基于关联规则与聚类分析的课程评价技术
2022-04-29范圣法张先梅虞慧群
范圣法, 张先梅, 虞慧群
( 华东理工大学1. 教务处;2. 计算机科学与工程系,上海 200237)
教学质量管理的根本目的在于形成教学质量的持续改进机制,保证教学质量不断提高[1]。课程质量是影响高校教育教学质量持续提升的首要因素,所有高等教育改革理念和思想,最终都要落实到课程建设中并通过课程的实施来实现[2-3]。已有的经验表明,外部因素如教育资源的投入、外部问责和评估等,并不能必然地提升教育质量,促进高等教育内部的教学质量才是解决问题的根本途径。因此,通过对本科课程的运行状态、教师、学生、实验、视频等信息的采集、分析和评价,建立本科课程评价体系及其支撑系统并用于本科教学管理服务中,将会增强教育改革的核心竞争力。如何合理地利用这些教学信息,以便得到对教学有益的潜在知识,做出有前瞻性的决策,已成为各大高校亟需解决的问题。
文献[4]挖掘了慕课平台中各类学习者的学习行为模式特点,从而找出优秀学习者所具备的特质。文献[5-7]通过分析学生的成绩数据,挖掘出各类学生的特点和有价值的关联规则,提高学生成绩和课程质量。文献[8]通过对学生属性、学习行为、历史成绩3 个方面的数据挖掘,预测出学生未来课程的表现,实现学生成绩预警,这对教师掌握不同类型学生的学习情况大有裨益。
本文基于以上研究背景,以毕业生能力达成分析为导向,以提高教学质量为目标,设计并实现了一种基于关联规则与聚类分析的课程评价技术系统,同时提供数据分析与决策支持功能。该系统针对传统课程评价系统单一地以成绩为唯一标准的问题,较为客观地使用了定量和定性相结合的课程评价原则,打破了地域和时间的限制,节约了大量人力和时间成本,实现了课程评价数据收集、课程评价处理的自动化。同时,对课程数据进行系统分析,得到了有助于提高教学质量的决策支持依据,为教师及专业责任教授提供了持续改进的参考依据。
1 课程评价数据预处理
1.1 需求分析
1.1.1 数据采集功能 课程评价系统需要采集课程数据及成绩数据。其中,课程数据不仅包括课程名称、课程人数等基本信息,还包括该课程与其对应指标点的考核评价依据等信息。成绩数据包括学生的姓名、学号等基本信息以及学生的考试、作业、实验成绩等信息,成绩数据的录入需要支持手工录入和通过Excel 文件批量导入,以贴合不同用户的使用习惯,使用户拥有良好的系统使用体验。数据采集用例如图1 所示。
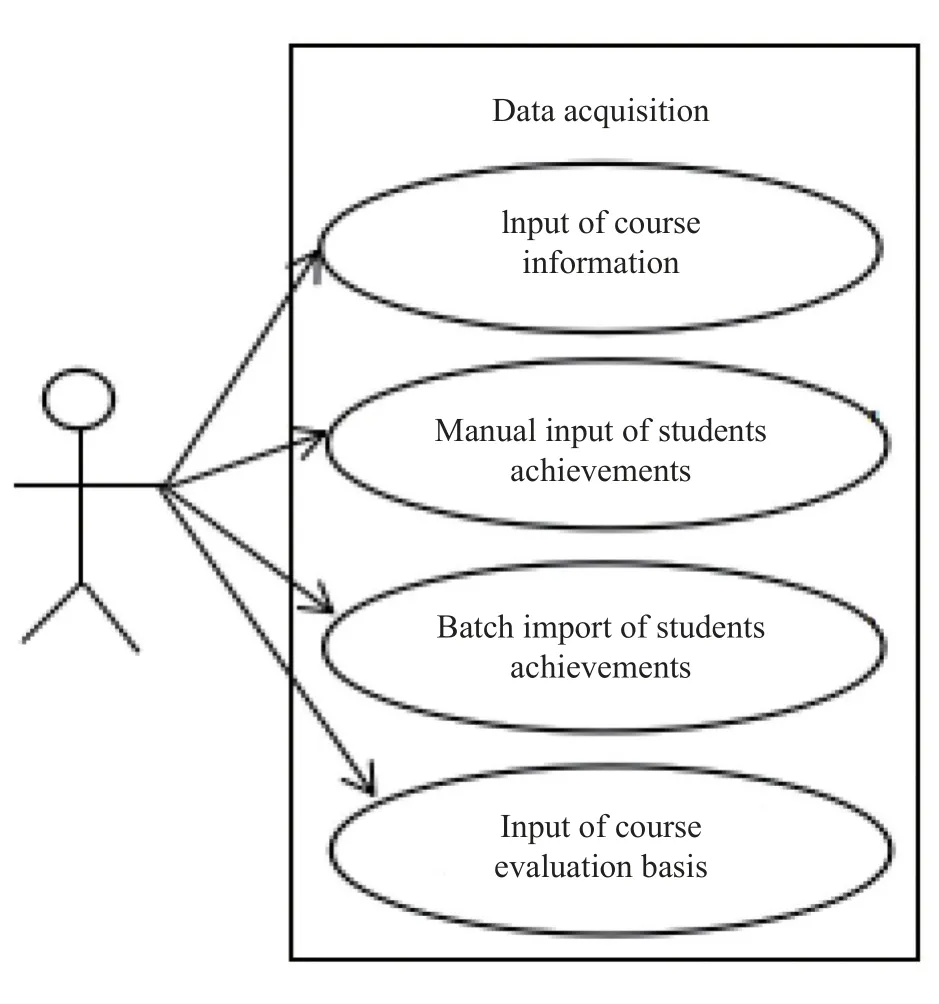
图1 数据采集用例图Fig. 1 Use case of data acquisition
1.1.2 报表查询及下载功能 课程评价系统旨在简化教育部工程教育认证的数据准备过程。由于在生成工程认证所需的报表1~报表9 时耗费了大量的人力及时间,因此如何通过采集到的数据生成所需要的报表,以提供给用户查看及下载成为了系统需要解决的问题。因篇幅限制,本文以《离散数学》课程为例,列出了报表6A:指标点相关考核项分解说明基本样式,如图2 所示。

图2 报表6A:指标点相关考核项分解说明基本样式Fig. 2 Report 6A: Basic styles of decomposition of relevant assessment items of indicator points
1.1.3 数据分析与决策支持功能 课程评价系统需要分析学生的成绩数据,根据毕业要求达成度评价方法,分别计算出课程达成度、指标点达成度、毕业要求达成度,并通过图表的形式直观地展示出每门课程学生的成绩分布情况及各项达成度,帮助教师优化教学方法,提高课程教学质量。数据分析与决策支持用例如图3 所示。

图3 数据分析及决策支持用例图Fig. 3 Use case of data analysis and decision-making support
教师登陆课程评价系统后,可以查看、更改个人基本信息,对自己的教学班进行管理。为进行课程质量评价,教师通过录入学生各项题型的成绩数据和与指标点相关联的评价依据,系统即可自动完成各项达成度的计算,生成对应的Excel 报表以供教师下载查看。同时,课程评价系统对学生成绩数据和各项达成度进行了可视化,教师可以直观地通过系统提供的多项图表对课程情况进行分析,做出具有前瞻性的教学决策。
1.2 总体功能
1.2.1 数据采集 数据录入功能为其他功能模块提供数据支持,包括开课课程的基本信息录入、评价依据信息录入、学生成绩录入。基本信息录入包括课程名称、学年、学生名单等信息的录入,其中学生名单可通过Excel 表格进行批量导入,该Excel 表格的格式需与预定义的学生名单的导入模板相匹配。完成课程基本信息配置后,可以进一步输入课程评价信息。评价信息录入包括评价依据、评价周期、课程与指标点的关联信息等信息的录入,从而为毕业要求达成度评价及工程认证表格的生成提供数据支持。学生成绩录入包括学生当前课程的考试成绩、作业成绩、实验成绩,分项拆解录入,并提供给用户批量导入和手工录入两种录入方式,贴近不同用户的使用习惯来改善用户体验。批量导入通过导入学生的考试成绩、作业成绩、实验成绩的分项拆解Excel 表格实现,该Excel 表格需符合预定义的成绩模板。
1.2.2 数据关联性和聚类分析 数据分析功能对存储在数据库中的各类课程数据进行计算分析,并将分析结果可视化,以便用户能够直观地了解课程评价结果。数据分析功能包括计算课程达成度、指标点达成度及毕业要求达成度并将它们存储在数据库中,分析学生成绩的分布情况,分析考试、作业、实验得分情况。
1.2.3 报表管理 报表管理是课程评价系统的核心功能之一,包括报表查询及报表下载。在已采集课程相关数据的基础上,课程评价系统能够自动生成报表,相较于传统的人工进行报表计算,具有其不可比拟的优势。报表查询通过第三方xlrd 模块实现对Excel 文件内容的读取,使用户能够在线查看报表。报表下载通过第三方xlwt 模块实现对Excel 文件的写入,完成写入操作的Excel 文件将保存在指定文件夹下,以供用户进行下载。
1.3 数据预处理
在实际的数据挖掘过程中,数据库庞大且一般由多个异构数据源构成,数据挖掘结果极易受到噪声、不一致的数据和缺失值的干扰,挖掘结果受数据质量影响大。因此,需要对数据进行预处理,以提高数据质量,简化数据挖掘过程。本文使用的数据是某专业2014~2018 学年所有学生已修课程的成绩数据,包括学生基本信息以及每门课程的考试、作业、实验成绩。数据预处理包括以下4 个步骤:
(1)数据清理。删除缺失数据以完成数据清理。由于部分学生未参加考试或是教师录入数据时未填写部分学生的成绩,导致成绩数据空缺,这些记录需进行删除。
(2)数据集成。删除重复的记录以解决数据冗余。由于教师批量导入的Excel 表格中存在重复的数据或是教师多次导入相同Excel 表格,导致数据库中存在同一个学生有多条成绩数据。因此,需保留该名学生多条成绩数据中的最高分,并将其他记录删除。此外,若学生的初修成绩不及格,次年需进行重修,也会造成数据冗余,需删除重复数据。
(3)数据转换。为使算法有更优的表现,对成绩数据进行标准化处理,具体方法是:将学生考试成绩除以考试总分,即标准化考试成绩=学生成绩/100,进而得到一个[0,1]区间内的数据。
(4)数据规约。数据离散化:数据形式受算法要求,学生考试成绩需进行离散化处理。将学生成绩分为优秀、不优秀两类,为排除课程的难度和出题方式的不同对考试成绩的影响,计算每一门课程的平均分,如果学生考试成绩大于该门课程的平均分则离散化为1,否则离散化为0。具体离散方式如表1所示。维数规约:去除无关属性。学生姓名、班级与数据挖掘无关,可以删除这些属性。

表1 考试成绩离散化处理Table 1 Discretization of examination score
2 基于关联规则与聚类分析的课程评价
2.1 关联规则分析
传统的Apriori 算法会产生大量的候选项集,同时为了完成模式匹配需要重复扫描整个数据库,开销尤为庞大。频繁模式增长(FP-growth)算法在不需要产生代价昂贵的候选项集前提下,可以挖掘出全部频繁项集[9-10]。
在对数据进行预处理的基础上,对考试成绩数据进行关联规则挖掘,用以发现不同课程之间的相互影响,帮助专业责任教授合理制定专业人才培养计划,培养能力更为综合的专业性人才,进一步提高教学质量。
在不忽视重要规则也不会产生大量无用规则的基础上,经过多次实验,最终最小支持度计数设置为50,最小置信度设置为0.85。使用FP-growth 算法对课程成绩数据进行关联规则挖掘到的部分课程关联规则如表2 所示。

表2 课程关联规则Table 2 Curriculum association rules
2.2 课程成绩数据类型的相异性度量
传统的K-means 算法在选择初始聚类中心时,从数据集中随机选择k个样本作为聚类中心,初始聚类中心不同,容易导致完全相异的聚类结果。面对不同的数据类型,数据挖掘技术往往需要使用不同的相异性度量方法[11-12]。本文中,学生成绩数据一般是数值类型数据,在进行离散化预处理后转变为二元类型数据,在此介绍其相异性度量方法。
2.2.1 学生成绩数据的相异性度量 学生成绩数据用整数或者实数值表示。不同的度量单位影响着聚类结果,因而在计算距离之前应对数据规范化处理,以最小化度量单位对聚类结果的影响。设学生成绩数据i=(xi1,xi2,···,xip)和j=(xj1,xj2,···,xjp) 中包含p个数值属性,i和j代表学生的成绩向量,常见的距离度量方法如下:
(1)欧几里得距离

2.2.2 离散化考试成绩的相异性度量 离散化考试成绩数据仅有0 或1 两种状态,其中0 表示学生考试成绩小于等于平均分,1 表示学生考试成绩大于平均分。两个离散化考试成绩数据之间的相异性可以通过二元类型数据联实现,如图4 所示,其中,a表示对象i和对象j的取值均为1 的状态数;b表示在对象i中取值为1、在对象j中取值为0 的状态数;c表示在对象i中取值为0、在对象j中取值为1 的状态数;d表示在对象i和对象j中取值均为0 的状态数。

图4 二元类型数据的列联表Fig. 4 Contingency table of binary type data
对称的二元类型数据中,它的两个状态被视作具有同等的重要程度,对称的二元相异性计算公式如下:
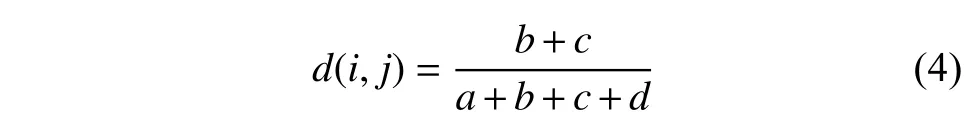
非对称的二元类型数据中,它的两个状态被视作具有不同的重要程度,取值全为1 的情况被视作比取值均为0 的情况更有意义。因此,d在此被略去,那么非对称的二元相异性计算公式如下:

例如,假设共有4 门课程,其平均分向量为(90,84, 81, 75)。学生i的成绩向量为(97, 90, 72, 83),则离散化后的成绩向量为(1, 0, 0, 1)。学生j的成绩向量为(88, 81, 91, 72),则离散化后的成绩向量为(0, 0,1, 0)。因此,可以得到图4 中a=0,b=2,c=1,d=1。
2.3 关联规则与聚类分析的课程评价实现
在不忽视重要规则也不会产生大量无用规则的基础上,经过多次实验,最终最小支持度计数设置为50,最小置信度设置为0.85。使用FP-growth 算法对课程成绩数据进行关联规则挖掘的伪代码如下:
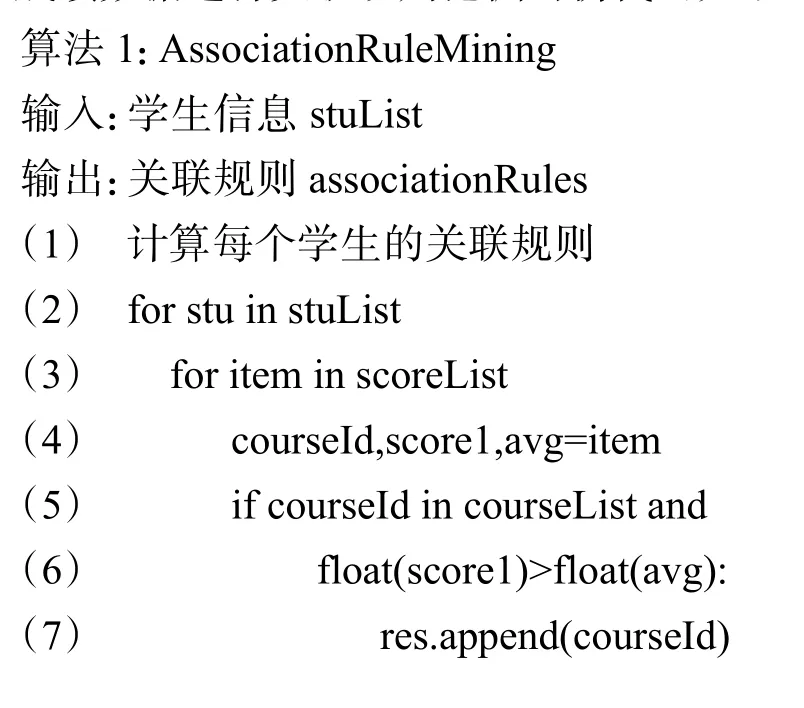

由于K-means++算法要求输入目标聚类个数,结合传统成绩判定方法,在避免产生无用聚类结果的基础上,将目标聚类个数设置为4,即k=4。使用sklearn.cluster 提供的K-means++算法,挖掘某门课程学生成绩的聚类结果的伪代码如下:

3 课程评价结果分析
为了说明K-means++算法相较于传统K-means算法的不同之处,本文通过一个实例说明K-means++算法选取课程成绩数据聚类中心的执行过程。选定如图5 所示的数据集,包含8 个成绩数据样本,图的横坐标代表平时成绩,纵坐标代表考试成绩。为简化计算,数据集中样本的序号(平时成绩,考试成绩)分别为1 号(3,4),2 号(4,4),3 号(3,3),4 号(4,3),5 号(0,2),6 号(1,2),7 号(0,1),8 号(1,1)。

图5 K-means++算法实例Fig. 5 Instances of K-means++ algorithm
假定算法随机选择6 号作为初始聚类中心,那么数据集中每一个样本到初始聚类中心的距离D(x)及被选为下一个聚类中心的概率P(x)如表3 所示。

表3 第2 个聚类中心的计算Table 3 Calculation of the second clustering center
表3 中S表示P(x)的累加值,S被用于通过轮盘法选择出下一个聚类中心。轮盘法的具体执行过程包括:随机产生一个[0,1]内的随机数,根据S的不同取值把[0,1]划分为若干个小区间,判断该随机数所处的具体区间,该区间所对应的元素即被选作下一个聚类中心。在本例中,区间被划分为[0,0.2),[0.2,0.525),···,[0.975,1],如果产生的随机数为0.3,那么该随机数落入[0.2,0.525)区间,据此2 号被选作下一个聚类中心。根据S的取值可以发现,第2 个初始聚类中心为1 号、2 号、3 号、4 号之一的概率为0.9,这4 个点恰为距离第一个初始聚类中心较远的点,这也验证了K-means++算法的思想,即距离已有聚类中心更远的点有更高的概率被选作下一个聚类中心。使用轮盘法重复以上步骤,生成所需的全部k个初始聚类中心。
K-means++算法解决了这个问题,即便考试难度存在一定的差异,也能从考试数据中挖掘出不同类型的学生。由于K-means++算法要求输入目标聚类个数,结合传统成绩判定方法,在避免产生无用聚类结果的基础上,将目标聚类个数设置为4,即k=4。Kmeans++算法对离散数学课程进行聚类,得到的最终聚类中心结果如表4 所示。
由表4 可以看出,第1 类学生考试成绩和平时成绩表现都很出色;第2 类学生考试成绩表现良好,但平时的表现较为普通;第3 类学生考试成绩表现良好,但平时表现尤为糟糕;第4 类学生考试成绩和平时成绩在及格线附近徘徊,表现欠佳。

表4 离散数学课程最终聚类中心Table 4 Final clustering center ofdiscrete mathematics
分析以上聚类结果,可以发现本课程各类学生的学习特点,从而得到有助于教师提高教学质量的结论:
(1)第1 类学生熟练掌握课程知识,平时表现优异,最终取得了非常理想的成绩。
(2)第2 类学生与第1 类学生相比,对课程的掌握程度相差不大,但平时成绩表现一般,可能是由于存在一定程度的缺勤、未交作业或实验完成效果不佳等情况,这些学生需要在平时的课程学习中加强自律性,提高对自己的要求。
(3)第3 类学生考试成绩表现良好,但平时成绩非常糟糕,其原因可能是考前通过高强度复习所以取得了不错的成绩,但平时可能存在比较严重的旷课、不交作业、不完成实验等情况,造成总成绩远低于考试成绩。
(4)第4 类学生考试成绩和平时成绩均表现较差,对课程知识的掌握程度较低,这可能是由于平时没有认真学习课程内容或是学生学习能力较差所导致。
综上所述,教师在教授课程时需要重点关注第3 类、第4 类学生的平时表现,他们容易存在学习态度不端正的情况。第4 类学生中可能存在部分学生学习能力较差,这一部分学生需要在平时的课程中鼓励其多向教师和同学提问,以尽快理解不懂的知识点,同时勤能补拙,这一部分学生平时的学习过程中需要多花一些时间。
此外,通过对上述关联规则的分析,可以进一步总结出有助于管理人员决策的结论:
(1)在新生和大二学生的培训课程中安排大学英语、汇编语言、线性代数、概率论和数字逻辑更为合理,这可以帮助学生为后续课程的专业知识打下坚实的基础。
(2)由于微机原理、计算机英语和计算机操作系统的课程内容比较全面,因此对于一些学习能力较差的学生来说是困难的。 因此,这些课程更适合大三学生。
4 结束语
各大高校在长期的教学活动中积累了海量的教学数据,如何从这些数据中发现有用的结论具有十分重要的现实意义。随着计算机技术的不断发展,可以通过数据挖掘技术帮助教师发现教学中可能存在的问题,从而及时改进教学方式,进一步提高课程教学质量,培养高质量人才,推动高校向更高水平发展。本文首先对课程评价系统的需求进行分析,系统主要功能包括:数据采集、报表生成与下载、数据分析与决策支持功能;然后完成了课程评价系统的总体架构设计和数据库设计,并基于Python 语言进行了系统实现;最后对课程成绩数据使用FPgrowth 算法进行关联规则分析,使用K-means++算法进行聚类分析,得到了有助于提高教学质量的决策支持依据,为教师及专业责任教授提供了持续改进的参考依据,为学生提供更精细化和个性化服务,有效提高学生成绩。
