可迁移测度准则下的协变量偏移修正多源集成方法
2015-08-17杨兴明吴克伟孙永宣
杨兴明 吴克伟 孙永宣 谢 昭
(合肥工业大学计算机与信息学院 合肥 230009)
可迁移测度准则下的协变量偏移修正多源集成方法
杨兴明 吴克伟 孙永宣 谢 昭*
(合肥工业大学计算机与信息学院 合肥 230009)
迁移学习通过充分利用源域共享知识,实现对目标域的小样本问题求解,然而,对训练和测试样本分布差异测度仍然是该领域的主要挑战。该文针对多源迁移学习算法中,由于源域选择和源域辅助样本选择不当引起的“负迁移”问题进行研究,提出一种可迁移测度准则下的协变量偏移修正多源集成方法。首先,根据源域和目标域之间的协变量偏移原则,利用联合概率的密度估计,定义辅助样本的可迁移测度,验证目标域和源域在数据空间中标记分布的一致性。其次,在多源域选择阶段,引入非迁移判别过程,提高了源域知识的迁移准确性。最后,在Caltech 256数据集中,验证了Gist特征知识表示和迁移的有效性,分析了多种条件下的辅助样本选择和源域选择的有效性。实验结果表明所提算法可有效降低“负迁移”现象的发生,获得更好的迁移学习性能。
集成学习;迁移学习;协变量偏移;图像分类
1 引言
传统机器学习方法在训练样本有限的情况下,难以有效描述特定类别的数据空间分布。迁移学习通过利用与目标任务相关的大量辅助样本,弥补训练样本不足,实现了不同领域和任务之间的知识共享、样本传播和再利用[1,2]。在迁移学习中将目标任务所在的领域称作目标域,把与当前任务不同但存在相关性的领域称作源域,迁移学习利用源域数据作为目标域任务的辅助样本,实现知识由源域到目标域的迁移[3]。迁移学习的难点在于迁移知识选择不当而引起的目标域任务性能降低的“负迁移”效应,即关注于共享知识选择的度量。当前研究根据共享知识策略的不同,大致可以分为实例层迁移、特征层迁移和模型层迁移。
实例层将待分类样本作为研究对象,描述其可能具有的共享知识。实例层迁移通过分析不同类别样本之间的关联特性,利用源域辅助样本扩充目标域实例的标记,实现异类小样本分类。实例层的度量关注于辅助样本的可迁移程度[4]与差异程度[5]、源域和目标域的相容性[6]与相关性(如类间相关性[7],视角相关性[8],帧间相关性[9])。实例层迁移还涉及多模态数据的应用场合,例如,跨域的标签传播[10]以及人脸识别[11]等问题。
特征层迁移通过构建有效的特征变换,提取样本中的抽象表示作为迁移知识载体。特征层的度量体现在目标域样本和源域样本的分布差异性,并期望通过特征映射实现分布差异的最小化。特征层的研究关注于利用稀疏学习[12,13]、层次分组[14]方法实现源域与目标域之间特征提取,并尝试获得特征空间的若干属性(如稀疏性[15]、可分解性[15]、几何流形[3])。此外,通过加入正则约束[16],防止迁移特征的学习过程中的过拟合现象的发生,提高迁移学习方法的执行效率。
模型层将不同分类方法中的控制参数作为共享知识对象,通过对数据分布建模,实现两域分布差异的度量。模型层研究关注于源域和目标域分类建模的可靠性(如基分类器[17],有序分类器[18],L2核分类器[19],条件与边缘概率[20])。模型层方法通过引入数据分布先验作为多级评价过程,确保迁移过程在不同级别下误差的有限积累[21,22],从而达到提高迁移精度的目的。
上述不同方法都将目标域和源域间的数据分布估计视为可靠的迁移先验信息[23]。但是,多源TrAdaboost[24,25]作为实例层的代表性方法,却没有对数据分布进行充分估计。此外,多源TrAdaboost方法在源域类别选择过程中,每轮学习对每个源域类别都进行一次目标域的“试迁移”,该过程没有考虑源域类别引入,是否会直接引起“负迁移”效应。
因此,本文重点关注实例多源TrAdaboost迁移学习对该问题分析的不足,通过考虑目标域和源域样本分布间的差异性,利用协变量偏移测量样本可迁移能力,调整样本权重更新策略,以反映数据分布估计对样本选择的影响。并根据源域类别的可迁移能力,引入源域非迁移选择过程,重新设计基于协变量偏移修正的迁移损失估计方法,提高迁移学习方法的执行效率。实验结果表明,本文算法能有效降低“负迁移”的发生,在有限样本下的图像分类任务中,获得更好的分类性能。
2 多源Adaboost集成迁移学习
Adaboost集成迁移(即 TrAdaboost)[25]采用Adaboost集成学习框架[6]。TrAdaboost算法放宽了原始Adaboost算法受限于训练与测试数据同分布的约束限制。TrAdaboost算法的迁移能力大小主要取决于该源域与目标域的关联程度,因此,仅依赖单个源域进行迁移的TrAdaboost算法,本质上易造成“负迁移”现象。为降低“负迁移”风险,通常可将单源域迁移过程扩展至多源域,从多个源域向目标域进行知识的迁移,即多源迁移学习,如多源TrAdaboost[4]。
在迁移学习分类任务中,假设样本数据空间为X,样本标记空间为 Y∈{- 1 ,+1}(这里举例二值情况)。定义目标域T,该域包含少量有标记的训练样本集合 DT和用于模型测试的无标记样本集合DTEST,数据均服从概率分布 PT。定义 K个源域S1,S2,…, SK,各源域包含标记数据 DS1,DS2,…, DSK,均服从概率分布 PSk。多源TrAdaboost通过合理利用源域辅助学习,获得目标域上的分类模型 fT/S: X → Y,并尽可能地减小其经验误差。

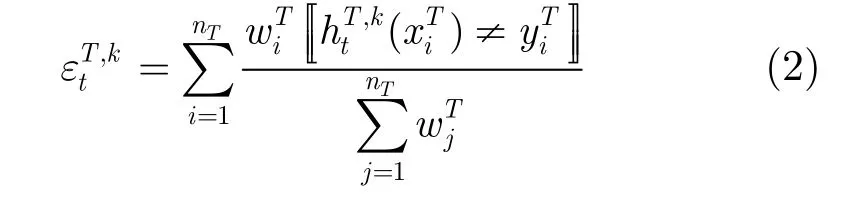
其中〚·〛为指示函数,当内部条件为真时,返回值为1,否则返回值为0。
多源TrAdaboost在每一轮学习中,根据最小损失选出该轮(第t轮)的优胜源域和优胜分类器(St,ht)= argminht,SkL( htT,k)。根据式(1),多源TrAdaboost算法虽然在一定程度上进行了知识的迁移,但是,该方法没有显式估计目标域和源域样本分布之间存在的差异性,对源域中知识迁移能力的解释能力有限。因此,难以从本质上解决源域关联性不足引起的“负迁移”现象。
3 可迁移测度准则下协变量偏移修正
针对多源TrAdaboost方法在目标域与源域样本分布一致性估计不足的问题,本文提出一种可迁移测度准则下的协变量偏移修正多源集成迁移方法。一方面,根据源域和目标域之间的协变量偏移原则,利用联合概率的密度估计,设计样本密度比值描述样本的可迁移度;另一方面,在多源域选择阶段,利用源域经验误差进行源域初步选择,避免由于分布差异引起的“负迁移”效应,提高迁移过程的可靠性。
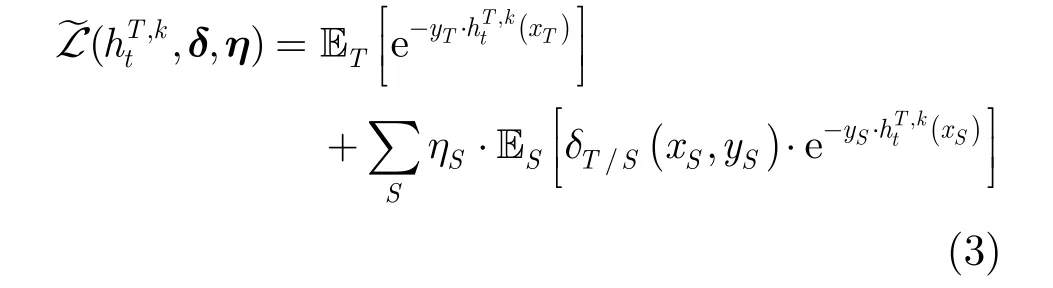
考虑协变量偏移下的可迁移测度后,对式(1)中的原始损失函数进行修正,则有其中,为一次迭代过程中源域 Sk和目标产生的迁移分类器, δ={δT/S(x,y )}为样本密度比值,}为源域迁移选择系数, ET[·]和ES[·]分别表示目标域和源域中的分类器预测损失期望。
3.1 协变量偏移下的样本可迁移测度
一般情况下,在迁移学习中,虽然源域与目标域样本分布形式不同,但对于给定的样本观测数据,该样本属于某个已知类别的条件概率相同,即标记y的正例和负例分布在目标域和源域样本x中是一致的这种现象被称为样本分布的协变量偏移(covariate shift)[26],而这种样本分布可较好解释多源TrAdaboost在目标域与源域样本分布一致性估计假设。
在协变量偏移条件下,讨论目标域和源域在数据空间中标记分布的一致性,分析联合概率,实现源域中每个实例的可迁移程度的有效估计。定义目标域和源域样本分布的密度比值为 δT/S(x,y)= PT(x,y )/ PS(x,y),则根据贝叶斯定理对该密度比值进行求解有
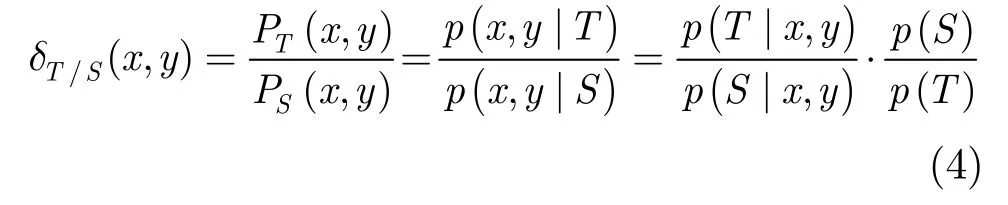
一般认为目标域和源域先验分布概率相同,即p(T )= p(S),因此δ取值仅取决于条件概率 p(T由于给定样本(x, y)属于目标域或源域的条件概率,无法先验获取,因此,实际通常采用预测标签与真实标签的指数函数进行近似:
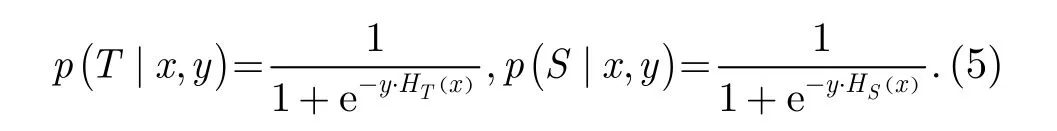
其中, HS(x)表示利用源域训练样本所得分类器,HT(x)表示利用目标域训练样本所得分类器,可根据传统机器学习方法直接学习获得。
3.2 源域非迁移选择
由式(1)进行的源域类别选择是一种确定性估计,但是,真实数据的损失估计存在不确定性,源域类别选择通常采用随机采样的过程,保证源域的多样性。本文通过估计源域的可迁移能力,调整随机采样的权重,实现源域非迁移选择,降低不良源域类别对目标域任务的“负迁移”效应。在第t次迭代中,源域 Sk对目标域T的可迁移能力定义为
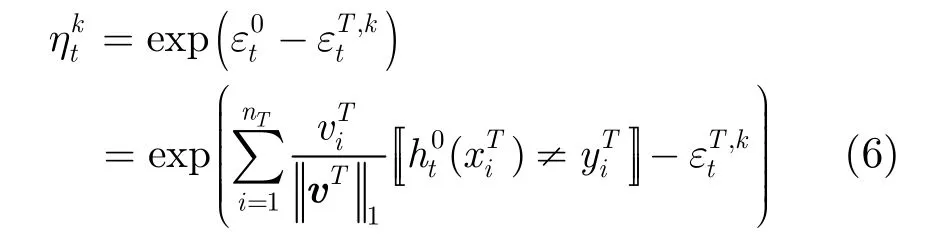
由于引入了源域非迁移选择,本文算法在多源TrAdaboost的框架中,通过重新估计随机采样的权重,抑制源域的“负迁移”现象。在每轮学习开始阶
3.3 协变量偏移下的样本权重更新
对于每个样本来说,样本分布密度比值仅依赖于源域和目标域。在最小化损失函数求解过程中,密度比值的估计对模型的影响主要体现在样本的权重更新过程中。
本文方法利用式(3)实现协变量修正下的损失估计,通过对其最小化获得最优分类器 ht,并进一步估计目标域和优胜源域在该分类器上的误差该误差是样本权重更新的重要依据。对于目标域中的样本来说,采用增大权重的方式强调该样本对分类判决面决策过程的影响。在源域样本的权重更新策略中,采用降低权重方式将其滤除。为进一步分析目标域样本权重的稳定性,迭代过程中的目标域样本权重可表示为
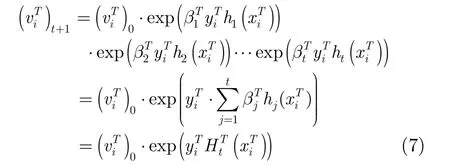
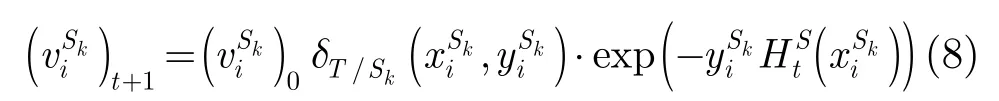
一般情况下,假设迁移学习的先验分布为等概率分布,各样本的初始权重相同,故忽略后不影响采样过程,更新过程等价为

式(9)给出了更为直接的计算形式,可以提高迁移学习的计算效率。
通过上述权重计算过程,可解释目标域样本分布 PT(x, y)和源域样本分布PSK(x,y)存在协变量偏移现象。在迭代运算过程中,目标域和源域的样本权重随之更新,用于调整对各源域的迁移误差估计。本文方法根据式(3)选出每轮优胜基分类器,最终将每轮的优胜基分类器组合获得的迁移学习分类器
4 实验与分析
4.1 实验图像集
为证明本文算法的有效性,分别采用加州理工学院的 Caltech256数据集[22]和麻省理工学院的SUN09数据集[27]进行实验。在本文实验中,通过对Caltech 256数据集进行数据统计,选择图像数不少于100幅的136个类别作为候选源域类别,剩余的120个类别作为候选目标域类别。对于SUN09数据集,选取144个类别中图像数目最少的前15个类别作为候选目标域类别,剩余的129个类别作为候选源域类别。本文采用Gist特征用于目标类别识别[28],Gist作为一种描述目标布局属性的主旨特征,具备描述Caltech256及SUN09数据集目标类的能力。
4.2 算法性能分析
目标域和源域的构造是迁移学习的基本步骤[4]:从候选目标域类别中任意选取某个类别作为目标域,从该类别中随机选取 n幅图像作为目标域正例样本,随机加入 n幅背景干扰图像作为目标域负例样本;从剩下的图像中随机选取 n幅正例和 n幅负例作为测试图像。接着,从候选源域类别中任意选取K个类别构建K个源域,从每个源类别中随机选取 n幅图像作为源域正例样本,在每个源域中随机加入幅背景干扰图像作为源域负例样本。
实验1 源域和目标域之间的密度比值估计
实验2 多源域迁移选择
进一步考察算法的源域选择情况和基分类器的误差,每轮迭代过程中随机选择5个源域。图2分别以Caltech256数据集的目标域类别hourglass和SUN09数据集的目标域类别 cup为例。其中,Caltech256数据集实验中随机选择的 5个源类为llama, ketch, T-shirt, hammock, light-house;SUN09数据集实验中随机选择的5个源类为table,gate, jar, pillow, pot。用柱状图给出前10轮源域选择结果,每轮选择1个优胜分类器,图中文字表示在该轮迭代中算法所选择的迁移源域类别。图2中部分源域选取的结果可能与人类认知并不相符,这种现象可以解释为:(1)源域类别随机且数量有限,选择范围内缺少更好的类别,每轮的分类器误差可能会增加;(2)算法除了选择源域,也对源域内样本进行了选择,可能其中的部分样本起到了正向迁移的作用。
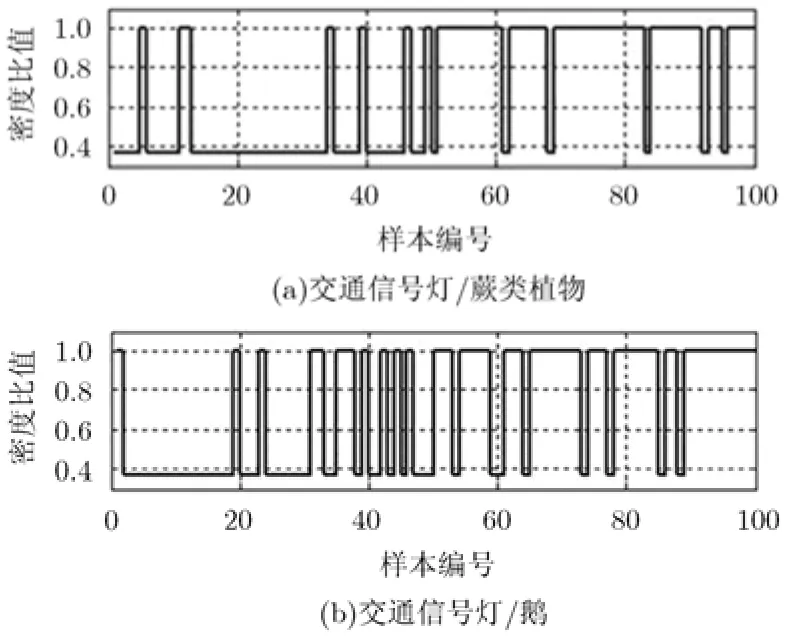
图1 目标/源域数据分布密度比值δ

图2 前10轮迭代过程中的源域选择情况
实验3 对比试验
为进一步说明算法的有效性,分别在Caltech256和SUN09数据集上实验,与目前公认经典有效的多类 Adaboost[25]、多源 TrAdaboost[4]算法进行对比。实验中各参数取值如下:目标域正例样本数,源域个数源域正例样本数基学习器均采用线性支持向量机(linear SVM), Adaboost弱分类器迭代次数均为30次。为增强实验客观性,所有实验结果均在15个随机目标域类别上进行测试,且由于实验中源域类别和样本选取的随机性,实验的定量评价结果为每个目标域类别上的5次重复实验的平均分类准确率。两个数据集下实验的参数设置相同。

图3 Caltech256数据集在4种条件下各算法的实验结果
实验结果考虑有限样本的规模对迁移学习算法的影响,分别在 4种条件下进行实验,测试图像中的比例和的比例保持一致,且固定在Caltech256和SUN09数据集下实验结果如图3和图4所示,其中45°斜线纹理柱为多类 Adaboost[25], 135°斜线纹理柱 为 多 源Adaboost[4],空心柱为本文方法实验结果,横坐标是源域个数K(4种情况),纵坐标为对应分类正确率,柱状图上方细线表示正确率变化的范围(即正确率方差)。
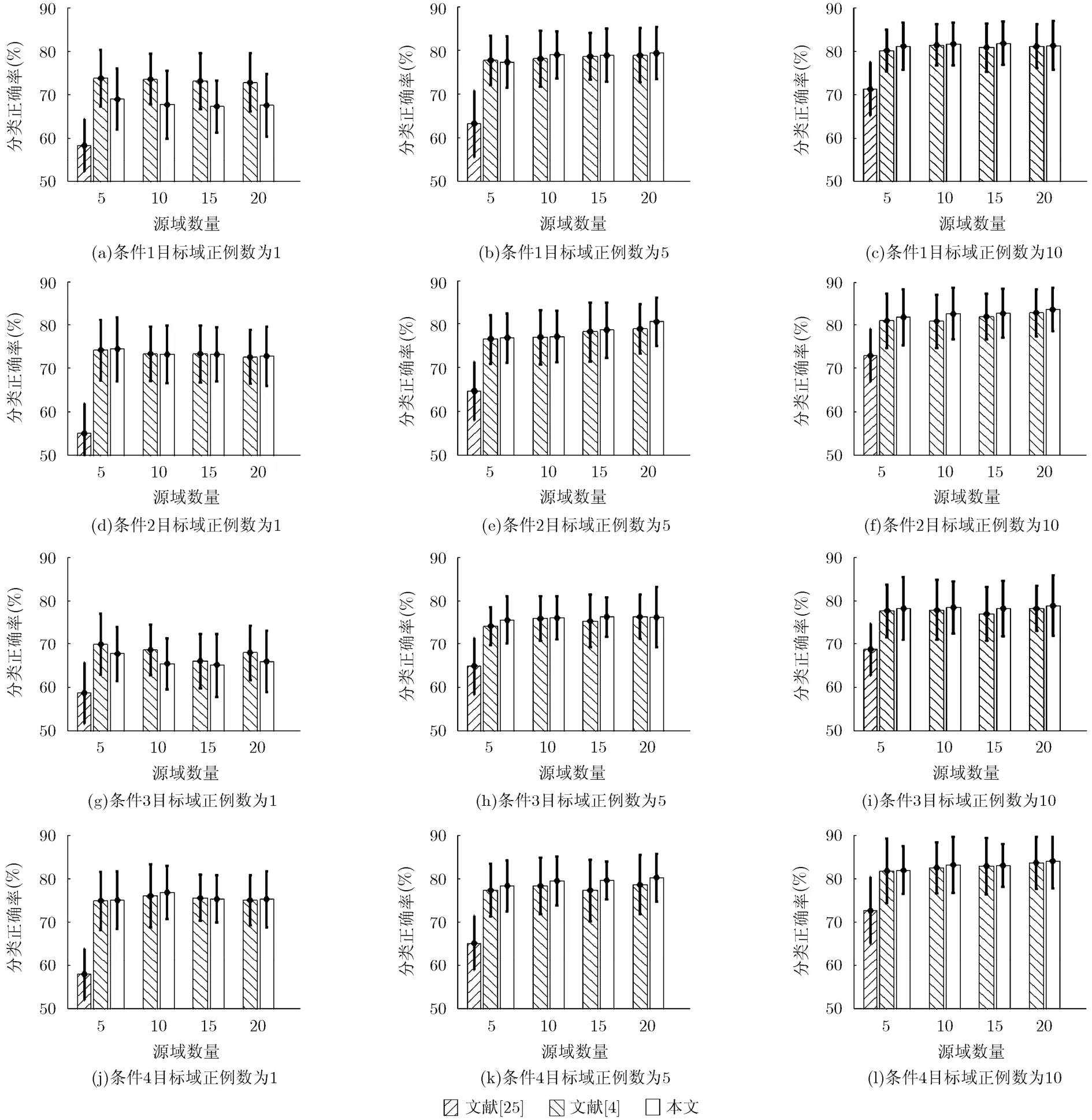
图4 SUN09数据集在4种条件下各算法的实验结果
根据图3和图4,实验分析源域个数对迁移学习影响情况可以发现,并非源域个数越多,迁移效果就一定越好,这是因为“迁移效应”主要和目标域、源域间的关联程度密切相关,过多的不相关源域可能反而会对迁移造成负向干扰。
4种条件分别给出了不同正负例分布的迁移学习情况,进一步分析负例样本数对迁移学习的影响。通过对比图3和图4中的数据可以发现,以条件(1)下的实验结果为基准,在条件(2)和条件(4)中,增加目标域的负例样本后,分类准确率可大幅上升且浮动较小,这表明目标域的负例样本对分类器的性能起到提升作用。然而,条件(3)中仅有源域的负例样本增加时,分类准确率反而下降,这说明过量的源域负例样本会给迁移过程带来干扰。总体而言,本文算法分类结果相对多源TrAdaboost方法具有明显优势。当目标域训练样本数为5和10时,多数情况本文方法完全胜出,少量条件下经典多源TrAdaboost方法能给出较好的结果,本文方法也能接近可行解。
从Caltech256和SUN09数据集实验均可以看出,新方法在极端情况(即目标域仅有1个正例训练样本)时的迁移效果不佳,这是因为在改进算法中增加了非迁移分类器作为判定条件。非迁移判断条件发生在以下的情况:由于在仅有1个正例训练样本时,所训练出的非迁移分类器随机性很大,只要对极少量的目标域样本分类正确,则视其误差为 0;在之后的源域类别的迁移能力计算中,会因为迁移分类器的误差大于0而出现大量负值,导致算法认定出现了“负迁移”而未能合理的进行源域的有效选取,在一定程度上限制了迁移过程的发生。
5 结束语
本文着重研究如何使用迁移学习理论解决小样本问题,通过分析迁移学习的“负迁移”现象产生的原因,解释了训练、测试样本不同分布的估计与评价方法,针对现有多源迁移算法,从两个方面分别解决源域选择和辅助样本选择的不足,通过考虑目标域、源域样本分布之间的差异性,对现有多源迁移损失函数引入了协变量偏移修正,抑制了单源域情况下的“负迁移”样本影响;通过在每轮迭代中计算源域的可迁移度,并增加非迁移判断,一定程度上抑制了多源域条件下的“负迁移”现象。实验结果证明了本文算法的有效性。由于本文实验采用单类别属性标记,未来工作将在此基础上向目标类的语义关系方向进行研究,分析语义指导下的源域选择方法。此外,本文算法在目标域仅有1个正例样本时效果不稳定,这种条件下的分类识 别(称为“one-shot learning”)已成为一个特定的研究课题,有待进一步改进的有效算法处理单样本跨域的迁移学习问题。
[1] Tommasi T, OrabonaF, and Caputo B. Learning categories from few examples with multi model knowledge transfer[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2014, 36(5): 928-941.
[2] Yao Y and Doretto G. Boosting for transfer learning with multiple sources[C]. Proceedings of Computer Vision and Pattern Recognition, San Francisco, 2010: 1855-1862.
[3] Long M S, Wang J M, Ding G G, et al.. Adaptation regularization a general framework for transfer learning[J]. IEEE Transactions on Knowledge and Data Engineering,2014, 26(5): 1076-1089.
[4] Lin D, An X, and Zhang J. Double-bootstrapping source data selection for instance-based transfer learning[J]. Pattern Recognition Letters, 2013, 34(11): 1279-1285.
[5] Kuzborskij I, Orabona F, and Caputo B. From N to N+1: multiclass transfer incremental learning[C]. Proceedings of Computer Vision and Pattern Recognition, Portland, 2013: 3358-3365.
[6] Zhu Y, Chen Y Q, Lu Z Q, et al.. Heterogeneous transfer learning for image classification[C]. Proceedings of AAAI Conference on Artificial Intelligence, San Francisco, 2011: 1304-1309.
[7] 张倩, 李明, 王雪松, 等. 一种面向多源领域的实例迁移学习[J]. 自动化学报, 2014, 40(6): 1176-1183. Zhang Qian, Li Ming, Wang Xue-song, et al.. Instance-based transfer learning for multi-source domains[J]. Acta Automatica Sinica, 2014, 40(6): 1176-1183.
[8] Pang J, Huang Q, Yan S, et al.. Transferring boosted detectors towards viewpoint and scene adaptiveness[J]. IEEE Transactions on Image Processing, 2011, 20(5): 1388-1400.
[9] Li G, Qin L, Huang Q, et al.. Treat samples differently: object tracking with semi-supervised online CovBoost[C]. Proceedings of International Conference on Computer Vision,Barcelona, 2011: 627-634.
[10] Qi G J, Aggarwal C, Rui Y, et al.. Towards cross-category knowledge propagation for learning visual concepts[C]. Proceedings of Computer Vision and Pattern Recognition,Colorado Springs, 2011: 897-904.
[11] Chu W S, Torre F D, and CohnJ F. Selective transfer machine for personalized facial action unit detection[C]. Proceedings of Computer Vision and Pattern Recognition,Portland, 2013: 3515-3522.
[12] Yang S Z, Hou C P, Zhang C S, et al.. Robust non-negative matrix factorization via joint sparse and graph regularization for transfer learning[J]. Neural Computing and Applications,2013, 23(2): 541-559.
[13] 方耀宁, 郭云飞, 丁雪涛, 等. 一种基于标签迁移学习的改进正则化奇异值分解推荐算法[J]. 电子与信息学报, 2013,35(12): 3046-3050. Fang Yao-ning, Guo Yun-fei, Ding Xue-tao, et al.. An improved regularized singular value decomposition recommender algorithm based on tag transfer learning[J]. Journal of Electronics & Information Technology, 2013,35(12): 3046-3050.
[14] Gopalan R. Learning cross-domain information transfer for location recognition and clustering[C]. Proceedings of Computer Vision and Pattern Recognition, Portland, 2013: 731-738.
[15] Luo Y, Liu T L, Tao D C, et al.. Decomposition-based transfer distance metric learning for image classification[J]. IEEE Transactions on Image Processing, 2014, 23(9): 3789-3801.
[16] Long M S, Wang J M, Ding G G, et al.. Transfer learning with graph co-regularization[J]. IEEE Transactions onKnowledge and Data Engineering, 2014, 26(7): 1805-1818.
[17] 洪佳明, 印鉴, 黄云, 等. TrSVM: 一种基于领域相似性的迁移学习算法[J]. 计算机研究与发展, 2011, 48(10): 1823-1830. Hong Jia-ming, Yin Jian, Huang Yun, et al.. TrSVM: a transfer learning algorithm using domain similarity[J]. Journal of Computer Research and Development, 2011,48(10): 1823-1830.
[18] Seah C W, Tsang I W, and Ong Y S. Transfer ordinal label learning[J]. IEEE Transactions on Neural Networkand Learning System, 2013, 24(11): 1863-1876.
[19] 许敏, 王士同, 史荧中. 一种新的面向迁移学习的 L2核分类器[J]. 电子与信息学报, 2013, 35(9): 2059-2065. Xu Min, Wang Shi-tong, and Shi Ying-zhong. A novel transfer-learning-oriented L2 kernel classifier[J]. Journal of Electronics & Information Technology, 2013, 35(9): 2059-2065.
[20] Long M S, Wang J M, Ding G G, et al.. Transfer feature learning with joint distribution adaptation[C]. Proceedings of International Conference on Computer Vision, Sydney,2013: 2200-2207.
[21] Patricia N and Caputo B. Learning to learn, from transfer learning to domain adaptation: a unifying perspective[C]. Proceedings of Computer Vision and Pattern Recognition,Columbus, 2014: 1442-1449.
[22] Zhang B, Wang Y, Wang Y, et al.. Stable learning in coding space for multi-class decoding and its extension for multi-class hypothesis transfer learning[C]. Proceedings of Computer Vision and Pattern Recognition, Columbus, 2014: 1075-1081.
[23] Gretton A, Smola A, Huang J, et al.. Covariate Shift by Kernel Mean Matching[M]. Cambridge: MIT Press, 2009: 131-160.
[24] Huang P P, Wang G, and Qin S Y. Boosting for transfer learning from multiple data sources[J]. Pattern Recognition Letters, 2012, 33(5): 568-579.
[25] Nie Q F, Jin L Z, and Fei S M. Probability estimation for multi-class classification using AdaBoost[J]. Pattern Recognition, 2014, 47(12): 3931-3940.
[26] Sugiyama M, Krauledat M, and Müller K R. Covariate shift adaptation by importance weighted cross validation[J]. The Journal of Machine Learning Research, 2007, 8(1): 985-1005.
[27] Choi M J, Lim J J, Torralba A, et al.. Exploiting hierarchical context on a large database of object categories[C]. IEEE Conference on Computer Vision & Pattern Recognition, San Frencisco, CA, 2010: 129-136.
[28] Han Y and Liu G. Biologically inspired task oriented gist model for scene classification[J]. Computer Vision and Image Understanding, 2013, 117(1): 76-95.
杨兴明: 男,1976年生,副教授,研究方向为计算机控制、模式识别、物联网应用.
吴克伟: 男,1984年生,讲师,研究方向为计算机视觉、图像处理、模式识别.
孙永宣: 男,1978年生,讲师,研究方向为计算机视觉、图像处理.
谢 昭: 男,1980年生,副研究员,研究方向为计算机视觉、图像处理、模式识别.
Modified Covariate-shift Multi-source Ensemble Method in Transferability Metric
Yang Xing-ming Wu Ke-wei Sun Yong-xuan Xie Zhao
(School of Computer and Information, Hefei University of Technology, Hefei 230009, China)
Transfer learning usually focuses on dealing with small training set in target domain by sharing knowledge generated from source ones, in which one main challenge is divergence metric of distributed samples between training and test data. In order to deal with “negative transfer” problem caused by improper auxiliary sample selections in source domains, this paper presents a modified covariate-shift multi-source ensemble method with transferability criterion. Firstly, transferability metric of auxiliary samples is defined by joint density estimation in accordance with co-variant transfer principles from source to target, so that the coherency of data distributions is verified. After that, whether transfer learning occurs or not should be determined after evaluating transferability metric in different sources to boost accuracy. Finally, experiments on Caltech256 using GIST demonstrate effectiveness and efficiency in the proposed approach and discussions of performance under diverse selections from auxiliary samples and source domains are presented as well. Experimental results show that the proposed method can sufficiently hold back “negative transfer” for better learnability in transfer style.
Ensemble learning; Transfer learning; Covariate shift; Image classification
s: The National Natural Science Foundation of China (60905005, 61273237)
TP391
A
1009-5896(2015)12-2913-08
10.11999/JEIT150323
2015-03-17;改回日期:2015-08-13;网络出版:2015-10-13
*通信作者:谢昭 xiezhao@hfut.edu.cn
国家自然科学基金(60905005, 61273237)
