基于对抗网络的声纹识别域迁移算法
2022-04-29季敏飞
季敏飞, 陈 宁
( 华东理工大学信息科学与工程学院,上海 200237)
声纹识别作为身份验证的一种手段,已经广泛应用于实际生活中。但在大多数的实际应用场景中,由于实际应用数据与训练数据在内部特征(例如情感、语言[1]、说话风格、年龄等)或者外部特征 (例如背景噪声、传输信道、麦克风、室内混响等)上存在的差异,导致训练的模型在实际应用场景下的性能大幅下降。同时由于实际场景中数据相对匮乏,无法获得可用于模型训练的足够数据对模型进行重新训练,因此,如何对原有的模型进行域迁移使其在目标域上达到较好的效果成为一个重要的问题。
为了解决以上问题,研究人员提出了许多适合声纹识别的域迁移方法。以在I-Vector[2]声纹识别模型的域迁移为例,文献[3]首先在I-Vector 模型基础上探讨了域不匹配的问题,然后采用了一些聚类方法来解决该问题。文献[4]在文献[3]基础上提出了基于PLDA (Probabilistic Linear Discriminant Analysis)的I-Vector 声纹识别模型域迁移框架,通过使用一个域外的PLDA 判别模型去归类域内数据,再根据这些数据重新调整PLDA 判别器的参数。文献[5]使用DICN 技术将域内、域外数据重新映射到第3 个空间,并通过使用一小部分域内数据提升PLDA判别器的效果。文献[6]提出了一个无监督的域迁移方法,通过调整域内、域外之间的协方差来解决域不适配的问题。文献[7]提出了基于 COR relation Alignment(CORAL)的域迁移方法,通过对齐两个域之间的二阶统计量来实现域迁移, 并且不需要任何标签。在此基础上,文献[8]将CORAL 域迁移技术应用到基于I-Vector 以及X-Vector[9-10]的声纹识别模型,得到CORAL+模型。
最近,基于深度学习的域迁移算法成为新的研究热点。文献[11]运用mix-PLDA 和TBC-PLDA 来提升系统的鲁棒性。文献[12]提出了一个新的端到端域迁移方法,通过引入对抗损失来解决声纹识别中语言不匹配的问题。文献[13]同样借助对抗思想,通过DANN 的方法来实现声纹识别的域迁移。
在文献[14]中,研究人员首次引入生成对抗网络(Generative Adversarial Network, GAN)来解决声音场景分类 (Acoustic Scene Classification, ASC) 任务中域不匹配的问题,利用少量目标域数据来调整网络模型,提高模型在未知数据集上的分类准确率。本文对文献[14]提出的用于声音场景分类的域迁移算法进行了研究和改进,并将其应用到基于XVector 的声纹识别模型的域迁移上。声纹识别任务与文献[14]中的声音场景分类任务存在较大的差异,主要表现为:(1)文献[14]中声音场景分类任务中源域和目标域的标签类别是保持不变的,而在声纹识别任务中,由于源域和目标域的说话人不同,因此分类的标签也发生了变化;(2)与声学场景分类任务相比,声纹识别任务中类的个数多了很多,这就加大了分类的难度;(3)文献[14]的实验中,源域数据和目标域数据的差异主要来自于录制设备、采样频率等,而在本文的实验中,源域数据和目标域数据存在说话人、语种、环境以及噪声等多方面的不同,差异更大。为了适应新的任务,本文对文献[14]提出的迁移模型进行了两方面改进:首先,重新设计鉴别器网络结构以便适合声纹识别任务;其次,在迁移后为了确保特征提取模型在说话人分类中的性能不下降,使用源域标注样本对特征提取模块进行调整。
1 算法模型
1.1 X-Vector 特征向量提取方法
X-Vector 特征向量提取模型框图如图1 所示。该模型以梅尔倒谱系数 (Mei-Frequency Cepstrum Coefficient, MFCC)为输入,由时延神经网络(Time Delay Neural Network, TDNN)、统计池化层和全连接层组成。其中TDNN 主要用于提取语音所包含的时序特性;统计池化层的作用是将整个时序特征进行聚合。该模型训练完成后,取第一个全连接层的输出作为X-Vector 特征向量。

图1 X-Vector 模型框图Fig. 1 Block diagram of X-Vector model
1.2 迁移模型
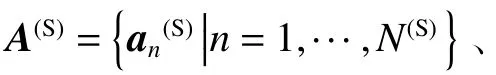

图2 GAN-DASV 模型框图Fig. 2 Block diagram of GAN-DASV model
将已经在源域A(S)上训练好的特征提取模型E(S)对目标域训练数据A(T1)进行迁移学习,从而获取更适合目标域的特征提取模型E(T)。迁移后的模型性能将在目标域测试集A(T2)上进行测试。算法主要分为3 个步骤,其中域迁移过程不需要目标域训练集标签。
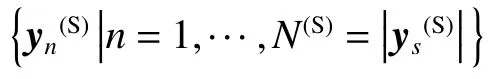

其中,C为说话人分类器。
1.2.2 从源域到目标域的迁移 如图2(b)所示,在源域到目标域的迁移阶段,将在源域A(S)上训练好的模型E(S)迁移至目标域数据集A(T)。
首先,采用E(S)的参数对目标域特征提取模型E(T)进行初始化,并采用随机初始化的方法对鉴别器D进行初始化。然后,采用生成对抗网络[15]的训练思想,将E(T)和D分别看成是生成对抗网络中的生成器和鉴别器,并对它们进行交替训练,使E(T)(A(T1))和E(S)(A(S))的数据分布尽可能相似。其中鉴别器D用于区分输入的E(S)(A(S))或E(T)(A(T1))来自于源域还是目标域。而目标域特征提取模型E(T)则用于混淆鉴别器的判断,使其无法分辨E(T)(A(T1))究竟来自于源域还是目标域。在此过程中用于训练的D和E(T)的损失函数L(D)和L(E(T)) 分别如式(2)和式(3)所示。

在每次D和E(T)交替训练的过程中,为了保证不降低E(T)提取说话人特征的能力,将源域数据A(S)输入新的E(T)和C,进行说话人类别分类的训练,这也是本文对文献[14]的一种改进。除此之外,为了减少模型训练过程中的震荡,参照文献[16]的方法,将鉴别器的输入进行调整,将历史数据与最新数据进行混合作为其输入。
1.2.3 迁移模型测试 如图2(c)中所示,在测试阶段,采用迁移学习获得的X-Vector 模型E(T)提取目标域测试集A(T2)中样本的特征,并采用基于PLDA或余弦评分(Cosine Distance Scoring, CDS) 算法对其进行打分。
2 实验过程
实验阶段的主要任务是验证本文提出的模型从源域到目标域上迁移的可行性。为了模拟实际场景中目标域数据集不足的情况,实验中选取的目标域数据集的大小将远远小于源域数据的大小。同时,实验中X-Vector 通过PyTorch 来实现,而PLDA 鉴别器则采用了Kaldi 上提供的程序。
2.1 数据库
实验采用 AISHELL1[17]为源域数据集,VoxCeleb1[18]和CN-Celeb[19]为目标域数据集。
AISHELL1 是希尔贝壳公司提供的开源中文普通话语音数据集,它包含了178 h 的录音,由400 个说话人构成。在实验中,为了更好地显示本文算法的迁移效果,只采用了源数据集一半的样本,由随机挑选的来自于340 个说话人的50 000 条语音片段组成。
VoxCeleb1 数据集包含了取自YouTube 的1 251个说话人超过100 000 条语音片段。实验随机选取了VoxCeleb1 训练集中的3 400 个语音片段构成目标域训练集,将VoxCeleb1 的测试集作为目标域测试集。
CN-Celeb 是由清华大学提供的开源的中文普通话语音数据库。它包含1 000 位中国名人的130 000条语音片段、11 种语音题材,共计274 h。同样从CN-Celeb 提供的训练集上随机选取了2 500 条数据作为目标域训练集,并将该数据集的测试集作为本实验的测试集。
VoxCeleb1 和CN-Celeb 被选为目标域数据集的原因是它们与源域数据集存在如下差异:
(1) VoxCeleb1 与AISHELL1 之间的语言不同,前者为英语,后者为普通话。
(2) CN-Celeb 与AISHELL1 相比,CN-Celeb 为非约束数据集,其包含如娱乐、访问、直播等场景,在声纹识别任务上更具挑战性。
(3) 无论是VoxCeleb1 还是CN-Celeb,其信噪比都小于AISHELL1。
2.2 模型参数的设置
实验中,将输入的音频分为长度为25 ms 的语音帧,并提取每帧语音的23 维梅尔倒谱系数作为XVector 模型的输入。X-Vector 和鉴别器的网络结构分别如表1、表2 所示。将X-Vector 网络中第1 个全连接层的输出作为鉴别器的输入,采用 Adam 优化器[20],批次大小和学习率分别设置为128 和0.001。将得到的模型在目标域测试数据集A(T2)上进行测试来验证它的性能。
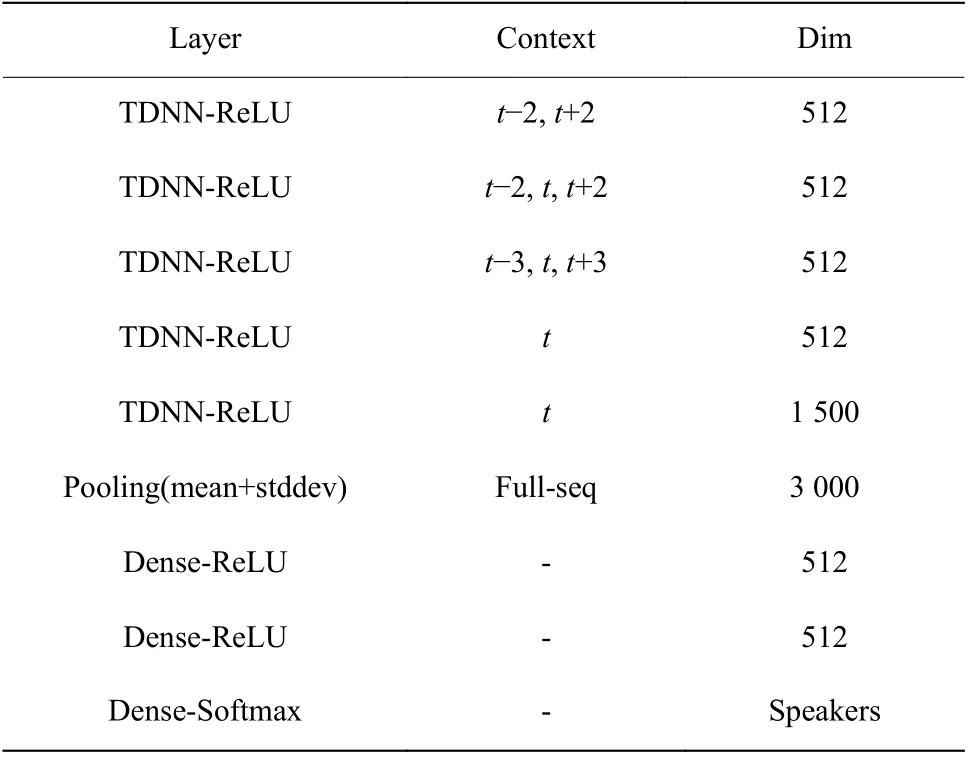
表1 X-Vector 网络结构Table 1 Network structure of X-Vector model

表2 鉴别器网络结构Table 2 Network structure of discriminator
2.3 实验结果
2.3.1 迁移前后性能对比 分别采用基于PLDA 和余弦评分(Cosine Distance Scoring, CDS)的打分方式对输出的X-Vector 特征向量进行打分。其中,基于PLDA 的打分方式具有很好的信道补偿能力,而基于CDS 的打分方式能更直观地观察到迁移对模型性能提升的效果。在迁移前后用于训练PLDA 的数据分别为迁移前后目标域训练数据集上提取的XVector 特征向量,实验结果如表3 所示。可以看出,在目标域测试集上,无论选用PLDA 还是CDS 的打分方式,本文提出的域迁移算法均可有效降低声纹识别的等错误率(Equal Error Rate, EER)。以基于PLDA 的打分方式为例,经过域迁移后,在VoxCeleb1和CN-Celeb 目标域测试集上,EER 分别下降了21.46%和19.24%。EER 越小模型性能越好。
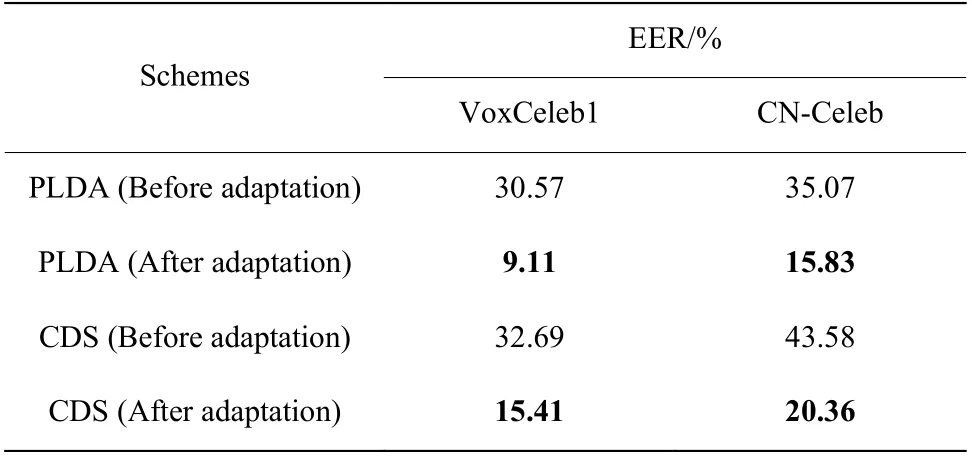
表3 迁移前后性能对比Table 3 Performance comparison before and after domain adaptation
2.3.2 与传统迁移方法性能对比 为验证本文方法的优越性,将本文方法与基于DANN[21]的迁移方法进行对比,结果分别如表4 和图3 所示。分别采用EER、最小检测代价(Minimum Detection Cost Function,DCF)、拒识率曲线(Detection Error Tradeoff, DET)作为衡量指标,其中DET 曲线越靠近左下角,表明性能越好。表4 和图3所示的实验结果表明,在两个目标域测试集上,本文方法的3 种衡量指标均优于基于DANN 的域迁移算法。

表4 本文算法与DANN 算法对比Table 4 Performance comparison between this paper and DANN

图3 域迁移前后DET 曲线对比Fig. 3 DET Curves comparison before and after domain adaptation
3 结束语
本文提出了一种面向声纹识别域迁移的模型。该模型可利用少量的无标签目标域样本实现域迁移学习。与迁移前相比,可在VoxCeleb1 和CN-Celeb数据集上实现21.46%和19.24%的EER 的提升。
将来,我们还会尝试引入新的生成对抗网络,如CycleGan,进行相关研究,以进一步提升模型的性能。
