基于时空图卷积网络的视频中人物姿态分类
2021-10-28张懿扬岳文静张怡静
张懿扬,陈 志*,岳文静,张怡静
(1.南京邮电大学 计算机学院,江苏 南京 210023; 2.南京邮电大学 通信与信息工程学院,江苏 南京 210023; 3.南京邮电大学 物联网学院,江苏 南京 210023)
0 引 言
在进行人物姿态分类时,一般认为人的行为具有多种模式,在群体人物行为中表现为三个或者更多相互作用、相互影响、有共同目标的人物组成的群体的相对运动现象[1],具体到竞技比赛中表现为运动者做出一些具有典型特点的竞技运动行为。通过对运动特征的分析与处理来提出可行性建议,可以提高运动质量,优化人们生活品质,提升体育竞技水平[2]。当前已开始使用深度学习等算法进行研究实验,形成了基于人工特征提取[3]的传统方法和基于深度学习[4]的方法。
在Microsoft Kinect、OpenPose等人体姿态检测系统中,人体关键点的运动轨迹为动作的描述提供了较好的表征,基于骨架关键点的模型通常能传达出重要的特征信息。以连续的视频帧中检测到的人体骨架关键点序列为输入,能够输出在视频中发生的人物动作类别。在早期使用骨骼进行人物动作识别时,仅仅利用单个时间步长的关键点坐标形成的特征向量,对其进行时间分析,并没有显式地利用关键点之间的空间联系。
在近期的研究中,利用关键点间自然联系的方法已经被开发出来[5],其效果较早期方法有着长足的进步,证明了连接的重要性。目前多数方法仍需要用手工制作的规则及部件来分析空间模式[6],这导致应用程序的设计模型很难泛化使用。
Yan S考虑到骨架的结构特征,提出了新的动态骨架模型:ST-GCN[7](时空图卷积网络)。因为其以图结构而非网络形式呈现,给卷积网络模型的使用造成困难。近来发现可以对任意图结构进行卷积的GCN(图卷积网络)有了快速的发展,不同于传统的基于图像的CNN(卷积神经网络),GCN可以基于任意拓扑结构进行卷积,因此可以基于人体姿态估计构造拓扑的人体结构,对人体结构进行运动学分析,最后以时序的人体结构进行CNN卷积,基于卷积的结果进行人体运动姿态分类。
尽管人体运动姿态分类任务有了新方向,在进行卷积网络模型训练时常常会出现特征冗余的问题。在卷积网络训练的过程中,关键点检测是检测人体的不同部分,并不是人体各个部分的特征都集中在最后一层特征图上,不同部分的特征可能会分布到不同尺度的特征图上,如果只是通过最后一层的特征图来进行关键点检测,会得到比较差的结果。Feichtenhofer等[8]在分类器级融合[9]的基础上提出了时间与空间特征融合算法,通过在Softmax层和卷积层之后的ReLU层进行操作以实现特征级的融合,有效避免特征冗余的问题,增强模型的鲁棒性。
1 基于ST-GCN的模型分析
考虑到要处理视频时需要分别进行空间部分与时序部分的网络训练,引入ST-GCN(spatial temporal graph convolutional networks)模型,即,该模型是结合图卷积网络和时间卷积网络进行的基于骨骼点的动作识别分类模型。
首先,为得到骨骼的数据,先使用OpenPose对视频进行预处理。该步骤将人体关节连接成骨骼,从而进行姿态估计。ST-GCN模型只需要关注其输出,由一系列的输入帧的身体关节序列构造时空图,时空图中将人体的关节作为图节点,将人体结构和时间上的连通性对应的两类边组成图的边。因此,ST-GCN将图节点的联合坐标向量作为输入,再对数据进行多层时空图卷积操作,从而形成更高级别的特征图。最后由SoftMax分类器分类到相应的动作类别。
在描述特征时需要表达多层骨骼序列从而尽可能保留原有的信息,ST-GCN使用时空卷积图来描述,能够很好地做到这一点。该模型使用每一帧每一个人体骨骼的坐标表示骨架关键点序列,基于此构建一个时空图,其中人体的关节关键点为图的节点V,以骨架自然连接方式构建空间图,得到空间边集Esp;身体结构的连通性和时间上的连通性为图的时序边集Et。由以上节点集与空间边集可构成训练时所需要的时空特征图。
在该模型中使用的卷积公式为:
aggre(x)=D-1AX
(1)
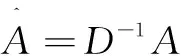

第一部分连接根节点本身,表示静止的特征;第二部分连接比节点本身更靠近骨架重心的相邻节点集,表示向心运动的特征;第三部分连接比节点本身更远离骨架重心的相邻节点集,表示离心运动的特征。
由此,一个卷积核将被划分为三个,其中每个卷积结果都代表了不同尺度的动作运动特征,将它们进行加权平均便能得到卷积的结果。
在完成以上步骤后,可以得到带有k个卷积核的图卷积表达式:
(2)
式中,n表示视频中的人数,k表示卷积核数量,使用上述子图划分方法后一般值为3,c表示关节特征数,t表示关键帧数,v、w表示OpenPose预处理后的输出关节数。对v求和代表节点的加权平均,对k求和代表不同卷积核的加权平均。
在通过图卷积网络得到空间上的节点特征后,还需要学习得到时间中节点的变化特征。在该模型中使用TCN,即时间卷积网络,通过传统卷积层的时间卷积操作来完成这项任务。
与此同时,考虑到在运动过程中,不同部分的躯干变化特征的重要性各不相同,因此在每个ST-GCN单元中都引入了注意力模型[10],用于在最后加权计算时保证每个单元有自己合适的权重,提高模型训练的准确性。最终利用标准的Softmax分类器将合并所有时空特征后的特征图分类到相应的类别当中,并用梯度下降SGD进行结果误差优化。
2 基于时空卷积网络的视频人物姿态分类
时空卷积网络ST-GCN具有良好的人体运动动作分类能力,但该模型仍存在不足之处。经过特征提取后得到的特征数据也存在着一些问题,例如,一单元内的方差较小,整体数据各个单元之间却有着较大数值的方差,而因为对图像部分特性的变化和其他特性的变化相比,同一种特征的敏感性不相同,因此当两类图像差异在某种特征敏感特性上的差异不大时,基于单一特征训练的分类器将无法得出正确的分类。此外,其他问题也会导致特征数据质量下降,例如复杂的背景噪声等,既增加了分类器训练难度,也降低了其准确性。
特征融合的方法可以解决这种问题,这种方法同时提取多种特征进行分类器训练,实现特征的互补。Simonyan提出了一种使用双流架构的网络模型[9],该模型属于分类器级的融合,通过对建立的空间流和时间流卷积神经网络分别进行独立训练,最终由Softmax分类器将上述两个网络融合。而Feichtenhofer在上述模型基础上做了网络融合方面的改进[8],提出了空间特征融合和时间特征融合算法,可以同时在分类器级和ReLU层进行融合操作,实现特征级的融合。
ST-GCN模型目前仅适用于分类器级的融合,因此对该模型进行如下改进:
针对该模型的时空特征图进行特征的融合,融合函数定义为[8]:
(3)

融合函数包括加性融合函数、级联融合函数、卷积融合函数等,为了尽可能保留原本特征图的结果,此处使用级联融合函数ycat=fcat(xa,xb),即:
(4)
式中,y∈H×W×2D,i∈[1,H],j∈[1,W],d∈[1,D]。它能够保留两个特征图的结果,保证特征描述的准确性,而融合后特征图的通道数量会变为原始特征图的两倍。实现特征级的融合,增强分类器结果的鲁棒性[11]。
3 实验与结果分析
3.1 实验准备
实验的数据集来源于hmdb51数据集[12],该数据集是当前识别动作研究领域最为重要的几个数据集之一,多数来源于电影,还有一部分来自公共数据库以及YouTube等网络视频库,包含51类动作,共有6 849个视频,每个动作每类至少包含有101段样本,分辨率为320*240。本次实验采用该数据集中的肢体动作部分,包括一般身体动作(general body movements)、与对象交互动作(body movements with object interaction)和人体动作(body movements for human interaction)三大类,实验数据集参数如表1所示。

表1 实验数据集参数
3.2 实验过程
为证明基于ST-GCN的视频人物运动分类改进模型的有效性以及更好的鲁棒性,现对某一视频进行运动人物检测与跟踪。该视频分辨率为320*240,帧率为30 F/s。
前10帧中每隔一帧取一次图像输出的运动人物检测与跟踪结果,如图1至图5所示,分类结果为上述图中人物正进行射门(足球运动)。

图1 第1帧图像(左)与运动姿态分类结果 (中上为原ST-GCN模型输出的骨骼图,中下为改进后模型骨骼图;右上为原ST-GCN模型输出的RGB渲染图,右下为改进后模型渲染图)

图2 第3帧图像(左)与运动姿态分类结果 (中上为原ST-GCN模型输出的骨骼图,中下为改进后模型骨骼图;右上为原ST-GCN模型输出的RGB渲染图,右下为改进后模型渲染图)

图3 第5帧图像(左)与运动姿态分类结果 (中上为原ST-GCN模型输出的骨骼图,中下为改进后模型骨骼图;右上为原ST-GCN模型输出的RGB渲染图,右下为改进后模型渲染图)

图4 第7帧图像(左)与运动姿态分类结果 (中上为原ST-GCN模型输出的骨骼图,中下为改进后模型骨骼图;右上为原ST-GCN模型输出的RGB渲染图,右下为改进后模型渲染图)

图5 第9帧图像(左)与运动姿态分类结果 (中上为原ST-GCN模型输出的骨骼图,中下为改进后模型骨骼图;右上为原ST-GCN模型输出的RGB渲染图,右下为改进后模型渲染图)
3.3 结果分析
实验采用HMDB51数据集进行测试,将结果根据动作分类进行每一类的对比后,再将改进后的模型与双流法Two-stream模型、深度监督网络Deeply-Supervised Nets模型[13]、残差网络ResNet-152[14]模型、TVNet[15]模型进行了对比,结果如表2和表3所示。

表2 模型改进前后不同动作的准确性比较 %
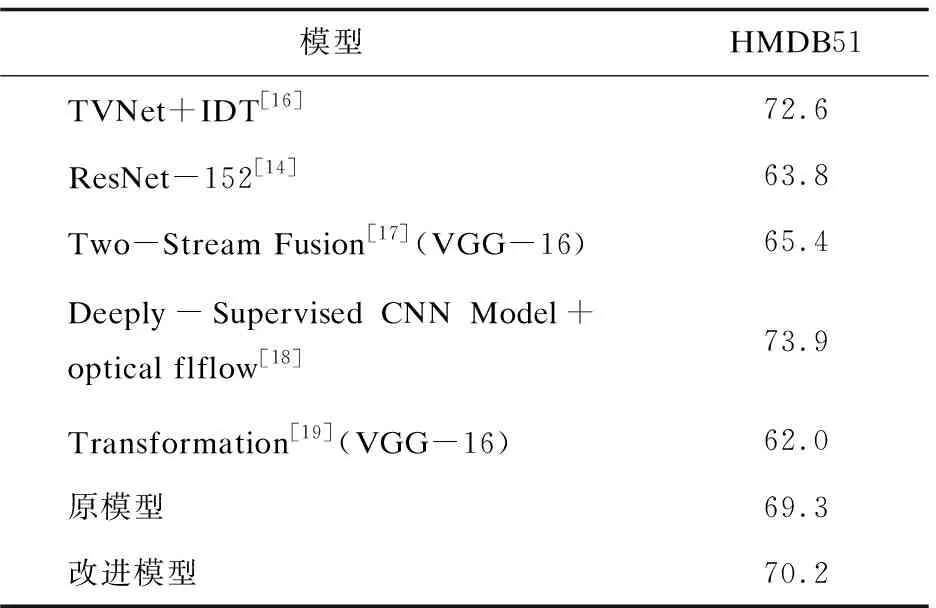
表3 改进模型与其他模型的准确度比较 %
图1至图5展示了视频中人物运动姿态分类模型的姿态分类结果,结果显示原ST-GCN与改进后的模型均能够正确地分类视频中的人物动作,但是相比于原模型,改进后的模型对于每个关节节点的特征进行卷积时的权重分配更符合人体运动规律。从表2和表3中能够看出,改进模型改善了原模型特征类内方差较小而类间方差较大的问题,具有更好的鲁棒性。
4 结束语
文中提出了基于时空图卷积网络的视频中人物姿态分类改进模型,该模型首先将输入的视频人体骨骼关键点进行处理,构造关节序列的时空图,继而将得到的时间特征图与空间特征图分别划分并进行级联特征融合,最后基于空间构型划分进行时序卷积与图卷积操作,得到分类结果。该模型能够准确得到视频中人物姿态的分类结果,解决了卷积网络在训练中的特征冗余问题,有效地提高人物姿态分类的鲁棒性。
在后续的研究中,可以考虑对视频中的一个群体进行动作分类,此外该算法是针对完整目标检测后的特征图分析与训练结果的分类,对于画面中有不完整人物出现时的目标检测仍有较大的发展空间。
