
= 0.5 和,![]() = 0.999為Adam 优化器 [20]。对生成器和鉴别器进行 100 次迭代,批量大小为8的训练。最后,我们在 RTX2070 GPU 上训练U3+GAN模型,耗时36个小时。
= 0.999為Adam 优化器 [20]。对生成器和鉴别器进行 100 次迭代,批量大小为8的训练。最后,我们在 RTX2070 GPU 上训练U3+GAN模型,耗时36个小时。
2.3 评价指标
以二分类为例,评价指标如表1所示:
在表2中,我们和近年来一些较好的架构进行了比较,从较早的Azzopardi[21]等人提出的分割模型,到现在YANG[28]提出的级联结构+多任务分割+融合网络模型,在多种指标的对比中,我们在SP、PR、ACC上面获得了较好的性能。虽然我们SE指标较低,分数为0.7025,但是在SP指标上我们获得了0.9918的分数,已经领先了现有的大部分架构。GAN 网络的鉴别器可以鉴别生成器生成的分割图片与真实图片的不同,和其他的U型网络相比多了一个校正错误的老师,所以会表现出更好的性能,因此我们认为将GAN架构的网络用在眼底视网膜血管分割上是很有潜力的研究方向。
如上图5、6所示,我们的模型与不同的网络进行了对比,图5中,局部图片为使用32步重叠补丁的第69与104步图片;图6中局部图片为相同步重叠补丁的35与100步图片,图片大小为(128,128)。从上两图中可以看出,对于单独的编解码U-Net模型(U-Net模型来自Github),U-Net提取的信息比较粗糙,虽然宏观上可以较好的分割视网膜血管,但是在局部更加细微的结构上分割的比较模糊,并且带有很多的噪音。对于SA-UNet来说,在细节的分割方面出现了比金标准更多的毛细血管分支,并且血管交织部分并没有精细的分割出来。而GAN网络具有更加优异的表现,GAN网络拥有一个鉴别器,可以更好的校验生成器的分割结果,在图的GAN分割图中,可以看出我们的表现与RV-GAN网络架构不相上下。另外由于本文的G网络结合了U-Net3+全尺度融合的方法,可以更好的提取粗粒度的宏观特征与细粒度的微观细节特征,所以此网络相对拥有更好的分割准确率,相比U-Net的架构,我们对于毛细血管与动脉的粗血管有更精准的分割,比如分支、重叠、连续细小的部分血管。本文结构与RV-GAN在测试集(图5)上分割结果上相差不大,仅有一些细小的分支血管没有分割清晰;并且我们发现RV-GAN返回原来的训练集上测试,反而结果没有预期的精确,在图7中的最后两幅分割图,我们可以看出在一些细小的分支结构和连续毛细血管,RV-GAN均出现了未分割与分割间断的情况,U3+GAN具有一定的优势性。综合各项评价指标,结果表明本文的U3+GAN模型能够更好地提取毛细血管和树状结构,并且对于宏观粗血管也可以更精准的分割,其分割结果比其他模型更为理想。
3结论
在这项工作中,我们提出了一种基于GAN框架的视网膜眼底血管分割的方法,该方法结合了U-Net3+和RVGAN的多尺度D网络以更好地捕获细粒度的细节和粗粒度的语义。实验结果表明,此模型网络可以更精准的分割眼底视网膜血管,在SP、PR、ACC的指标上获得了更高的得分。在研究中我们发现,针对GAN架构网络结合对Loss函数的改进在图像分割领域拥有更大的潜力。最后,为了更有效的将这种框架应用到视网膜血管分割的实验中,我们希望可以让此框架可以拓展到其他数据集中,并且可以用来分割眼底视网膜产生的异物与病变区域。
参考文献
[1]Son J , Park S J , Jung K H . Retinal Vessel Segmentation in Fundoscopic Images with Generative Adversarial Networks[J]. 2017.
[2]Kamran S A , Hossain K F , Tavakkoli A , et al. RV-GAN: Segmenting Retinal Vascular Structure in Fundus Photographs using a Novel Multi-scale Generative Adversarial Network[J]. arXiv e-prints, 2021.
[3]Chen C, Chuah JH, Raza A, Wang Y. Retinal vessel segmentation using deep learning: a review. IEEE Access. 2021 Aug 3.
[4]Soares JV, Leandro JJ, Cesar RM, Jelinek HF, Cree MJ. Retinal vessel segmentation using the 2-D Gabor wavelet and supervised classification. IEEE Transactions on medical Imaging. 2006 Aug 21;25(9):1214-22.
[5]李蘭兰, 张孝辉, 牛得草, 胡益煌, 赵铁松, 王大彪. 深度学习在视网膜血管分割上的研究进展. 计算机科学与探索. 2021 Jun 17;15(11):2063-76.
